
Share:
Sina is a former member of the Vonage Team. He was a Java Developer Advocate at Vonage. He comes from an academic background and is generally curious about anything related to cars, computers, programming, technology and human nature. In his spare time, he can be found walking or playing competitive video games.
Boost Your Productivity with Model-Driven Engineering (Part 2)
Welcome back to our productivity-boosting adventure! In Part 1, we covered the main concepts of model-driven engineering (MDE) and briefly introduced some "tools of the trade". In this article, I will provide a case study - specifically, how I used these technologies to help save a lot of time in adding support for new APIs to the Vonage Java SDK.
We have a lot of APIs at Vonage. Some of these are fairly small and simple, but some are huge. Take, for example, our larger APIs like Video, Meetings and Proactive Connect. Compare them to a smaller API, like Number Insight v2 - just look at the size difference in the scroll bars! Those larger APIs have not only lots of endpoints but also large and complex data models for requests and responses.
Once an API is considered stable ("General Availability" status), we aim to add support for it in our official SDKs. I have already written about the value SDKs add, and my colleague Jim Seconde has also talked about this, so I won't repeat the benefits of offering SDKs for APIs. Needless to say, a high-quality SDK requires significant resources to develop and maintain - it's probably around 80% of my job! However, much of the effort that goes into adding new APIs to our SDKs is quite laborious and requires very little thought. Whilst writing boilerplate can be somewhat therapeutic, it is undoubtedly not the best use of a developer's time because such a task can be automated.
So, what does a strongly typed SDK, such as the Java or .NET require? Well, for a start, (usually) every endpoint needs to be supported, so having the logic for the correct URL, HTTP request method, and authentication type. Generating a JSON Web Token, for example, and applying it to the request payload with the right settings, as well as other metadata such as Content-Type and Accept headers. Then, there are the actual request bodies. Sometimes, the payload is part of the query parameters, such as when filtering search results in a GET request. Other times, it's part of the body and needs to be serialised as JSON. The SDK also needs to handle responses: both successful (2xx HTTP status codes) and unsuccessful (4xx and 5xx codes). Endpoints that return a response body need to be parsed from JSON. Thus, the SDK needs to be able to serialise and deserialise JSON payloads into an object. Whilst libraries such as Jackson make this process declarative, we still need to define the classes and fields manually. There are other things, such as validation (to prevent 422 responses) and documentation, but hopefully, you get the idea. Ultimately, it's about making life as easy as possible for users of the API when using it from a programming language.
Having now introduced the problem domain and model-driven engineering concepts, we can now look at bringing it all together. There are various ways to approach this depending on the scope and time commitment, and there's no definitive "right" way to do it. Therefore, I will describe the pragmatic approach I took. Since the goal is to maximise productivity, I did not spend a lot of time "over-engineering" or architecting the solution upfront. With MDE, this can work, but it also has its drawbacks. I will return to discussing this at the end. If you want to follow along, I've made this open-source on GitHub.
As is the case with any model-driven engineering approach, the first place to start is the metamodel. So, here it is, with both the textual Emfatic syntax on the left and the tree view on the right. Note that I decided to create the metamodel using the built-in Ecore editor rather than Emfatic or an alternative (meta)modelling tool.
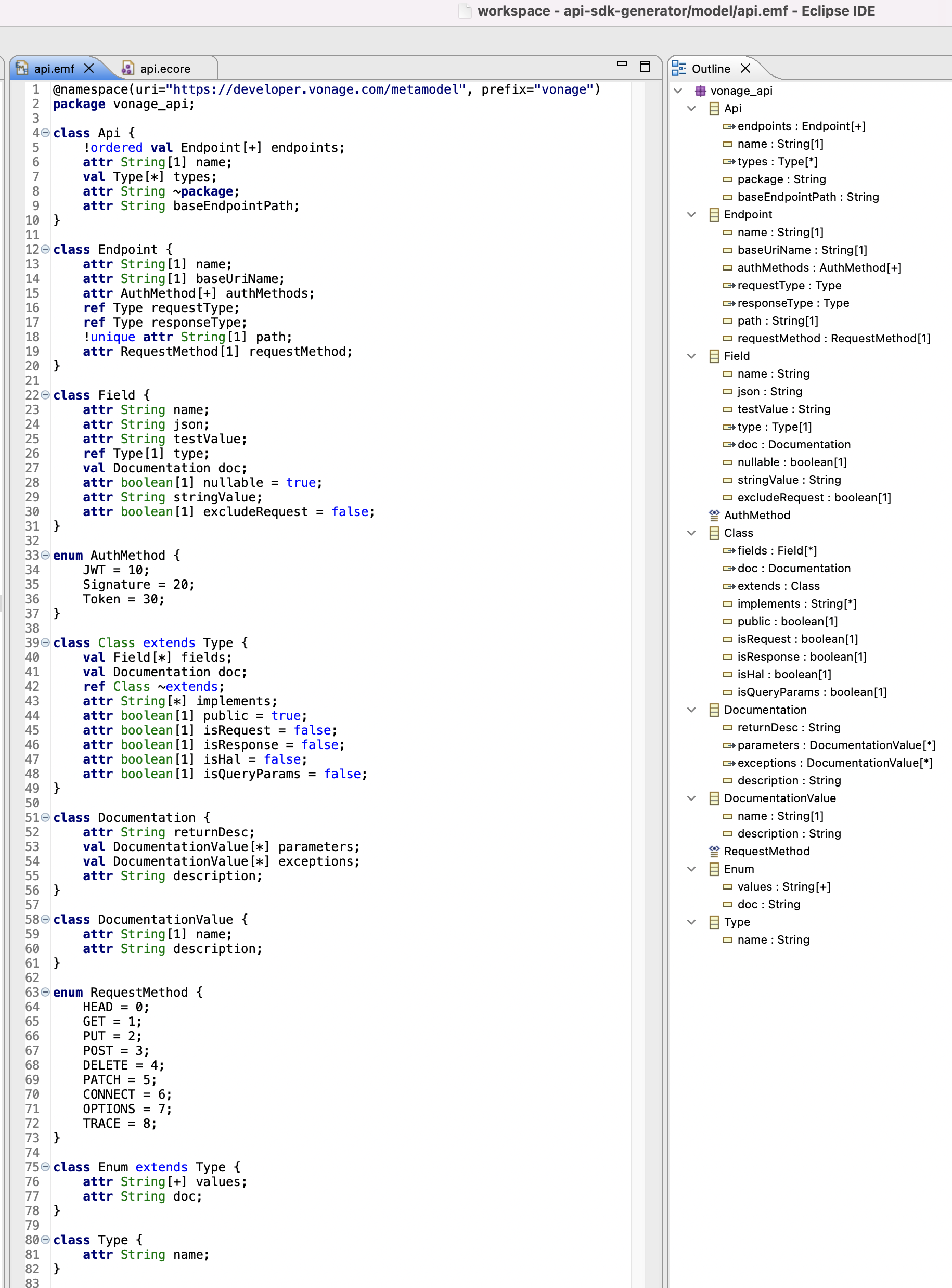
If you've looked at any of the OpenAPI specs mentioned earlier, the metamodel should hopefully be somewhat self-explanatory in its structure. The root of the hierarchy is the Api class, which has a name, package (which is to say where the classes will be in the SDK), the base endpoint path (for example, https://api-eu.vonage.com/v1/meetings for Meetings API) and of course the actual endpoints. Since all objects need to be contained in the root element, types are referenced here even though they are not directly used by the Api class.
The Endpoint class is next in the hierarchy. It has what you'd expect: name, URL (path), the HTTP request method (represented as an enum), one or more authentication methods (again, represented as an enum since there are 3 types), and of course, the request & response types.
So what is a type? Well, it can be a built-in type that we want to reference - i.e. a type already defined in the SDK, standard library etc. - basically, anything we don't want to model. So a Type just has a name attribute that we can use in these cases (e.g. String, UUID, Integer, URI and so on). Types that we do want to model are a Class which extends Type (thus inheriting the name attribute). This is somewhat an exercise in partially modelling a Java class, except much more specific to our needs. As you can see from the remaining attributes and types described in the metamodel, there are some very peculiar fields and notable omissions. For example, a Java class has methods and constructors, but these are not included here. Why? Because we don't need them. I've also decided to model the documentation for Class and Field using the Documentation type, but again these are incomplete relative to the capabilities of Javadoc. Modelling the entirety of Java is way beyond our needs. To satisfy your curiosity, here is a metamodel of Java 7 - and that's without all the fancy features of the latest JDKs!
Now for the part you've been waiting for: code generation! As mentioned in Part 1, there are several Model-to-Text tools available, but I've opted to use Epsilon's Generation Language (EGL). This is mostly due to familiarity, and EGL isn't particularly special. It is a template-based language, where a template (.egl file) has static and dynamic regions. Static regions are the default: text entered in the file will appear verbatim in the output. On the other hand, dynamic regions allow you to programmatically determine the output, which can (and usually will) depend on some property of the model.
For example, in exception.egl, I am using only one property: name to vary the output. The request_response.egl template is more complex, using for loops to declare all the fields in the class and relying on helper functions which I defined in helper_functions.egl. Since EGL is built on top of EOL, dynamic regions can contain any EOL code, including operations. EGL also has "template operations" (annotated with @template), which are functions that output text (or return the text as a string) when called. Thus, we can build up our library of utility functions and reuse them across templates.
You may be wondering: where do these variables come from, and how are the templates invoked? After all, for a template to be useful, it has to be parameterised with values from the model. And where does the output get written to? That's where the main benefit of using Epsilon comes in: its EGX coordination language. The idea of EGX is to provide a rule-based language that controls when & how templates are called, the parameters they are called with and where the output is directed to. The specs.egx file defines this logic - it's what brings the model and templates together. The pre section is executed first and contains mainly variable declarations that will be used in the script, such as the output directory and common names. It also retrieves from the model various types and categorises them by properties, such as whether they are requests or responses (we defined this as a boolean property of Class in our metamodel for this reason). Operations declared on type Class in this script are used to derive the variables that will be passed to each template from the model element's properties.
To make this clearer, let's look at an example. Take the QueryParamsRequest rule. Think of the transform and in keywords as being like an enhanced for loop. The input collection,, in this case,, comes from the queryParamsRequestTypes computed in pre. In other cases (for example, the Enum rule) it comes from all instances of a given type in the model. For each model element (in our example, bound to the variable request), the parameters are obtained from a utility method. This binds variable names to be used in the template to the properties of request - note that the operations used self as the operation is declared on the type Class, which has the attributes we're looking to use. The template is a relative path to the EGL template we want to invoke for this rule. Finally, the target is the file we want to write the results to. By default, EGX overwrites the file if it exists, but this is configurable.
Hopefully, this is starting to make sense! You can see how, with EGX, we can choose which templates to invoke based on model element types and how those templates' variables are derived from the model. This coordination logic is really the centerpiece of the approach. To run it, we just feed the template the model(s) we want and get the output.
This article has briefly explained the MDE approach taken to help with the specific case of generating boilerplate for the Java SDK. Whilst I hope the value it adds is apparent, you may be more curious about the development process and lessons learned from this exercise. In the third and final part of this series, I will reflect on the approach and provide some key takeaways to bear in mind if you decide to go this route for your projects.
If you have any comments or suggestions, feel free to reach out to us on X, formerly known as Twitter or drop by our Community Slack. I hope this article has been useful and I welcome any thoughts/opinions. If you enjoyed it, please check out my other Java articles.
Share:
Sina is a former member of the Vonage Team. He was a Java Developer Advocate at Vonage. He comes from an academic background and is generally curious about anything related to cars, computers, programming, technology and human nature. In his spare time, he can be found walking or playing competitive video games.