Share:
Aaron was a developer advocate at Nexmo. A seasoned software engineer and wannabe digital artist Aaron is frequently found creating things with code, or electronics; sometimes both. You can customarily tell when he's working on something new by the smell of burning components in the air.
Respect API Rate Limits With a Backoff
Time to read: 13 minutes
This article was updated in April 2025
When working with the Vonage Communication APIs—or any API really—you should be cognizant of their rate limits. Rate limits are one of the ways service providers can reduce the load on their servers, prevent malicious activity, or ensure a single user is not monopolizing the available resources.
In this article, we will look at how you can best manage your API calls to ensure you are a “good API citizen”. We will look at how you can respect the Vonage Communication API rate limits while also being efficient and completing your API calls as quickly as allowed.
To buy a virtual phone number, go to your API dashboard and follow the steps shown below.
 Purchase a phone number
Purchase a phone number
Go to your API dashboard
Navigate to BUILD & MANAGE > Numbers > Buy Numbers.
Choose the attributes needed and then click Search
Click the Buy button next to the number you want and validate your purchase
To confirm you have purchased the virtual number, go to the left-hand navigation menu, under BUILD & MANAGE, click Numbers, then Your Numbers
When working with external APIs, we should always attempt to keep our throughput at an acceptable level. But mistakes happen, there might be a sudden surge in usage, and we end up exceeding the rate limit causing our API call to fail.
When this happens, it can be tempting to try again immediately, but doing so is counter-productive. If your API calls are failing because you have hit the rate limit, this is the service telling you to slow down. Immediately trying the same request again is not slowing down and can lead you to be banned from some services. Instead, you should “back off” and pause before trying again.
A backoff is where you wait before taking an action. The amount of time to wait can be calculated using many different strategies, but a few of the most common are:
Constant: wait a constant amount of time between each attempt. For example if we have a constant delay of 1 seconds then our attempts will happen at 1s, 2s, 3s, 4s, 5s, 6s, 7s, etc
Fibonaccial: here we use the Fibonacci number corresponding to the current attempt, making our delays 1s, 1s, 2s, 3s, 5s, 8s, 13s, etc
Exponential: the delay is calculated as 2 to the power of the number of unsuccessful attempts that have been made. For example:
2^1 = 2 = 2
2^2 = 2 * 2 = 4
2^3 = 2 2 2 = 8
2^4 = 2 2 2 * 2 = 16
2^5 = 2 2 2 2 2 = 32
2^6 = 2 2 2 2 2 * 2 = 64
2^7 = 2 2 2 2 2 2 2 = 128
There are other strategies—fixed, linear, polynomial—but for the sake of this article, we’re going to stick with the Exponential backoff strategy provided by the Python backoff package.
I don’t want to trigger Vonage’s API rate limit just to demonstrate the Backoff package. Instead, let’s create some mock code with asyncio.
import asyncio
from datetime import datetime
import backoff
import uvloop
start_time = datetime.now().timestamp()
@backoff.on_predicate(backoff.constant, max_time=300, jitter=lambda x: x)
async def slow_operation():
with open("./attempts.log", "a") as f:
f.write(f"{datetime.now().timestamp() - start_time}\n")
return False
async def main(loop):
for x in range(0, 500):
asyncio.ensure_future(slow_operation(), loop=loop)
if __name__ == "__main__":
loop = uvloop.new_event_loop()
loop.create_task(main(loop))
loop.run_forever()In this example, the slow_operation() function logs the milliseconds since the epoch and then returns False, ensuring the backoff decorator runs each time we call the function. Backoff will keep executing slow_operation() until the delay reaches the max_time of 300 seconds, at which point it will give up.
To generate plenty of data points for the graph, we queue up the slow_operation() function 500 times within our asyncio loop.
If we graph the number of function calls attempted per second, this is what it looks like when we use a constant strategy:
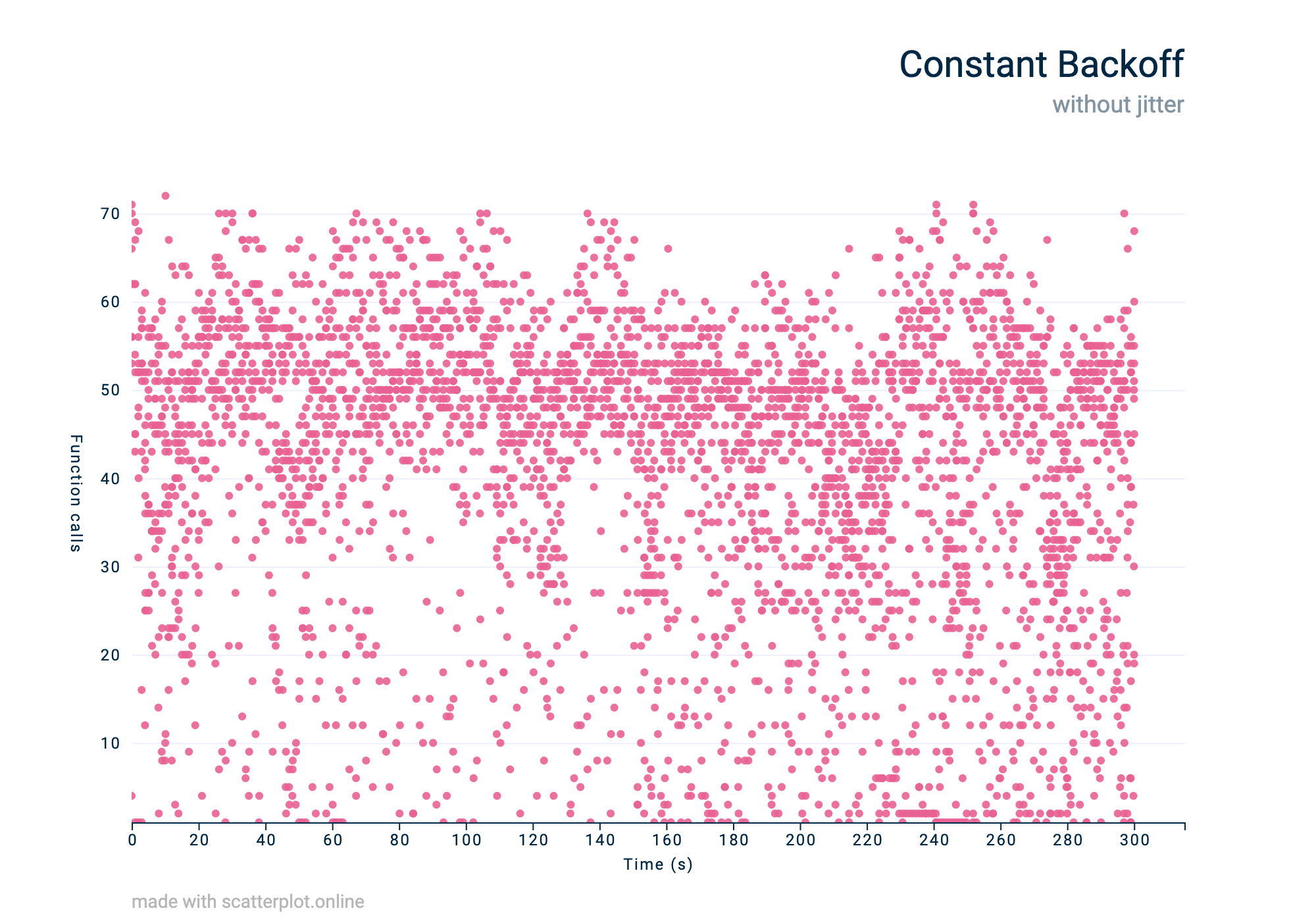 A constant traffic pattern visualised
A constant traffic pattern visualised
There is a thick band in the 40 to 60 function calls range, so a constant backoff is not appropriate for our needs. Each second, we’re flooding the API with requests, keeping our throughput far too high, and we’re likely to continue to be rate-limited.
But if we run the same code with the exponential strategy, we get a very different graph.
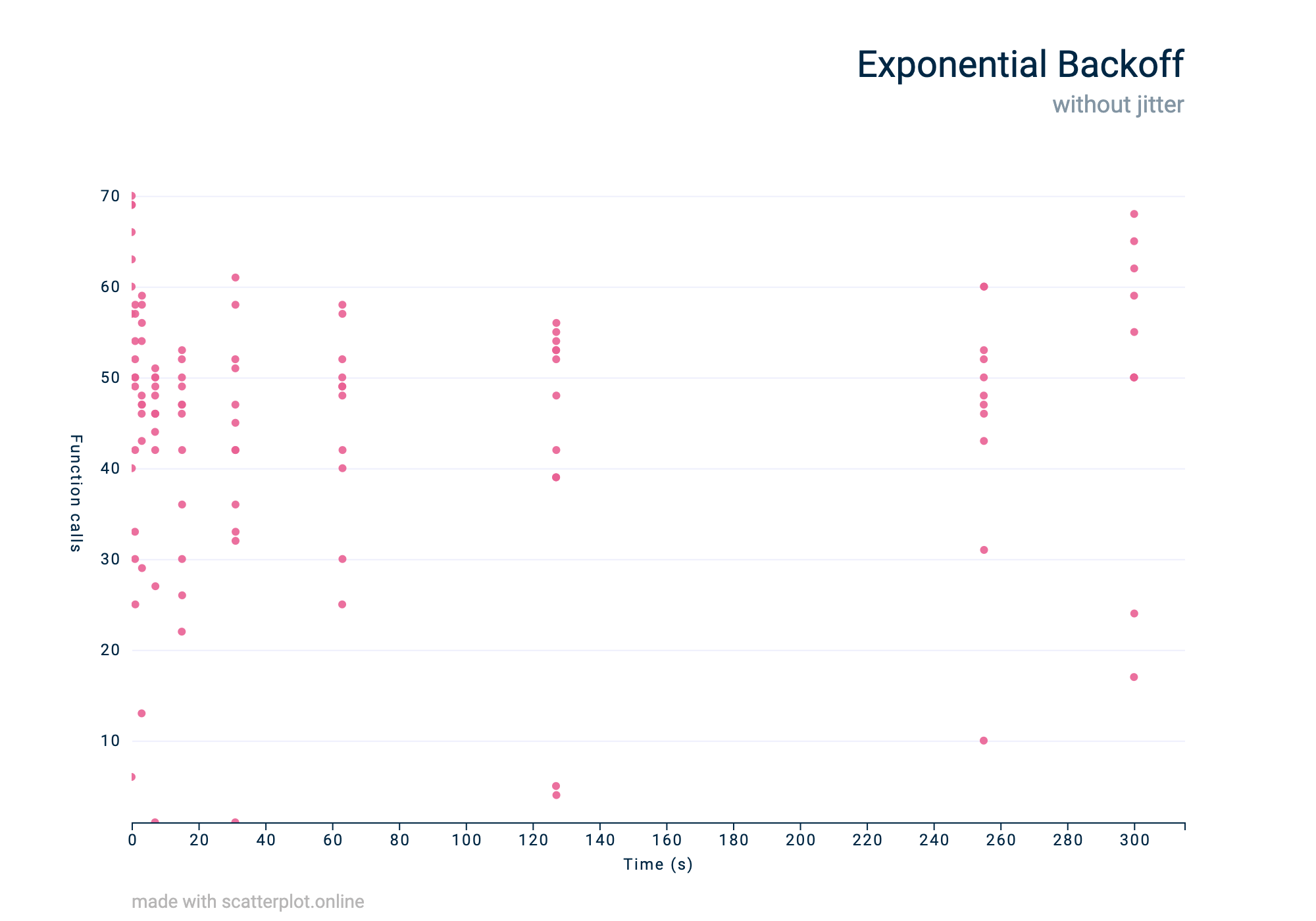 A visualisation of a traffic pattern using exponential backoff
A visualisation of a traffic pattern using exponential backoff
This graph is much better. We can see where the backoff strategy has increased the delay, reducing the throughput and hopefully giving us enough time to end the rate-limiting. But now we have another issue.
In the graph, we can see the calls are now bunching together around the end of the delays. We could end up in a situation where these bunches keep triggering the rate-limiting again. To stop these bunches from forming, we use jitter.
Jitter adds a random factor to delay duration calculation in our backoff.
sleep = random.uniform(0, delay)The Python backoff package includes this jitter by default. In the code examples above I’m removing it with a lambda function, so let’s generate the exponential graph again, but this time with jitter.
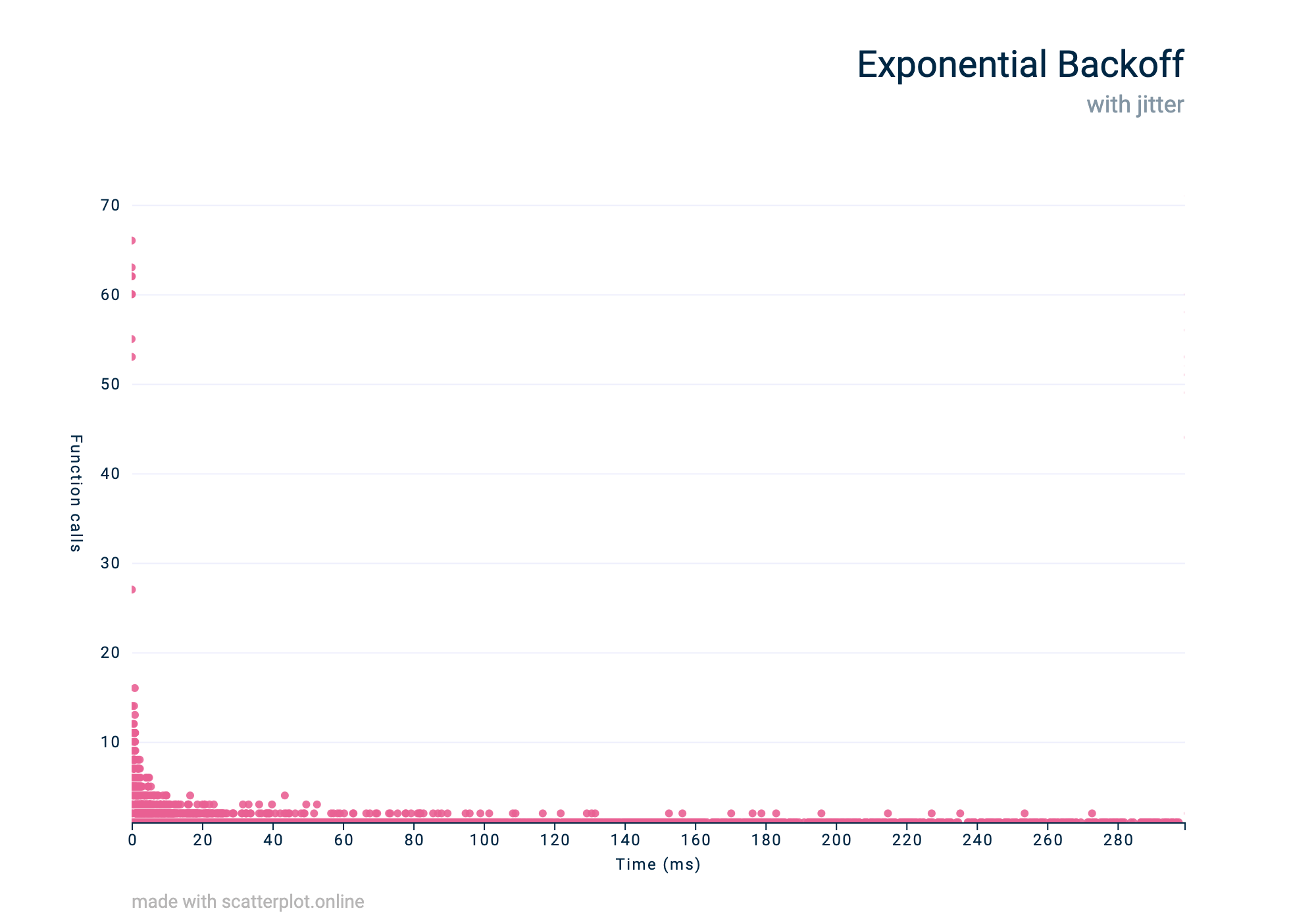 An exponential backoff traffic pattern visualised
An exponential backoff traffic pattern visualised
As we’re still using an exponential strategy, we can see that the number of calls drops off very quickly, but thanks to the added randomness of the jitter, we don’t see any bunching. Instead, the function calls per second are low and more evenly distributed.
Rate limits vary depending upon the Vonage Communications API you are using. For example, the Redact and Application APIs have a rate limit of 170 requests per second. However, due to carrier restrictions, the rate limit for outbound SMS can be as low as one request per second. Making SMS the perfect candidate for applying the backoff techniques we looked at above.
Python has a large number of task queues to choose from—Celery, [huey²], RQ, Kuyruk, Taskmaster, Dramatiq, WorQ—and almost as many brokers—MongoDB, Redis, RabbitMQ, SQS. Some of these task queues come with support for backoff built-in, but they also add a lot of complexity, making them out of scope for this article.
However, once you’re comfortable with the underlying techniques and the reasoning behind using a task queue, backoff, jitter, and so on, then I recommend you revisit the links to the task queues above. The code examples we will be looking at in the rest of this article are intentionally succinct so we can focus on only throughput management; where-as the packages above are much more robust and production-ready.
To ensure that network latency on any one request doesn’t block our entire application, we’re going to send our SMS asynchronously. But, this does mean we cannot use the Vonage Python SDK to send our SMS. The Python SDK is not async as it uses Requests, which is blocking.
We can look at the Messages API example request from the documentation to get an idea of what the Vonage Python SDK is doing for us:
In this code snippet, we can see that we’re issuing a POST request to the endpoint https://api.nexmo.com/v0.1/message. The request includes some information about the type of content we’re sending and expecting as a response. But, the essential parts to note is the Authorization header and the data (-d) option.
The request is Authorized using JSON Web Tokens (JWT). JWT is an open industry standard, and there are several Python packages available to help with their generation. But, handily the Vonage Python SDK already has a function we can call to create a valid JWT for the request. As the JWT generation is swift, does not require any Network I/O, and is only performed once at the start of the script, it doesn’t matter that it is not asynchronous.
Install the Vonage CLI globally with this command:
npm install @vonage/cli -gNext, configure the CLI with your Vonage API key and secret. You can find this information in the Developer Dashboard.
vonage config:set --apiKey=VONAGE_API_KEY --apiSecret=VONAGE_API_SECRETCreate a new directory for your project and CD into it:
mkdir my_project
CD my_projectNow, use the CLI to create a Vonage application.
vonage apps:create
✔ Application Name … my_project
✔ Select App Capabilities › Messages
✔ Create messages webhooks? … no
✔ Allow use of data for AI training? noThis command will store your private key in the file my_project.key. We’ll need this when generating our JWT, along with the application id. The application id is output in the terminal when you run the app:create command, or you can find it on your Vonage dashboard.
Now you need a number so you can receive calls. You can rent one by using the following command (replacing the country code with your code). For example, if you are in the USA, replace GB with US:
Now link the number to your app:
vonage apps:link --number=VONAGE_NUMBER APP_ID
import vonage
vonage_client = vonage.Client(
application_id=os.environ["VONAGE_APPLICATION_ID"],
private_key=os.environ["VONAGE_PRIVATE_KEY"],
)
jwt = vonage_client.generate_application_jwt()
@backoff.on_predicate(backoff.expo, max_time=300)
async def send_sms(recipient, message):
async with httpx.AsyncClient() as httpx_client:
response = await httpx_client.post(
"https://api.nexmo.com/v0.1/messages",
headers={
"Authorization": b"Bearer " + jwt,
"Content-Type": "application/json",
"Accept": "application/json",
},
json={
"from": {"type": "sms", "number": os.environ["VONAGE_NUMBER"]},
"to": {"type": "sms", "number": recipient},
"message": {"content": {"type": "text", "text": message,}},
},
)
return response.status_code == 202At the top of our script, outside of the async function, we instantiate our Vonage client with the application id and private key. I’ve stored these in environmental variables, so they’re not hard-coded within my script.
The send_sms function makes the API request, so this function has our backoff decorator. We’re using on_predicate, so if the function returns False, it will attempt it again. I’ve kept the max_time at 300 seconds, but we could also set a max_attempt limit or both!
To make the asynchronous POST request, we use httpx. httpx is an HTTP client for Python 3 with a very similar interface as Requests, but it supports async. I structured the httpx request as close as possible to the cURL example we looked at above. We have the headers with the content type information as well as the Authorization header, which includes the JWT generated for us by the Vonage Python SDK.
Our payload is a JSON string containing the from number, the recipient’s number, and our message.
Finally, we check the HTTP status code returned by the Messages API to the request. Anything other than a 202 Accepted will cause the function to return False, triggering another attempt.
In my example script, I have just hardcoded a list of recipients.
async def main(loop):
recipients = [
"13055550157",
"15615550134",
]
message = "✨✨✨Hello! This is an SMS from the Vonage Communication APIs Messages API using exponential backoff and jitter 😄"
for recipient in recipients:
asyncio.ensure_future(send_sms(recipient, message), loop=loop)
if __name__ == "__main__":
loop = uvloop.new_event_loop()
loop.create_task(main(loop))
loop.run_forever()But this is where you could use a task queue or a broker. Also, I’m also not being a good API citizen! I know that the Message API has a rate limit of 1 message per second when sending messages within the US, but I have no delay in my loop!
My script will attempt to make the API calls with no delay between them, very quickly triggering the rate-limiting. While the backoff helps us manage when we do exceed the maximum throughput allowed, it should be a last resort. Ideally, to be most efficient, we want to get as close to the rate limit, but without exceeding it. The addition of a short sleep when adding tasks to the loop should help with this.
for recipient in recipients:
asyncio.ensure_future(send_sms(recipient, message), loop=loop)
await asyncio.sleep(1)
In this recording, I’ve removed the sleep and modified the example so that it attempts to make several hundred requests at a time, causing it to nearly instantly trigger throttling by Vonage. But watch what happens after a few seconds.
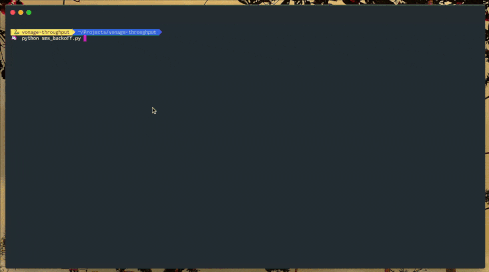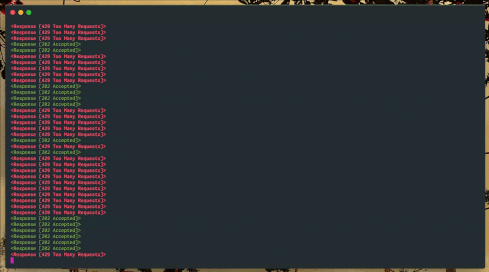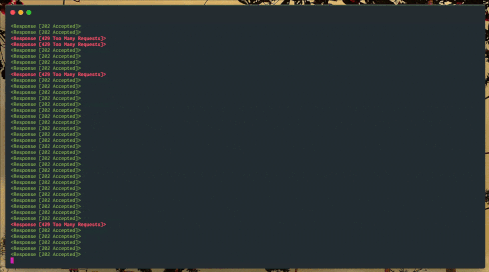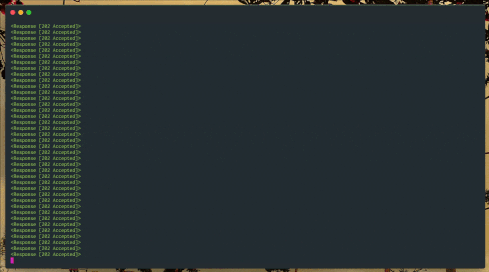 Traffic to an API being backed off over time until blocked requests end
Traffic to an API being backed off over time until blocked requests end
Almost as soon as the script begins, we see it exceeds the Messages API rate limit, and the endpoint begins to return an HTTP status of 429 “Too Many Requests”. So, the script starts to backoff. At first, the number of failed requests seems to remain about the same, but as the delay increases exponentially, the number of failed requests drops off within a few seconds, and our script can begin sending again.
Without production load, it can be quite tricky to generate enough requests to trigger the rate limiting. You can check out the example script from this tutorial as well as usage instructions on GitHub.
Please note that sending messages will charge your account. If you routinely send enough messages to become rate-limited, you might violate the Vonage terms of service; also, the carriers will not look upon you sending the same message hundreds of times favorably! So I do recommend that if you do want to try this for yourself, you don’t test it against the live Messages API but instead mock it out. There are several packages for httpx to make this process easier, including pytest-httpx and respx.
We’ve only looked at some of the functionality available with Python backoff. Check the documentation for more information on supplying different backoff strategies for different types of exceptions, or the various events which backoff emits. Try modifying the example code so that if backoff executes the on_giveup handler, the script will use the Vonage Voice API to phone the on-call engineer.
Have a question or want to share what you're building?
Subscribe to the Developer Newsletter
Follow us on X (formerly Twitter) for updates
Watch tutorials on our YouTube channel
Connect with us on the Vonage Developer page on LinkedIn
Stay connected and keep up with the latest developer news, tips, and events.
Full Stack Python - Task Queues AWS Architecture Blog - Exponential Backoff And Jitter
Share:
Aaron was a developer advocate at Nexmo. A seasoned software engineer and wannabe digital artist Aaron is frequently found creating things with code, or electronics; sometimes both. You can customarily tell when he's working on something new by the smell of burning components in the air.