
Share:
Sina is a former member of the Vonage Team. He was a Java Developer Advocate at Vonage. He comes from an academic background and is generally curious about anything related to cars, computers, programming, technology and human nature. In his spare time, he can be found walking or playing competitive video games.
Boost Your Productivity With Model-Driven Engineering (Part 1)
Time to read: 10 minutes
When asked about our occupation, we, as developers, are not short of choices for words. We may describe ourselves in various ways: "Software Developer", "Computer Programmer", "Computer Scientist", "Coder", "Software Engineer" or other more specialist roles, like "Software Architect", "DevOps Engineer", "Developer Advocate", etc. We sometimes use these terms interchangeably or choose the one that resonates with us the most. But when you think about it, is "Computer Programmer" really the same thing as a "Software Engineer"? In many cases, it can be. I, like many, if not most developers, thoroughly enjoy programming profusely. It is undoubtedly the cornerstone of our profession and the thing that attracted many of us to this line of work.
However, it is important to acknowledge that this field is built upon abstractions. On the surface, the job of a computer programmer has changed drastically since its earliest days of punchcards. Most of us do not know Assembly or even C - then (and still now) considered a "high-level" programming language. The task of a programmer (or "coder") is ultimately to relay instructions to the underlying hardware to perform some operations. However, this is not how most of us think of our jobs day to day. Instead, we think at a higher level of abstraction - in terms of solutions. Thus, programming, as fun and challenging as it may be, is a means to an end. Hence, the term "Software Engineer" is a more inclusive catch-all for the entire development process. If software engineering is like building a house, then programming is the brick-laying part of it.
Unfortunately, programming is not always fun or conducive to problem-solving. Especially in the case of verbose languages like Java, it is often a chore. This is a result of boilerplate: code that is repetitive and tedious to write by hand, but still necessary and useful. This is often the least productive aspect of programming and, coincidentally, the most automatable. Although IDEs are good at generating common boilerplate, like getters and setters, toString(), equals and hashCode(), they can only cater to common generic needs of the language, not the domain. If only there was a way to cut out the tedious process of hand-writing domain-specific boilerplate...
Model-Driven Engineering (MDE) is a discipline that promotes models to be first-class artifacts in the engineering process, raising the level of abstraction in doing so. When applied to software engineering, this means that instead of source code being the primary artifact of interest, we instead care more about the domain model.
Although MDE is often an academic term and discipline, it has gained more widespread attention through the term "low-code" - something which academics are also aware of. One may argue that MDE is broader in scope than the low-code movement, but in practice, these differences in semantics are often of academic interest - pardon the pun!
So, you may be wondering: what is a model? Well, it's anything that declaratively describes the domain. You can think of a model as domain-specific data. The crucial thing is that this data is structured in a predictable way. In MDE-speak, we call this structure the metamodel. The metamodel is itself a model that describes the "blueprint" for the domain – similar to how an architect's blueprint provides a guide to the construction of a building. To make this clearer, let's consider some examples.
The idea of a metamodel is to restrict what can be expressed when using general-purpose tools and languages. Examples of metamodelling technologies include XML Schema (XSD), JSON Schema or any database schema. That's right: if you've ever worked with a relational database, an XML document, or any sort of configuration file, you're already familiar with this concept, even though you may not have thought of it in such terms.
There are plenty of examples available, though for brevity and illustrative purposes, I will not provide them here directly. But when you start thinking of schemas as metamodels and structured data conforming to those schemas as models, it might make sense intuitively. Consider the "CustomersOrders.xsd" file from this tutorial. That file is effectively modelling the domain concepts and how they relate to each other. The "CustomersOrder.xml" file is an instance of this - a model that conforms to the "CustomersOrders.xsd" metamodel. If you're familiar with object-oriented programming, you can think of metamodels as Classes and models as Objects (i.e. instances of those classes). In object-oriented programming, a class defines the schema for concrete instances (objects). Another example is this minimal JSON Schema. It defines a Person which has three properties: firstName, lastName and age.
In both of these cases, did you notice that the metamodel itself is written in the same language as the model? That is, an XSD file uses the same syntax as XML, and a JSON Schema is itself written in JSON! The corollary of this is that metamodels themselves are models which conform to a meta-metamodel. Mind-blowing, right? In other words, there is a schema for the metamodel. Thankfully in most cases, this top-level meta-metamodel is usually where it stops. Meta-metamodels usually conform to themselves. No joke - there is literally an XSD file which defines the metamodel for XSDs!
Having defined the main concept in model-driven engineering, let us now turn to some tooling. Although schemas and models can (and often are) defined using conventional tools and serialisation formats such as JSON and XML, to really embrace MDE, it would be beneficial to be familiar with dedicated tools used by MDE professionals. Due to the history of MDE, with its heavily academic and enterprise roots, the Eclipse Foundation is widely considered to be the home platform for the most well-established MDE tools. Central to this is the Eclipse Modelling Framework (EMF). At its core, the project defines a framework for defining metamodels and tooling to work with them programmatically in Java. As you may have guessed, it includes the meta-metamodel - called Ecore. Here is a simplified diagram of Ecore's main concepts and hierarchy:
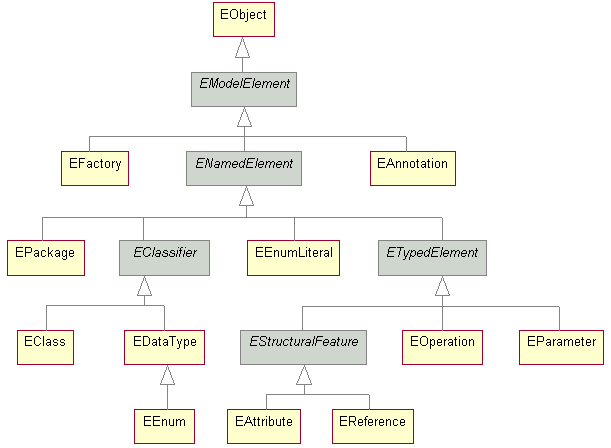
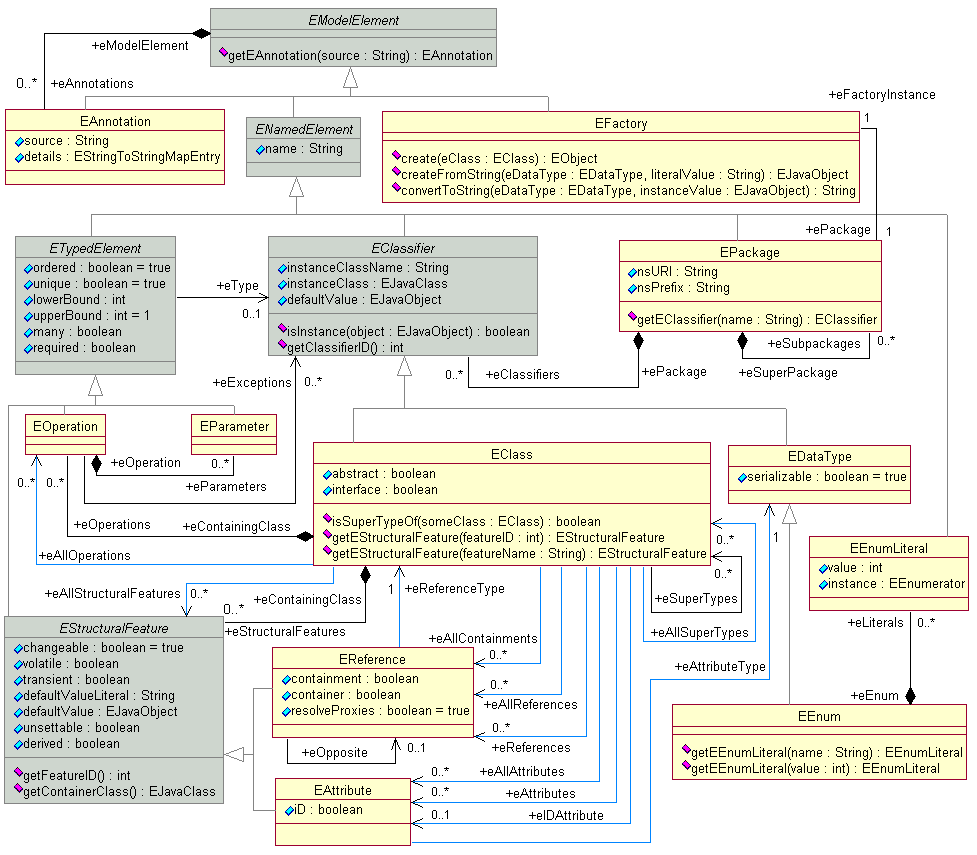
There is a lot more to it, of course - here's a more detailed UML digram. But don't worry - it's not something you need to know. These are concepts that will become intuitive when using Ecore to define your metamodel. There are of course tutorials available online for EMF, although some may be quite dated. They are still relevant as EMF has been stable for a long time.
{kind=link}
You can define Ecore metamodels using the built-in tree editor, visual languages like UML, or textual ones like Emfatic, which is much easier to work with than the XML, which underpins all Ecore metamodels. Enterprise-grade tools like Papyrus and Sirius are built on top of EMF and provide more powerful facilities for working with models. You can even define your metamodel as a grammar for a domain-specific language using Xtext.
That is a lot to take in! The idea is to give you an overview of the tools and technologies available. As you can see, MDE tooling and its principles are quite rich, well-established, and relatively mature. You can define your models and metamodels graphically or textually, and because a lot of tooling is built on top of EMF, once you've defined your metamodel, you can generate Java code from it and work with it programmatically if you wish.
Now that you are familiar with metamodelling and tools that can be used to define (meta)models, you may be rightfully asking: so what? What can I do with these models? Why spend all this time and effort defining a schema that ultimately limits what I can express using a general language? Well, that's where the real value of MDE comes in. The metamodel is necessary in order for you to be able to work with models at an abstract level. Model Management is the process of acting upon models. These tasks include the following:
Visualisation: Presenting different views and graphical representations of a model for various purposes and audiences.
Querying: Obtaining data from the model, oftentimes involving computationally intensive expressions.
Validation: Metamodels are often not powerful enough to express all the constraints pertaining to a domain model, so additional programmatic logic is needed to ensure models are well-formed.
Comparison: Comparing models and acting upon differences programmatically.
Merging: Taking multiple input models and producing a single output model.
Migration: Mapping a model to an evolved version of the metamodel.
Transformation: Modifying a model or producing a different output model (which may conform to a different metamodel).
Text Generation: Using model(s) to generate textual output, such as source code and documentation.
As you may have guessed, there is also tooling for all of these tasks. The de-facto language used for validating models beyond the capabilities of Ecore is the Object Constraint Language (OCL). You can learn more about it from an introductory tutorial, so I won't dwell on the specifics here. However, it's useful to be aware that a lot of other model management languages build on top of or are inspired by OCL's expressions, syntax, and semantics. The literature on model-to-model transformations is vast and often quite complex, as it is the central area of research area in academia for MDE. There are, of course, languages for model transformations, such as ATL and QVT, but we won't dwell on those.
So as a developer, what do we really care about? Productivity, right? That is the premise of the entire discussion. Since much of our day-to-day is taken up with writing documentation and boilerplate code, what we want is to auto-generate as much of this as possible so we can focus on the fun stuff and the parts that require more attention/engineering expertise. This is where model-to-text transformation can help. There are standards, such as MOF M2T and tools conforming to them such as Acceleo, but you may be familiar with more conventional tools such as Jakarta Server Pages (JSP). Whilst Java on the web sounds like a relic from the early 2000s, the principle behind it is still valid. After all, the PHP language literally stands for "Hypertext Preprocessor" and is still widely used. But what do JSP and PHP have to do with code generation and model-driven engineering? That's where we'll pick up on part 2 of this blog post. Before that, let's take a look at a tool that will actually be used to demonstrate this.
We've briefly covered the main concepts in MDE and some tooling, but how does it all tie together? We have different metamodelling technologies, so models can be in various formats, yet most of the tooling I've mentioned so far is based on EMF. Moreover, since each model management task has its own tool, with varying syntax and semantics for defining the querying/transformation logic, it may seem that MDE is too complex and heavyweight given the steep learning curve. However, there is one project (Eclipse-based, naturally) that aims to unify the various modelling technologies and model management tasks: Epsilon. Full disclosure: I contributed to Epsilon extensively during my PhD so of course I'm going to be a bit biased!
I won't spend long explaining Epsilon and its architecture - instead leaving that to the documentation, though I'll provide a brief introduction. Basically, Epsilon provides a family of task-specific model management languages built on top of a common core query language called EOL. This is inspired by OCL's syntax but behaves much more like Java since it is implemented in Java and makes heavy use of Java's reflection capabilities. You can even call native Java code from EOL, so essentially, EOL is a complete programming language with all the usual imperative programming constructs, as well as declarative operations for working with collections.
Crucially, Epsilon also supports multiple modelling technologies and is not bound to EMF. Although it has very strong support for EMF models and integrates with other EMF tooling, its Model Connectivity Layer means that the languages are decoupled from the underlying model persistence format, so you can use it with various types of models such as XML, CSV and other spreadsheet formats, JDBC-compliant databases. Simulink and more. Thus, Epsilon provides an all-in-one solution for model management without having to work with different tools based on the modelling technology. You can even combine multiple models of different types within the same program and work with them in a uniform way.
Phew, that's a lot to take in! But I promise in the next part, it will all come together through a practical example. Specifically, I will demonstrate how I used Epsilon to effectively automate writing a huge chunk of boilerplate code for the Vonage Java SDK.
If you have any comments or suggestions, feel free to reach out to us on X, formerly known as Twitter or drop by our Community Slack. I hope this article has been useful and I welcome any thoughts/opinions. If you enjoyed it, please check out my other Java articles.
Share:
Sina is a former member of the Vonage Team. He was a Java Developer Advocate at Vonage. He comes from an academic background and is generally curious about anything related to cars, computers, programming, technology and human nature. In his spare time, he can be found walking or playing competitive video games.