
Share:
Benjamin Aronov is a developer advocate at Vonage. He is a proven community builder with a background in Ruby on Rails. Benjamin enjoys the beaches of Tel Aviv which he calls home. His Tel Aviv base allows him to meet and learn from some of the world's best startup founders. Outside of tech, Benjamin loves traveling the world in search of the perfect pain au chocolat.
How to Build an Intent Classification Hierarchy
Time to read: 10 minutes
Conversational AI agents are a great way to save your company its most important resource: employee time! Agents are like interactive FAQs except much more flexible. When built correctly, they can drastically help improve your customer experience. But the question is, how do you build them correctly?
Thankfully, the team at AI Studio has done the hard work for you! We’ve been able to improve performance on large AI agents (50+ Intents) considerably. These techniques have resulted in some agents seeing a 55% increase in successful calls and an 83% reduction in requests for human agents.
This post will cover how to build a hierarchy in Intent Classification to improve your agents’ performance in routing users to the correct intent. Topics will include general NLU best practices, examples of building a hierarchical classification, and tips on designing your Conversational AI agent in AI Studio.
What is NLU? Natural Language Understanding, or NLU, is the process that allows a computer to understand the intention of a piece of text. NLU is how a computer understands what a user means when they speak with the computer. The software does this through Intent Classification and Entity Extraction.
Intent Classification seems pretty straightforward, right? The Agent just breaks down the user input and maps it to your defined intents. But in practice, it is very easy to confuse the model.
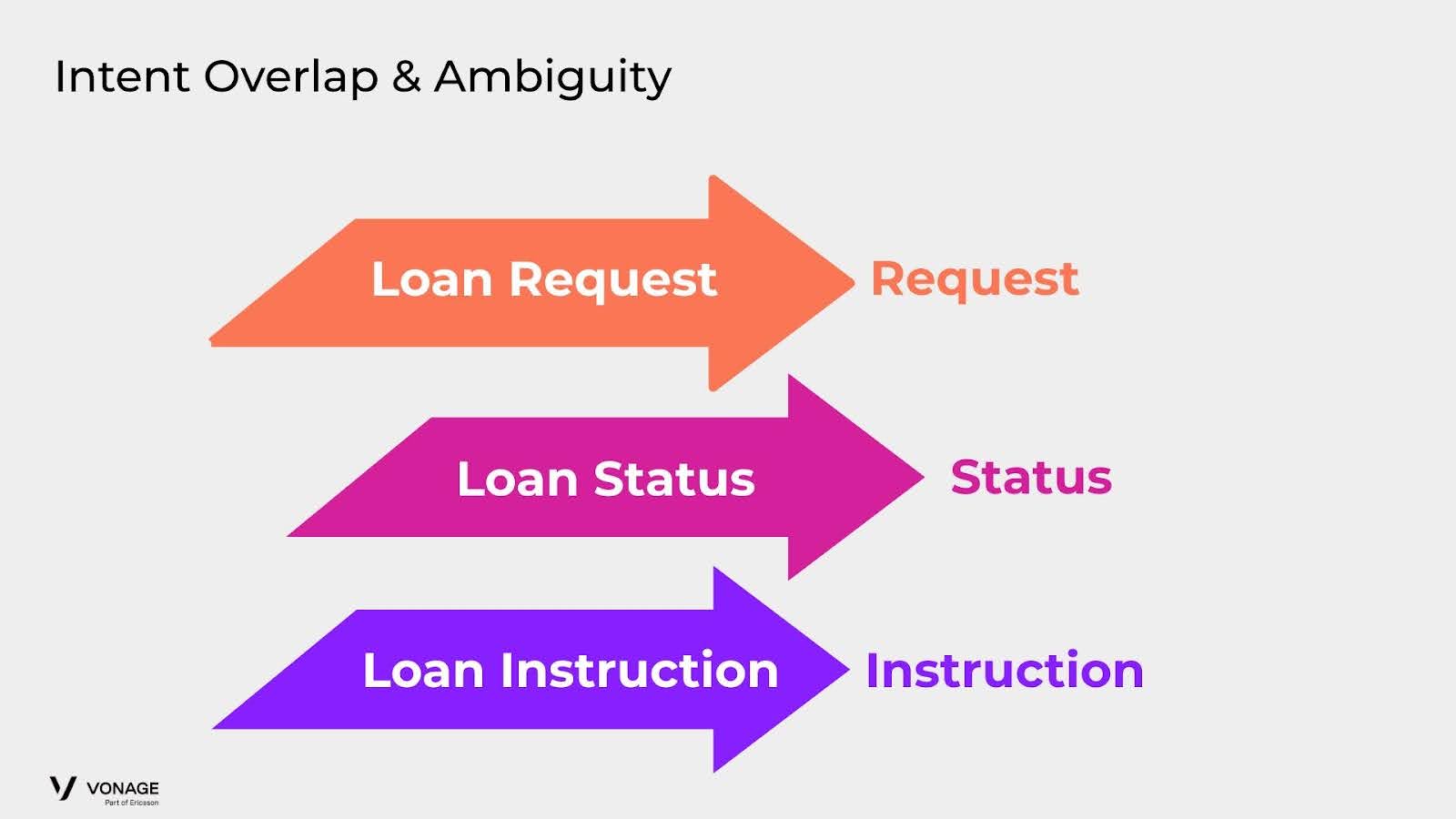
Consider the scenario of an agent designed for a financial institution such as a bank. Within this context, customers may initiate various interactions related to loans, such as making a Loan Request, checking Loan Status, or seeking general Loan Information.
The challenge arises when the terms like "loan" or "mortgage" are employed in diverse contexts, such as in phrases like "talk with mortgage representative" or "get mortgage offer." This widespread use of the same keywords within a single classification node can potentially result in misclassification by the model.
To mitigate this issue, we propose implementing a hierarchical structure with two layers, essentially comprising two classification nodes. The first layer would focus on classifying the core concept, such as "loan" or "mortgage," while the second layer would specialize in discerning the specific action or intent associated with the user's query (request, status, representative, etc). This hierarchical approach aims to enhance the model's precision and reduce the likelihood of misclassifying similar but contextually distinct intents.
 Intent Overlap & Ambiguity
Intent Overlap & Ambiguity
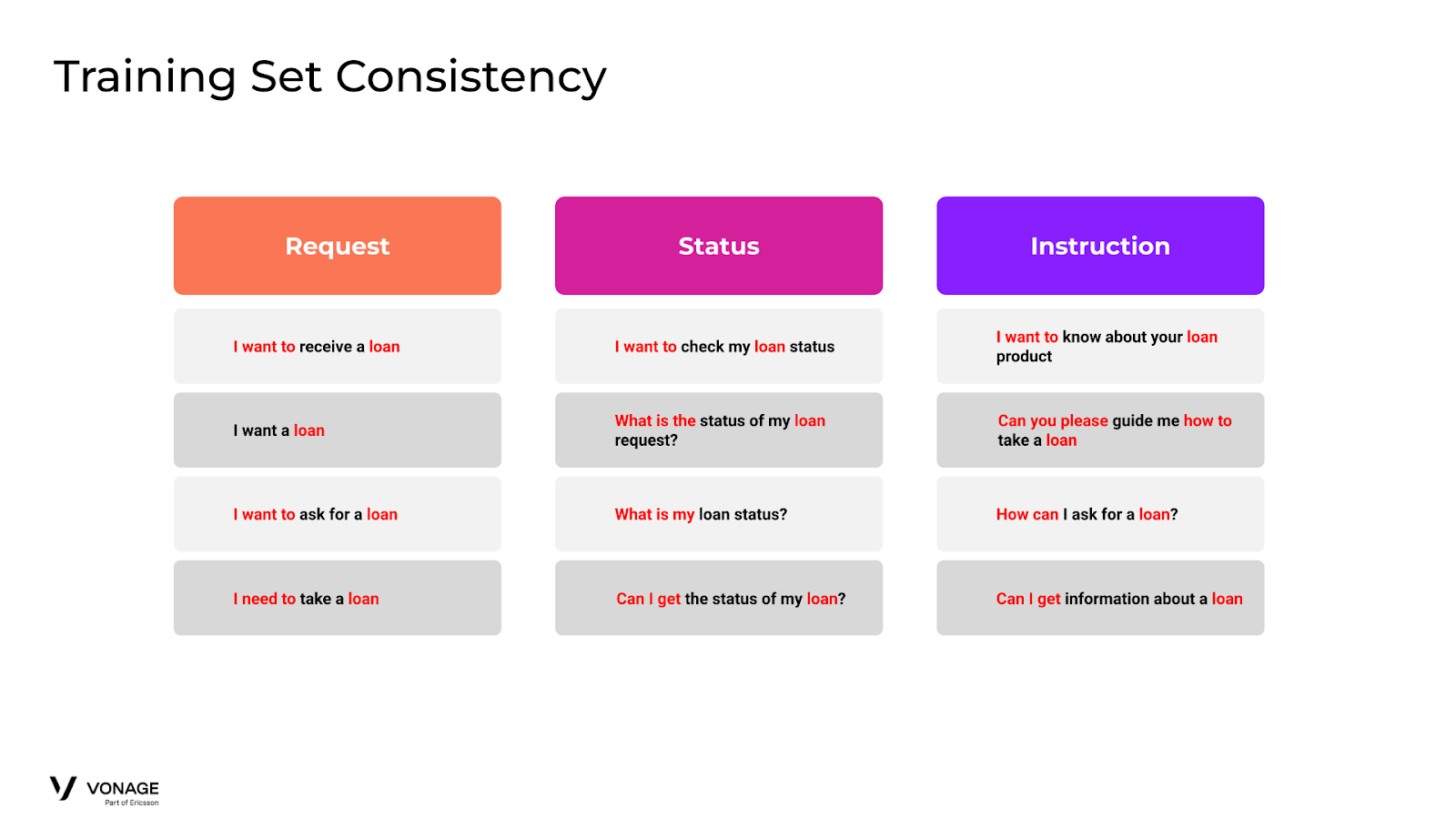
Additionally, because the training sets that make up each intent will have very similar expressions we need to be extremely consistent. Adding ambiguous words in your training sets can cause unexpected behavior if applied inconsistently.
For instance imagine your (Loan) Request intent contains the expression, “I want to ask for a loan”. Now a user asks your agent, “I want to ask for a loan status”, which should route them to (Loan) Status. Unless your training set for Status includes an expression with the phrase, “I want to” and “loan”, there is a very high probability that it will route incorrectly to Request. To solve this problem, your training data needs to be extremely consistent with ambiguous filler/supporting words. So either add it everywhere or remove it everywhere. Often it’s easier to omit.
 Training Set Consistency
Training Set Consistency
Now imagine that we wanted to add two new intents to our Bank agent: Call Back and Sales. Call Back is for users wanting a customer support representative to call them back and Sales is for someone from the Sales department to call them.
 Inconsistent Training Example
Inconsistent Training Example
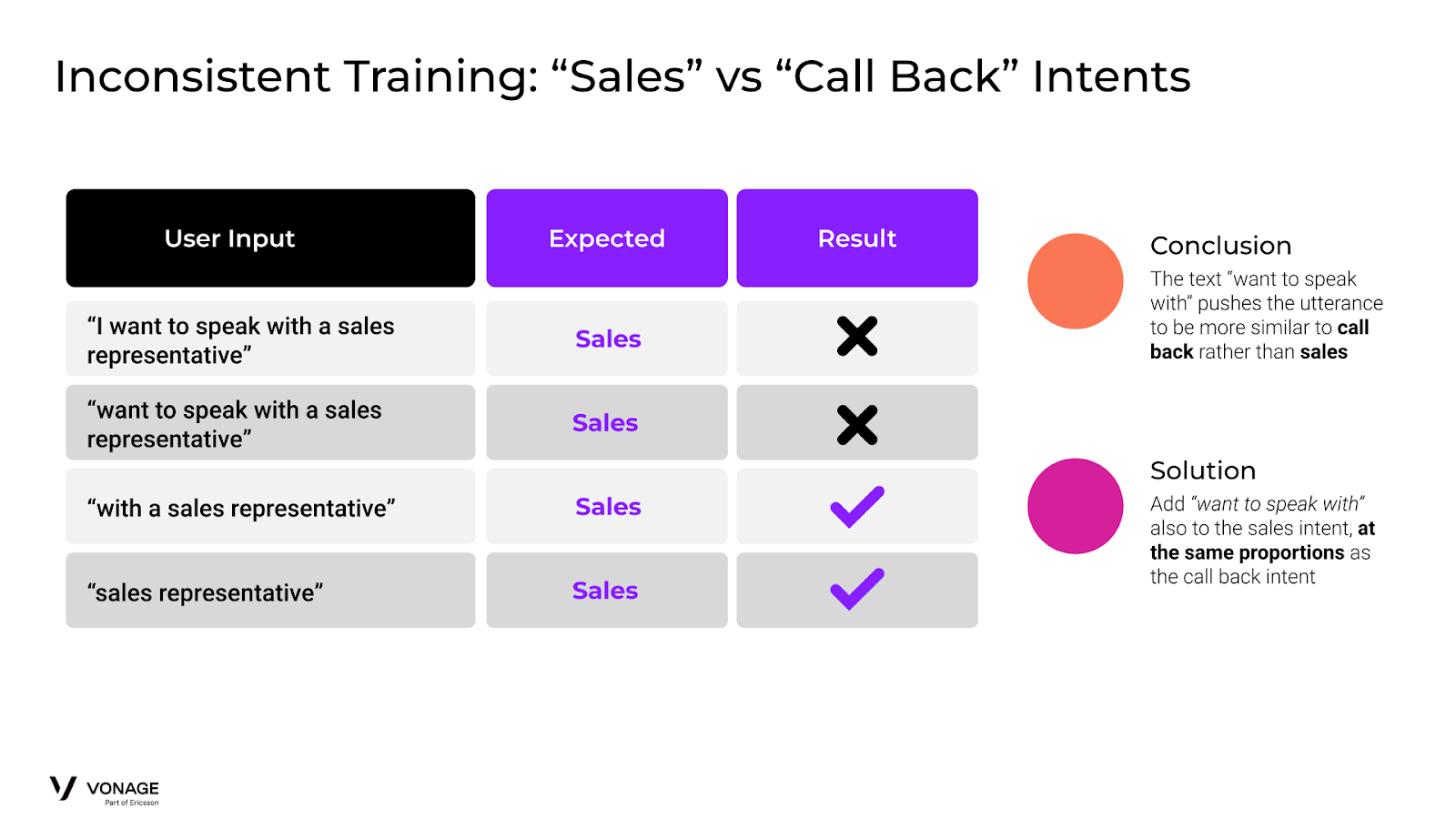
We expect all the following to be classified as “sales”:
I want to speak with a sales representative
want to speak with a sales representative
with a sales representative
sales representative
However, as we see in the diagram, the first two user inputs that have “want to speak with” end up being classified as “call back”. That’s because the words “speak with” are more similar to call back than sales.
The solution is to add training data to our “sales” intent that contains “want to speak with”. It should be in the same proportion as the training data for similar training data in the “call back” training set.
In a more complicated agent, these two intents may look very similar compared to other intents. We’ll see shortly how hierarchical classification will help our agent get to the point where it can make this more granular distinction.
Sanitizing our Intents to avoid Intent Overlap and ensuring our Training Sets are consistent are a good start to improving Classification but once we start to have agents with lots of intents, it won’t be enough as the world is full of inevitable overlap. And those pesky users never behave as we want them to!
Hierarchical Classification helps with these large-scale agents as it creates levels of classification to only focus the classification on one variable or topic at a time. By classifying in stages, the agent is most effective by categorizing intents into groups by their biggest differentiators. Grouping by greatest differentiation helps to eliminate overlap and ambiguity.
Breaking down our classification into stages may seem straightforward, but quickly we see that there are different ways to group intents. We can either group them by their nouns or their verbs.
Nouns are the items in your agent that a user may inquire about. Think about these as the direct objects of their request. Most often these are the products or services that your business offers. Examples of nouns would be “late check-out”, “birthday package”, and “1:1 consultation”.
Verbs on the other hand are the the action someone wants to take on the noun. Consider the differences between the customer requests of 'BOOK a reservation', 'CANCEL a reservation', and 'CHANGE a reservation'.
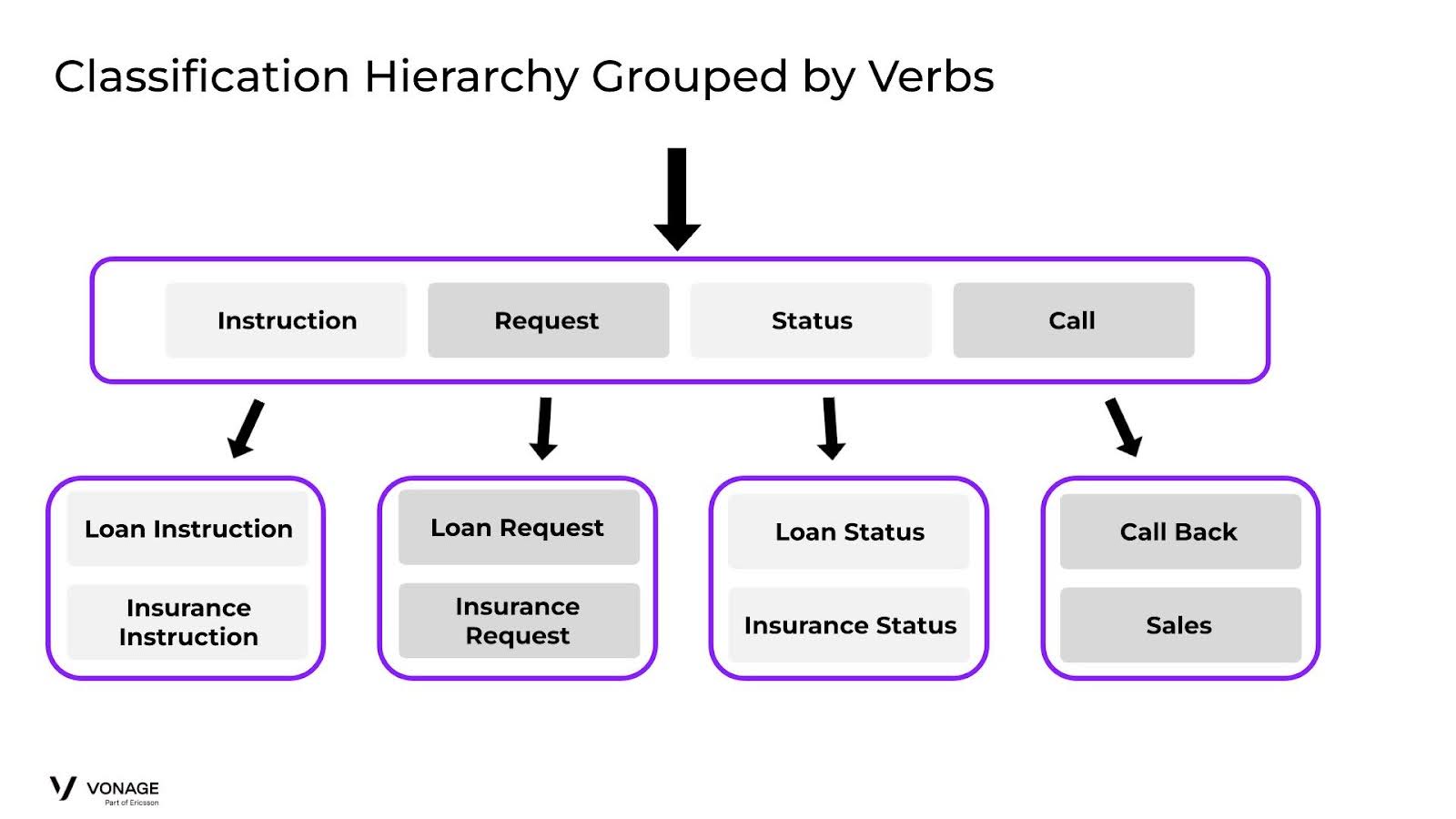
Imagine that we expand our Bank scenario. Instead of just offering Loans, we also want to start offering Insurance. For Insurance, we also give the user the option to Request Insurance, Check on Insurance Status, and General Insurance Information. Our classifier now needs to compare the user input across lots of training data, which inherently will begin to overlap.
This is exactly the scenario where hierarchy will improve our agent's performance. The first step is to group our topics. In this example, we have a few ways we can group the topics. We could either group them by product or by services.
This diagram illustrates how we might group by verbs:
 Hierarchy Grouped By Verbs
Hierarchy Grouped By Verbs
While the groups make logical sense and we might pass the initial classifier with high results, what will happen in the second stage of classification? As we saw earlier, the classifier will have issues with the second round as high ambiguity is likely when comparing user input-looking things like Loan Instruction and Insurance Instruction. In these instances, there will be high overlap in the Training Sets and we’ll need to be very meticulous to keep the data consistent.
Now, let’s try to see what happens when we group the Intents by nouns:
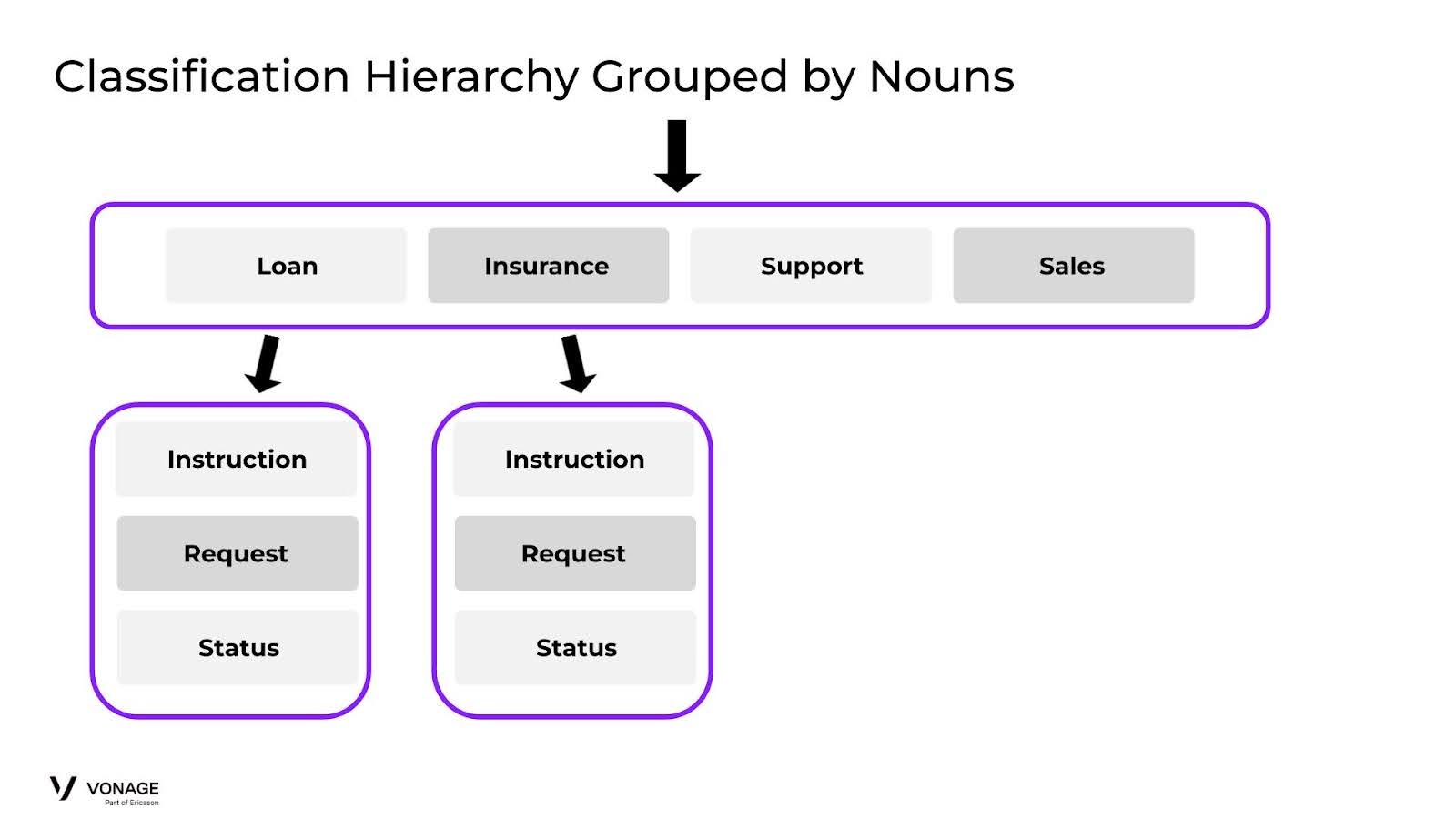 Hierarchy Grouped By Nouns
Hierarchy Grouped By Nouns
What we see here is that not only do we remove a layer of complexity in immediately differentiating between Support and Sales, but more importantly we create groupings in the 2nd round that are much easier to classify. In each group of Loans and Insurance, each Intent can be stripped down to have very little overlap as we did earlier.
Now that you understand the theory, let’s jump in with a practical guide.
If you have real-world data, that’s awesome you’re ahead of the game! Jump to number step 2, you can focus on the core training data and leave out any outliers for now.
Otherwise, imagine that your users speak without using filler words or unnecessary extra words. Now write out all the user expressions you can think of. This is your idealized training set.
Imagine all the possible synonyms for your products/offerings.
Example: room/reservation/booking/stay
Just as we organized the Bank topics into broad groups around nouns, you too should group your topics into broad Noun/Noun Phrase categories. At this point, you can start to identify the supporting verbs/verbs.
In the real world users behave kind of like cavemen. Very often they reply with single words, much more often nouns than verbs. Grouping around nouns will lead to much higher performance.
Where is the greatest potential for high ambiguity? For the highly ambiguous cases, add training data to standardize and create uniform phrases across the different groups. Just as you saw with the example of Sales vs Call Back Intents above, normalize the training data for groups with high ambiguity.
After you’ve solved most use cases, you may find that you still have some intents that don’t fit in your broad-scope topics. Where should you account for these?
You should add these intents at the point where they have the greatest ability to be negated by your model. Consider you have an agent for a Nutritionist and one of your intents is to Healthy Foods. However, a user asks, “Can I order a pizza?”. The model will most likely push the user to the “Healthy Foods” intent, even though a pizza shouldn’t go there. See the diagram:
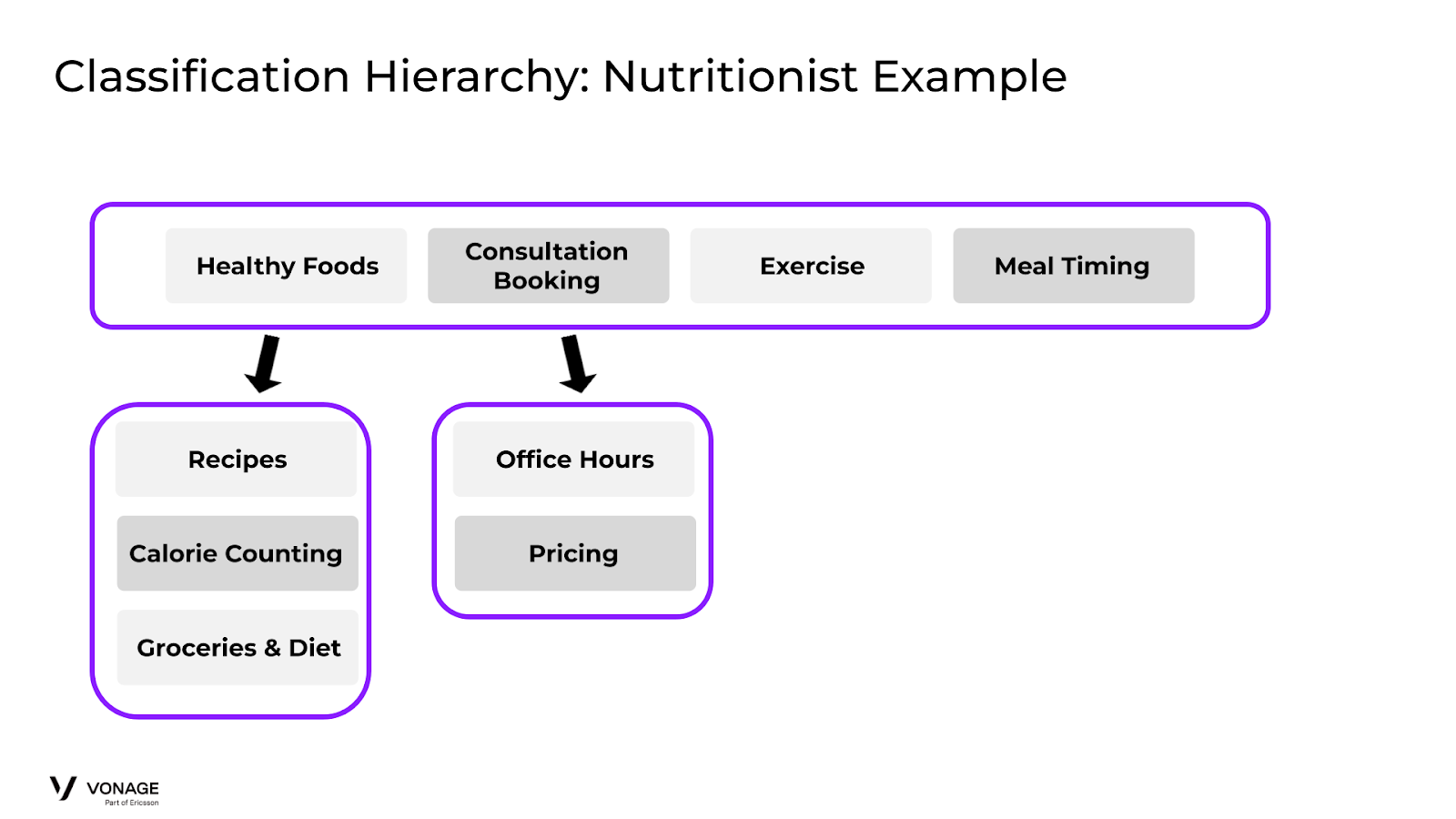 Classification Hierarchy: Nutritionist Example
Classification Hierarchy: Nutritionist Example
Our solution is to create a new “negative” intent to capture the default behavior and route it accordingly. So we create an “Unhealthy Foods” intent that will capture these “negative” cases and direct it to the right flow. Our updated classification:
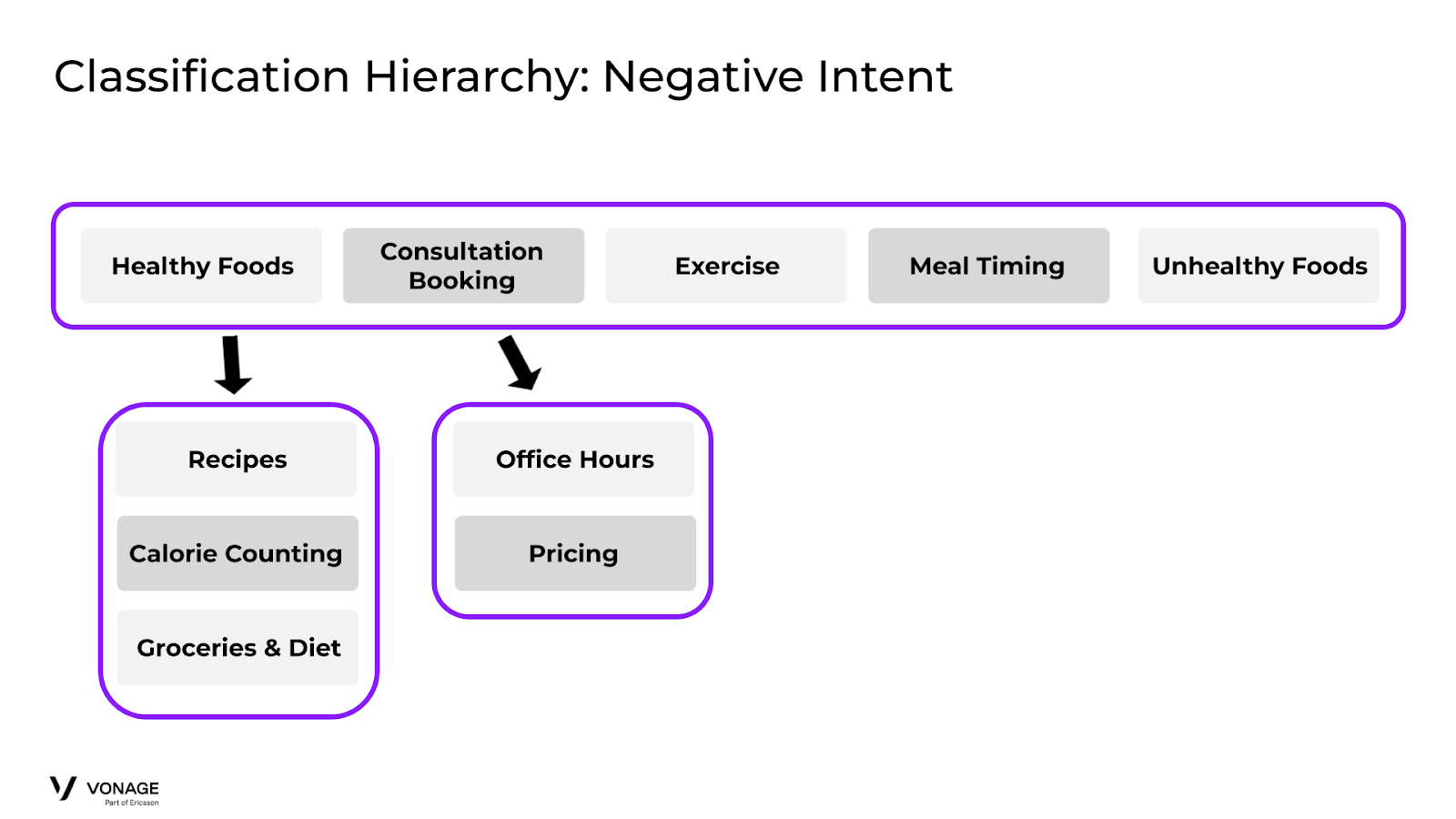 Classification Negative Intent Example
Classification Negative Intent Example
AI Studio makes it easy to get started quickly and start building out agents with drag-and-drop nodes. However, as your agent starts to scale, it becomes very difficult to keep track of dozens or hundreds of nodes. Not only will agent organization become unmanageable but the Studio will start to become slow in the browser window, loading a large number of nodes.
It’s best to get ahead of these issues by planning out your agent ahead of time and using the Subflow feature. For best practices, each intent should have its own subflow. Each of these subflows will join at a Topic Group Level. Each of these Groups will then flow up to a main level. Creating a Hierarchical Classification before you start working makes organizing your subflows a breeze and helps prevent creating future technical debt.
After you’ve created the first version of your agent, you might find that your hierarchy has “leakage”. A small number of users may accidentally end up in the wrong flow. Instead of breaking your head to re-engineer the perfect hierarchy model, just “Go with the Flow!”.
For example, consider this example where a hotel had a premium restaurant package called the “Eagles Nest”. Users will ask for “premium offering for the Hotel” or use other terminology because they don’t know it’s called “Eagles Nest”. There was a top-level classifier for the Hotel and a top-level classifier for “Eagles Nest”. There was so much training data for Hotel, that user inquiries often ended up in Hotel instead of Eagles Nest. So instead of redesigning the whole agent over, we can add a subflow in Hotel, which then leads back to Eagles Nest. In the final agent, this subflow may live in 3 or 4 different places because it all depends on how someone may ask for it.
In addition to users giving way too simplistic inputs, often they will say the subject they have a question about rather than a detailed question. A great way to handle this and improve user experience is to create a “catch” intent at your highest level of classification.
For example instead of saying, “I want to make a booking with a Dr. Smith for surgery.”, they will say, “Booking question” or “Surgery question”.
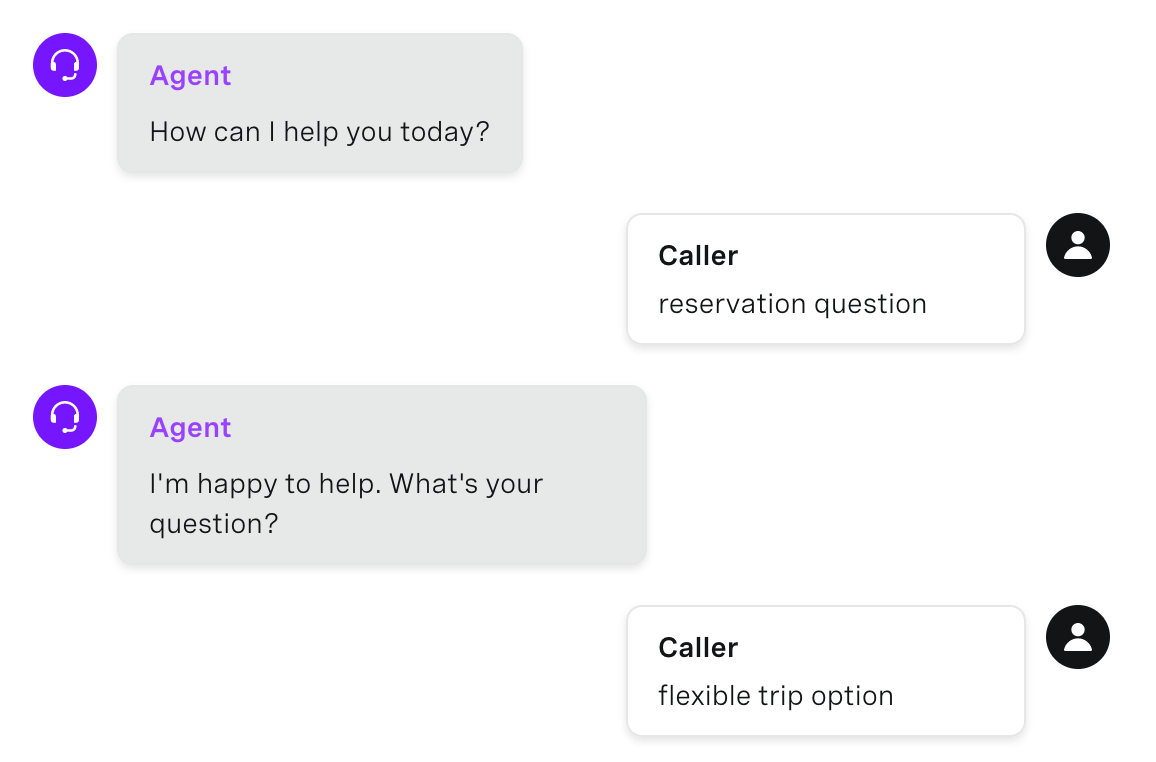 Question Deflection Example
Question Deflection Example
We found that adding this simple catch-all for inputs about questions helped create confidence in the users that the virtual agent would be able to help them.
Now that you’ve seen the power of Classification Hierarchy in Conversational AI agents, you can go and make your agents much better at answering your users! Remember these steps and you’ll be the hero at your company:
Review training data
Organize the data, identify where there’s potential for high ambiguity
Create a hierarchical classification
Build out agent
Test, test, test
If you enjoyed this article let us know on Vonage Developer Community Slack. This post was inspired by a question from a community member there! You can also follow us on X, formerly known as Twitter, for the latest Vonage API news.
Share:
Benjamin Aronov is a developer advocate at Vonage. He is a proven community builder with a background in Ruby on Rails. Benjamin enjoys the beaches of Tel Aviv which he calls home. His Tel Aviv base allows him to meet and learn from some of the world's best startup founders. Outside of tech, Benjamin loves traveling the world in search of the perfect pain au chocolat.