
Share:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.
Enhance Video Conferencing with ChatGPT: Meet Your Live AI Assistant
Time to read: 6 minutes
Technology, especially artificial intelligence, has changed the way we talk and work online. As the world increasingly shifts towards online interactions via webinars, conferences, and one-on-one meetings, there's an undeniable need for a tool that can enhance the productivity of these virtual gatherings.
Picture this: an AI assistant at your side during these virtual rendezvous, ready to answer queries, take notes on action items, and distill essential information into concise summaries. Today, we are creating such an assistant, focusing primarily on one-on-one conversations. However, the possibilities are limitless, with this concept applicable to many scenarios. So, without further ado, let's build “Sushi”!
Here you can find a video demo:
A Vonage API account. Access your Vonage API Dashboard to locate your API Key and API Secret.
An OpenAI Account and API Secret
Node 16.20.1+
npm
To setup the app on your machine, first clone the repo.
git clone https://github.com/hamzanasir/vonage-openai-demoNow move into the repository and install the associated packages via:
npm installNow we need to set up our Vonage API Key and Secret. Let’s start by copying the .env template:
cp .envcopy .envNow all you need to do is replace the API Key and Secret in the .env file with your credentials. You can find your API Key and Secret on the project page of your Vonage Video API Account (https://tokbox.com/account). Your .env file should look like this:
# enter your TokBox API key after the '=' sign below
TOKBOX_API_KEY=your_api_key
# enter your TokBox api secret after the '=' sign below
TOKBOX_SECRET=your_project_secretYou also need to create an OpenAI project. You can do this by going to https://platform.openai.com/signup. Once you’re signed up you can go to the API Keys section to Create a new secret key.
Paste your secret key in the .env file.
# enter your OpenAI Secret after the '=' sign below
OPENAI_SECRET=your_openai_secretNow that that’s done, you can start the app with:
npm startNow go to http://localhost:8080/. To start conversing with Sushi, make sure you hit the start captions buttons on the bottom left to start Vonage’s Live Caption service. For the best experience, make sure you’re wearing headphones, so Sushi’s voice doesn’t feedback to the publisher microphone.
All of the code we talk about in this blog can be found in the public/js/app.js file. If you’re curious about how Live captions work, be sure to check out the routes/index.js file to see how the caption service starts and stops.
To grasp the inner workings of our virtual assistant, let's delve into its architectural framework.
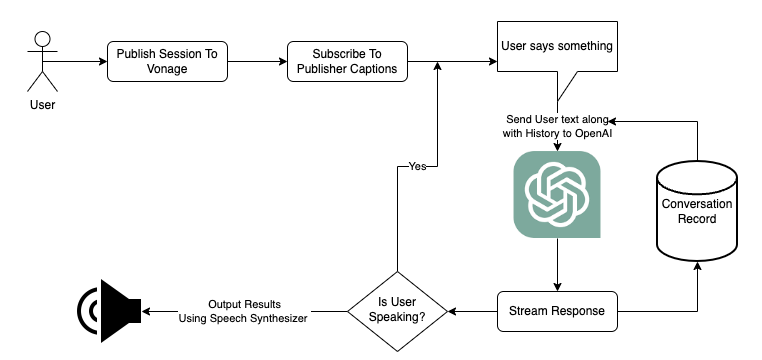
At the heart of this setup lies the management of user conversations and interactions with OpenAI's API. We've chosen OpenAI's GPT-3.5 Turbo model, which excels in handling conversations. However, OpenAI offers a variety of models to suit your specific project goals.
When we send a request to GPT, it takes a moment to craft a response. Let’s take a more dynamic approach. We stream the data as it's being generated, ensuring a faster and more natural conversation experience. This approach also empowers users to interrupt and guide the conversation, mimicking real-life interactions.
As GPT formulates its response, we convert the generated text into audible speech using a speech synthesizer. Various options are available for this purpose, including paid third-party speech synthesizers that can deliver a more natural-sounding voice. For our project, we've opted for the browser's native SpeechSynthesisUtterance module. To manage Interruptions from the user speaking, we will be using the browsers AbortController.
Let's dive into how we initiate and manage our captioning service, a pivotal component in our system.
To kick things off, we fire up the captioning service by calling our server via POST at /captions/start, providing it with our Session ID. With this setup, we're ready to receive captions for all the subscribers in the session. However, we also want our own captions to be generated as the publisher. To achieve this, we subscribe to our own publisher with zero volume, ensuring that we don't get a repeat of our own voice.
Here's a snippet of the code that makes this happen:
const publisherOptions = {
insertMode: 'append',
width: '100%',
height: '100%',
publishCaptions: true,
};
publisher = OT.initPublisher('publisher', publisherOptions, (err) => {
if (err) {
handleError(err);
} else {
session.publish(publisher, () => {
if (error) {
console.error(error);
} else {
const captionOnlySub = session.subscribe(
publisher.stream,
document.createElement('div'),
{
audioVolume: 0
},
);
speakText(greetingMessage);
captionOnlySub.on('captionReceived', async (event) => {
if (event.isFinal) {
stopAiGenerator();
startAiGenerator(event.caption)
}
});
}
});
}
});
In this code, we publish our audio and video to the session and then subscribe to the same instance to receive our captions. To make this process work seamlessly, we attach a 'captionReceived' event handler to our mock subscriber. This event handler captures the transcription of our speech as we speak. Since this event is usually triggered periodically as we talk, we use the 'isFinal' boolean to identify when we've finished speaking. Once our generated text is ready, we pass it to our startAiGenerator for further processing.
The backbone of our logic lies within the startAiGenerator function. Since it's a hefty function, let's break it down into manageable pieces. First, let's take a closer look at the logic for making API calls:
async function startAiGenerator(message) {
let aiText = '';
let utterableText = ''
abortController = new AbortController();
const userMessage = {
'role': 'user',
'content': message
}
const reqBody = {
messages: [...messages, userMessage],
temperature: 1,
max_tokens: 256,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
model: 'gpt-3.5-turbo',
stream: true
};
try {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
headers: {
'Authorization': `Bearer ${openAISecret}`,
'Content-Type': 'application/json',
},
body: JSON.stringify(reqBody),
method: 'POST',
signal: abortController.signal
});In this snippet, we have two variables, aiText and utterableText. aiText stores the complete response to our query, while utterableText captures the last complete sentence or phrase from the readable stream of data received from OpenAI. We also set up an AbortController instance to handle user interruptions while the assistant is speaking. Before we commence the AI generator, a separate function, stopAiGenerator(), is called to halt any ongoing AI generation process.
function stopAiGenerator() {
if (abortController) {
abortController.abort();
abortController = null;
}
window.speechSynthesis.cancel();
}Lastly, we call OpenAI with the history of the conversations stored in the global messages array. Now let’s take a look at how we stream data from OpenAI:
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
while (true) {
const chunk = await reader.read();
const { done, value } = chunk;
if (done) {
break;
}
const decodedChunk = decoder.decode(value);
const lines = decodedChunk.split('\n');
const parsedLines = lines
.map(l => l.replace(/^data: /, '').trim())
.filter(l => l !== '' && l !== '[DONE]')
.map(l => JSON.parse(l));
for (const line of parsedLines) {
const textChunk = line?.choices[0]?.delta?.content;
if (textChunk) {
utterableText += textChunk
if (textChunk.match(/[.!?:,]$/)) {
speakText(utterableText);
utterableText = '';
}
aiText += textChunk;
}
}
}
In this segment, we initiate the reader from the fetch object we used to request GPT. We employ a while loop to continuously read from the stream until it's depleted. For each chunk of text, we append it to the two variables defined earlier. If a chunk includes a punctuation mark, we trigger the speakText() function, which vocalizes the most recent sentence or phrase generated and resets utterableText to an empty string. Keep in mind that this process can be halted at any point using a stop signal from our AbortController.
Lastly, whether we terminate the stream or allow it to complete, we save both the user's input and OpenAI's response as follows:
messages.push(userMessage);
messages.push({
content: aiText,
role: 'assistant'
})
"Prompt engineering" in natural language processing entails crafting instructions or questions to guide AI models. It's about finding the right balance between clarity and ambiguity to achieve specific outcomes. With the proper prompt engineering, you could turn Sushi into a mock law advisor, medical expert, sassy friend, etc. For this demo, we’re using this prompt:
const messages = [
{
'role': 'system',
'content': "You are a participant called Sushi in a live call with someone. Speak concisely, as if you're having a one-on-one conversation with someone. " // Prompt engineering for AI assistant
}
];Try changing the content of this code to see how the assistant will behave!
This section of this project has room for flexibility. You can choose to opt for more natural, advanced solutions for speech synthesis. Most of these will be paid, so in this demo, we’re opting for the browser’s default SpeechSynthesisUtterance functionality.
function speakText(text) {
let captions = '';
const utterThis = new SpeechSynthesisUtterance(text);
utterThis.voice = voices.find((v) => v.name.includes('Samantha'));
utterThis.onboundary = (event) => {
captions += `${event.utterance.text.substring(event.charIndex, event.charIndex + event.charLength)} `;
displayCaptions(captions, 'ai-assistant');
};
utterThis.onstart = () => {
animateVoiceSynthesis();
};
utterThis.onend = function() {
stopAnimateVoiceSynthesis();
};
window.speechSynthesis.speak(utterThis);
}
So first, we initialize the SpeechSynthesisUtterance module with the text we want to utter. After that, we need to set a voice available from the browser. These are loaded asynchronously like so:
let voices = window.speechSynthesis.getVoices();
if (speechSynthesis.onvoiceschanged !== undefined)
speechSynthesis.onvoiceschanged = updateVoices;
function updateVoices() {
voices = window.speechSynthesis.getVoices();
}We use the onstart and onend events to animate the bars in the middle to illustrate when Sushi is speaking. Additionally, the onboundary event is used to insert text captions to display what word the speech synthesizer is speaking.
It’s important to note that this is just an example of what you can do with an integration with GPT. The purpose of this demo is to show how you can create the pipeline between Vonage Video Live Captions and OpenAI, but the sky's the limit to what you can build with expertly crafted prompts.
Check out the example section of GPT to see the endless amount of applications. We can’t wait to see what you’ll create!
Let us know what you're building with Vonage Video API. Chat with us on our Vonage Community Slack or X, formerly known as Twitter, @VonageDev.
Share:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.