
Share:
Enrico is a former Vonage team member. He worked as a Solutions Engineer, helping the sales team with his technical expertise. He is passionate about the cloud, startups, and new technologies. He is the Co-Founder of a WebRTC Startup in Italy. Out of work, he likes to travel and taste as many weird foods as possible.
Video + AI: Vonage Video Transcript Into Google Docs
Time to read: 8 minutes
In the fast-evolving landscape of video communication, while numerous features dazzle us with video feed manipulations like background replacements or blurs, the potential of audio shouldn't be overlooked. Delving into the audio aspect offers a realm of opportunities to amplify the user experience.
For those using Vonage's video API, Vonage's Audio Connector is a sophisticated tool that channels raw audio from a Vonage Video session to external platforms for further processing. With the ability to send individual or mixed audio streams and easily identify speakers, this technology becomes essential to businesses that want to extend their communication tools.
In this article, we'll delve into how businesses and professionals can use this tool to transcribe conversations into Google Docs, transforming everyday communications like sales discussions, strategic calls, and customer interactions into valuable textual records. By the conclusion of this article, we'll have set up a Vonage video call that's transcribed into a Google Doc, with content distinctly divided by each speaker.
tl;dr If you would like to skip ahead and get right to deploying it, you can find all the code for the app on GitHub.
A Vonage Video Account Node and npm Ngrok for webhook testing A Google Cloud account
These are required to make the project work. In the below items, I'll show you where you can download/ sign up for them.
If you don’t have it, install ngrok on your local machine. Learn how here. Then, run the command to start the tunnel, specifying the port number of the local server you want to expose (ngrok http 3000). Ngrok will generate a unique URL that allows external access to your local server. We will need it on the next step when setting up the WebSocket for the Vonage Audio Connector.
First of all, ensure you have a Google account. If you don’t have one, create a free account at Google Account Signup. We would need a Google Account to interact with the Google Docs API and also to transcribe the audio to text. Once you have a Google account, follow these steps:
Go to the Google Cloud Console: Google Cloud Console Create a new project and give it a project name, add a billing account and a location
Navigate to APIs & Services > Library, search for "Google Docs API" and enable it for your project
Navigate to APIs & Services > Credentials, click "Create Credentials" and select "OAuth 2.0 Client ID"
Choose "Web application" as the type.
Under "Authorized redirect URIs", add "http://localhost:3003/oauth2callback" You'll receive a client ID and client secret. Keep these safe. Download the JSON file and store it in the project root directory
The credentials above are needed to write into a Google Docs document.
Then, we need credentials to use the Google Speech-to-Text service.
Select the project you have created on the step before
In the left sidebar, click on “Navigation Menu” (three horizontal lines)
Go to APIs & Services > Library
Search for "Speech-to-Text" in the search bar
Click on "Cloud Speech-to-Text API"
Click "Enable" to activate the API for your project
In the left sidebar, go to "IAM & Admin > Service accounts
Click on the “Create Service Account” button at the top
Provide a name and description for the service account. Click "Create"
Find the one you just created in the list of service accounts On the right side, under the "Actions" column, click on the three dots (options) and select Manage keys
Click on Add Key" and choose JSON. The JSON key will be generated and downloaded to your machine. Store this key at the root of your project
Let’s start by exploring the capabilities of Vonage Audio Connector. The Audio Connector sends audio streams to a WebSocket opened on your server. This means you can catch those streams and process them. In our case, we will first transcribe the audio to text using Google Speech API and then write the transcription to a Google Docs file.
The project architecture is the following:
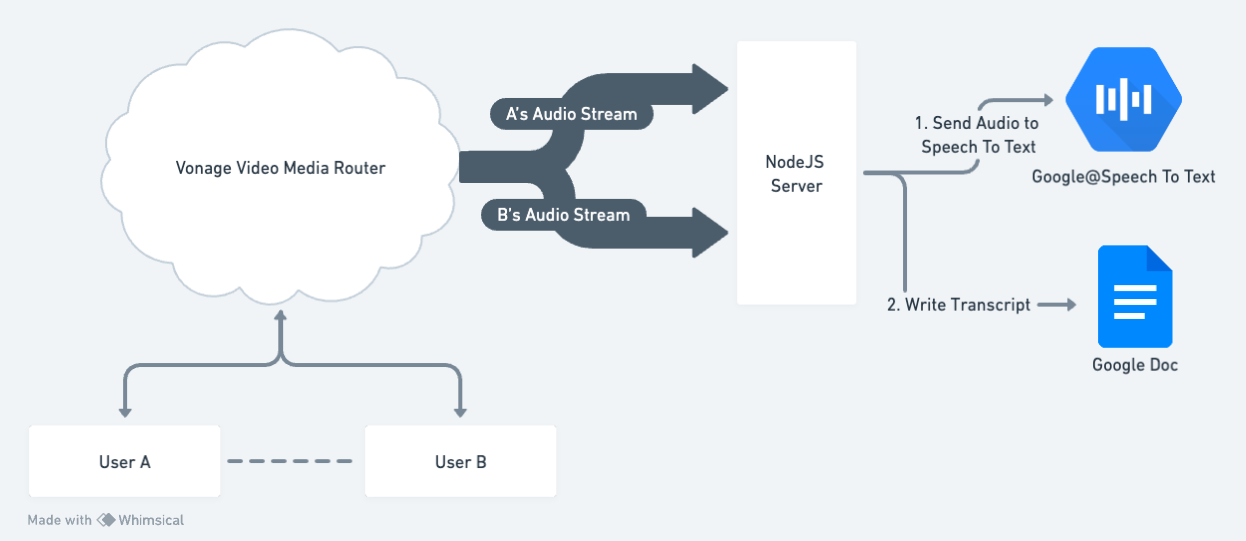 Audio Connector to Google Docs Architecture
Audio Connector to Google Docs Architecture
Let’s go through the steps:
Users connect to a Vonage Video Routed Session: the session type has to be routed. Otherwise, the Audio connector feature can’t be used.
Vonage Video Router sends audio chunks to a WebSocket connection opened on the NodeJS Server. The application server (NodeJS) will take the audio chunks and send them to the Google Speech-to-text service. The application server keeps track of the streamId based on the WebSocket connection. Once the audio has been transcribed, the server will send the transcription to a Google Docs document.
The application server is built with NodeJS and ExpressJS, which is a popular web server framework for NodeJS. It also uses the ws library to handle the WebSocket connection. Let’s dive into the file structure in the next sections.
At the top of the file, we require the various dependencies our app needs to function
require("dotenv").config();
const express = require("express");
const bodyParser = require("body-parser");
const { authorize, writeToGoogleDoc } = require("./google-apis/googleDoc");
const apiRouter = require("./routes");
const path = require("path");
const app = express();
const PORT = 3000;
const streamingSTT = require("./google-apis/streamingSTT");
const { createSessionandToken, generateToken } = require("./opentok");
const documentId = process.env.GOOGLE_DOCUMENT_ID;
// Set up EJS as templating engine
app.set("views", path.join(__dirname, "views"));
app.set("view engine", "ejs");
// Serve static files (like CSS, JS) from a 'public' directory
app.use(express.static("public"));
app.use(express.json());
app.use(bodyParser.json());After that, we set up the WebSocket connection and the handlers for the WebSocket messages:
app.ws(`/socket/:streamId`, async (ws, req) => {
console.log("Socket connection received", req.params);
const { streamId } = req.params;
const streamingClient = new streamingSTT.GoogleSST(streamId, (data) => {
const username = data.username ? data.username : data.streamId;
writeToGoogleDoc(googleClient, documentId, username, data.transcript);
});
ws.on("message", (msg) => {
try {
if (typeof msg === "string") {
let config = JSON.parse(msg);
console.log("First Message Config", config);
streamingClient.setUsername(config.username);
streamingClient.transcribe();
} else {
if (streamingClient.speechClient) {
streamingClient.handleAudioStream(msg);
}
}
} catch (err) {
console.log(err);
ws.removeAllListeners("message");
ws.close();
}
});
ws.on("close", () => {
console.log("Websocket closed");
});
});
Let's delve into the details of the WebSocket URL connection. Observe the use of a path parameter, /:streamId. This design ensures that for every new audio connection, the server is informed of both the streamId and the username associated with that audio stream. Such a design choice is pivotal as it facilitates associating the transcription with a specific username and streamId.
Following this, we initialise a new instance of GoogleSTT (SpeechToText). While doing so, we pass the streamId and a callback function to its constructor. This callback is triggered every time a transcription is available, invoking the writeToGoogleDoc function. This function is responsible for connecting to the Google Docs document and appending the transcription.
Delving deeper, the listener for the "message" event is where the magic happens: audio data is relayed to the GoogleSTT service. The Audio Connector's initial message imparts the audio format and stream metadata (further details can be found in the Vonage Audio Connector documentation). Subsequent messages contain audio chunks, which are promptly dispatched to the Google service via streamingClient.handleAudioStream(msg).
The OpenTok folder contains all the necessary OpenTok methods to create a session and, most importantly, to create the WebSocket connection between the server and Vonage Media Router. Let’s focus on the latter:
const startTranscription = async (streamId, sessionId, username) => {
try {
const { token } = generateToken(sessionId, "publisher");
let socketUriForStream = process.env.NGROK_DOMAIN + "/socket/" + streamId;
opentok.websocketConnect(
sessionId,
token,
socketUriForStream,
{ streams: [streamId], headers: { username } },
function (error, socket) {
if (error) {
console.log("Error:", error.message);
} else {
console.log("OpenTok Socket WwebSsocket connected", socket);
}
}
);
return response.data;
} catch (e) {
console.log(e?.response?.data);
return e;
}
};
The function primarily accepts three inputs: streamId, sessionId, and username. Both the sessionId and streamId play a pivotal role informing the Vonage Media Router about the specific audio stream we aim to retrieve. For enhanced clarity in our WebSocket callbacks, I've included the publisher's username in the headers section. While this step remains optional, it's instrumental if you're looking to annotate the speaker's identity in the transcriptions.
This file introduces a tool called GoogleSTT. This tool's job is to convert spoken words into text with the help of Google's service.
Within the tool, the main part we look at is called the transcribe function. This function first sets some basic settings like the kind of audio and which language is being spoken. After this, it begins a process where voice data is sent to Google, and in return, Google provides the text version of that voice.
When Google returns the written text, the function calls the transcriptCallback, which was set on the WebSocket connection.
async transcribe() {
const request = {
config: {
encoding: this.encoding,
sampleRateHertz: this.sampleRateHertz,
languageCode: this.languageCode,
},
interimResults: false,
};
console.log("Request", request);
this.stream = this.speechClient.streamingRecognize(request);
this.stream.on("data", async (data) => {
let transcript = data.results[0].alternatives[0].transcript;
console.log("Transcript", transcript);
if (this.transcriptCallback) {
this.transcriptCallback({
transcript,
streamId: this.streamId, //tood need to add User Name ?
username: this.username,
});
}
});
this.stream.on("error", (err) => {
console.error(err);
});
this.stream.on("finish", (res) => {});
return this.stream;
}
This module is all about connecting to Google Docs and managing the content inside them. Right at the beginning, we have some essential tools like file reading (fs) and system paths (path).
The key part of this module revolves around Google's authorization. We need to ensure that our software has the right permissions to interact with someone's Google Document. For this, we have a set of specific permissions, or "scopes", defined as SCOPES.
The file named token.json is crucial. When a user gives our software permission for the first time, their access details get stored in this file. This means they won't need to repeatedly authorize our app every time they use it.
Now, the main act: writeToGoogleDoc. Once we have the needed permissions, this function takes in a Google Document ID, a username, and the text you want to add. It fetches the document, finds the right place to put the text, and adds the provided text right at that spot, marking it with the username to indicate who said what.
First of all, begin by cloning the GitHub repository to your local machine. Once you've done that, navigate to the project directory and run the npm install command to set up all the necessary dependencies. With that out of the way, it's time to open up a tunnel using ngrok to expose your local development environment to the internet.
Next, ensure you've updated the .env file with the appropriate configurations (Vonage and Google credentials, Google Docs ID, and ngrok domain). Now, you're all set to experience the project! Simply open a browser and navigate to a URL structured like your-url.com/room/enrico . Once the page loads, you'll see an option to enable transcription. Click on the button, and you're good to go!
We've gone over how to connect with WebSockets, change audio into text, and put this text into a Google Docs document. Now, it's time to see all of it come together. Watch the video below to see the project working.
In conclusion, the introduction of the new Audio Connector truly broadens the horizon for innovative applications. By bridging audio streams to other services, we unlock a realm of possibilities, from transcription to real-time analytics and beyond.
In this project, we explored a practical example of this potential, seamlessly integrating audio streams with Google's Speech-to-Text service and then capturing the transcriptions in a Google Docs document. As we've demonstrated, the combination of these technologies not only streamlines communication but also paves the way for diverse and exciting use cases in the future. Whether for business meetings, educational sessions, or any scenario where spoken words hold value, the doors are now wide open for further exploration and innovation.
Let us know what you're building with the Audio Connector. Chat with us on our Vonage Community Slack or send us a message on X, formerly known as Twitter.
Share:
Enrico is a former Vonage team member. He worked as a Solutions Engineer, helping the sales team with his technical expertise. He is passionate about the cloud, startups, and new technologies. He is the Co-Founder of a WebRTC Startup in Italy. Out of work, he likes to travel and taste as many weird foods as possible.