Post-Call Transcriptions
Pricing
The pricing of transcription, with or without summary, is $0.04510 / €0.04100 per minute, regardless of the number of participants. Only individual archive charges will be applicable.
Feature overview
Post-call transcription can help with improved record keeping, improved customer service, increased productivity, and better data analysis. Vonage Video API servers generate post-call transcriptions using artificial intelligence and other state-of-the-art technology.
You enable transcriptions when you start an archive using the REST API.
After the archive recording completes, the transcription will be available as a JSON file.
Enabling transcription when starting an archive
When you use the Vonage Video REST API start an archive, set the hasAudio and hasTranscription properties to true in the JSON properties you sent to the start archive REST method:
Also, you can include an optional transcriptionProperties object with a hasSummary (Boolean) and/or primaryLanguageCode (String) properties. When setting hasSummary to true, it will include an AI-generated summary in the transcription. If set to false or missing (default value is false), the transcription summary will not be included. If the transcription is for another language than the "en-US" (default), configure the property primaryLanguageCode with a supported language code.
Set outputMode (in the POST data) to "individual". Transcriptions are available for individual stream archives only.
Set the value for application_id to your Application ID. Set the value for json_web_token to a JSON web token (see the REST API Authentication documentation).
For other archive options, see the documentation for the start archive REST method.
The response for a call to the start archive REST method will include hasTranscription and transcription properties in addition to the other documented properties of the response:
{
"createdAt" : 1384221730555,
"duration" : 0,
"hasAudio" : true,
"hasVideo" : true,
"id" : "b40ef09b-3811-4726-b508-e41a0f96c68f",
"name" : "The archive name you supplied",
"outputMode" : "individual",
"applicationId" : "12345abc",
"reason" : "",
"resolution" : "640x480",
"sessionId" : "flR1ZSBPY3QgMjkgMTI6MTM6MjMgUERUIDIwMTN",
"size" : 0,
"status" : "started",
"streamMode" : "auto",
"hasTranscription" : true,
"transcription" : {
"hasSummary": true,
"primaryLanguageCode": "ja-JP",
"reason": "",
"status": "requested",
"url": ""
}
}
See Getting transcription status for information on dynamically getting the transcription details.
In an automatically archived session, the transcription won't be started automatically. You should start a second archive, using the multiArchiveTag option, for the transcription (see Simultaneous archives).
Support for transcriptions is currently available with the Vonage Video REST API and can be enabled and managed through the Vonage Server SDKs.
Getting transcription status
The response for the REST methods for listing archives and retrieving archive information will include hasTranscription and transcription properties:
{
"id" : "b40ef09b-3811-4726-b508-e41a0f96c68f",
"event": "archive",
"createdAt" : 1723584124,
"duration" : 328,
"name" : "the archive name",
"partnerId" : "123456abc",
"reason" : "",
"sessionId" : "2_MX40NzIwMzJ-flR1ZSBPERUIDIwMTN-MC45NDQ2MzE2NH4",
"size" : 18023312,
"status" : "uploaded",
"hasTranscription" : true,
"transcription": {
"status": "available",
"url": "URL for downloading the transcription, if available",
"reason": "The reason for failure, if status is set to failed",
"hasSummary": true,
"primaryLanguageCode": "The configured language code"
}
}
The hasTranscription property is a Boolean, indicating whether transcription is enabled for the archive.
The transcription property an object with the following properties:
status(String) — The status of the transcription, which can be set to one of these:"requested"— ThehasTranscriptionproperty was set totrueduring the start archive call, but transcription has not started."failed"— The transcription failed. Check thereasonproperty for more information."started"— The transcription is in progress."available"— The transcription is available for download from Vonage. Check theurlproperty."uploaded"— The transcription is available for download from the S3 bucket or Azure container you specified in your Video API account. Look for a transcription.zip in the archive ID folder in your archive storage target. See Archive storage.
url(String) — The URL URL for downloading the transcription, if thestatusis set to"available".reason(String) — The reason for transcription failure, if thestatusis set to"failed".hasSummary(Boolean) — Indicates whether an AI-generated summary is included in the transcription.primaryLanguageCode(String) — The language code configured for the transcription.
You can also set an archive status callback for your Video API account. See Archive status changes. The callback data will also include hasTranscription and transcription properties.
Transcription format
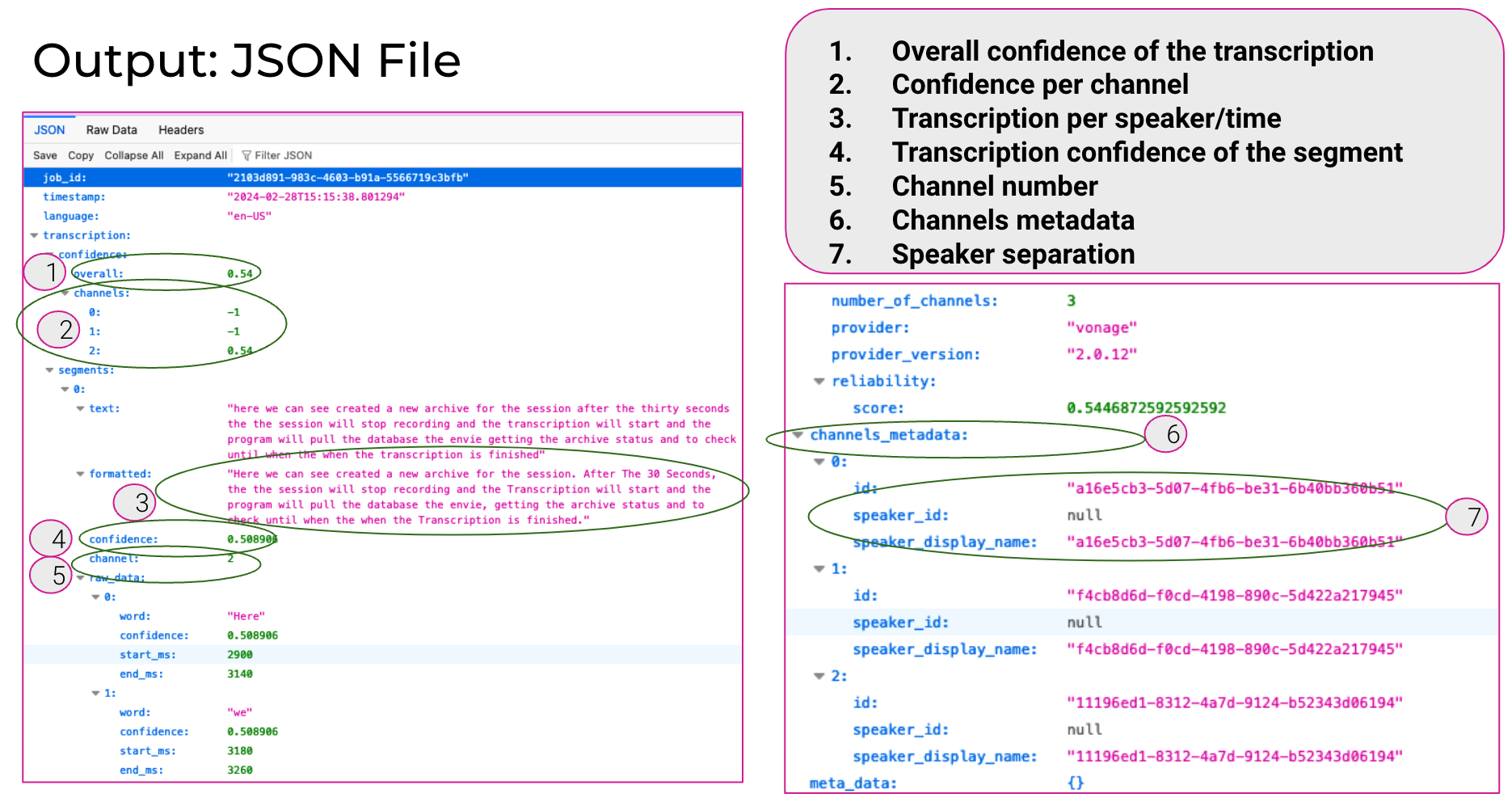
The transcription is provided as a compressed ZIP file. The uncompressed file is a text file with JSON data.
The transcription includes individual segments of text. Each segment corresponds to an individual audio channel (from one of the audio streams in the session).
The JSON has the following top-level properties:
job_id— A unique ID for the transcription.timestamp— An ISO 8601 date string for when the transcription file was created.number_of_channels— The number of individual audio channels in the archive included in the transcription.reliability— An object with one property:score. Thescoreis a number indicating the estimated overall reliability of the transcription (from 0 to 1.0).summary— If you set thehasSummaryproperty of thetranscriptionPropertiesobject totruewhen starting the archive, this property is included. It is set to an AI-generated summary of the transcription.confidence— A object with two properties:overallandchannels. Theoverallproperty is the estimated confidence of the entire transcription (from 0 to 1.0). Thechannelsproperty is an array listing the estimated confidence of each channel in the transcription.channels_metadata— An array of objects defining each audio channel. Each object anidproperty, which is the video stream ID. You can add identifying connection data when you create a client token for each user. You can use session monitoring callbacks to get the stream IDs and the connection data for each stream's connection. You can then use these to identify the stream's user in the transcription.segments— An object containing individual segments in the transcript. Each segment object has the following properties:text— The transcribed text of the segment.formatted— The formatted text (with punctuation) of the segment.confidence— A number, from 0 to 1.0, representing the estimated confidence of the segment's transcription.channel— The integer identifying the audio channel for the segment.
raw_data— An array objects for each word in the transcription segment. Each object includes the following properties:word— The word.confidence— A number, from 0 to 1.0, representing the estimated confidence of the transcribed word.start_ms— The offset of the start of the word from the start of the transcription, in milliseconds.end_ms— The offset of the end of the word from the start of the transcription, in milliseconds.
Download transcriptions
There are two ways to download the transcription file for an archive: via the REST API or via the Developer Dashboard.
Download via the REST API
You can download the transcription file for a specific archive by calling the retrieve archive information REST method and checking the transcription.url property in the response. If the transcription.status property is set to "available" or "uploaded", the transcription.url property contains a URL for downloading the transcription file.
Use an HTTP GET request to download the transcription file from the URL. For example:
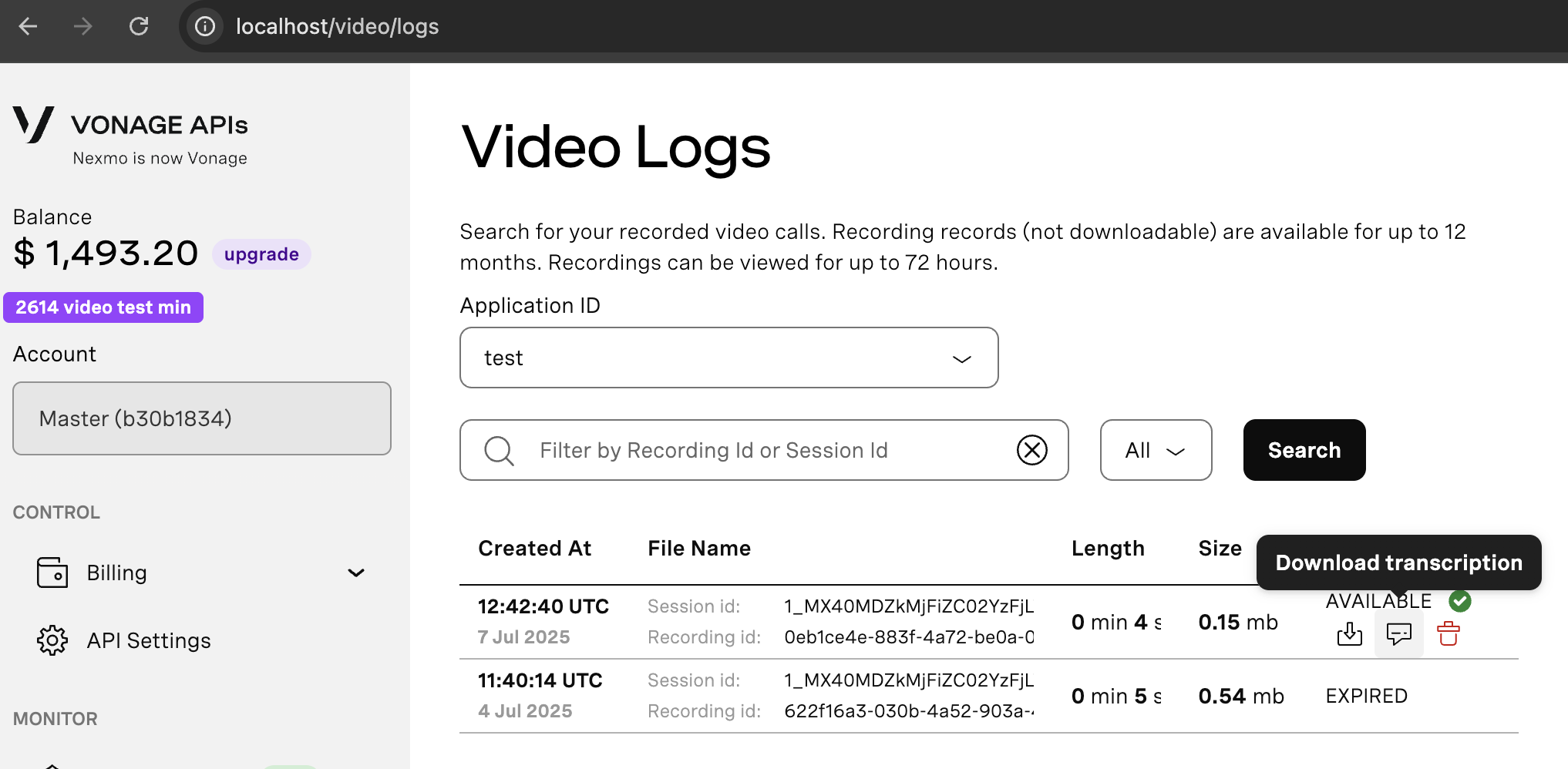
Download via the Developer Dashboard
You can download transcription for a specific call if the fallback storage option has been enabled by following these steps:
- Open the Developer Dashboard and navigate to Video Logs.
- Select an application from the applications list and click search. Optionally You can provide recording ID or session ID to narrow down the results.
- In the results list, locate the relevant session.
- Hover the mouse over the Status column for that session and click the Download Transcription button.
Limitations/Known Issues
Transcriptions are only available for individual stream archives, not for composed archives.
Transcriptions are not compatible with encrypted archives.
This feature currently supported with the Vonage Video REST API, not with the Vonage Video server SDKs.
The maximum length of a transcription is 120 minutes.
Post-call transcription is not fully compliant with all Regional Media Zones (see below).
| Regional Media Zone Support | Available |
|---|---|
| USA | Yes |
| EU | Yes |
| Canada | Based on requirement |
| Germany | Based on requirement |
| Australia | Based on requirement |
| Japan | Based on requirement |
| South Korea | Based on requirement |
| Singapore | Based on requirement |
Frequently Asked Questions
- How many streams can be analyzed from a single session?
- Up to 50 streams with a maximum of 120 transcribed minutes.
- Does Post-call Transcription work with both Routed and Relayed Sessions?
- The Post-Call Transcriptions feature is intended for Routed sessions that use the Vonage Media servers.
- If the transcription uploads to the customer-configured S3 bucket fails, does the retry or fallback mechanism work similarly to the archive upload?
- Yes, the retry mechanism for PCT operates exactly the same as for regular archive uploads.
- In cases where the transcription falls back and is uploaded to the Vonage cloud, will the customer need to use an HTTP GET request to obtain the download link for the transcription?
- When the transcription status changes, the customer should receive a callback that includes the download URL. If no callback is registered, the download link can only be retrieved through an HTTP GET request.
- Once the transcription download link is received, it allows for a direct download. Are there any plans to introduce authentication for downloading the transcription?
- There are no plans to introduce authentication for the link. The download link has a short expiration window. If not accessed within that timeframe, a new request must be made to obtain a fresh link.
- Even though multiple users have joined in the session, the transcription file is a single JSON file. How do we differentiate between the users?
- Each transcription entry in the file is associated with a specific channel number, assigned to each stream. The file also includes
channels_metadata, which provides stream ID information corresponding to each channel ID.
- Each transcription entry in the file is associated with a specific channel number, assigned to each stream. The file also includes
Supported Languages
| Language | Code |
|---|---|
| Afrikaans (South Africa) | af-ZA |
| Amharic (Ethiopia) | am-ET |
| Arabic (United Arab Emirates) | ar-AE |
| Arabic (Bahrain) | ar-BH |
| Arabic (Algeria) | ar-DZ |
| Arabic (Egypt) | ar-EG |
| Arabic (Israel) | ar-IL |
| Arabic (Iraq) | ar-IQ |
| Arabic (Jordan) | ar-JO |
| Arabic (Kuwait) | ar-KW |
| Arabic (Lebanon) | ar-LB |
| Arabic (Morocco) | ar-MA |
| Arabic (Mauritania) | ar-MR |
| Arabic (Oman) | ar-OM |
| Arabic (Palestinian Territories) | ar-PS |
| Arabic (Qatar) | ar-QA |
| Arabic (Saudi Arabia) | ar-SA |
| Arabic (Syria) | ar-SY |
| Arabic (Tunisia) | ar-TN |
| Arabic (Yemen) | ar-YE |
| Azerbaijani (Azerbaijan) | az-AZ |
| Bulgarian (Bulgaria) | bg-BG |
| Bengali (Bangladesh) | bn-BD |
| Bengali (India) | bn-IN |
| Bosnian (Bosnia and Herzegovina) | bs-BA |
| Catalan (Spain) | ca-ES |
| Czech (Czech Republic) | cs-CZ |
| Danish (Denmark) | da-DK |
| German (Austria) | de-AT |
| German (Switzerland) | de-CH |
| German (Germany) | de-DE |
| Greek (Greece) | el-GR |
| English (Australia) | en-AU |
| English (Canada) | en-CA |
| English (United Kingdom) | en-GB |
| English (Ghana) | en-GH |
| English (Hong Kong) | en-HK |
| English (Ireland) | en-IE |
| English (India) | en-IN |
| English (Kenya) | en-KE |
| English (Nigeria) | en-NG |
| English (New Zealand) | en-NZ |
| English (Philippines) | en-PH |
| English (Pakistan) | en-PK |
| English (Singapore) | en-SG |
| English (Tanzania) | en-TZ |
| English (United States) | en-US |
| English (South Africa) | en-ZA |
| Spanish (Argentina) | es-AR |
| Spanish (Bolivia) | es-BO |
| Spanish (Chile) | es-CL |
| Spanish (Colombia) | es-CO |
| Spanish (Costa Rica) | es-CR |
| Spanish (Dominican Republic) | es-DO |
| Spanish (Ecuador) | es-EC |
| Spanish (Spain) | es-ES |
| Spanish (Guatemala) | es-GT |
| Spanish (Honduras) | es-HN |
| Spanish (Mexico) | es-MX |
| Spanish (Nicaragua) | es-NI |
| Spanish (Panama) | es-PA |
| Spanish (Peru) | es-PE |
| Spanish (Puerto Rico) | es-PR |
| Spanish (Paraguay) | es-PY |
| Spanish (El Salvador) | es-SV |
| Spanish (United States) | es-US |
| Spanish (Uruguay) | es-UY |
| Spanish (Venezuela) | es-VE |
| Estonian (Estonia) | et-EE |
| Basque (Spain) | eu-ES |
| Persian (Iran) | fa-IR |
| Finnish (Finland) | fi-FI |
| French (Belgium) | fr-BE |
| French (Canada) | fr-CA |
| French (Switzerland) | fr-CH |
| French (France) | fr-FR |
| Galician (Spain) | gl-ES |
| Gujarati (India) | gu-IN |
| Hindi (India) | hi-IN |
| Croatian (Croatia) | hr-HR |
| Hungarian (Hungary) | hu-HU |
| Armenian (Armenia) | hy-AM |
| Indonesian (Indonesia) | id-ID |
| Icelandic (Iceland) | is-IS |
| Italian (Switzerland) | it-CH |
| Italian (Italy) | it-IT |
| Hebrew (Israel) | iw-IL |
| Japanese (Japan) | ja-JP |
| Javanese (Indonesia) | jv-ID |
| Georgian (Georgia) | ka-GE |
| Kazakh (Kazakhstan) | kk-KZ |
| Khmer (Cambodia) | km-KH |
| Kannada (India) | kn-IN |
| Korean (South Korea) | ko-KR |
| Lao (Laos) | lo-LA |
| Lithuanian (Lithuania) | lt-LT |
| Latvian (Latvia) | lv-LV |
| Macedonian (North Macedonia) | mk-MK |
| Malayalam (India) | ml-IN |
| Mongolian (Mongolia) | mn-MN |
| Marathi (India) | mr-IN |
| Malay (Malaysia) | ms-MY |
| Burmese (Myanmar) | my-MM |
| Nepali (Nepal) | ne-NP |
| Dutch (Belgium) | nl-BE |
| Dutch (Netherlands) | nl-NL |
| Norwegian (Norway) | no-NO |
| Polish (Poland) | pl-PL |
| Portuguese (Brazil) | pt-BR |
| Portuguese (Portugal) | pt-PT |
| Romanian (Romania) | ro-RO |
| Russian (Russia) | ru-RU |
| Kinyarwanda (Rwanda) | rw-RW |
| Sinhala (Sri Lanka) | si-LK |
| Slovak (Slovakia) | sk-SK |
| Slovenian (Slovenia) | sl-SI |
| Albanian (Albania) | sq-AL |
| Serbian (Serbia) | sr-RS |
| Southern Sotho (South Africa) | st-ZA |
| Sundanese (Indonesia) | su-ID |
| Swedish (Sweden) | sv-SE |
| Swahili (Kenya) | sw-KE |
| Swahili (Tanzania) | sw-TZ |
| Tamil (India) | ta-IN |
| Tamil (Sri Lanka) | ta-LK |
| Tamil (Malaysia) | ta-MY |
| Tamil (Singapore) | ta-SG |
| Telugu (India) | te-IN |
| Thai (Thailand) | th-TH |
| Turkish (Turkey) | tr-TR |
| Tsonga (South Africa) | ts-ZA |
| Ukrainian (Ukraine) | uk-UA |
| Urdu (India) | ur-IN |
| Urdu (Pakistan) | ur-PK |
| Uzbek (Uzbekistan) | uz-UZ |
| Venda (South Africa) | ve-ZA |
| Vietnamese (Vietnam) | vi-VN |
| Xhosa (South Africa) | xh-ZA |
| Zulu (South Africa) | zu-ZA |