
Share:
Max is a former member of the Vonage Team. He was a Python Developer Advocate and Software Engineer, interested in communications APIs, machine learning, developer experience and dance! His training is in Physics, but now he works on open-source projects and makes stuff to make developers' lives better.
Improve Your Software Project - Part Two: Making Changes
Time to read: 14 minutes
Have you ever taken over a codebase and realised that you're not happy with how the code is written or organised? It's a common story, but one that can cause a lot of headaches. Technical debt can snowball, making it exponentially harder to understand the code and add new features.
In this three-part series, I'll walk through some of the key things you'll want to do to become happier with your shiny (old) project. To give some concrete examples, I'll tie everything together by explaining how I refactored and enhanced the open-source Vonage Python SDK, a library that makes HTTP calls to Vonage APIs, but the principles apply to any kind of software project.
The examples in this post will be written in Python, but these principles apply to projects in any language. There's also a handy checklist to follow if you're specifically trying to fix a Python project.
Part Two: Making Changes (this article)
In Part Two, we'll talk about:
Becoming confident to make changes and address technical debt
Building trust with your boss, team, and users
By the end of the article, you'll be ready to change things for the better in your project whilst keeping the relevant people happy.
Let's get started!
If you followed Part One of this series, you'll already have a good understanding of the project you now own, as well as knowing how the codebase (and tests, if you're lucky enough to have them) is structured, and what purpose that structure serves. Now is a great time to think about the overall architecture and start to restructure the project more logically if you think it could be improved.
The project I'm using as an example is the Vonage Python SDK, which allows a user to call many different Vonage APIs. In my case, the macrostructure of my project looked like this:
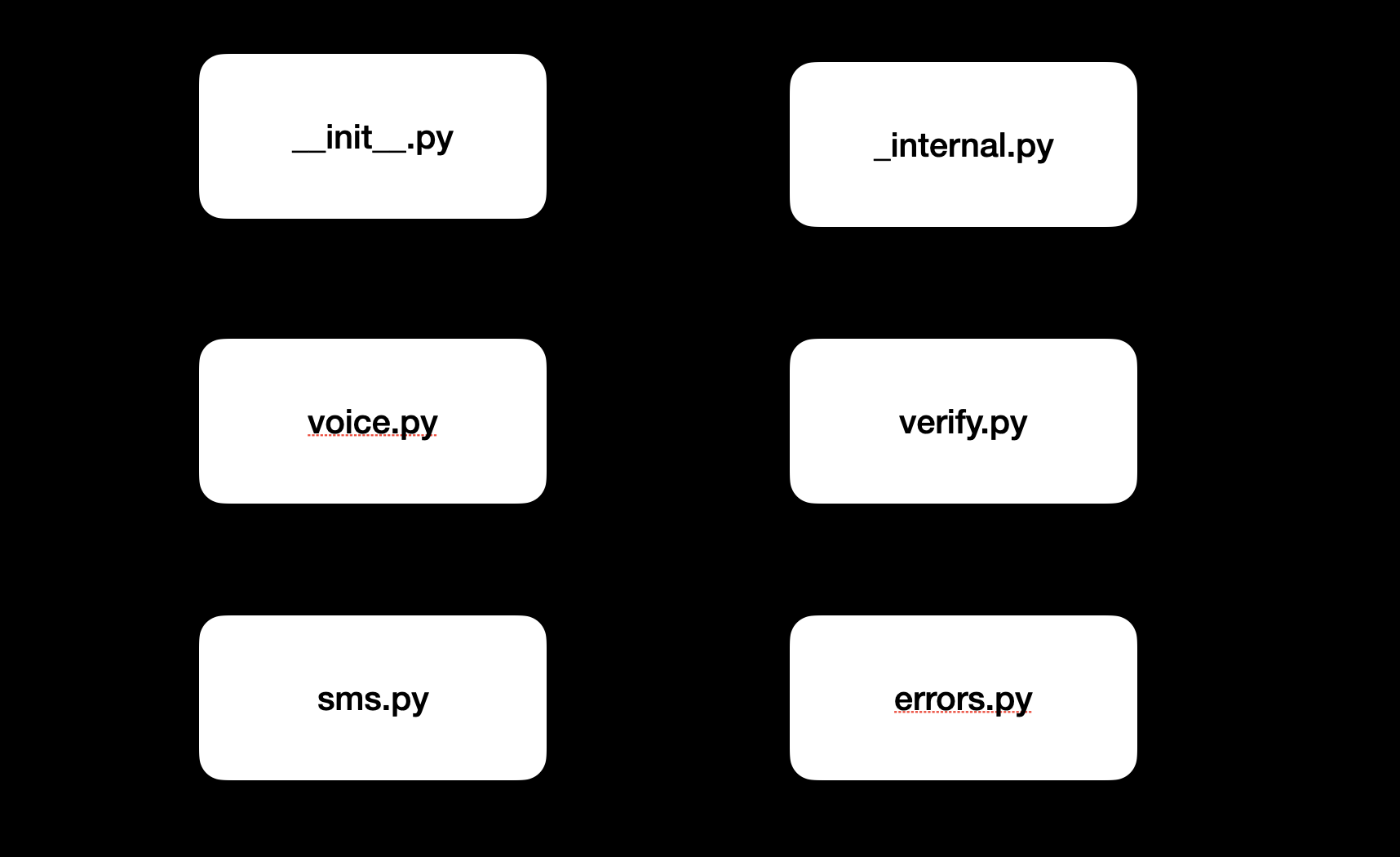
You can see from the figure above that the code was split into six main modules (single files, yes Python is very compact!):
An
__init__module, typically a minimal file used for packaging up the codeAn
_internalmodule which contained internal methods (and also one of the APIs we support, for some reason)sms,voiceandverifymodules which each contained code to call a single APIAn
errorsmodule, which contained all the custom errors
My first question when looking at this was: where are the other APIs? When I arrived at Vonage, the SDK supported 12 different APIs (we've added more since then!), yet there were only 3 modules related to these APIs.
It transpired that about 90% of the code was actually inside the __init__.py file, including implementations of many APIs, deprecated methods, the logic for tasks like JWT generation, the base API requests and other optional settings... way too much for a file that should be very minimal. I decided to refactor this by creating a Client class that would deal with the core logic, then classes named after APIs (with a small amount of logical grouping).
We ended up with a structure that looked like this:

Look at the structure of your project. Ask yourself: could I make this better? Group similar functionality into modules that are small enough to understand easily, but no smaller - you still want to be able to see the big picture of what the project does.
I'd also recommend creating classes to hold similar methods, as well as custom errors for each class to give yourself and your users more visibility on what's wrong when things break.
When you start on a new project, it probably won't have been left in a "completed" state. Software projects are always a work in progress and the constant iterative improvements are a large part of why we use version control. In this situation, you might find that there are branches in your version control system that contain features, enhancements or bug fixes.
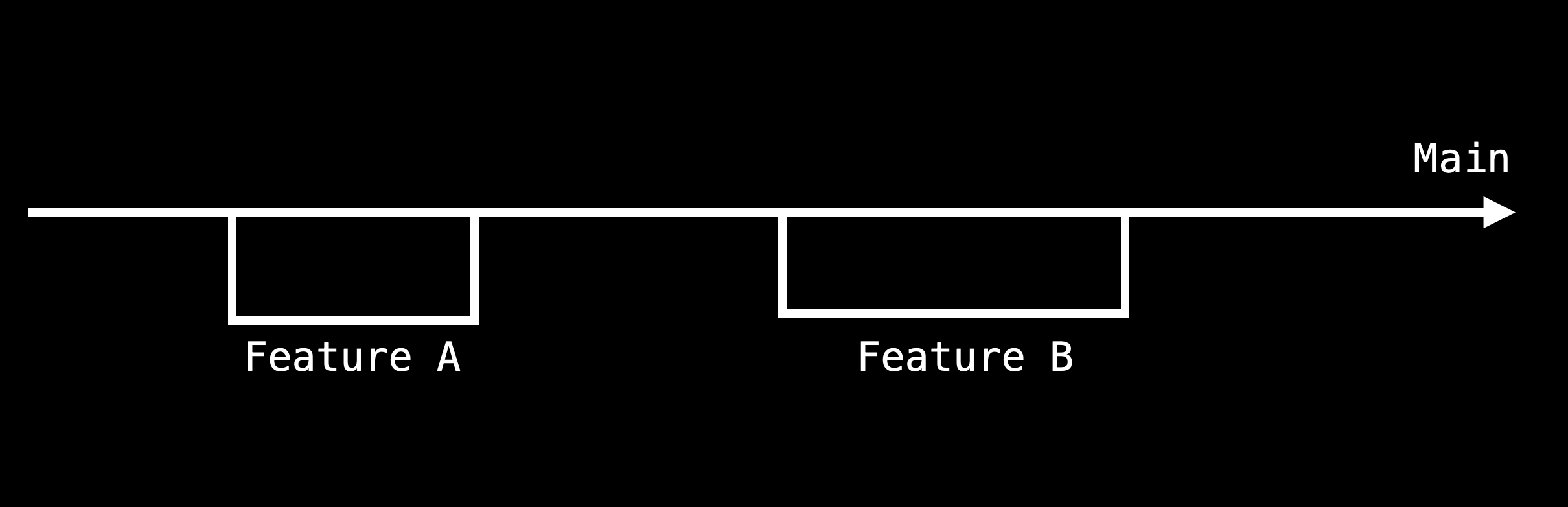
The ideal situation in a lot of cases looks like this: a single main branch, with features being developed on secondary feature branches, then merged back into the main branch.
In some projects, it might make sense to have a longer-running beta branch, if there's a beta feature you want to test and keep separate from your main codebase. In the Vonage Python SDK, we currently have a beta branch with code that calls our Vonage Video API, which is in beta. We don't want to merge this branch as the API it calls isn't officially released. In this case, your branch structure might look more like this:
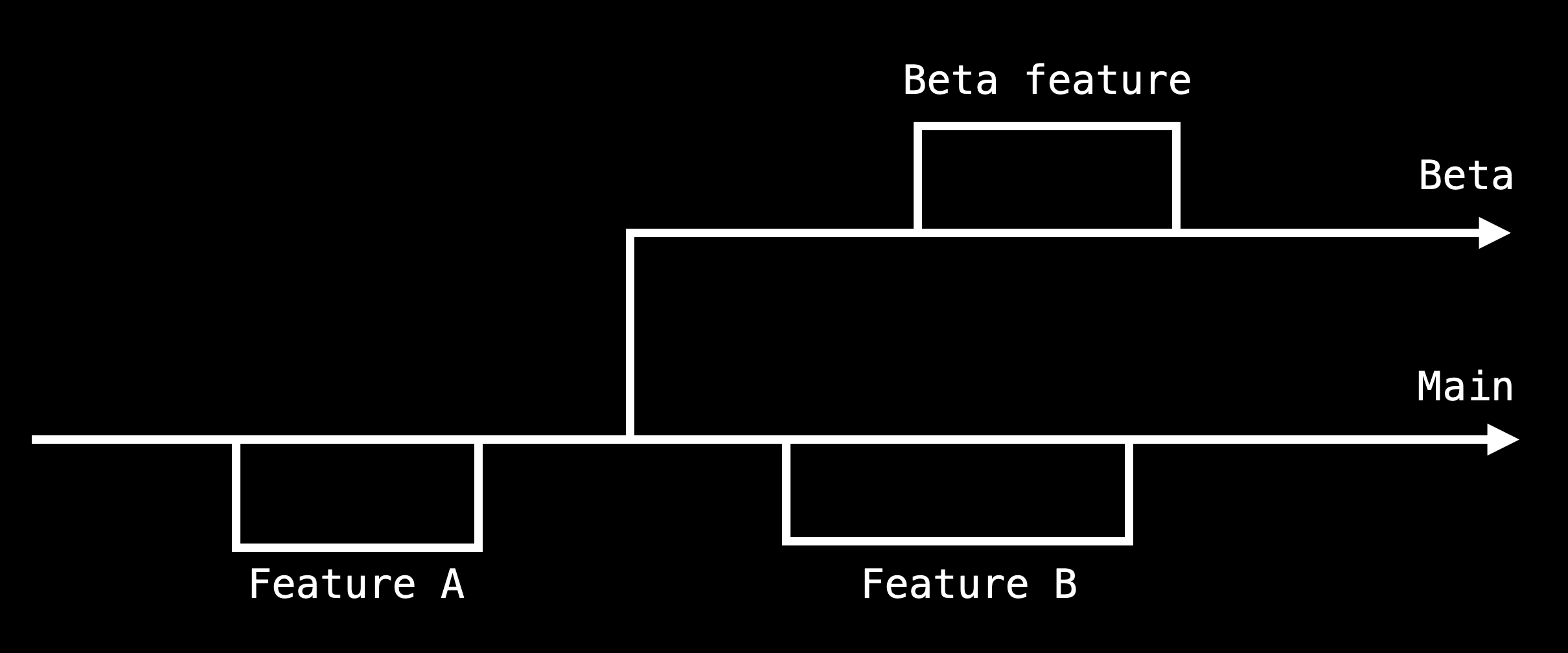
In the case where you have to develop features separately, it might be wise to periodically rebase the beta branch to pull in the changes from the main branch - this is what I do with the Vonage Python SDK.
Those are the "good" cases. But when you arrive at a project, it might look more like this:
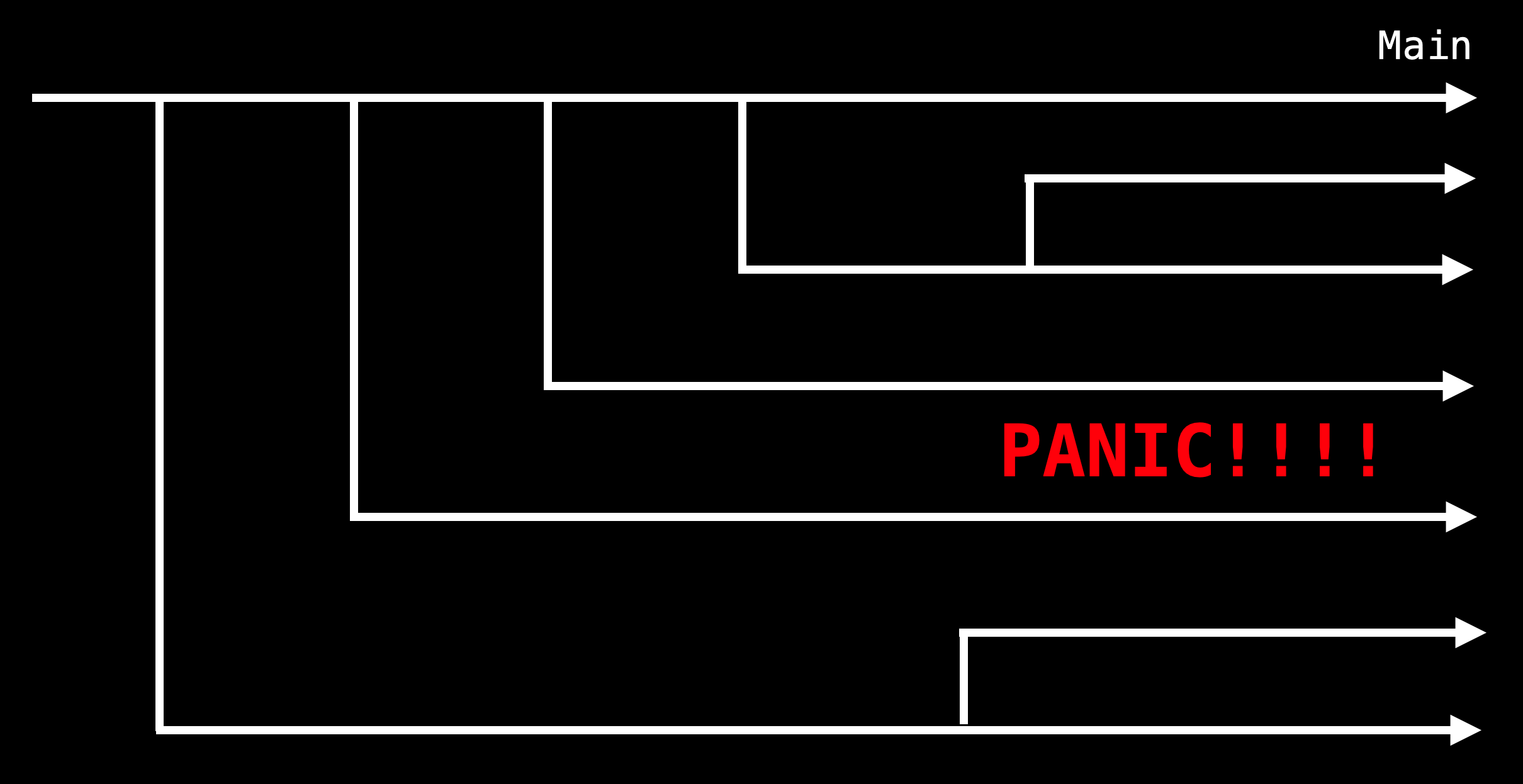
I.e. way too many branches, and a lack of consistency. Usually, things end up like this when multiple developers were working on many features simultaneously, though it could also be the case that a previous engineer used new branches to plan various tasks and try new things, but never got around to finishing them.
In this situation, these branches can be a great source of insight into how the previous project owner was handling the project, as well as a source of inspiration - some of the features or fixes might be good enough to implement yourself. However, once you understand what an extra branch contains, it's usually a good idea to close it - the aim is to give yourself as much of a blank slate as possible to implement your ideas.
Now seems like a good time to remind everyone (myself included) about Chesterton's Fence - the aphorism stating that you shouldn't remove something, without understanding why it was put there in the first place. Make an effort to understand the purpose of a branch or part of the code before removing it! Most importantly: don't remove something just because you don't know why it's there, try to understand first.
Almost every software project will depend on other people's code. The beauty of open source is that a lot of problems and challenges have been solved before your code came along, by very smart people who are willing to share their work with you. However, it's important to understand the dependencies your code has, what they're used for and whether they're the very best tools for the job.
A dependency that was suitable in the past may also become less suitable over time, which leads us to ask the question:
When choosing to keep (or replace) a dependency, this section should help you to evaluate whether a dependency is worth using.
First, consider the license. Make sure you're allowed to use the dependency for your project. If you can't, that's a no. If you're not sure what I'm talking about when I say this, this article from Snyk should help explain what to look for when evaluating a dependency's license.
Next, is the dependency actively maintained? You can see the commit history of open-source projects. Some are so simple that they need very little maintenance, and this is fine. More complex projects should be actively maintained, i.e. there should be frequent commits, and issues and PRs aren't ignored for a long time. It's important as you want the dependency to support new language versions and play nicely with new features and other dependencies you're using.
It's worth considering the popularity of the dependency. All dependencies can have security vulnerabilities, and a more widely used dependency is more likely to have these vulnerabilities flagged by automated tools, security researchers and other users, increasing the likelihood that any vulnerabilities will be quickly patched, keeping your users safe. Picking a widely used option also means a larger number of people will be able to answer questions if you get stuck!
Finally, consider the supporting assets - is the documentation clear? Are there reliable examples online that use this dependency? These things can help you get started or debug problems fast, so they're worth considering.
So you've found the perfect set of dependencies? Great news... for now. A well-maintained library that fits your needs might not stay that way - the maintainers could abandon the project or your requirements could change, rendering it unsuitable. The best piece of advice I have here is: continue to qualify your dependencies over time! Make sure they still fit your needs. And you never know, a new library might appear that suits your needs even more perfectly in future.
If your project has to communicate with other code, the thorny problem of how to test your code's functionality appears. In our example, the Vonage Python SDK's main task is to call many different APIs. We don't have control over the APIs themselves, or how they behave.
An example of this is when you use the SDK to call Vonage's SMS API. Many things can happen here, depending on your exact needs, but I'll give a specific example. Sending an SMS with the Python SDK is quite a simple process:
import vonage
client = vonage.Client(key="API_KEY", secret="API_SECRET")
client.sms.send_message(
{
"from": "SENDER_NAME"
"to": "RECIPIENT_PHONE_NUMBER",
"text": "A text message sent using the Vonage SMS API",
}
)But after you run this code, a lot of things happen. Here's a (very) simplified version:
The SDK sends a request to a Vonage server
The server parses the request and sends a response back to the SDK.
If the request was OK, the server sends an SMS to a recipient's phone number
Status information (e.g. delivery receipt) is sent back to the Vonage Server
Optionally, this info is sent from a Vonage server to a webhook specified by the user so they can see information like whether the SMS was successfully delivered.
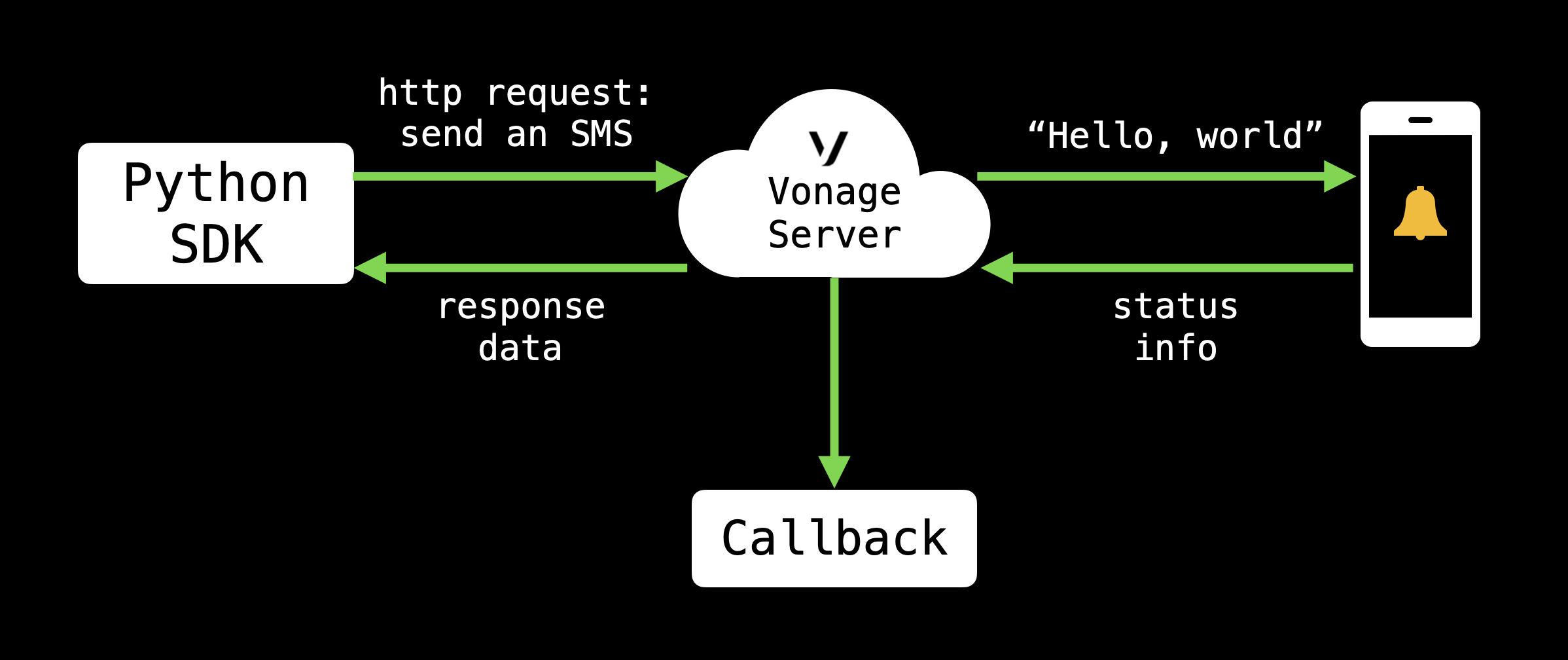
In this situation, running our code causes a whole lot of other code to run. We can't test this other code from the SDK, so we have to make an assumption when we write our tests: if we send the right information, we'll make the right stuff happen and get the correct responses back.
In our example, the only part of the code we can test is this:
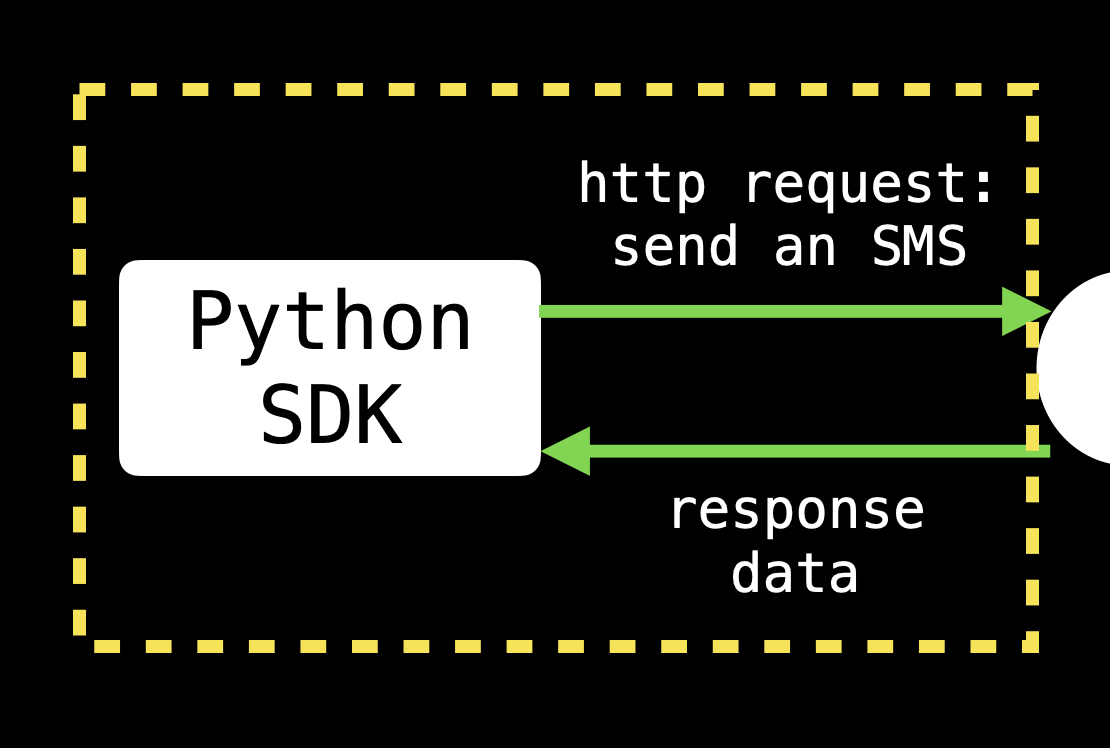
So the only questions our code can be evaluated on are: 1. are the requests we send well-formed, and 2. are the responses dealt with appropriately?
In summary, scope your testing to only test how your code sends and receives data, and assume that the other software does its job correctly, sending success and error responses for your code to process. When testing, consider capturing API requests and returning mocked responses in the correct form for the request, so your code can consume and process this mock data when you run your tests without actually calling the external services you can't control.
Remember that your tests prove that your code complies to your test suite's specifications, not necessarily to the actual API behaviour. When adding a new feature, it's a good idea to create a demo app that actually uses your code to make live requests, as well as just running your tests (this approach also provides you with a great response to cache for use with your tests in future!)
So you've cleaned up the codebase, done some restructuring, improved your tests and perhaps even added new features to your project. Time to make a new release!
This process is all about building trust - letting your users and your team know that you know what you're doing. The aim is to show your users that they can trust your changes and that updating won't break any parts of their workflow without their knowledge. Transparency is the key here - you don't want to give your users any hidden surprises.
The most important recommendation would be this: use semantic versioning! With semantic versioning, you follow an x.y.z structure for your version numbers, where:
x is the major version, which you should raise when you make breaking changes,
y is the minor version, which you should raise when you add backwards-compatible functionality, and
z is the patch version, which you should raise when you make a bug fix, dependency update etc., in a backwards-compatible way.
To give a real-life example, when adding support for the Vonage Messages API (but not changing anything that would make the new release backwards-incompatible), I made a minor release, from v2.7.0 -> v2.8.0. When I wanted to remove some deprecated methods and change how objects are instantiated in the SDK, I knew this would break existing functionality, so I made a major release, v2.8.0 -> v3.0.0. When I found a bug in the new code, I fixed it and updated the SDK with a patch release, v3.0.0 -> v3.0.1. Following these rules tells a user exactly what to expect when they upgrade to the latest version. If you make a major release, they know to expect a breaking change!
Whenever you make a new release, update the changelog, so a user knows what to expect. It's often the first place a user will look as it typically spells out all the differences in the new version and can help them to decide if they should update. If you don't update the changelog, users will not know what to expect from a new version and consequently will be a lot warier.
Similarly, when you make a new release, keep documentation, READMEs and code samples up to date with the latest version. If you don't do this, your users won't necessarily know how to use all your great new features, and if you've made a breaking change, your docs and code samples might stop working completely.
Remember, transparency is key - be predictable, so the project's long-time user can trust that the code they rely on is in safe hands, and new users can learn how to use your software.
When you start changing code, you'll likely want to restructure/refactor a lot of it. As long as this doesn't change how any of the code is called by a user, this can be done to your heart's content. However, if you want to change how something is called, you'll need to deprecate the old method and add the new one in a minor release, then remove the old one in a major release later on.
I'll give a specific example here. In the Vonage Python SDK, I wanted to change how the get_standard_number_insight method was called by a user. Originally, this was a method associated with the Client class. I wanted to change the structure by having a NumberInsight class that contained this method, that the Client class instantiated and used. This would make this way of calling the Number Insight API the same as the way a user would send SMS messages or make voice calls.

First, I created a NumberInsight class and added a version of the get_standard_number_insight method to it.
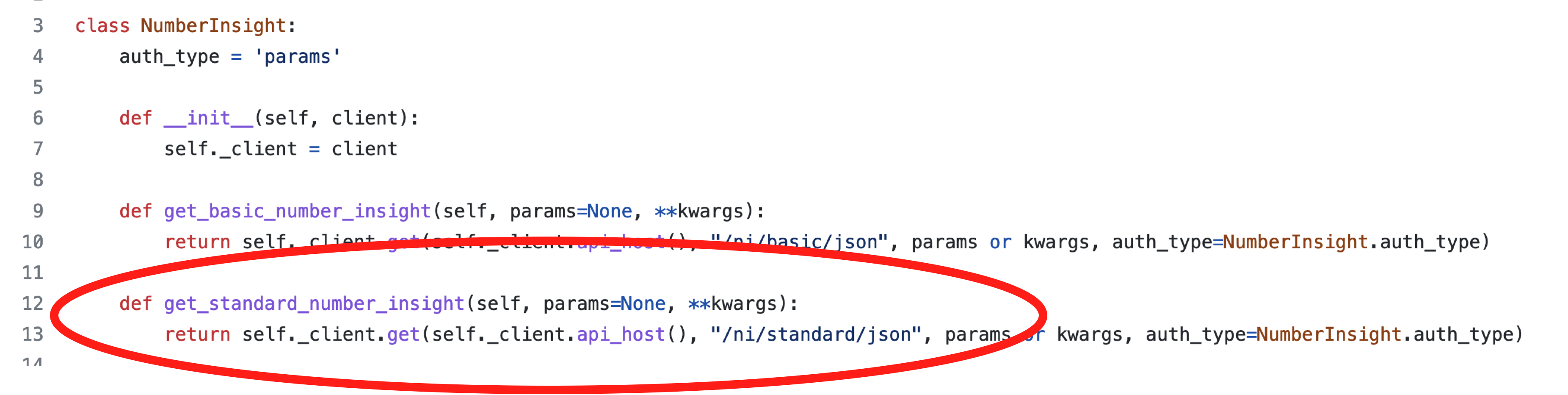
Next, I deprecated the method in the Client class. In Python, this can be done by adding a decorator that prints a deprecation warning to the user when they use the method.

After this, I updated code snippets and docs to reflect the change.
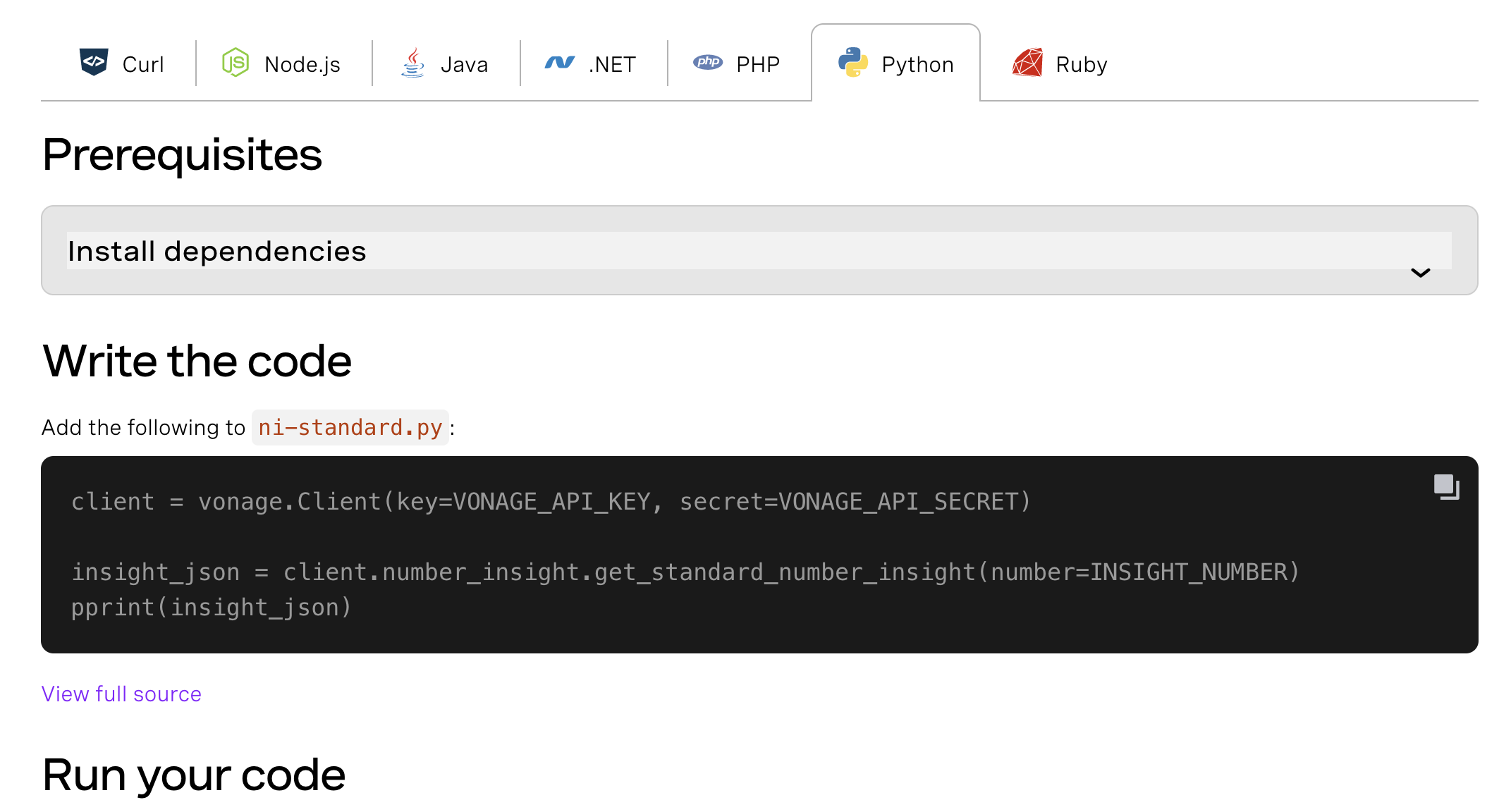
Now I was able to make a minor release. After a release where you deprecate functionality, it's good practice to leave the deprecated parts alone for a while before removing them, to allow sufficient time for people to switch over. I would suggest leaving the deprecated functionality in for at least one release, or one month - whichever is longer. Again, this is all about building trust.
I left this old code for a few months, then made a major release where I removed the old ways of calling these methods. Being methodical and transparent about what my intentions were meant that my users knew what to expect when they updated to the latest version.

The final thing to consider when you start to work on an legacy codebase is that you probably won't have infinite time to polish the code the way that you like it before you have to add new features, fix bugs etc. You'll likely have other priorities to juggle, e.g. deadlines to add new functionality, at the same time you're trying to make big changes to old code.
In this case, you need to be comfortable advocating for yourself and your work. Set the expectation that part of your time needs to be spent on improving the legacy codebase, which means you won't be as quick at developing new features as your boss might like. Stress that the time you spend refactoring now will help you understand the codebase and pay dividends later on, as it will be much easier to maintain.
Ultimately, your work on a legacy project should improve the user experience and its long-term ease-of-use and ease-of-maintenance. You might not recieve immediate praise for dealing with technical debt, as the work isn't visible to your users or your team right away, but managing technical debt can stop things being much worse for everyone later - this work is very much worth doing!
Something that helped a lot with this process was creating work tickets for discovery and learning, to show I was investing in future efficiency. I also created tickets for technical debt, to give my team insight into the work I was doing, alongside the tickets for developing new features. This approach helped me build trust within my company and allow people to understand how I was spending my time, and I can't recommend it enough.
If you followed the suggestions in this article, your project will be looking much better already! The releases you make will lay the groundwork for all the great things you want to do with your project.
Click here to read Part 3 of the series, where I'll explain ways to take your project to the next level. We'll talk about enhancements that benefit your users, as well as things that make the codebase easier to work with. Finally, we'll explain best practices for handing over a project.
Have a question/want to share your thoughts? You can reach out to us on our Vonage Community Slack or send us a message on Twitter.
Share:
Max is a former member of the Vonage Team. He was a Python Developer Advocate and Software Engineer, interested in communications APIs, machine learning, developer experience and dance! His training is in Physics, but now he works on open-source projects and makes stuff to make developers' lives better.