
Share:
Yotam is a Principal Data Scientist at Vonage. He brings his PhD in Computational Neuroscience and a passion for ethical data science to every project he undertakes. His past work includes leading a grant-funded research project to create a facial-gesture-controlled communication tool for ALS patients, powered by low-cost, accessible forehead-electrode technology.
Man in the Loop vs. LLM in the Loop
Time to read: 7 minutes
In AI, striking a balance between human oversight (“man in the loop”) and automation (“LLM in the loop”) is crucial for building real-world solutions. We at Vonage AI, the team responsible for developing AI services within Vonage, faced this challenge while redesigning our speech-to-text (STT) systems to meet the growing demands for accurate call center transcription.
To overcome the limits of traditional benchmarking, we developed a new approach using Large Language Models (LLMs) to generate high-quality reference transcriptions by processing outputs from multiple STT providers. Instead of relying on human-generated references or a single “ground truth”, the LLM synthesizes a consensus transcription, using its understanding of language and context across inputs.
This LLM-derived reference enables scalable, unbiased, and context-aware computation of Word Error Rate (WER) for each provider.
In this post, we share how this LLM-based method compares with traditional benchmarking, focusing on:
The limits of current benchmarking methods
How LLMs synthesize reference transcriptions
Key findings from our experiments
At Vonage AI, we are a team of researchers and engineers dedicated to pushing the boundaries of what's possible with artificial intelligence. As part of Vonage’s commitment to intelligent communications, we focus on both cutting-edge conversational AI and core machine learning research, delivering robust, scalable, and forward-thinking AI solutions. This post shares one of our research efforts: rethinking how we benchmark transcription accuracy in a fast-moving, multi-model world.
A few years ago, when we were fine-tuning our STT models for the various dialects present in our customers' call center audio recordings, we relied heavily on human annotators to transcribe audio snippets. These transcriptions served as the “ground truth” for training and evaluating our in-house models.
The process is time-consuming, slowing down development cycles.
High costs make it difficult to scale effectively.
Human reviewers often begin with existing transcriptions, which can introduce inherent bias into their corrections.
The task is mentally demanding, increasing the likelihood of human error over time.
However, the challenges proved worthwhile; our fine-tuned proprietary model ultimately outperformed leading third-party solutions for our specific use case.
As customer needs evolved, we faced new challenges with manual labeling
Supporting new languages and dialects required hiring human experts fluent in each specific language.
Testing on industry-specific use cases, such as medical transcription, demanded humans with domain expertise.
The rapid growth of advanced open-source models introduced more options for evaluating, deploying, and fine-tuning; hence, we needed a scalable and consistent way to evaluate accuracy without waiting weeks for manual transcription.
As a result, we entered a new era: LLM in the loop.
Instead of relying on humans to transcribe audio for ground truth, we now use a Large Language Model (LLM) to generate reference transcriptions. The LLM analyzes outputs from various transcription systems and reasons across them to produce the most accurate reconstruction of what was said, sometimes aligning with one model’s output for a partial segment of the audio and with another model’s output for a different part of the audio.
It’s like having a smart, fast referee that:
Reads multiple transcriptions of the same audio
Understands context and language nuances
Produces a reliable, unbiased “reference” to compare models against
To validate the concept, we processed a well-known corpus that we had previously labeled manually. We used it to estimate the accuracy of the LLM-driven pipeline while also evaluating the original contribution of the manual labeling effort.
Here’s what we designed:
We transcribed the same 5–15 second audio snippets using multiple STT systems, including our own in-house models, open-source models, and third-party providers.
For each clip, we collected all transcriptions along with the original human labels. We then prompted the LLM with these alternatives (blinded to their sources) and asked it to generate the most accurate, likely transcription for that snippet.
Using this LLM-generated “synthetic ground truth” on ~300 samples, we computed the Word Error Rate (WER) for each STT system.
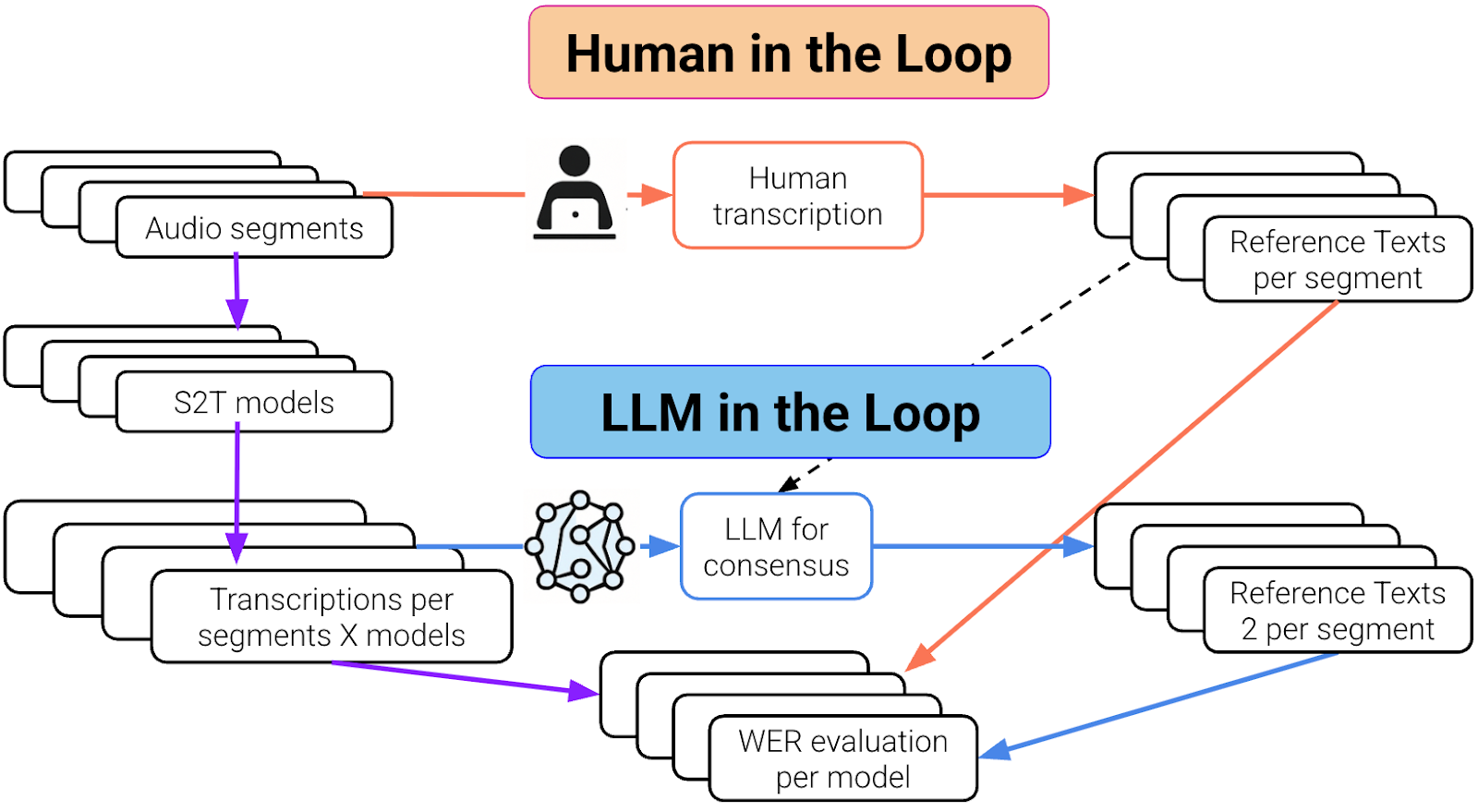 Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
The Human and the LLM Loops. Purple part is common on both loops.
Imagine we have the following STT outputs from various providers for a short agent audio snippet:
 Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
These transcriptions vary in formatting, numeric representation, and accuracy, reflecting typical outputs from different models.
The LLM is instructed to generate two aligned reference transcriptions:
Alphabetic reference:
If the twenty-four-hour period passes, that's going to be a fifty-dollar fee to cancel up to eight days before arrival.
Alphanumeric reference:
If the 24-hour period passes, that's going to be a $50 fee to cancel up to 8 days before arrival.
This approach ensures fair (and formatting-unbiased) comparison between different types of model outputs: non-formatting models (such as our solution) are measured against non-formatted references, while formatting-capable models are measured against formatted references that preserve equivalent meaning.
The following models were tested:
Vonage AI (VAI) - Our in-house fine-tuned model, trained on manually labeled data by the same team
Vonage AI (VAI) - Our older version model, untuned for this use case
The original human-labeled transcriptions
Three open-source models from OpenAI: Whisper-Large(V3), Whisper-Medium, Whisper-Small
Two third-party providers
To examine the role of human references, we used the LLM-based evaluation pipeline in two configurations:
Label-In: The human transcription was included among the alternative outputs shown to the LLM for reference synthesis.
Label-Out: The human transcription was excluded (blinded) from the alternatives shown to the LLM
We compared the two to assess the robustness of the LLM-generated reference and potential biases introduced by human-labeled data.
We used Word Error Rate (WER) as our main evaluation metric. This is a standard measure of transcription quality. WER quantifies the number of errors in a transcription by comparing it to a reference. These errors fall into three categories:
Insertions: extra words added
Deletions: words that were missed
Substitutions: incorrect words in place of the correct ones
WER is calculated using the formula:
 Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Lower WER indicates a more accurate transcription.
 Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
WERs were nearly identical across both setups, demonstrating the robustness of LLM-generated references.
Stable ranking and WER values across both label-in and label-out settings for most models.
“3rd-Party 2” showed notable improvement when the human label was excluded (WER 10.5 → 9.5), suggesting better alignment with LLM-generated outputs than with human annotations.
Human-labeled transcriptions had higher WER than nearly all automated models under this evaluation. This was expected, given that the corpus was transcribed by non-native English speakers and the annotation tool lacked typo safeguards.
VAI Fine-tuned model trained on human labels by the same team still outperformed its untuned counterpart (WER 13.7 → 12.5), showing the utility of such data despite its imperfections.
These results demonstrate that LLM-generated reference transcriptions are reliable, consistent, and scalable for benchmarking STT systems. The near-identical WERs and rankings across evaluations, with or without human-labeled data, highlight the robustness of the pipeline.
While some models may align better with the LLM’s tokenization or formatting style (as seen with “3rd-Party 2”), overall, the LLM-derived references offer a fair and reproducible evaluation method.
Importantly, although human-labeled references showed higher error rates, they remain valuable for model training. Fine-tuning on such data improved model performance significantly, reaffirming the role of labeled data in model development, even when evaluation can be automated.
LLMs can generate reliable reference transcriptions, supporting scalable, high-throughput benchmarking.
Human-labeled references are no longer required for evaluation, but still offer benefits for training.
This method accelerates fair benchmarking across new models, languages, and domains, eliminating the need for manual transcription.
Want to build your own AI agent and benchmark different solutions? You can try your own AI Studio Agent and combine it with various 3rd party solutions like Deepgram and see which works best for you.
Have a question or want to share what you're building?
Subscribe to the Developer Newsletter
Follow us on X (formerly Twitter) for updates
Watch tutorials on our YouTube channel
Connect with us on the Vonage Developer page on LinkedIn
Stay connected and keep up with the latest developer news, tips, and events.
Share:
Yotam is a Principal Data Scientist at Vonage. He brings his PhD in Computational Neuroscience and a passion for ethical data science to every project he undertakes. His past work includes leading a grant-funded research project to create a facial-gesture-controlled communication tool for ALS patients, powered by low-cost, accessible forehead-electrode technology.