
ビデオ+AI:音声コネクターによるライブ翻訳
所要時間:1 分
ビデオ通話で世界中の人々がそれぞれの母国語を話し、全員がお互いを理解しあっている様子を想像してみてください。スピーカーの音声はテキストに翻訳され、他の参加者は母国語で読むことができます。このブログ記事では、これを実現する方法を説明します。主なコンポーネントの一つは、リリースされたばかりの新しいAudio Connector機能です。
つまり オーディオコネクタを使用すると、ルーティングされたビデオ通話セッションのオーディオストリームを個別に(A、B)、または組み合わせて(A+B)、合計50ストリームまでWebSocketサーバーに送信できます。
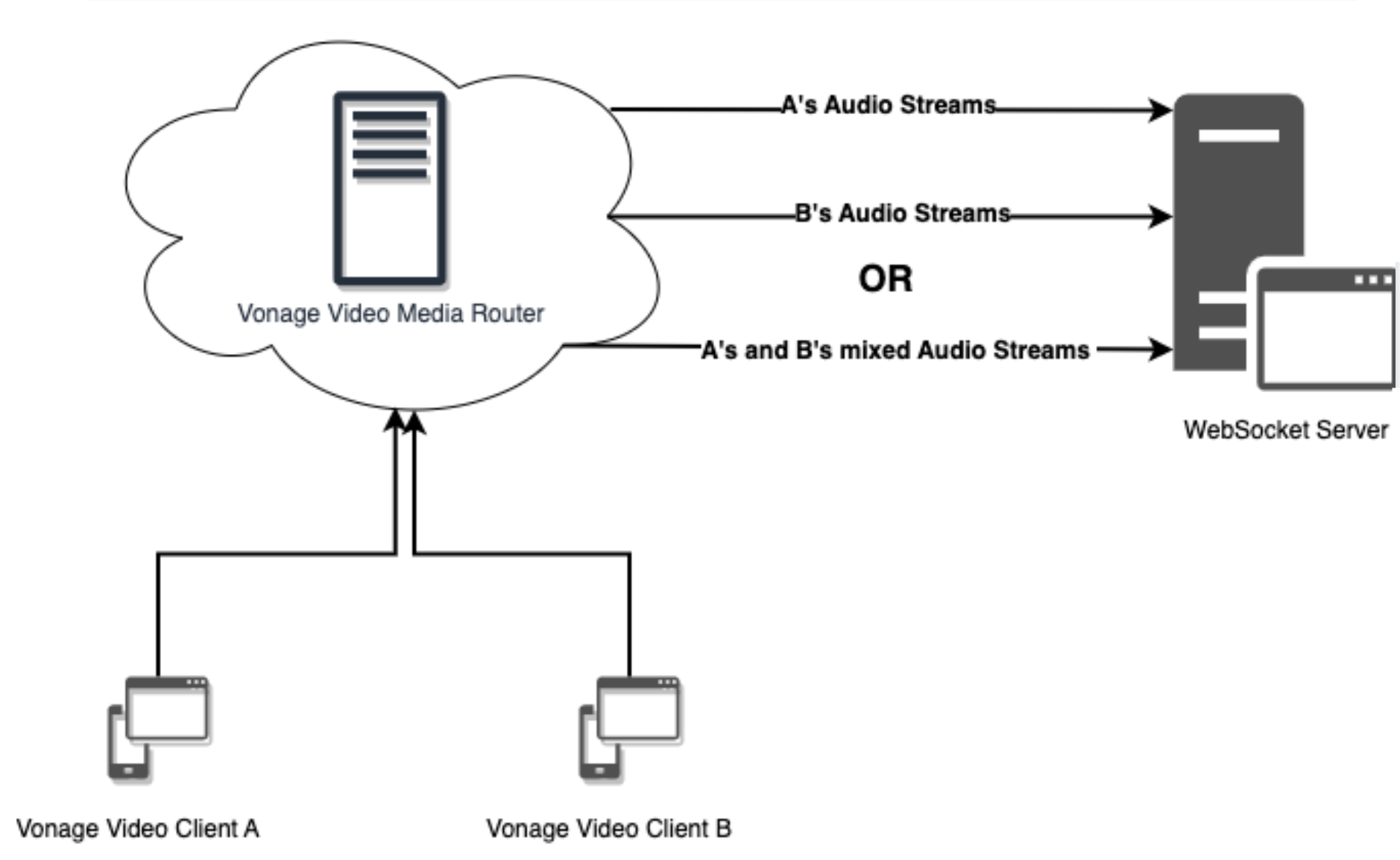 Audio Connector Diagram
Audio Connector Diagram
Audio Connector の使用を開始するためにオンにする機能フラグやスイッチはありません。デフォルトで有効になっており、送信された参加者オーディオストリームの数に応じて価格が設定されます。オーディオストリームを受信するために、WebSocket サーバーを作成するだけです。
音声ストリームを分離して分析できるようになると、多くの新しい可能性が開けます。このブログ記事で取り上げるのは、マイクロソフトのAzureを使った人工知能によるリアルタイム翻訳です。 AIスピーチサービス.
コードとデモを実際に見たい場合は GitHub リポジトリをご覧ください。デプロイボタンをクリックし、いくつかの認証情報を入力すると、ビデオ通話でリアルタイムのライブ翻訳を体験することができます。
前述したように、デモ・アプリケーションを実行するにはいくつかの認証情報が必要です。
Video API キーとシークレットは、ダッシュボードの ダッシュボードで見つけることができます。
 Vonage Project Credentials
Vonage Project Credentials
マイクロソフト側では、AzureポータルでSpeech Servicesリソースを作成する必要があります。 Azureポータル.作成したら、いずれかのキー(どちらでも構いません)と、"Location/Region "の値が必要になります。
 Microsoft Azure Project Credentials
Microsoft Azure Project Credentials
これらの認証情報と実行中のアプリケーションのドメインを入力すると、名前を入力し、話す言語を選択し、翻訳を読むことができます。URLを共有し、あなたのビデオセッションに1人か2人の友人を参加させる。
このセクションでは、デモ・アプリケーションの舞台裏で起こっていることを説明します。できるだけコードにとらわれないようにするため、一般的なメソッドについて説明し、ドキュメントを紹介します。私は デモ・アプリケーションをNodeJSを使って構築しました。
ビデオ通話は、このサンプルプロジェクトにあるような基本的な通常のビデオ通話です。 サンプルプロジェクトまたは新しい ビデオ・ウェブ・コンポーネント.唯一の違いは、セッションを開始する前に、ユーザーが自分の名前と使用する言語を入力できるようにすることです。
ビデオ通話が発生すると、Audio ConnectorがWebSocketサーバに送信を開始するためのオーディオがあることを意味します。WebSocket サーバーの作成方法がわからない場合は、以下を検索してください。 <your programming language> WebSocket serverうまくいけば、多くのチュートリアルやライブラリが検索結果に表示されます。そうでない場合は、AIチャットボットに聞くことができます。ハハ
新しく作成したWebSocketサーバーにオーディオ・ストリームの送信を開始するには、Vonageは様々なサーバーSDKでメソッドを提供しています(Java, NodeJS, PHP, Python, Ruby, .NET) を使用してWebSocket接続を開始します。サーバー側の言語が表示されない場合は RESTエンドポイント.
WebSocketサーバーがオーディオストリームを受信したら、翻訳を開始しましょう。マイクロソフトのAzure AIスピーチサービスは、30以上の言語の音声を翻訳できる。Microsoftには、以下のSpeech Service SDKがあります。 C++, C#, Go, Java, JavaScript/NodeJS, Objective-Cおよび Python.
まず、キーと地域を音声翻訳設定に設定します。言語SDKでは、次のようなものがあるはずです。 SpeechTranslationConfigのようなものがあるはずです。 fromSubscriptionのようなものがあるはずです。音声認識とターゲット言語をどこに設定するかは、1つのストリームを組み合わせて送信するか、複数の個別のストリームを送信するかによって異なります。
WebSocketサーバー上で、人工知能で翻訳するためにAudio Connectorから送信されたデータを収集したいと思うでしょう。そのためには、少なくともNodeJSでは、Audio Input Stream用のPush Streamを作成する必要があります。これがその仕組みです。
Audio Connectorは異なるタイプのWebSocketメッセージを送信します:
テキストベースのメッセージには、初期メッセージ、オーディオストリームがミュート/アンミュートされたときの更新、接続が切断されたときの更新があります。これらのメッセージには、オーディオフォーマット情報、接続ステータスに関するデータ、接続作成時に送信したカスタムヘッダーデータが含まれます。
もう一つは、オーディオストリームを表すバイナリーオーディオメッセージです。これらは、人工知能が翻訳するためにPush Streamに追加したいものです。
テキストベースのメッセージと音声メッセージを区別するために、私はメッセージをJSONパースしてみる。エラーが出なければ、それはテキスト・メッセージである。エラーが発生した場合は、バイナリーのオーディオ・メッセージがPush Streamに追加されたことを意味する。
プッシュストリームからオーディオ入力ストリームが供給されるようになったので、Speech SDKがオーディオを分析して翻訳できるように、ストリーム入力からのオーディオを設定する必要があります。ストリームの "理解 "を開始するために、AudioとSpeech Translationの設定を使用してTranslation Recognizerを作成します。翻訳レコグナイザーは、オーディオストリームで何が話されているかを継続的に認識しようとします。
翻訳レコグナイザーが何を言っているのかを理解しようとするため、部分的な翻訳が行われます。文の内容を完全に理解できると判断されると、最終的な翻訳が提示されます。
そして、Vonage Video機能を使って、最終的な翻訳をビデオセッションに送信します。 シグナル機能参加者のスクリーンに表示されます。
ビデオ通話の参加者全員をミュートにして、ブラウザが合成音声で翻訳テキストを読み上げる機能を追加したら、クールな機能になると思いました。もし試されたら、その様子を 開発者コミュニティSlackまたはX(旧Twitter)でお知らせください。 またはX(旧Twitter)でお知らせください。.