
Share:
Aaron was a developer advocate at Nexmo. A seasoned software engineer and wannabe digital artist Aaron is frequently found creating things with code, or electronics; sometimes both. You can customarily tell when he's working on something new by the smell of burning components in the air.
Creating a Voice Journal for the Next Web
Time to read: 6 minutes
The world-wide-web is a wondrous thing. We can create and share information easier than at any point before in human history.
Writing a tutorial for the @NexmoDev blog while 35,000 feet above the Atlantic #devrellife pic.twitter.com/mvxGDuEDky
— Aaron Bassett - what timezone is it? (@aaronbassett) May 15, 2018
However, much of what we create lives within walled gardens; this is the antithesis to the original idea of the www. Breaking down these walled gardens has been something Tim Berners Lee has been talking about since at least 2009!
In fact, data is about our lives. You just -- you log on to your social networking site, your favorite one, you say, "This is my friend." Bing! Relationship. Data. You say, "This photograph, it's about -- it depicts this person. " Bing! That's data. Data, data, data. Every time you do things on the social networking site, the social networking site is taking data and using it -- re-purposing it -- and using it to make other people's lives more interesting on the site. But, when you go to another linked data site -- and let's say this is one about travel, and you say, "I want to send this photo to all the people in that group," you can't get over the walls.
In fact, decentralisation has been a fundamental aspect of the www since its inception.
Decentralisation: No permission is needed from a central authority to post anything on the web, there is no central controlling node, and so no single point of failure … and no “kill switch”! This also implies freedom from indiscriminate censorship and surveillance.
— Web Foundation, History of the Web
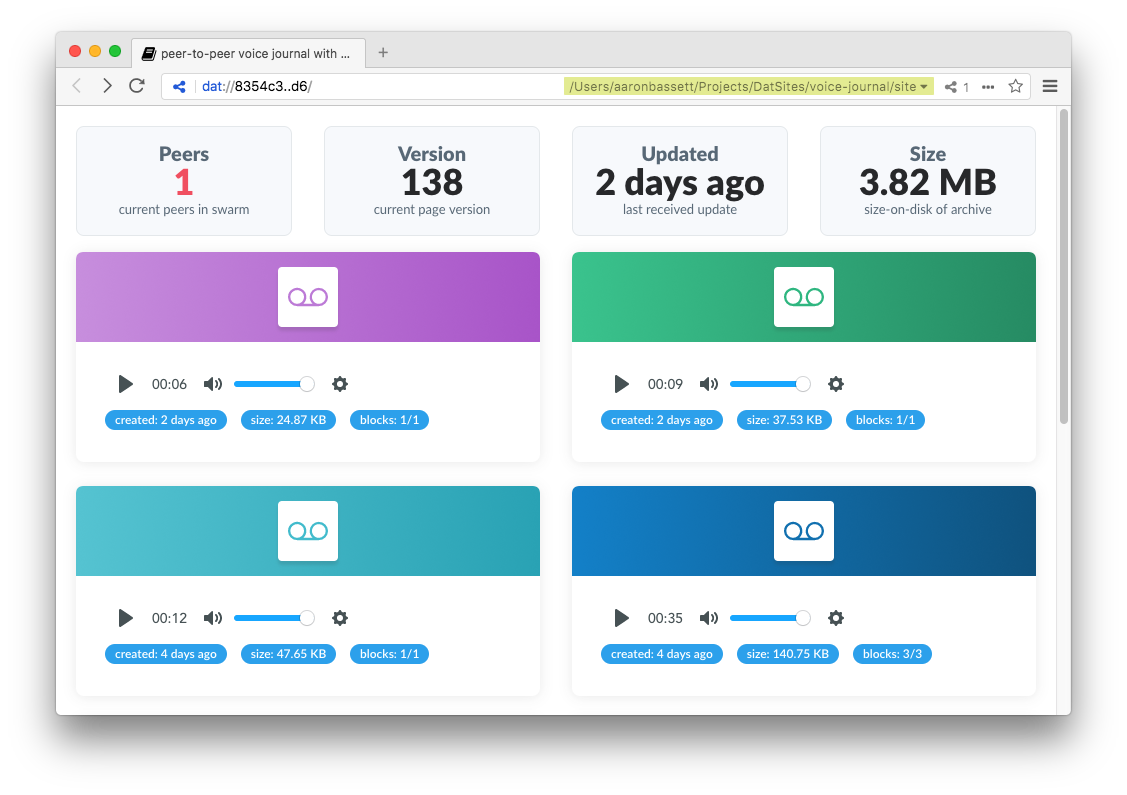 Voice Journal Screenshot
Voice Journal Screenshot
With the person-to-person web, there is no server required. Each visitor to your site becomes a peer in the swarm. Connecting directly together and sharing your site's files with each other. Not only does this help keep your site online, but it also creates freedom from indiscriminate censorship.
Let's look at how we can use the Dat protocol with Nexmo's Voice API to create a distributed website to host an audio journal. You can download the code for this example on Github.
The process flow for our application is straightforward. When we call our Nexmo Virtual Number, it records the audio as an MP3, notifies our server that there's a new recording. Then, when our server receives the notification from Nexmo, it downloads the MP3 file and adds it to our archive, and it is automatically shared with all peers using the Dat protocol.
Recording the audio is exceptionally simple with Nexmo. We create an NCCO file with a single record action. You may also want to use the TTS functionality to play a message before your recording; I've chosen not to, and instead, I instruct Nexmo to play a beep when it is ready to record. Much like an answering machine.
@hug.get('/')
def ncco():
return [
{
"action": "record",
"eventUrl": ["<SERVER URL>/recordings"],
"endOnKey": "*",
"beepStart": True
}
]In the code above I'm using Hug to create a JSON endpoint to serve my NCCO file to the Nexmo API. For more information on creating voice applications with Nexmo (and for details on what an NCCO file is), please read some of my previous tutorials:
Proxy Voice Calls Anonymously with Express, the Nexmo Voice API, and a Virtual Number
Inbound Voice Call Campaign Tracking with Nexmo Virtual Numbers and Mixpanel
I also explain more about Nexmo Voice Applications in my live coding webinars; it's about 20 minutes in:
Once the call has finished, or the user has pressed ""* Nexmo notifies us about the new recording via the webhook we specified as the eventUrl in the code above. The request to our webhook contains the recording_url which we can use to download the MP3 file. However, first, we need to authenticate with Nexmo to ensure that we have permission to download the recording. We use JWTs for authentication.
@hug.post('/recordings')
def recordings(recording_url, recording_uuid):
iat = int(time.time())
now = datetime.datetime.now()
with open('nexmo_private.key', 'rb') as key_file:
private_key = key_file.read()
payload = {
'application_id': os.environ['APPLICATION_ID'],
'iat': iat,
'exp': iat + 60,
'jti': str(uuid.uuid4()),
}
token = jwt.encode(payload, private_key, algorithm='RS256')
recording_response = requests.get(
recording_url,
headers={
'Authorization': b'Bearer ' + token,
'User-Agent': 'voice-journal'
}
)
if recording_response.status_code == 200:
recordingfile = f'./site/recordings/{now.year}/{now.month}/{recording_uuid}.mp3'
os.makedirs(os.path.dirname(recordingfile), exist_ok=True)
with open(recordingfile, 'wb') as f:
f.write(recording_response.content)Most of the code above is for the JWT authentication [*yeah, someone really should make that easier to do in the Python client… ?]. After we download the recording, we save the MP3 file, making sure to keep our archive nice and organised.
{kind=link}
/recordings/<current year>/<current month>/<recording uuid>.mp3By structuring our recordings in this way on disk, even without our application frontend, we can easily find and listen to a recording from a particular day.
There are two main ways of distributing our site via Dat; using the Dat CLI, or via the Beaker Browser. For simplicity, we're going to use Beaker in this example. However, if you wanted to run your webhook on a server, or as a serverless function, then use the Dat CLI. Tara Vancil has a great article on how they use the Dat CLI to publish updates on their blog (dat version). One thing to bear in mind is that our application frontend uses some Beaker specific APIs for interacting with our archive and displaying information about the swarm; unlike Tara's site, it does not work in a regular browser, so you do not need dathttpd.
If you haven't done so already, you should download Beaker now.
Note: Much like BitTorrent and other P2P protocols, members of a swarm can by necessity see the IP addresses of other members. Remember this is peer-to-peer distribution, it does not go through a centralised service. You can skip the next section if you're not comfortable sharing your IP address with other swarm participants.
Open the following dat:// link in Beaker: dat://8354c381e6f859e57ef6979af7e287acf3d528d8463f54774c36b6bc8aa514d6/
Congratulations, you are now a member of my swarm and can distribute the audio recordings to other visitors. You're (one of) my web servers, thank you!
However, when you close your browser, you leave the swarm. The files remain on your computer, but you're no longer distributing them to other visitors. To ensure that there is always at least one peer available I have added the archive to #_hashbase.
You don't need to create a UI to access your recordings. Beaker creates a simple interface for us to use if our archive directory does not contain an index file. It's functional, but not very pretty. We can do better.
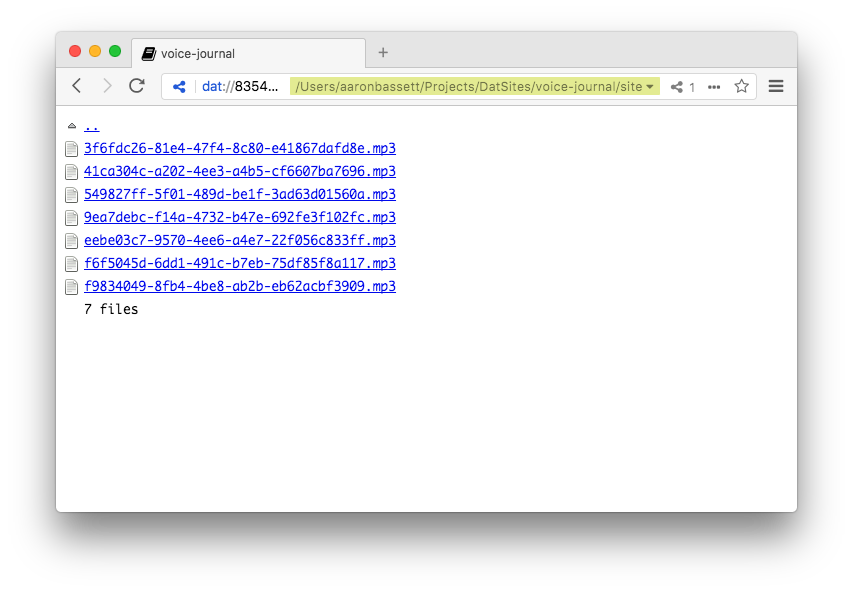 Directory listing rendered by Beaker Browser
Directory listing rendered by Beaker Browser
Our frontend is a Vue application, which uses the Vonage Volta design system. Volta is the same design system which we used in the recent Nexmo Dashboard redesign. Unfortunately, Volta is not open source, at least not yet.
We also use some Beaker specific APIs for interacting with our archive.
const archive = new DatArchive(window.location)
let allRecordings = await archive.readdir('/recordings', {recursive: true, stat: true})In the code above we interrogate our archive, reading the contents of our recordings directory and filtering out any files which are not MP3s. The stat option instructs Beaker to run stat() on every entry and return with {name:, stat:}.
Another noteworthy part of the page is the information boxes at the top of the page.
 Screenshot of swarm information UI
Screenshot of swarm information UI
We use another Beaker API to retrieve this information, getInfo()
async peers () {
return await this.archiveInfo.peers
},
async version () {
return await this.archiveInfo.version
},
async mtime () {
let timestamp = await this.archiveInfo.mtime
return moment(timestamp).startOf().fromNow()
},
async filesize () {
let size = await this.archiveInfo.size
return filesize(size, {round: 2})
}
The Dat protocol ensures that the archive is signed by the author, and can be checked for correctness by querying network peers (distribution uniformity). Only one version of the archive’s history can be distributed. If a signed Dat archive is found to differ from a peer’s signed copy, it is treated as corrupt, as the differing content could indicate a targeted attack by the Dat author. It’s important that all users receive the same content, and that’s why Dat has integrity verification built in.
— Beaker Browser, Publish Software Securely
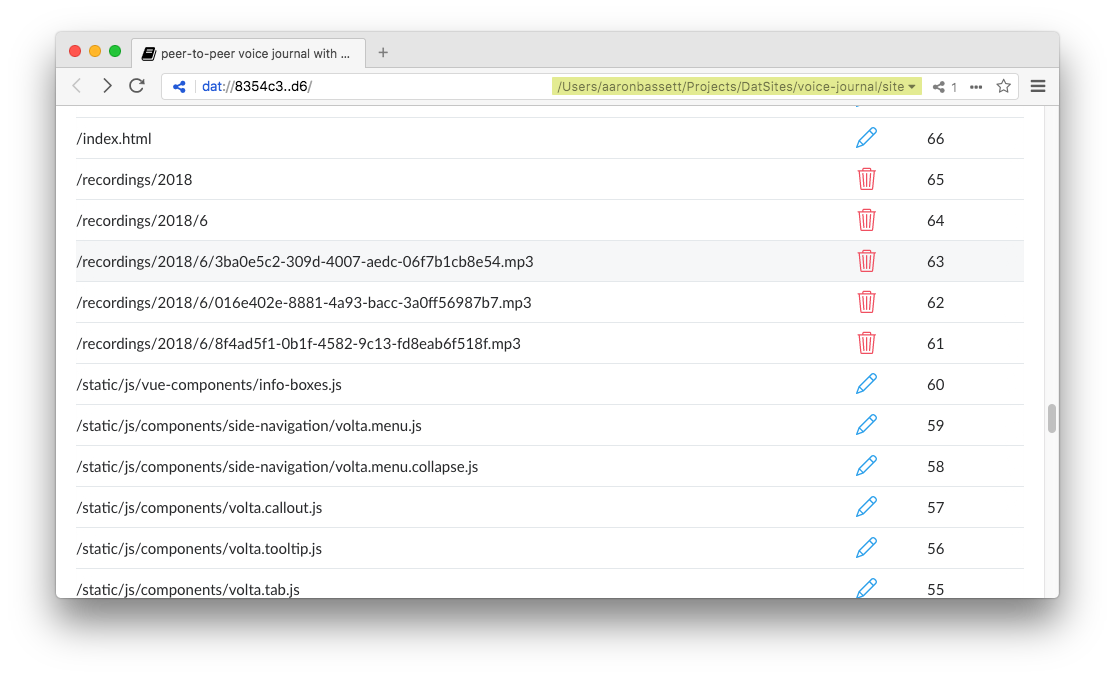 History log screenshot
History log screenshot
Using the Beaker Web APIs, we can query and display this log of changes to our archive; this log even shows if the author has deleted any journal entries.
archiveHistory: {
async get () {
const archive = new DatArchive(window.location)
const completeHistory = archive.history({start: 0, reverse: true})
return completeHistory
}
},
Try forking my archive and adding new recordings via the Nexmo Voice API. If you get stuck, the Beaker Browser docs, Nexmo Voice API overview, and this post about ngrok will help.
Read the Nexmo documentation around recording calls and conversations.
Find out more about the Dat Project, the Dat protocol, and Beaker Browser.
Explore some of the other impressive things you can do with the Nexmo Voice API; view our posts on real-time sentiment analysis, anonymous voice proxies, critical voice messages, real-time translation.
Have a play in the Nexmo Voice Playground!
Share:
Aaron was a developer advocate at Nexmo. A seasoned software engineer and wannabe digital artist Aaron is frequently found creating things with code, or electronics; sometimes both. You can customarily tell when he's working on something new by the smell of burning components in the air.