
Share:
David is a Software Architect working on Vonage Call Centre, focussing on infrastructure, internal platform and frontend. He has experience across multiple industries including finance, IoT and Cloud Communications.
Self-Service Datastores
Time to read: 4 minutes
Traditionally, datastores have been managed by specialist teams and require a lot of work to set up and manage. This approach can work for monolithic architectures. However, for microservices with a higher rate of change and the aim for each to have their own datastore, this model doesn’t scale. This can make creating microservices expensive and teams become dependent on a centralized team.
The VCC (Vonage Contact Center) technology team’s solution to this problem was to move to a self-service model using automation, enabling teams to carry out many of these tasks themselves. However self-service itself is quite an abstract concept, so our first task was to define what a self-service datastore actually meant for us.
A datastore is “a repository for persistently storing and managing collections of data.” For us, this covers:
Relational Database e.g., MySQL
NoSQL database e.g., DynamoDB
Caches e.g., Redis
Other stores like Elasticsearch
Self-service for these means a team can:
Create and manage their datastore
Make schema changes
Securely make data changes
Support their datastore, including access for debugging and production support
These things by themselves are quite easy to do. However, to avoid creating more problems than we solve, we also need to consider:
Tooling that bakes-in best practice using automated tests and quality gates
Audit trail for all access and changes to ensure compliance
Multi-tenancy barriers and facades (it’s not always economical to have a database cluster per microservice)
Complexity of hot-hot replication, where required
Ease of use, robustness, and hiding internal complexity
Both of the key stakeholders of datastores (teams that operate datastores and feature teams that use datastores) benefit from self-service, but in different ways. Depending on your organizational structure, these could even be the same team! The following two graphs show the scenario of adopting self-service and continuing to improve it vs. doing nothing, over a period of 18 months.
These graphs show our experience of how Business as Usual (BAU) tasks like performing schema migrations, making data changes, etc. impacted teams as the demand for datastores increased over time.
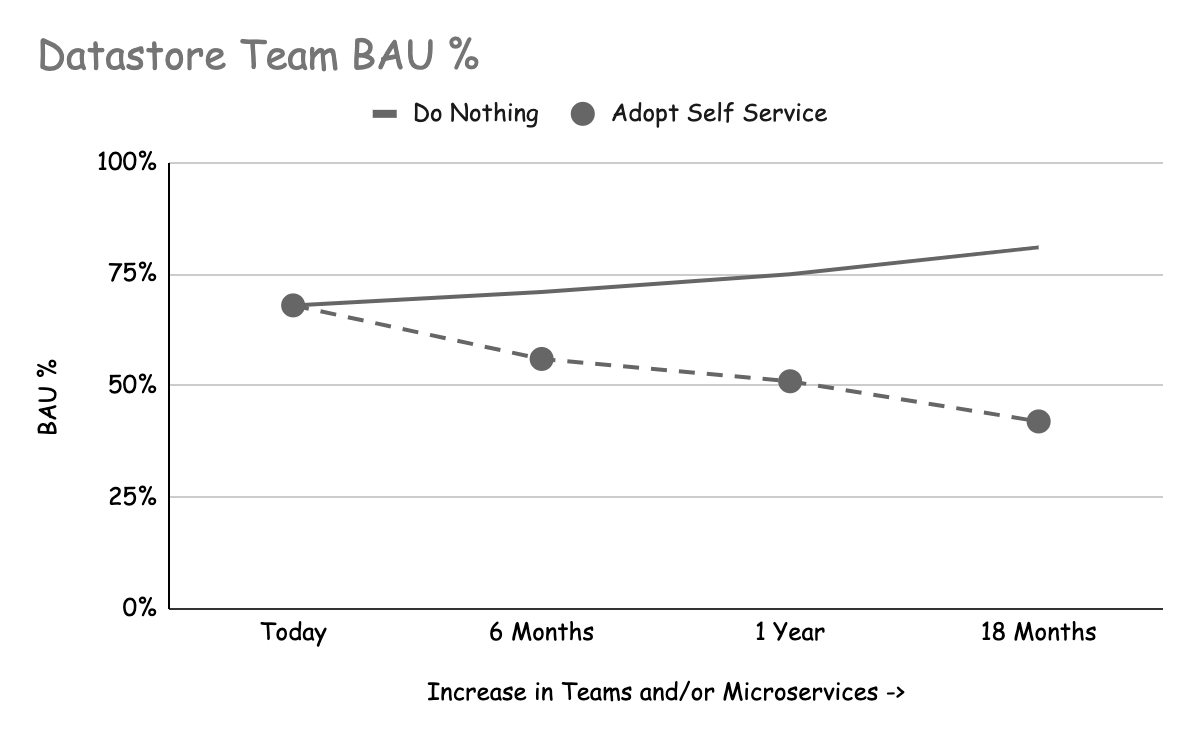 Impact from BAU tasks increases over time
Impact from BAU tasks increases over time
If your organization is growing the number of microservices and/or teams it has then there will come a point where the amount of BAU will overwhelm your datastore team(s). You can address this by adding more people, but it’s likely this won’t scale to keep up with the demand. Pivoting to a self-service strategy will reduce BAU by removing tasks like schema migration, while allowing the datastore team to focus on higher value tasks.
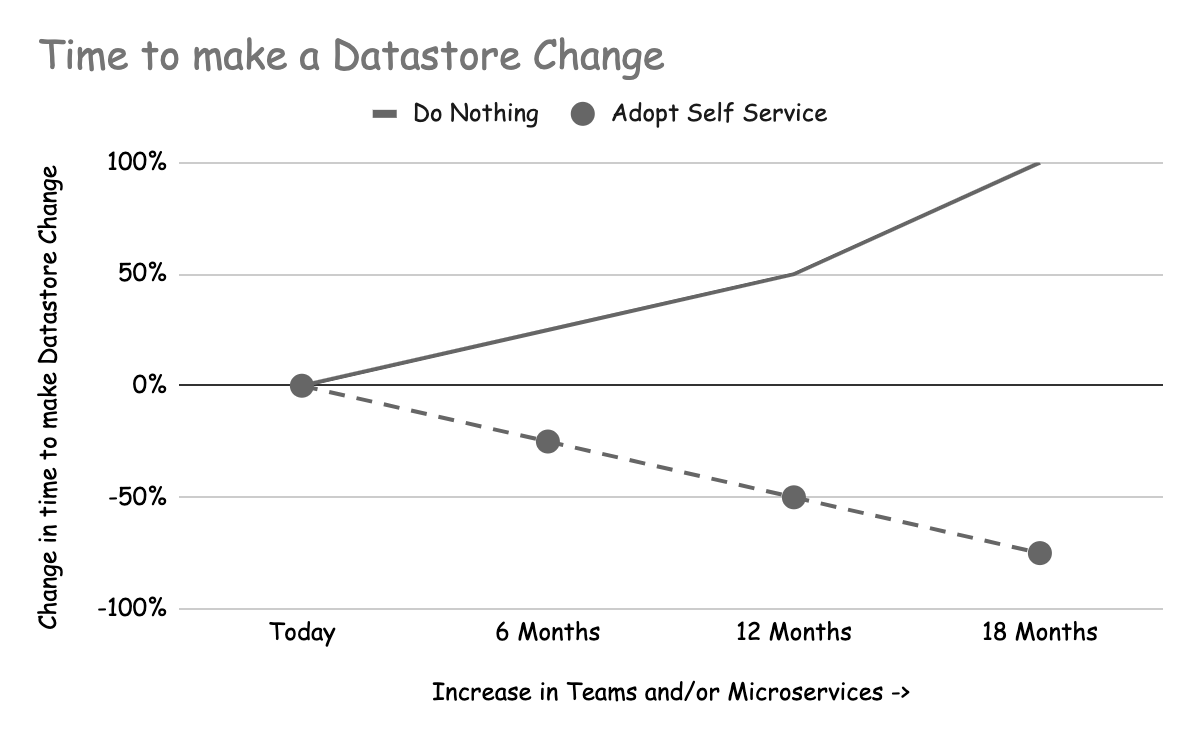 Time to make a datastore change increases over time
Time to make a datastore change increases over time
Feature teams will also benefit from self-service, as making datastores changes will be faster and less costly as you add more self-service capabilities. If feature teams are dependent on a datastore team to make these changes for them, that team can become a bottleneck and increase the cost of changes. This cost is primarily seen in elapsed time. If the datastore team starts to become overwhelmed then feature teams may have to start tracking the changes they’ve requested to make sure they happen.
Now that you understand what a self-service datastore is and why we want them, you’re probably curious what we are doing to move to a self-service model.
Teams working on VCC have adopted self-service for AWS Aurora MySQL, allowing us to automatically create new schemas for services and make schema changes as part of the CI pipeline. It also takes care of providing database credentials and access configuration to microservices.
The process for running the migrations (as shown in the diagram below) involves a lambda that orchestrates creating Docker containers to perform migrations. Messaging is used for communication between the CI system and the schema migration system. The process will also create a database if the schema doesn’t already exist.
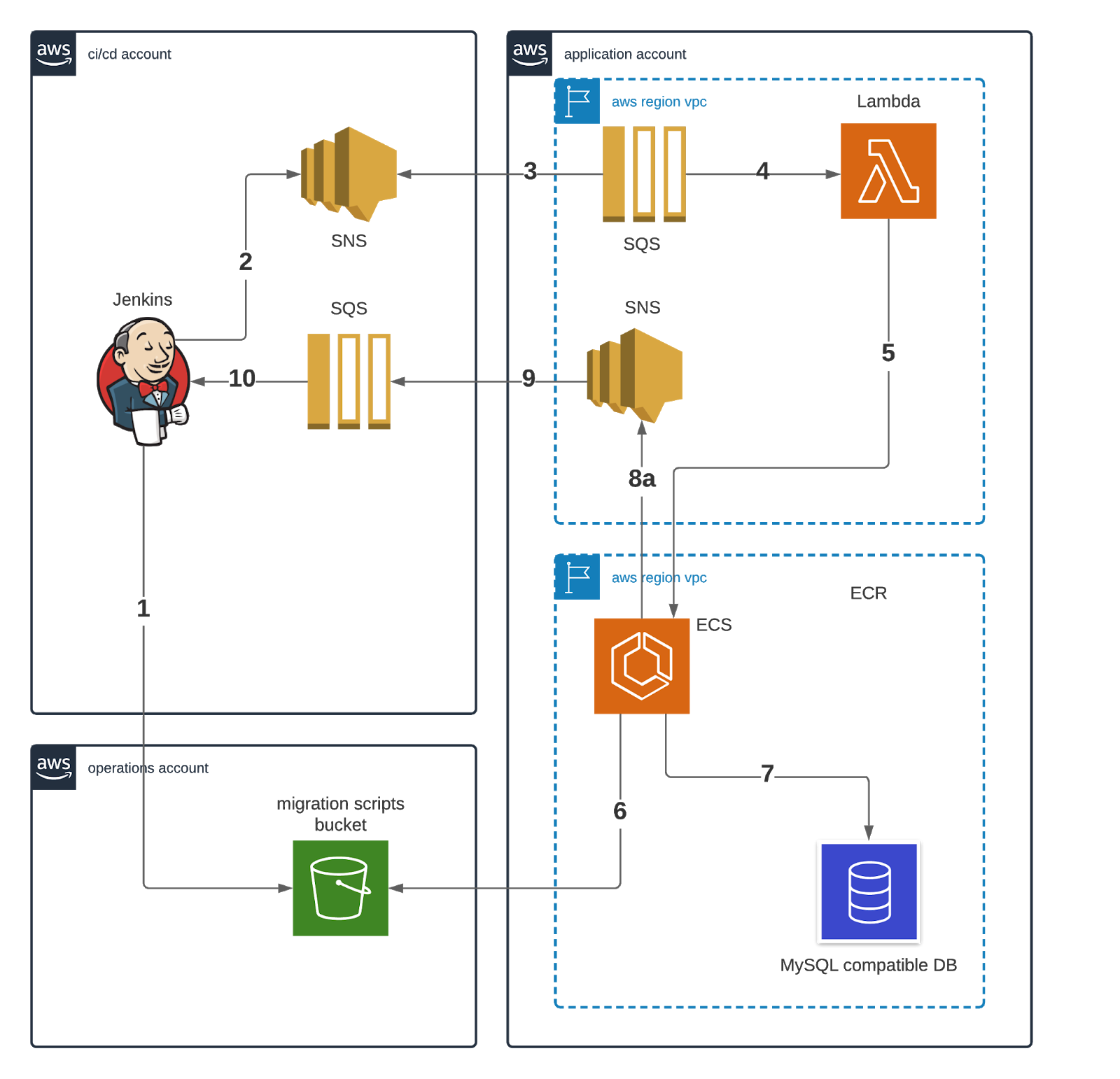
The migration process workflow is that Jenkins requests a new version of a schema to be deployed by (1) uploading the migration to the migration scripts bucket and then (2) publishing to an SNS topic. This is picked up by (3) an SQS, which subscribes to the topic and (4) triggers the schema migration lambda.
The schema migration lambda (5) starts an ECS task whose (6) container pulls the migration from the migration script bucket and then (7) runs flyway using the migration script against the targeted aurora cluster. On completion of the migration (8) the container publishes an SNS message which is (9) picked up by a CI/CD SQS queue which (10) updates the state of the Jenkins job to say it’s completed.
To support this, we’ve also built guidelines around best practice specific to our architecture (e.g., considerations for hot-hot multi-cluster replication and best practices for migrations so teams can avoid common pitfalls).
Next, we’re looking at adding more self-service capabilities, such as enabling self-service data changes, providing more metrics, and tools for detailed query analysis. We want to enable secure low-friction data access with integration into our audit trail. We also need to check that the work we’ve done already has brought the benefits we expect.
Finally, we’re looking into whether other parts of Vonage can leverage the work we’ve done. This is especially relevant as we’re building the Vonage Communications Platform and the common architecture of the internal platforms to underpin it.