
Share:
IOS Developer turned Data Science / Machine Learning enthusiast. I want people to understand what machine learning is and how we can use it in our applications.
Building a User Churn Prediction Model with Scikit-Learn and Vonage
Time to read: 13 minutes
Vonage’s Conversation API allows developers to build their own Contact Center solution. With voice, text, and integrations to other solutions, Vonage allows you to build a complex solution, without the development being complex.
When building your contact center solution, you need it to be smart. The most powerful solutions use AI to route calls, translate text, recommend products and so on. What's great is that you don’t have to be an AI researcher with a Ph.D. to integrate AI into your application. You also don’t have to rely on a 3rd party system. This seems impossible at first, but there has been lots of progress on many machine learning libraries so that you, as a developer, can build a machine learning system into your solution. In this post, we’ll look into adding a way to predict the likelihood of a customer churning.
Churn, by definition, is the number of customers who stopped using your product, divided by the number of total customers. For example, a company with a 1% churn per month with 1000 customers means that 10 out of 1000 customers stop using the company's service each month. It is used as an indicator of how well the company is doing. A company with low customer churn usually means that the customers are sticking around. Higher churn means that customers are using the product or service, but then leave.
A contact center is one place where customers interact directly with the business, especially with customer service. And losing a customer with bad support could have an impact on churn, and therefore, your health as a company.
In this post, we'll go over how to build an application that simulates a conversation between a customer and agent and can predict the likelihood of churn, using the Vonage Conversation API.

In our demo, we have two user personas: a customer and an agent. For this example, we’ll assume the company is a TV service provider, and the customer has a question about their service. We also assume that this customer has been with the company for a while, and we have data to support this.
In our example, we have some information about the user. This could be:
How long in months that the customer has used the service.
Their current payment method. (Check, Credit Card..)
Services that they are using. (live TV, set-top box, streaming services.. )
And many more.
For our demo, when the customer interacts with the agent, we show the likelihood of the user churning on the agent’s screen, as soon as they interact. This could be helpful to the agent before starting the conversation, so that more attention could be given to the customer, depending on the likelihood of churn.
Access to Google Colab
We'll be using Hui Jing Chen's excellent blog post as a starter. We will be adding our churn prediction functionality on top of this application.
To run our application locally, we will clone the repo, and we'll need to use ngrok. If you are not familiar with Ngrok, please refer to our Ngrok tutorial before proceeding.
Before going over the application, we first need to build our model. And to build it, we'll be using Jupyter Notebooks running on Google Colab. A Jupyter Notebook is an interactive way to run code and is widely used in data science and machine learning. Google Colab is a free service that lets you run these notebooks in the cloud. The code to build the notebook is located here.To run this notebook, upload it to Google Colab.
For this tutorial, we will assume you have a basic understanding of what machine learning is, but you won't need to fully understand everything to follow along.
To build a model, we first need data. And for this example, we’ll use Telecom Churn Dataset from IBM. This dataset contains 7043 rows of a telecoms anonymized user data. To get an understanding of the dataset, we'll have a look at the first 10 rows of the data using Pandas. Pandas is a python library for processing and understanding data. For each user, we have 23 columns, also known as features. These include the customer gender (male, female), tenure (how long have they been a customer), and if they have different services, including phone, internet, and TV.
To build our model, we first need to make sure there are no empty values in the dataset. If we don't check for this and try to build our model, we will have errors.
Let’s read in our dataset and remove any empty values.
df = pd.read_csv("/content/WA_Fn-UseC_-Telco-Customer-Churn.csv")
df = df.dropna(axis='columns', inplace=True)Next, use df.head() to view the first 10 rows of the data. When we look at this data, we see that many of the rows contain strings. (YES, NO). We now have to convert these strings into numbers, because machine learning models only know how to deal with numbers.
For each row that contains a string, we need to see if the strings are unique. To view all the possible values in this column, pandas has a function, called unique() to do this for us.
df.Partner.unique()returns: array(['Yes', 'No'], dtype=object)
This means that the row only contains the values YES and NO. For this column, we can convert those strings into booleans(1,0). However, if we look at the other rows, say PaymentMethod, there’s more values than YES or NO.
df.PaymentMethod.unique()returns array(['Electronic check', 'Mailed check', 'Bank transfer (automatic)', 'Credit card (automatic)'], dtype=object)
So for this column, we need to do a little more work. Whenever a value is YES or NO, we can convert it to 1 or 0, respectively. When it's any other string, let's set it to -1. Again, the machine learning model can only use numbers, so that’s why we set it to -1.
If we look at the other columns, PhoneService, MultipleLines, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, and StreamingMovies, they appear to be similar. So let's write a function that goes through each column and converts our strings into ints.
numeric_features = ['Partner', 'Dependents', 'PhoneService', 'MultipleLines','OnlineSecurity', 'OnlineBackup','DeviceProtection', 'TechSupport','StreamingTV', 'StreamingMovies', 'PaperlessBilling', 'Churn']
def to_numeric(s):
if s == "Yes":
return 1
elif s == "No":
return 0
else: return -1
for feature in numeric_features:
df[feature] = df[feature].apply(to_numeric)Numeric_features is a list of all the columns that we need to update. to_numeric is a function that takes in the value from every row and converts the string to an int. Finally, we’ll loop through all the items in to_numeric and call the pandas function apply to call our function. Let’s have a look at the first 10 rows to verify.
It looks like those rows are now valid, but we have to deal with the other columns. Let's first inspect Contact and see the shown values.
df.Contract.unique()which returns: array(['Month-to-month', 'One year', 'Two year'], dtype=object)
These values are still strings, but it's not as easy as converting to 1's and 0's. There are other columns in this dataset that are similar, including PhoneService, MultipleLines, InternetService, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, StreamingMovies, Contract, PaperlessBilling, and PaymentMethod.
Luckily, in pandas, we can convert these values using get_dummies(). This function, when applied to a column, will create a new column for every possible value. And every value in each of these new columns will be 1 or 0. This is also known as one-hot-encoding.
So for example, let’s take the Contract column, which contains the values of Month-to-month, One year, and Two year. Using get_dummies(), we will create 3 new columns called Contract_Month-to-month, Contract_One year and Contract_Two year. And every value in these columns will be either 1 or 0.
categorical_features = [
'PhoneService',
'MultipleLines',
'InternetService',
'OnlineSecurity',
'OnlineBackup',
'DeviceProtection',
'TechSupport',
'StreamingTV',
'StreamingMovies',
'Contract',
'PaperlessBilling',
'PaymentMethod']
df = pd.get_dummies(df, columns=categorical_features)Here, we create a list of these features that we want to convert to categorical and call the get_dummies function using the DataFrame(df) and the list of columns(categorical_features). Let's again view the first 10 rows to double-check our work. Since the DataFrame is now 41 features, we'll link to the cell here rather than showing a screenshot of the DataFrame
It looks like all the columns are numeric. Let's build our model. To build our model, we'll use another package called scikit-learn. Scikit-Learn has many built-in functions to process and train a model with our data.
First, we need 2 matrices, X and y. X is a matrix that includes all of our features except for the feature that we are using to make predictions(Churn). Y is just the value of Churn, which is a 1 or 0.
X = df.drop(labels='Churn',axis=1)
Y = df.Churn
print(X.shape, Y.shape)This returns: ((7043, 40), (7043,)) Which means that there are 7043 rows and 40 columns in X. For Y, we have 7043 rows.
Next, we have to split our data into a train and test set. When training our model, we only use a portion of the dataset. The rest of the data is used for testing. This is to see how well our model has learned the data. Using Scikit-Learn, lets split our dataset using the train-test-split() function.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,Y,test_size=0.3, random_state=42)Finally, we can build a model.
For this example, we will use a simple model. But in the real world, we need to test different models with our dataset to see what's best. This is where a lot of the work lies in machine learning. There are no hard or fast rules for selecting a model for your data. It always depends on the dataset.
For this example, we will use LogisticRegression to train our model. It's a good model to start with since it generally works well with making predictions for boolean values. Scikit-learn makes it very simple to implement this model.
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
model = LogisticRegression()
model.fit(X_train, y_train)Once the model has been trained on the training set, we can now use it on the testing set by calling the predict function, passing in our testing set(X_test).
model.predict(X_test)
# Print the prediction accuracy
print (metrics.accuracy_score(y_test, prediction_test))Using metrics.accuracy_score we can print out our accuracy, 0.8135352579271179 which is ~89%. This means that when our model is given data from the testing set to make a prediction, its result is correct about 89% percent of the time. Note, this accuracy is just one of many metrics when evaluating a model.
Once we have our model, we'll need to save it to be used in our contact center app. To save the model, we use the joblib function dump.
We will also need to save the names of the columns that we used for training as we will use them when we build our server to make predictions.
model_columns = list(df.columns)
model_columns.remove('Churn')
joblib.dump(model_columns, 'model_columns.pkl')Next, we'll build a simple Python server to serve this model.
Next, we will make a Flask app to create a basic server application to host our model. We need a way to host and model and make predictions. If this were a production application, we would need to save the user's information, which would contain the same information that we used for training in our dataset. These would include how long the user has been with the company(tenure), whether they have InternetService, PhoneService, OnlineBackup, etc... This way, when we make our prediction, we would make a query to our database to return the users info, make a prediction from our model and return the likelihood of churning. However, for this example, we will generate the information for a user and send that prediction back to the application.
In server.py, we will make a simple Flask app, which only has one endpoint called /predict. This endpoint will generate the user's data, invoke our model and return the prediction as a JSON response.
Before making the prediction, we first need to load the saved model when the server starts.
app = Flask(__name__)
@app.route('/predict', methods=['GET'])
@cross_origin()
def predict():
#will return prediction
return
if __name__ == '__main__':
model = joblib.load('model/model.pkl')
model_columns = joblib.load('model/model_columns.pkl')
app.run()Here we use joblib to load our model and the columns that we used for training. We need to make sure we have copied model.pkl and model_columns.pkl into our server application. In the predict() function, we'll generate a random user's data, create a new DataFrame from the data using the saved columns names.
def predict():
random_user_data = generate_data()
#https://towardsdatascience.com/a-flask-api-for-serving-scikit-learn-models-c8bcdaa41daa
query = pd.get_dummies(pd.DataFrame(random_user_data, index=[0]))
query = query.reindex(columns=model_columns, fill_value=0)
#return prediction as probability in percent
prediction = round(model.predict_proba(query)[:,1][0], 2)* 100
return jsonify({'churn': prediction})The generate_data() function creates a new dictionary that contains the same columns as our training dataset and assigns a random value to each.
def random_bool():
return random_number()
def random_number(low=0, high=1):
return random.randint(low,high)
def generate_data():
internetServices = ['DSL', 'Fiber optic', 'No']
contracts = ['Month-to-month', 'One year', 'Two year']
paymentMethods = ['Electronic check', 'Mailed check', 'Bank transfer (automatic)','Credit card (automatic)']
random_data = {
'name':'customer',
'Partner': random_bool(),
'Dependents': random_bool(),
'tenure': random_number(0,50),
'PhoneService': random_bool(),
'MultipleLines': random_number(-1),
'InternetService': random.choice(internetServices),
'OnlineSecurity': random_number(-1),
'OnlineBackup': random_number(-1),
'DeviceProtection': random_number(-1),
'TechSupport': random_number(-1),
'StreamingTV': random_number(-1),
'StreamingMovies': random_number(-1),
'Contract': random.choice(contracts),
'PaperlessBilling': random_bool(),
'PaymentMethod': random.choice(paymentMethods)
}
return random_dataFor InternetService, Contract and PaymentMethod, we hard code the possible values that can be used for each, and choose a random value. For the other features, if it only contained a Yes or No value in the training set, we'll assign 1 or 0, randomly, For the features that used Yes, No and some other string, we'll use 1, 0 and -1, respectively.
Next, let's go over our predict function, which is called when there is a request to the/predict endpoint.
@app.route('/predict', methods=['GET'])
@cross_origin()
def predict():
random_user_data = generate_data()
query = pd.get_dummies(pd.DataFrame(random_user_data, index=[0]))
query = query.reindex(columns=model_columns, fill_value=0)
#return prediction as probability in percent
prediction = round(model.predict_proba(query)[:,1][0], 2)* 100
return jsonify({'churn': prediction})Here, we generate data for a random user, then create a DataFrame that looks just the DataFrame we used for training our model. This will have the same columns but only have 1 row of the dataset.
Finally, we'll call predict_proba on the model to return a vector for the likelihood of the user churning. [[0.79329917 0.20670083]] This matrix contains the probability of the user churning (0.79329917) and the use not churning 0.20670083. We'll take the last item in the vector, round to 2 decimal places, and convert into a percentage.
prediction = round(model.predict_proba(query)[:,1][0], 2)* 100 This will return 21.0, which is the percentage of the user churning.
Finally, we'll return this value as JSON in a churn object.
Next, we'll run and deploy our model locally.
In your terminal, navigate to the model_server folder and run:
Now, our model server is running, and we can now test it by making a GET request to the /predict endpoint.
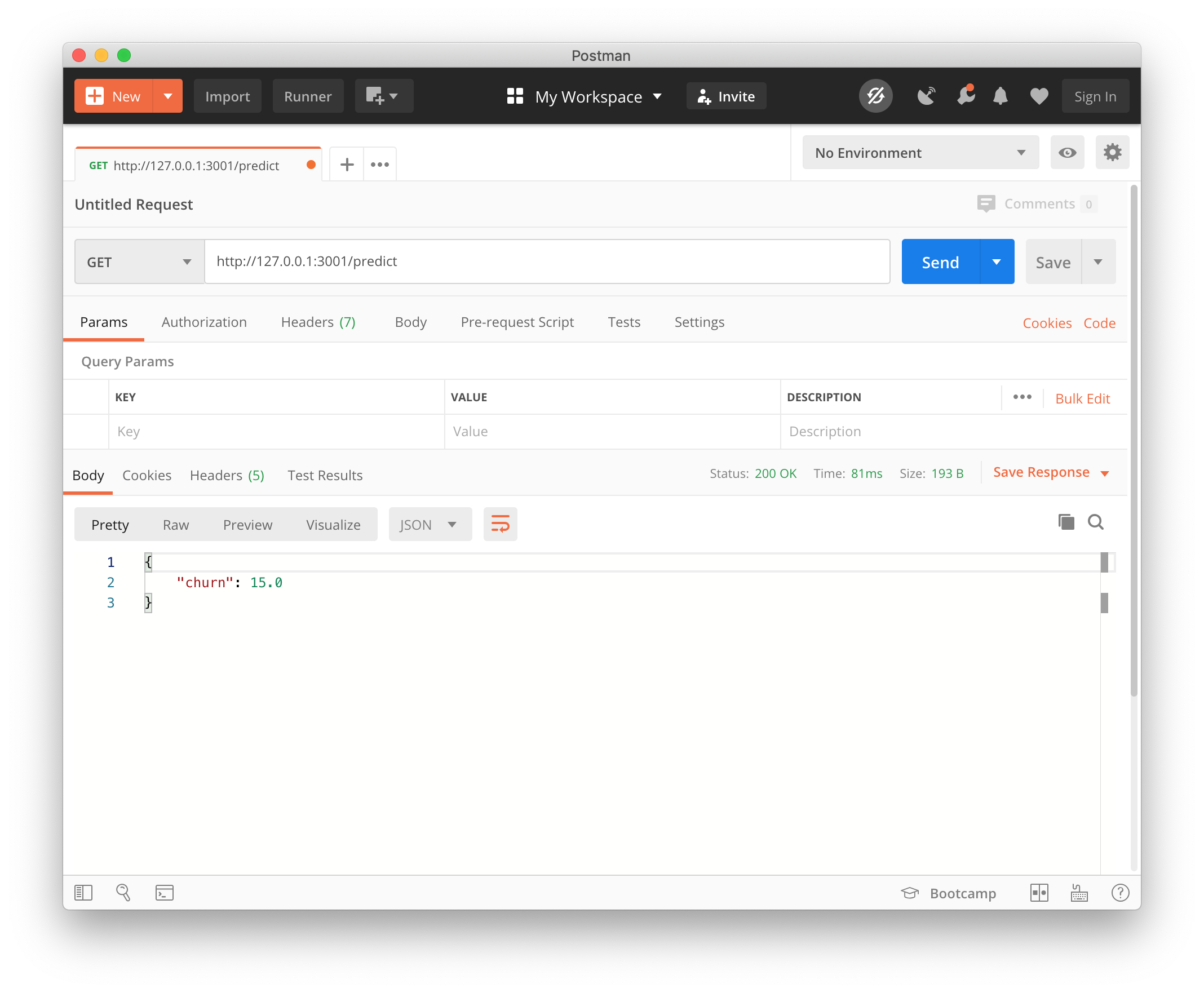
The server returns a JSON response that shows the percentage of the likelihood of a random user churning.
After will built our machine learning model and created a backend to serve our predictions, we'll now integrate it into a web app to show churn predictions to a customer service agent.
To show our churn prediction, we'll be creating a custom Conversation Event called churn-prediction to be called when the model server returns its churn prediction for a given user.
In the ui_app folder, navigate to the common.js file, inside the public folder, and we'll add the following:
function getChurnForUser(conversation) {
//Send custom event to agent
if (window.location.pathname == "/") {
fetch("http://127.0.0.1:3001/predict",{
mode: 'cors',
headers: {
'Access-Control-Allow-Origin':'*'
}
})
.then(response => {return response.json()})
.then(json => {
conversation.sendCustomEvent({ type: 'churn-prediction', body: json}).then(() => {
console.log('custom event was sent');
}).catch((error)=>{
console.log('error sending the custom event', error);
});
})
.catch(error => console.log('error', error));
}
}
This function accepts the activate conversation and calls the model server that we built previously. We've hardcoded the URL and port for ease of use.
In a production environment, we would pass in the user-id to generate a prediction for that user. But for this example, as shown before, we generate a random user's information to be used in the churn prediction model.
Next, we'll add an h2 tag on the agent's screen to show the churn prediction. Then, we'll add a listener to churn-prediction event, which will update the text inside the h2 tag. Inside setupListeners function we'll add this:
activeConversation.on('churn-prediction', (sender, message) => {
if (window.location.pathname == "/agent") {
document.getElementById("churn_text").innerHTML = "Likelihood of customer churn: " + message["body"]["churn"] + "%"
console.log(sender, message);
}
});
When the churn-prediction event fires, we send the churn prediction in the message property and update the innerHTML text with the churn.
Now, whenever we have new users speak with our agent, we'll be able to see that users likelihood of churning. If the possibility of churn is high, maybe, we should be a little extra nice to them :)
Overall, we have shown that building a machine learning model isn't magic, and anyone can build something that is useful and can be used in a production environment. We have shown that our model is able to predict the probability of churn with 89% accuracy. Which is great for our first model. But there's a lot more that we can do in order to build an even better model. One of the best ways to learn is by doing, so let's see if you can build a model that beats this one!
You can use the supplied Google Colab Notebook as a starter project. As always, we are happy to help with any questions in our community slack.