
Teilen Sie:
IOS-Entwickler, der sich für Data Science und maschinelles Lernen begeistert. Ich möchte, dass die Menschen verstehen, was maschinelles Lernen ist und wie wir es in unseren Applications nutzen können.
Aufbau eines Hunderassen-Detektors mit maschinellem Lernen
Lesedauer: 9 Minuten
Hier bei Nexmo nutzen wir Facebook Workplace als einen unserer vielen Kommunikationskanäle. Wenn Sie es noch nicht benutzt oder davon gehört haben, ist es genau wie Facebook, aber für Unternehmen. Jeder von uns hier bei Nexmo hat einen Account, und wir können verschiedene Gruppen innerhalb des Unternehmens einsehen und ihnen beitreten.
Vor ein paar Monaten hat einer unserer Mitarbeiter eine Gruppe eingerichtet, in der wir unsere Haustiere zeigen können. Das war eine tolle Idee, und viele Mitglieder des Teams stellen Fotos ihrer Haustiere ein. Ich schaue fast täglich in die Gruppe, und es ist eine gute Möglichkeit, sich an den schönen Dingen des Lebens zu erfreuen (Welpen!).
 wp-group
wp-group
Nachdem ich mir die Fotos von Hunden, Katzen und sogar Kaninchen angeschaut hatte, fragten einige Leute: "Welche Rasse ist das?". Als ich das sah, hatte ich die Idee, einen Algorithmus für maschinelles Lernen zu entwickeln, um herauszufinden, welche Hunderasse auf dem Foto zu sehen ist.
In diesem Beitrag werden wir lernen, wie man eine Hunderasse Detektor erstellen mit Keraszu erstellen, einem sehr beliebten Framework zum Erstellen von Modellen für maschinelles Lernen.
Dieser Beitrag setzt voraus, dass Sie etwas Python beherrschen und ein grundlegendes Verständnis von maschinellem Lernen haben. Sie sollten wissen, was Keras ist und wie man ein grundlegendes maschinelles Lernmodell trainiert.
Um viele Probleme des maschinellen Lernens zu lösen, braucht man Daten, und zwar jede Menge davon. Insbesondere brauchen wir Fotos von vielen Hunden und den verschiedenen Rassen, die es gibt. Für dieses Projekt werden wir den Datensatz der Herausforderung zur Identifizierung von Hunderassen auf Kaggle verwenden. Dieser Datensatz enthält über 10.000 Bilder von Hunden, kategorisiert nach Rasse.
Beginnen wir mit dem Bau des Modells. Ich werde Folgendes verwenden Google Colab zum Erstellen meines Jupyter-Notizbuchin Python. Ein Jupyter-Notizbuch ist eine Open-Source-Webanwendung, mit der Sie sowohl Code als auch Text und Bilder schreiben können. Es ist eine großartige Möglichkeit für den Einstieg. Google Colab ist ein kostenloser Dienst, der Ihre Jupyter-Notebooks hosten kann.
Hinweis: Wenn Sie sehen möchten, wie das Modell aufgebaut ist, können Sie mein Notizbuch hier ansehen.
Bevor wir das Modell erstellen können, müssen wir uns die Daten besorgen, die auf Kaggle gehostet werden. Um die Daten zu laden, müssen wir ein Paket verwenden, um die Daten auf unser Notebook herunterzuladen, indem wir die Kaggle-API. So können wir den Datensatz für den Hunderassen-Wettbewerb herunterladen. Bevor wir den Datensatz herunterladen können, müssen wir einen Account bei Kaggle erstellen und den Kaggle-API-Schlüssel und das Geheimnis erhalten.
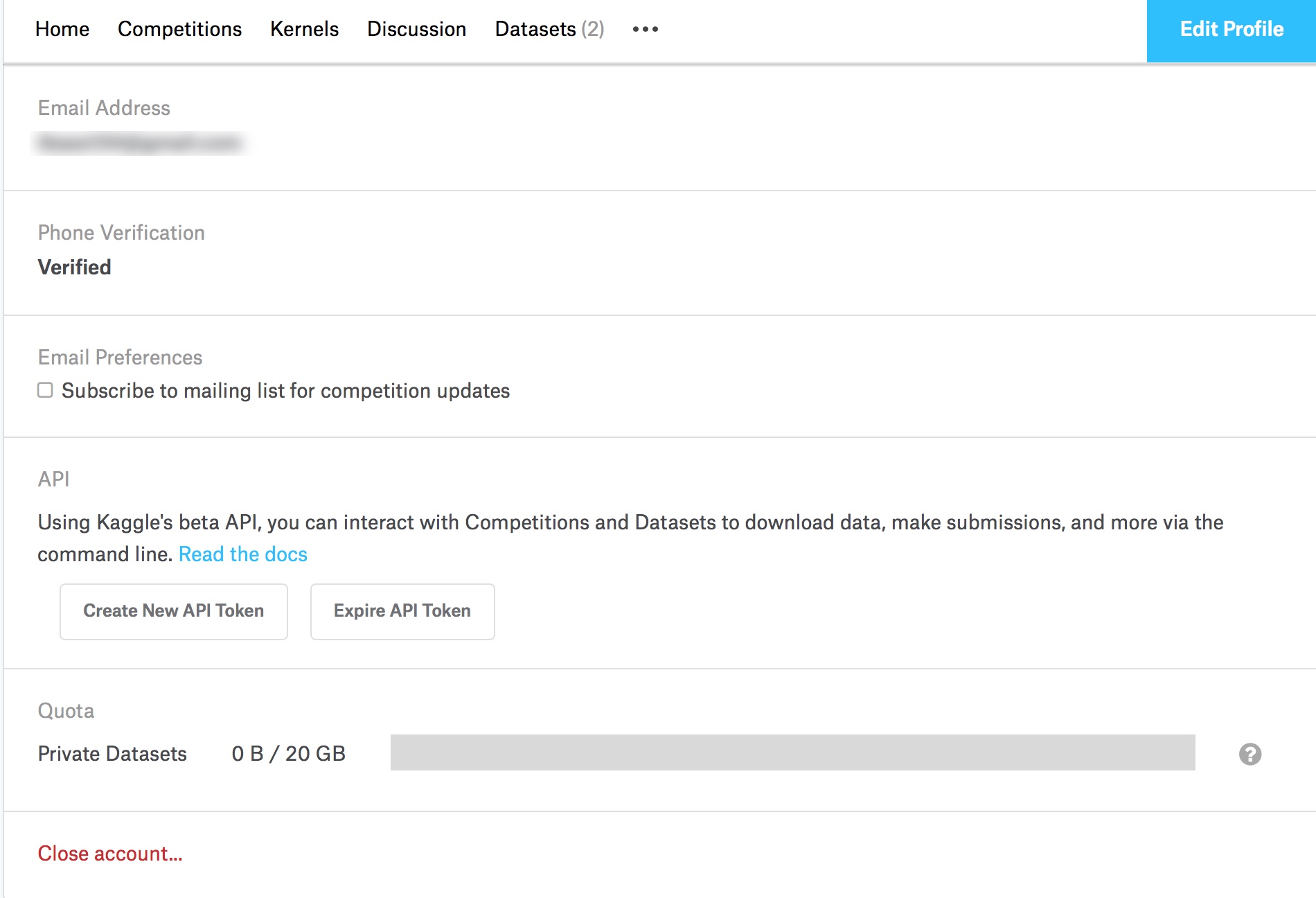 kaggle-create-api-token
kaggle-create-api-token
Gehen Sie auf "Create New API Token" und speichern Sie die Datei auf Ihrem Rechner. Um die Daten herunterzuladen, führen wir Folgendes aus Zelle.
# Run this cell and select the kaggle.json file downloaded
# from the Kaggle account settings page.
from google.colab import files
files.upload()
# Let's make sure the kaggle.json file is present.
!ls -lha kaggle.json
# Next, install the Kaggle API client.
!pip install -q kaggle
# The Kaggle API client expects this file to be in ~/.kaggle,
# so move it there.
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
# This permissions change avoids a warning on Kaggle tool startup.
!chmod 600 ~/.kaggle/kaggle.json
#download the dataset for the dog-breed identification challenge https://www.kaggle.com/c/dog-breed-identification
!kaggle competitions download -c dog-breed-identification
#unzip the downloaded files
!unzip labels.csv.zip
!unzip test.zip
!unzip train.zipWenn Sie nicht jede Zeile dieses Codes oder eines anderen Codeabschnitts verstehen, machen Sie sich keine Sorgen. Sie können den Quellcode kopieren und einfügen, um alles selbst auszuführen, ohne sich um die Details kümmern zu müssen.
Wenn Sie diese Zelle ausführen, werden Sie aufgefordert, eine Datei auszuwählen. Suchen Sie die JSON-Datei, die von Kaggle heruntergeladen wurde, und laden Sie sie in die Zelle hoch. Sie können dann die Kaggle-API ausführen und den Datensatz in das Notebook herunterladen. Sobald die Dateien heruntergeladen sind, entpacken wir die Dateien mit !unzip. Das ! vor dem Befehl ermöglicht es Ihnen, eine Befehlszeilenaktion innerhalb von Google Colab auszuführen. Der !unzip Befehl entpackt einfach jede Datei.
Die von Kaggle heruntergeladenen Dateien enthalten die folgenden Informationen:
Training Images, den Ordner
\trainOrdnerTestbilder, die sich im Ordner
\testOrdnerEine CSV-Datei namens
labels.csvdie den Namen der Rasse und den Dateinamen enthält, der auf das Bild im Trainingsordner verweist.
Jetzt können wir unsere Daten in einen Dataframe laden, indem wir Pandas. A DataFrameist eine einfache Datenstruktur, die Zeilen und Spalten enthält, ähnlich wie eine CSV-Datei. Pandas ist ein Python-Paket, das leistungsstarke, einfach zu verwendende Datenstrukturen und Datenanalysewerkzeuge bereitstellt. Es wird in vielen Anwendungen für maschinelles Lernen verwendet. Wenn Sie Anwendungen für maschinelles Lernen entwickeln, ist Pandas eines der ersten Pakete, die Sie verwenden werden. Wenn Sie mehr über Pandas erfahren möchten, schauen Sie sich ihr eigenes Tutorial an, 10-Minuten-Tutorial zu Pandas.
Mit Pandas können wir die csv-Datei aus dem Kaggle-Datensatz in einen Pandas Dataframe importieren.
#import the necessary packages
import pandas as pd
import numpy as np
#constants
num_classes = 12 # the number of breeds we want to classify
seed = 42 # makes the random numbers in numpy predictable
im_size = 299 # This size of the images
batch_size = 32
#read the csv into a dataframe, group the breeds by name and append the path the to image in the `filename` column
df = pd.read_csv('labels.csv')
selected_breed_list = list(df.groupby('breed').count().sort_values(by='id', ascending=False).head(num_classes).index)
df = df[df['breed'].isin(selected_breed_list)]
df['filename'] = df.apply(lambda x: ('train/' + x['id'] + '.jpg'), axis=1)
breeds = pd.Series(df['breed'])
print("total number of breeds to classify",len(breeds.unique()))
df.head()Das Programm lädt die csv-Datei in einen DataFrame pd.read_csv('labels.csv')und sortiert dann den DataFrame alphabetisch nach Rasse. Dann drucken wir die ersten 10 Zeilen aus mit df.head()
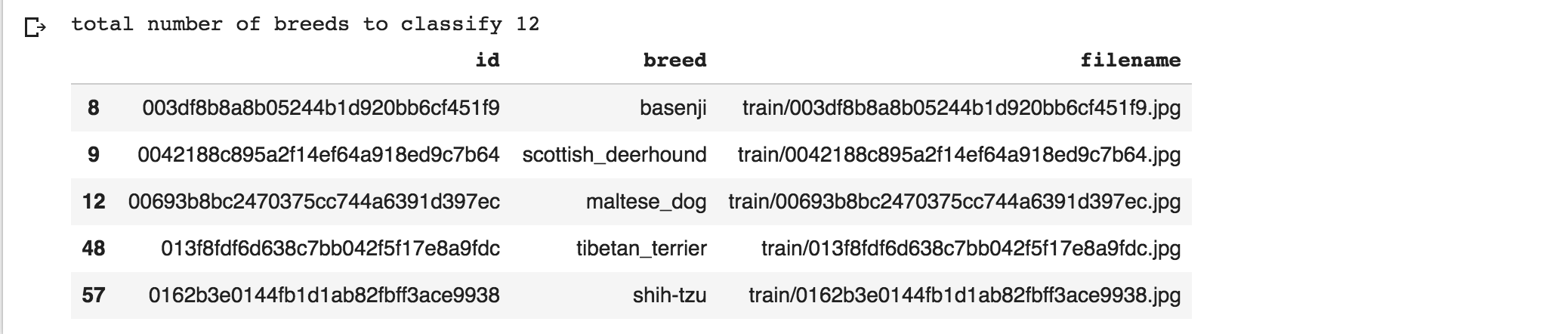 df_head
df_head
Als Nächstes müssen wir eine Funktion schreiben, die die Größe aller Bilder auf die von uns benötigte Größe von 299 x 299 Pixel ändert. Es wird klar sein warum wir die Größe des Bildes später ändern müssen.
from keras.preprocessing import image
def read_img(img_id, train_or_test, size):
"""Read and resize image.
# Arguments
img_id: string
train_or_test: string 'train' or 'test'.
size: resize the original image.
# Returns
Image as numpy array.
"""
path = train_or_test + "/" + img_id + ".jpg"
img = image.load_img(path, target_size=size)
return image.img_to_array(img)Die Funktion read_img() Funktion lädt das Bild in der benötigten Größe (299x299px) und wandelt es in ein mehrdimensionales Numpy-Array um. Numpy ist ein weiteres Python-Paket, das beim maschinellen Lernen sehr häufig verwendet wird. Es erleichtert die Arbeit mit diesen Arten von Arrays in Python.
Als nächstes müssen wir die Namen der Rassen (basenji, scottish_deerhound) in Vektoren (eindimensionale Arrays von Numbers) umwandeln, da unser maschinelles Lernmodell nur mit Zahlen umgehen kann. Um dies zu tun, verwenden wir Scikit Learns LabelEncoder. Ein LabelEncoder nimmt alle Rassennamen und wandelt den Namen der Rasse in eine ganze Zahl um. Jede Zahl wird für jede Rasse anders sein (0 für basenji, 1 für scottish_deerhound usw.). Scikit-Learn ist ein weiteres Open-Source-Paket, das den Einstieg in das maschinelle Lernen erleichtert.
Als Nächstes teilen wir den Datensatz in zwei Teile, einen zum Trainieren und einen zum Testen. Wenn wir unser Modell trainieren, verwenden wir die Daten aus dem Trainingsdatensatz, um das Modell zu trainieren. Wenn wir dann sehen wollen, wie gut es funktioniert hat, testen wir das Modell mit dem Testdatensatz.
from sklearn.preprocessing import LabelEncoder
label_enc = LabelEncoder()
np.random.seed(seed=seed)
rnd = np.random.random(len(df))
train_idx = rnd < 0.9 valid_idx = rnd >= 0.9
y_train = label_enc.fit_transform(df["breed"].values)
ytr = y_train[train_idx]
yv = y_train[valid_idx]
Zum Schluss nehmen wir alle Bilder aus dem Trainingssatz und ändern ihre Größe mit der read_img Funktion, die wir zuvor erstellt haben. Dann müssen wir jedes Bild verarbeiten, um es in das richtige Format zu bringen, das unser Modell erwartet.
from tqdm import tqdm
from keras.applications import xception
x_train = np.zeros((train_idx.sum(), im_size, im_size, 3), dtype='float32')
x_valid = np.zeros((valid_idx.sum(), im_size, im_size, 3), dtype='float32')
train_i = 0
valid_i = 0
for i, img_id in tqdm(enumerate(df['id'])):
img = read_img(img_id, 'train', (im_size, im_size))
x = xception.preprocess_input(np.expand_dims(img.copy(), axis=0))
if train_idx[i]:
x_train[train_i] = x
train_i += 1
elif valid_idx[i]:
x_valid[valid_i] = x
valid_i += 1
print('Train Images shape: {} size: {:,}'.format(x_train.shape, x_train.size))
[00:06, 201.73it/s]Train Images shape: (1218, 299, 299, 3) size: 326,671,254In dieser Funktion durchlaufen wir jedes Element in unserem DataFrame (for i, img_id in tqdm(enumerate(df['id'])): und rufen die read_image Funktion auf, die die img_id, die ID des Bildes, die mit dem Dateinamen des Bildes aus dem \train Ordner entspricht, und die Größe auf 299x299px ändert. Dann rufen wir die xception.preprocess_input Funktion auf.
Bevor wir uns ansehen, was diese Funktion tut, müssen wir verstehen, was xception ist.
Um Modelle von Grund auf neu zu trainieren, braucht man viel mehr Bilder als die, die uns zur Verfügung stehen (10k), sowie eine Menge Rechenzeit und Ressourcen. Um diesen Prozess zu beschleunigen, können wir eine Technik verwenden, die Transfer-Lernen. Das bedeutet, dass wir ein Modell verwenden können, das zuvor auf einem anderen Datensatz trainiert wurde, wie z.B. Imagenet-Datensatz. Xception ist eines dieser vortrainierten Modelle. Wir können uns bei der Extraktion von Merkmalen aus dem Bild auf das vortrainierte Modell verlassen. Wir werden das Modell dann nur für unseren speziellen Anwendungsfall trainieren: die Bestimmung der Rasse.
Ich habe mit einigen Modellen experimentiert und festgestellt, dass Xception die besten Ergebnisse für den Anwendungsfall der Rassenerkennung mit dem von uns verwendeten Bilddatensatz liefert.
Für andere Datensätze gibt es möglicherweise andere Modelle, die für Ihre Bedürfnisse besser geeignet sind und bessere Ergebnisse liefern. Machen Sie also unbedingt einige Tests, bevor Sie sich für ein Modell entscheiden. Um mehr über dieses und andere vorbereitete Modelle zu erfahren, lesen Sie dies (https://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception-xception-keras/). In diesem Beitrag wird auch erläutert, was ImageNet ist und wie es mit diesen vorbereiteten Modellen zusammenhängt.
OK, kommen wir zurück zu dem, was die xception.preprocess_input() Funktion tut. Sie nimmt das Bild, das jetzt ein Numpy-Array ist, und konvertiert es in ein Format, das das Xception-Modell erwartet, bei dem alle Werte im Array zwischen -1 und 1 liegen, was als Normalisierung bekannt ist.
Jetzt können wir unser Modell aufbauen.
Da wir Xception als Basismodell verwenden, ist unser eigenes Modell sehr einfach. Für unser eigenes Modell laden wir die Ausgabe von Xception, d. h. alle Ebenen, die bereits für Bilder aus Imagenet trainiert wurden, und erstellen dann ein sequenzielles Modell.
Aus dem Keras-Blog: "Das Sequential-Modell ist ein linearer Stapel von Schichten." - Erste Schritte mit dem Sequential-Modell von Keras
Das bedeutet, dass wir andere Schichten über das Xception-Modell legen können. So kann unser Modell auf unseren Hundebildern trainieren.
Hier ist unser Modell. Quelle
from keras.layers import GlobalAveragePooling2D, Dense, BatchNormalization, Dropout
from keras.optimizers import Adam, SGD, RMSprop
from keras.models import Model, Input
# create the base pre-trained model
base_model = xception.Xception(weights='imagenet', include_top=False)
# first: train only the top layers (which were randomly initialized)
# i.e. freeze all convolutional Xception layers
for layer in base_model.layers:
layer.trainable = False
# add a global spatial average pooling layer
x = base_model.output
x = BatchNormalization()(x)
x = GlobalAveragePooling2D()(x)
# let's add a fully-connected layer
x = Dropout(0.5)(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
# and a logistic layer and set it to the number of breeds we want to classify,
predictions = Dense(num_classes, activation='softmax')(x)
# this is the model we will train
model = Model(inputs=base_model.input, outputs=predictions)Zuerst nehmen wir unsere base_modeldie Xception ist, dann, Freeze die Schichten. Das bedeutet, dass wir diese Schichten nicht trainieren werden, da sie bereits trainiert wurden. Als nächstes nehmen wir die Ausgabe von base_model und fügen die folgenden Schichten hinzu:
BatchNormalisierung - wendet eine Transformation an, die den Mittelwert der Aktivierung nahe bei 0 und die Standardabweichung der Aktivierung nahe bei 1 hält.
GlobalAveragePooling2D Schicht - reduziert die Anzahl der zu lernenden Parameter.
Aussetzer - schaltet nach dem Zufallsprinzip Eingaben aus, um eine Überanpassung.
Dichtes Schicht - die jedes Neuron im Netz verbindet.
gefolgt von einem weiteren Ausstieg Ebene.
Schließlich erstellen wir eine weitere dichte Schicht und setzen sie auf die Anzahl der Rassen, für die wir trainieren.
Die Auswahl dieser Schichten basiert auf Versuch und Irrtum. Es gibt keine bekannte Methode, um beim Aufbau Ihres Modells eine gute Netzstruktur zu bestimmen. Wenn Sie Ihre eigenen Modelle erstellen, ist Stack Overflow Ihr bester Freund.
Jetzt beginnen wir mit dem eigentlichen Training des Modells. Die Art und Weise, wie ich das Modell trainiere, ist sehr einfach. Sie werden diese Art von Code sehen, wenn Sie andere Modelle in Keras durchgehen. Quelle
import datetime
from keras.callbacks import EarlyStopping, ModelCheckpoint
epochs = 1
learning_rate = 0.001
# checkpoints
early_stopping = EarlyStopping(monitor='val_acc', patience=5)
STAMP = "{}_dog_breed_model".format(datetime.date.today().strftime("%Y-%m-%d"))
bst_model_path = "{}.h5".format(STAMP)
model_checkpoint = ModelCheckpoint(bst_model_path,
save_best_only=True,
save_weights_only=False,
verbose=1)
# compile the model
optimizer = RMSprop(lr=learning_rate, rho=0.9)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=["accuracy"])
hist = model.fit_generator(train_generator,
steps_per_epoch=train_idx.sum() // batch_size,
epochs=epochs, callbacks=[early_stopping, model_checkpoint],
validation_data=valid_generator,
validation_steps=valid_idx.sum() // batch_size)
model.save(bst_model_path)Wir fügen zunächst einige Callback-Funktionenhinzu, d. h. Funktionen, die wir nach jeder Trainingsrunde ausführen, auch bekannt als epoch. Wir haben 2 Rückrufe:
early_stoppingmit dempatienceParameter von 5: Damit wird das Training abgebrochen, wenn sich das Modell nach 5 Epochen nicht verbessert hat.model_checkpoint: Das Modell wird zur späteren Verwendung in einer Datei gespeichert.
Als nächstes setzen wir den Optimierer auf RMSprop. Ein Optimierer ist die Art und Weise, wie das Modell "lernt". Für jede Epoche berechnet das Modell die Verlustfunktion, die angibt, wie schlecht das Modell im Vergleich zur Testmenge abgeschnitten hat. Das Ziel ist es, diesen Verlust so gering wie möglich zu halten, was als Gradientenabstieg. Keras unterstützt viele Optimierer, und in meinen Experimenten schien RMSProp, das den Gradientenabstieg durchführt, am besten zu funktionieren.
Als nächstes erstellen wir das Modell mit der model.compile Funktion, die den Optimierer akzeptiert, welche Verlustfunktion wir berechnen wollen (sparse_categorical_crossentropy), und die Einstellung des metrics Parameter auf accuracy, der uns sagt, wie genau das Modell nach jeder Epoche ist.
Danach werden wir unsere Ausbildung machen, indem wir anrufen model.fit_generator(). Die Parameter dieser Funktion sind: ImageDataGeneratorTrainings- und Testmenge, die Anzahl der Schritte, die wir durchführen, die Anzahl der Epochen, die zu prüfenden Daten und die Anzahl der zu prüfenden Schritte. Wir trainieren dieses Modell zunächst für 10 Epochen, um zu sehen, wie wir abgeschnitten haben.
Epoch 1/10
38/38 [==============================] - 40s 1s/step - loss: 0.5477 - acc: 0.8281 - val_loss: 0.0555 - val_acc: 0.9766
*skipping output for readability*
Epoch 10/10
38/38 [==============================] - 33s 857ms/step - loss: 0.2426 - acc: 0.9358 - val_loss: 0.0457 - val_acc: 0.9905Wir haben also ein Modell, das zu 99 % genau 12 Rassen vorhersagen kann!
Jetzt können wir unser Modell an einigen Bildern von Hunden testen und sehen, ob wir in der Lage sind, die richtige Rasse aus dem Bild zu ermitteln. Wir werden eine Funktion schreiben, die ein Bild aus dem Internet nimmt, es so formatiert, wie es das Modell erwartet (299x299px Bild) und die Vorhersage mit model.predict(). Diese Funktion nimmt ein Bild in Form eines Numpy-Arrays auf und gibt die Ausgabe als Liste von Wahrscheinlichkeiten für jede Rasse zurück. Wir verwenden np.argmax() um den Index der höchsten Wahrscheinlichkeit aus der Ausgabe von model.predict(). Um den Namen der Rasse zurückzugeben, verwenden wir die labels.csv die wir aus dem Kaggle-Datensatz geladen haben, der die 12 Rassenamen enthält. Dann sortieren wir die Liste alphabetisch und geben den Namen der Rasse zurück.
from keras.models import load_model
from keras.preprocessing import image
import matplotlib.pyplot as plt
import numpy as np
import os
def predict_from_image(img_path):
img = image.load_img(img_path, target_size=(299, 299))
img_tensor = image.img_to_array(img) # (height, width, channels)
img_tensor = np.expand_dims(img_tensor, axis=0) # (1, height, width, channels), add a dimension because the model expects this shape: (batch_size, height, width, channels)
img_tensor /= 255.
pred = model.predict(img_tensor)
predicted_class = sorted_breeds_list[np.argmax(pred)]
return predicted_classLassen Sie uns nun diese Funktion testen, nur um sicherzugehen, dass sie funktioniert. Wir laden ein Foto von einem Scottish Deerhoundherunter, indem wir wget, einem Kommandozeilenprogramm zum Herunterladen von Dateien, und sehen, wie sich das Modell verhält.
{kind=link}
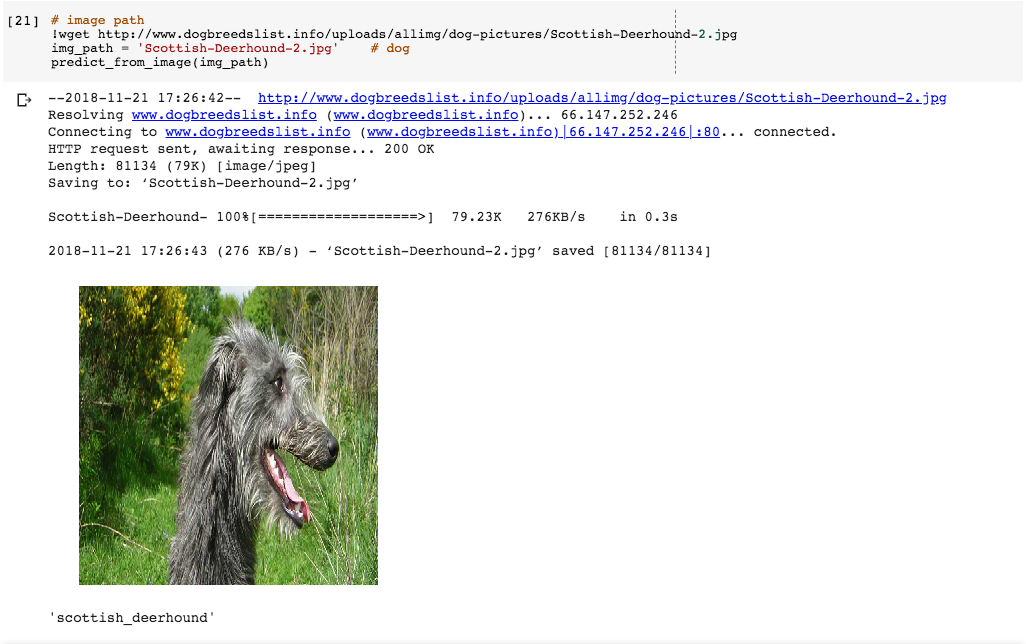 predict
predict
Schön! Das Modell sagt voraus, dass der Hund auf dem Foto ein Scottish Deerhound ist, und das ist er auch!
In diesem Beitrag haben wir gelernt, wie wir unser eigenes maschinelles Lernmodell mit Keras erstellen, unser Modell mit Transfer Learning trainieren und mit unserem Modell Vorhersagen treffen können.
In einem späteren Beitrag werden wir uns damit beschäftigen, wie man dieses Modell als einfache API auf einem Server bereitstellt, damit andere es nutzen können. Dann werden wir einen Workplace-Bot erstellen, der es jedem in unserer Workplace-Gruppe ermöglicht, zu fragen, welche Hunderasse auf einem Foto in einem Workplace-Post zu sehen ist.