Transcriptions après appel
Tarification
Le prix de la transcription, avec ou sans résumé, est de 0,04510 $ / 0,04100 € par minute, quel que soit le nombre de participants. Seuls les frais d'archivage individuels seront applicables.
Aperçu des fonctionnalités
La transcription après appel peut contribuer à améliorer la tenue des dossiers, le service à la clientèle, la productivité et l'analyse des données. Les serveurs Video API de Vonage génèrent des transcriptions après appel en utilisant l'intelligence artificielle et d'autres technologies de pointe.
Vous activez les transcriptions lorsque vous démarrez une archive à l'aide de l'API REST.
Une fois l'enregistrement des archives terminé, la transcription sera disponible sous la forme d'un fichier JSON.
Activation de la transcription lors du démarrage d'une archive
Lorsque vous utilisez l'API Video REST de Vonage pour démarrer une archive, définissez le paramètre hasAudio et hasTranscription propriétés à true dans les propriétés JSON que vous avez envoyées à la méthode REST de démarrage de l'archive :
Vous pouvez également inclure un élément facultatif transcriptionProperties avec un objet hasSummary (booléen) et/ou primaryLanguageCode (Chaîne). Lors de la définition des propriétés hasSummary à true, il inclura un résumé généré par l'IA dans la transcription. Si la valeur est fausse ou manquante (la valeur par défaut est false), le résumé de la transcription ne sera pas inclus. Si la transcription est pour une autre langue que "en-US" (par défaut), configurez la propriété primaryLanguageCode avec un code langue supporté.
Set (jeu de mots) outputMode (dans les données POST) à "individual". Les transcriptions sont disponibles pour archives de flux individuels seulement.
Définir la valeur de application_id à votre ID d'application. Définissez la valeur de json_web_token à un jeton web JSON (voir la section Authentification de l'API REST documentation).
Pour d'autres options d'archivage, voir la documentation de l'option Démarrer la méthode REST d'archivage.
La réponse à un appel à la méthode REST "start archive" comprendra les éléments suivants hasTranscription et transcription en plus des autres propriétés documentées de la réponse :
{
"createdAt" : 1384221730555,
"duration" : 0,
"hasAudio" : true,
"hasVideo" : true,
"id" : "b40ef09b-3811-4726-b508-e41a0f96c68f",
"name" : "The archive name you supplied",
"outputMode" : "individual",
"applicationId" : "12345abc",
"reason" : "",
"resolution" : "640x480",
"sessionId" : "flR1ZSBPY3QgMjkgMTI6MTM6MjMgUERUIDIwMTN",
"size" : 0,
"status" : "started",
"streamMode" : "auto",
"hasTranscription" : true,
"transcription" : {
"hasSummary": true,
"primaryLanguageCode": "ja-JP",
"reason": "",
"status": "requested",
"url": ""
}
}
Voir Obtenir l'état de la transcription pour obtenir des informations sur l'obtention dynamique des détails de la transcription.
Dans un session automatiquement archivéela transcription ne sera pas lancée automatiquement. Vous devez lancer une deuxième archive, en utilisant l'option multiArchiveTag pour la transcription (voir Archives simultanées).
La prise en charge des transcriptions est actuellement disponible avec l'API Video REST de Vonage et peut être activée et gérée par le biais des SDK de Vonage Server.
Obtenir l'état de la transcription
La réponse aux méthodes REST pour archives des listes et recherche d'informations dans les archives comprendra hasTranscription et transcription propriétés :
{
"id" : "b40ef09b-3811-4726-b508-e41a0f96c68f",
"event": "archive",
"createdAt" : 1723584124,
"duration" : 328,
"name" : "the archive name",
"partnerId" : "123456abc",
"reason" : "",
"sessionId" : "2_MX40NzIwMzJ-flR1ZSBPERUIDIwMTN-MC45NDQ2MzE2NH4",
"size" : 18023312,
"status" : "uploaded",
"hasTranscription" : true,
"transcription": {
"status": "available",
"url": "URL for downloading the transcription, if available",
"reason": "The reason for failure, if status is set to failed",
"hasSummary": true,
"primaryLanguageCode": "The configured language code"
}
}
Les hasTranscription est un booléen qui indique si la transcription est activée pour l'archive.
Les transcription un objet ayant les propriétés suivantes :
status(Chaîne) - Le statut de la transcription, qui peut prendre l'une des valeurs suivantes :"requested"- LehasTranscriptiona été fixée àtruependant l'appel d'archives de démarrage, mais la transcription n'a pas commencé."failed"- La transcription a échoué. Vérifier lareasonpour plus d'informations."started"- La transcription est en cours."available"- La transcription peut être téléchargée à partir de Vonage. Vérifier laurlpropriété."uploaded"- La transcription est disponible au téléchargement à partir du seau S3 ou du conteneur Azure que vous avez indiqué dans votre compte Video API. Recherchez une transcription.zip dans le dossier archive ID de votre cible de stockage d'archives. Voir Stockage d'archives.
url(Chaîne) - L'URL pour le téléchargement de la transcription, si l'optionstatusest fixé à"available".reason(Chaîne) - La raison de l'échec de la transcription, si l'erreur de transcription a été corrigée.statusest fixé à"failed".hasSummary(Booléen) - Indique si un résumé généré par l'IA est inclus dans la transcription.primaryLanguageCode(Chaîne) - Le code de langue configuré pour la transcription.
Vous pouvez également définir un rappel de l'état de l'archive pour la fonction votre compte Video API. Voir Changement de statut des archives. Les données du rappel comprendront également hasTranscription et transcription propriétés.
Format de transcription
La transcription est fournie sous la forme d'un fichier ZIP compressé. Le fichier non compressé est un fichier texte avec des données JSON.
La transcription comprend des segments de texte individuels. Chaque segment correspond à un canal audio individuel (provenant d'un des flux audio de la session).
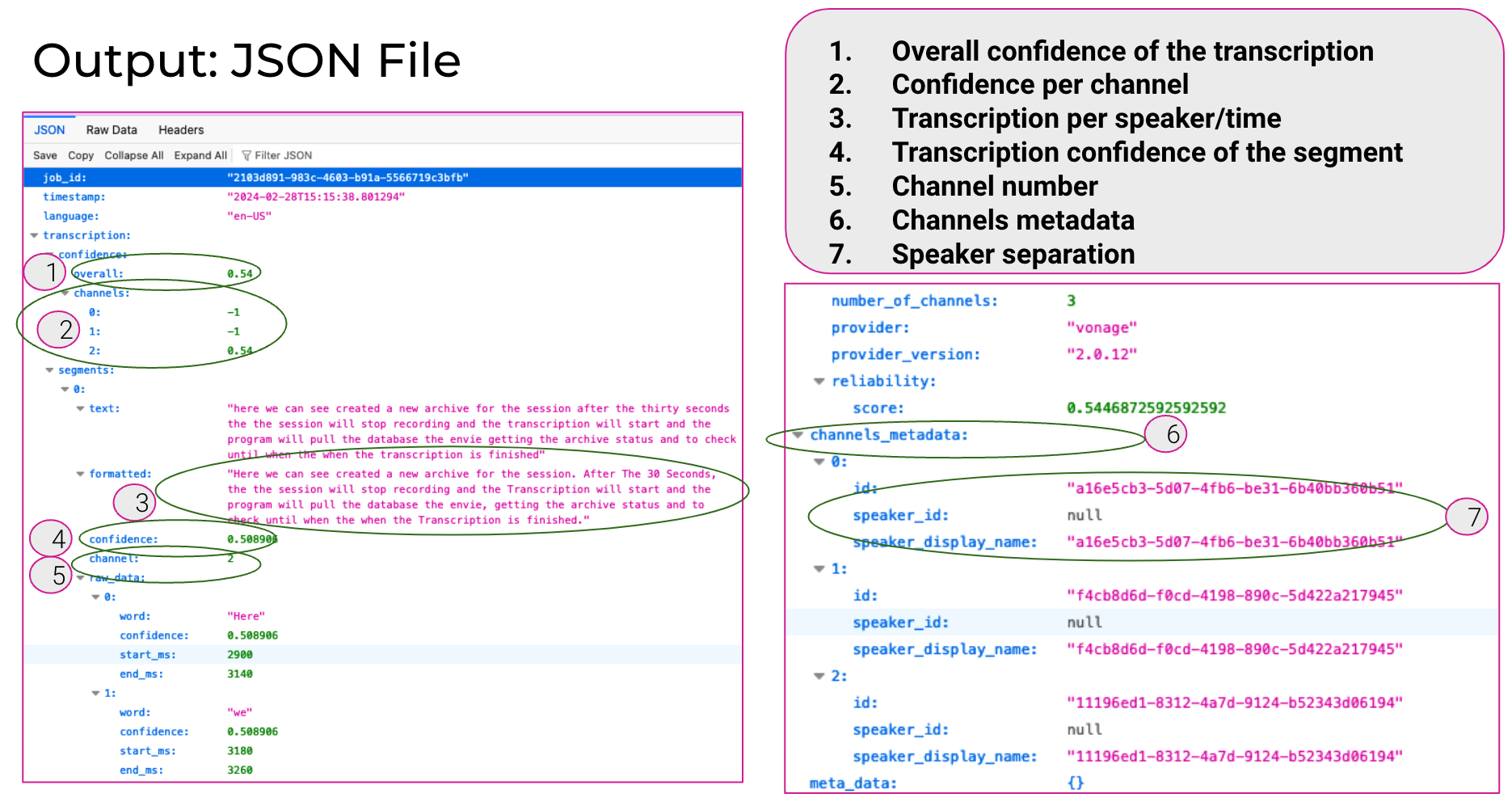
Le JSON possède les propriétés de premier niveau suivantes :
job_id- Un identifiant unique pour la transcription.timestamp- Chaîne de date ISO 8601 indiquant la date de création du fichier de transcription.number_of_channels- Le nombre de canaux audio individuels de l'archive inclus dans la transcription.reliability- Un objet doté d'une propriété :score. Lesscoreest un nombre indiquant la fiabilité globale estimée de la transcription (de 0 à 1,0).summary- Si vous réglez lehasSummaryde la propriététranscriptionPropertiesà l'objettruelors du démarrage de l'archive, cette propriété est incluse. Elle est définie comme un résumé de la transcription généré par l'IA.confidence- Un objet avec deux propriétés :overalletchannels. Lesoverallest la confiance estimée de l'ensemble de la transcription (de 0 à 1,0). La propriétéchannelsest un tableau listant la confiance estimée de chaque canal dans la transcription.channels_metadata- Un tableau d'objets définissant chaque canal audio. Chaque objet est unidqui est l'identifiant du flux vidéo. Vous pouvez ajouter des données d'identification de la connexion lorsque vous créer un jeton client pour chaque utilisateur. Vous pouvez utiliser rappels de suivi de session pour obtenir les identifiants de flux et les données de connexion de chaque flux. Vous pouvez ensuite les utiliser pour identifier l'utilisateur du flux dans la transcription.segments- Un objet contenant des segments individuels dans la transcription. Chaque objet segment possède les propriétés suivantes :text- Le texte transcrit de la séquence.formatted- Le texte formaté (avec la ponctuation) du segment.confidence- Un nombre, compris entre 0 et 1,0, représentant la confiance estimée de la transcription du segment.channel- L'entier identifiant le canal audio pour le segment.
raw_data- Un tableau d'objets pour chaque mot du segment de transcription. Chaque objet comprend les propriétés suivantes :word- Le mot.confidence- Un nombre, compris entre 0 et 1,0, représentant la confiance estimée du mot transcrit.start_ms- Le décalage du début du mot par rapport au début de la transcription, en millisecondes.end_ms- Le décalage de la fin du mot par rapport au début de la transcription, en millisecondes.
Télécharger les transcriptions
Il existe deux façons de télécharger le fichier de transcription d'une archive : via l'API REST ou via le tableau de bord du développeur.
Téléchargement via l'API REST
Vous pouvez télécharger le fichier de transcription d'une archive spécifique en appelant la fonction Récupérer des informations sur les archives Méthode REST et en vérifiant le transcription.url dans la réponse. Si la propriété transcription.status est fixée à "available" ou "uploaded", le transcription.url contient une URL pour le téléchargement du fichier de transcription.
Utilisez une requête HTTP GET pour télécharger le fichier de transcription à partir de l'URL. Par exemple, le fichier de transcription peut être téléchargé à l'aide d'une requête HTTP GET :
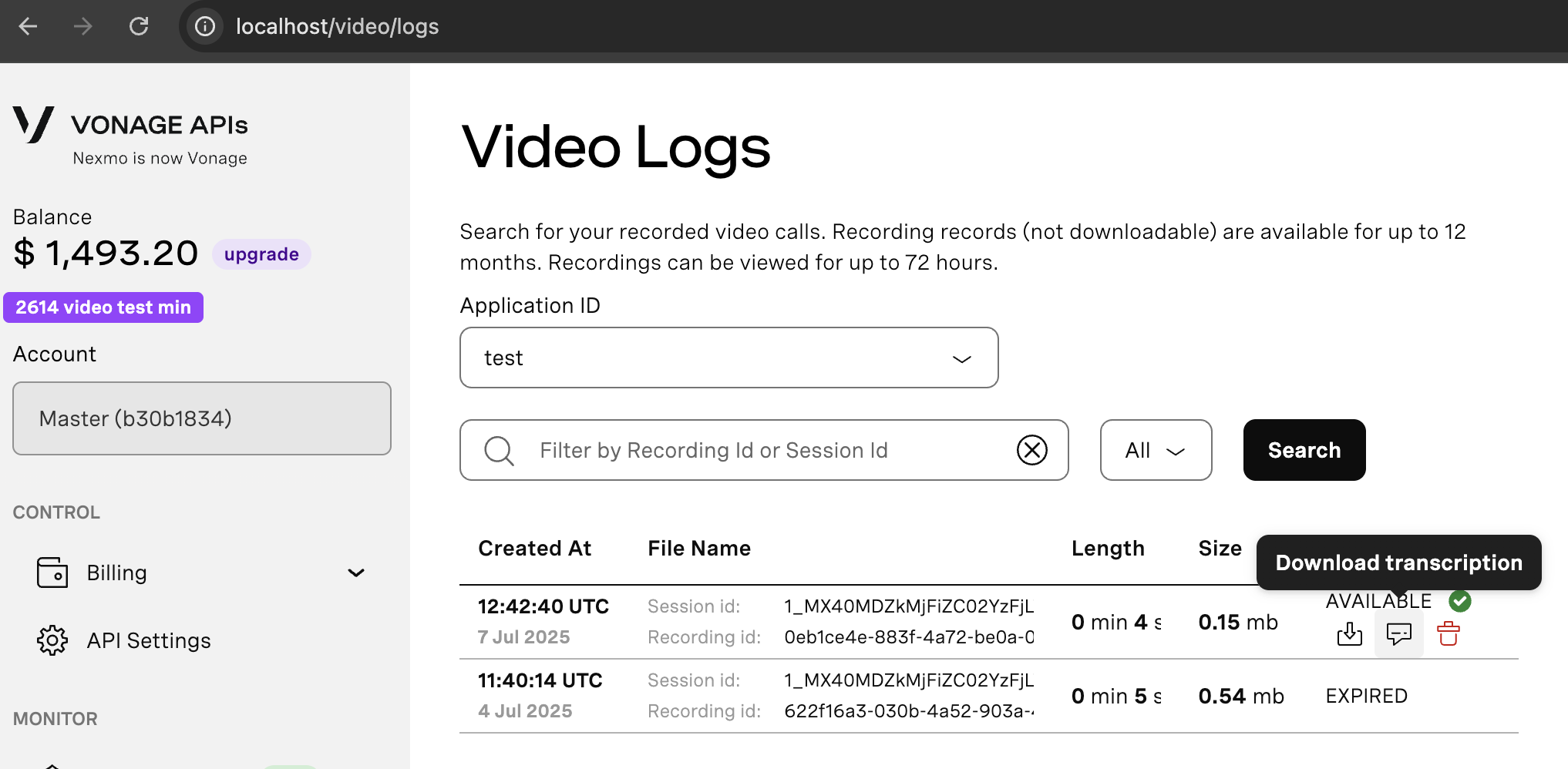
Télécharger via le tableau de bord du développeur
Vous pouvez télécharger la transcription d'un appel spécifique si l'option stockage de secours a été activée en suivant les étapes suivantes :
- Ouvrez le tableau de bord du développeur et naviguez vers Journaux vidéo.
- Sélectionnez une application dans la liste des applications et cliquez sur recherche. Optionnellement Vous pouvez fournir ID d'enregistrement ou ID de la session pour réduire les résultats.
- Dans la liste des résultats, recherchez la session concernée.
- Passez la souris sur le Statut pour cette session et cliquez sur le bouton Télécharger la transcription bouton.
Limites/problèmes connus
Les transcriptions ne sont disponibles que pour les archives de flux individuels, pas pour les archives composées.
Les transcriptions ne sont pas compatibles avec les archives cryptées.
Cette fonctionnalité est actuellement prise en charge par l'API Video REST de Vonage, et non par les SDK du serveur Video de Vonage.
La durée maximale d'une transcription est de 120 minutes.
La transcription après appel n'est pas entièrement conforme à toutes les normes de l'Union européenne. Zones médiatiques régionales (voir ci-dessous).
| Regional Media Zone Support | Available |
|---|---|
| USA | Yes |
| EU | Yes |
| Canada | Based on requirement |
| Germany | Based on requirement |
| Australia | Based on requirement |
| Japan | Based on requirement |
| South Korea | Based on requirement |
| Singapore | Based on requirement |
Questions fréquemment posées
- Combien de flux peuvent être analysés au cours d'une même session ?
- Jusqu'à 50 flux avec un maximum de 120 minutes transcrites.
- La transcription après appel fonctionne-t-elle avec les sessions acheminées et relayées ?
- La fonction de transcription après appel est destinée aux sessions acheminées qui utilisent les serveurs Vonage Media.
- En cas d'échec du téléchargement de la transcription vers le seau S3 configuré par le client, le mécanisme de réessai ou de repli fonctionne-t-il de la même manière que pour le téléchargement des archives ?
- Oui, le mécanisme de relance pour le PCT fonctionne exactement de la même manière que pour les téléchargements d'archives ordinaires.
- Dans les cas où la transcription retombe et est téléchargée sur le nuage de Vonage, le client devra-t-il utiliser une requête HTTP GET pour obtenir le lien de téléchargement de la transcription ?
- Lorsque le statut de la transcription change, le client doit recevoir un rappel contenant l'URL de téléchargement. Si aucun rappel n'est enregistré, le lien de téléchargement ne peut être récupéré qu'au moyen d'une requête HTTP GET.
- Une fois que le lien de téléchargement de la transcription est reçu, il permet un téléchargement direct. Est-il prévu d'introduire une authentification pour le téléchargement de la transcription ?
- Il n'est pas prévu d'introduire une authentification pour le lien. Le lien de téléchargement a une courte durée d'expiration. S'il n'est pas consulté dans ce délai, une nouvelle demande doit être faite pour obtenir un nouveau lien.
- Bien que plusieurs utilisateurs aient participé à la session, le fichier de transcription est un fichier JSON unique. Comment différencier les utilisateurs ?
- Chaque entrée de transcription dans le fichier est associée à un numéro de canal spécifique, attribué à chaque flux. Le fichier comprend également
channels_metadataqui fournit des informations sur l'ID de flux correspondant à chaque ID de canal.
- Chaque entrée de transcription dans le fichier est associée à un numéro de canal spécifique, attribué à chaque flux. Le fichier comprend également
Langues prises en charge
| Langue | Code |
|---|---|
| Afrikaans (Afrique du Sud) | af-ZA |
| Amharique (Éthiopie) | am-ET |
| Arabe (Émirats arabes unis) | ar-AE |
| Arabe (Bahreïn) | ar-BH |
| Arabe (Algérie) | ar-DZ |
| Arabe (Égypte) | ar-EG |
| Arabe (Israël) | ar-IL |
| Arabe (Irak) | ar-IQ |
| Arabe (Jordanie) | ar-JO |
| Arabe (Koweït) | ar-KW |
| Arabe (Liban) | ar-LB |
| Arabe (Maroc) | ar-MA |
| Arabe (Mauritanie) | ar-MR |
| Arabe (Oman) | ar-OM |
| Arabe (Territoires palestiniens) | ar-PS |
| Arabe (Qatar) | ar-QA |
| Arabe (Arabie Saoudite) | ar-SA |
| Arabe (Syrie) | ar-SY |
| Arabe (Tunisie) | ar-TN |
| Arabe (Yémen) | ar-YE |
| Azerbaïdjanais (Azerbaïdjan) | az-AZ |
| Bulgare (Bulgarie) | bg-BG |
| Bengali (Bangladesh) | bn-BD |
| Bengali (Inde) | bn-IN |
| Bosniaque (Bosnie-Herzégovine) | bs-BA |
| Catalan (Espagne) | ca-ES |
| Tchèque (République tchèque) | cs-CZ |
| Danois (Danemark) | da-DK |
| Allemand (Autriche) | de-AT |
| Allemand (Suisse) | de-CH |
| Allemand (Allemagne) | de-DE |
| Grec (Grèce) | el-GR |
| Anglais (Australie) | fr-AU |
| Anglais (Canada) | fr-CA |
| Anglais (Royaume-Uni) | fr-GB |
| Anglais (Ghana) | fr-GH |
| Anglais (Hong Kong) | fr-HK |
| Anglais (Irlande) | fr-IE |
| Anglais (Inde) | fr-IN |
| Anglais (Kenya) | en-KE |
| Anglais (Nigeria) | fr-NG |
| Anglais (Nouvelle-Zélande) | fr-NZ |
| Anglais (Philippines) | fr-PH |
| Anglais (Pakistan) | fr-PK |
| Anglais (Singapour) | fr-SG |
| Anglais (Tanzanie) | fr-TZ |
| Anglais (États-Unis) | en-US |
| Anglais (Afrique du Sud) | fr-ZA |
| Espagnol (Argentine) | es-AR |
| Espagnol (Bolivie) | es-BO |
| Espagnol (Chili) | es-CL |
| Espagnol (Colombie) | es-CO |
| Espagnol (Costa Rica) | es-CR |
| Espagnol (République dominicaine) | es-DO |
| Espagnol (Équateur) | es-EC |
| Espagnol (Espagne) | es-ES |
| Espagnol (Guatemala) | es-GT |
| Espagnol (Honduras) | es-HN |
| Espagnol (Mexique) | es-MX |
| Espagnol (Nicaragua) | es-NI |
| Espagnol (Panama) | es-PA |
| Espagnol (Pérou) | es-PE |
| Espagnol (Porto Rico) | es-PR |
| Espagnol (Paraguay) | es-PY |
| Espagnol (El Salvador) | es-SV |
| Espagnol (États-Unis) | es-US |
| Espagnol (Uruguay) | es-UY |
| Espagnol (Venezuela) | es-VE |
| Estonien (Estonie) | et-EE |
| Basque (Espagne) | eu-ES |
| Persan (Iran) | fa-IR |
| Finlandais (Finlande) | fi-FI |
| Français (Belgique) | fr-BE |
| Français (Canada) | fr-CA |
| Français (Suisse) | fr-CH |
| Français (France) | fr-FR |
| Galicien (Espagne) | gl-ES |
| Gujarati (Inde) | gu-IN |
| Hindi (Inde) | hi-IN |
| Croate (Croatie) | hr-HR |
| Hongrois (Hongrie) | hu-HU |
| Arménien (Arménie) | hy-AM |
| Indonésien (Indonésie) | id-ID |
| Islandais (Islande) | is-IS |
| Italien (Suisse) | it-CH |
| Italien (Italie) | it-IT |
| Hébreu (Israël) | iw-IL |
| Japonais (Japon) | ja-JP |
| Javanais (Indonésie) | jv-ID |
| Géorgien (Géorgie) | ka-GE |
| Kazakh (Kazakhstan) | kk-KZ |
| Khmer (Cambodge) | km-KH |
| Kannada (Inde) | kn-IN |
| Coréen (Corée du Sud) | ko-KR |
| Lao (Laos) | lo-LA |
| Lituanien (Lituanie) | lt-LT |
| Letton (Lettonie) | lv-LV |
| Macédonien (Macédoine du Nord) | mk-MK |
| Malayalam (Inde) | ml-IN |
| Mongol (Mongolie) | mn-MN |
| Marathi (Inde) | mr-IN |
| Malais (Malaisie) | ms-MY |
| Birman (Myanmar) | mon-MM |
| Népalais (Nepal) | ne-NP |
| Néerlandais (Belgique) | nl-BE |
| Néerlandais (Pays-Bas) | nl-NL |
| Norvégien (Norvège) | non-non |
| Polonais (Pologne) | pl-PL |
| Portugais (Brésil) | pt-BR |
| Portugais (Portugal) | pt-PT |
| Roumain (Roumanie) | ro-RO |
| Russe (Russie) | ru-RU |
| Kinyarwanda (Rwanda) | rw-RW |
| Sinhala (Sri Lanka) | si-LK |
| Slovaque (Slovaquie) | sk-SK |
| Slovène (Slovénie) | sl-SI |
| Albanais (Albanie) | sq-AL |
| Serbe (Serbie) | sr-RS |
| Sotho du Sud (Afrique du Sud) | st-ZA |
| Sundanais (Indonésie) | su-ID |
| Suédois (Suède) | sv-SE |
| Swahili (Kenya) | sw-KE |
| Swahili (Tanzanie) | sw-TZ |
| Tamil (Inde) | ta-IN |
| Tamoul (Sri Lanka) | ta-LK |
| Tamoul (Malaisie) | ta-MY |
| Tamoul (Singapour) | ta-SG |
| Telugu (Inde) | te-IN |
| Thaï (Thaïlande) | th-TH |
| Turc (Turquie) | tr-TR |
| Tsonga (Afrique du Sud) | ts-ZA |
| Ukrainien (Ukraine) | uk-UA |
| Urdu (Inde) | ur-IN |
| Urdu (Pakistan) | ur-PK |
| Ouzbek (Ouzbékistan) | uz-UZ |
| Venda (Afrique du Sud) | ve-ZA |
| Vietnamien (Vietnam) | vi-VN |
| Xhosa (Afrique du Sud) | xh-ZA |
| Zulu (Afrique du Sud) | zu-ZA |