
シェア:
スタンダップ・コメディーの学位論文を持つ俳優の訓練を受け、ミートアップ・シーンを経てPHP開発に携わるようになった。技術について話したり書いたり、レコード・コレクションから変わったレコードを再生したり買ったりしています。
SQLiteの復活
所要時間:3 分
OK、認めよう。復帰ではない。むしろ再構築と呼ぼう。 SQLiteはは2000年から存在し、当初の用途はアメリカ海軍駆逐艦のミサイル追跡用だった。過去10年間、NoSQLやドキュメント指向のデータベース・システムが台頭し、SQLiteから脚光を浴びることはなかったが、リレーショナル・データベース・システムとしての信頼性は確かに証明されている。この記事では、SQLiteの見過ごされてきた可能性を探り、本番レベルのアーキテクチャを念頭に置いて、SQLiteがいかに素早くスピンアップできるかを実証する。OK、それは認めよう。むしろ再構築と呼ぼう。SQLiteは2000年から存在している。過去10年間、NoSQLやドキュメント指向のデータベースが台頭し、多くのスポットライトを浴びてきたが、SQLiteは依然として強力な選択肢である。もともとはアメリカ海軍の駆逐艦のミサイル追跡用に開発されたSQLiteは、信頼性の高いリレーショナル・データベースであることを静かに証明してきた。もしかしたら、プロダクション・グレードのアーキテクチャにおけるSQLiteの可能性を見落としているかもしれない。この記事では、SQLiteをいかに速く簡単に立ち上げることができるかを紹介する。
>> TL;DR:完全なソースコードは GitHub.
では、ソフトウェアエンジニア、特にウェブアプリケーション開発者は、SQliteをどのようなものとして知っているのでしょうか?さて、SQliteには2つの評判があります:
テストを実行する必要があるのですが、完全な Postgresサーバーを立ち上げたくないので、この便利なファイルを使ってテストを実行するのはどうでしょう?
小さいから組み込み用でしょ?でも、山のようなデータを生成するウェブ・アプリケーションには使えない。
SQLiteはテストに非常に便利だ。例えば、マイグレーションやシーダーなど、既存のアーキテクチャーがコード化されているとします。テスト・スイートを実行するときに、SQL互換のデータベース・サーバー、たとえば MySQL, MariaDBやPostgresのようなSQL互換のデータベースサーバーを使う代わりに、空白のSQLiteファイルを使って同じコードを実行する。素晴らしい。しかし、ポイント2はどうだろう?
 Just one file: portability at its finestそう、小さいのだ。さらに良いのは、接続がシンプルなことだ。
Just one file: portability at its finestそう、小さいのだ。さらに良いのは、接続がシンプルなことだ。
JetbrainsのIDEには、新しいSQLiteファイルを作成できるデータベースパネルがある。 VSCodeにもSQLiteファイルを作成するプラグインがたくさんある。つまり 本当のヘビー 開発者なら Vimから直接作成できる。
フットプリントはわずか699kb。それだけだ。実行するサービスもバックグラウンド・プロセスもない。
これは、完全に MySQL サーバをスピンアップするのに必要なリソースとは大きく異なります。
こんなに簡単なら、なぜもっと多くのウェブ・アプリケーションでSQLiteを使わないのか?
その答えはたいてい思い込みに行き着く。サーバーベースのリレーショナル・データベースが主流だが、少し考えれば、SQLiteが実際の要件に完璧にフィットすることに気づくかもしれない。
読み込みと書き込みの速度は、最大の違いのひとつだ。SQLiteは、数百万行の中規模データベースとしては、信じられないほど高速だ。 信じられないほど速い。 ベンチマークによって異なりますが、MySQLの平均が最大10ms程度であるのに対し、SQLiteは一回のクエリーで最大5msかかります。
しかし、もしSQLiteがすべてのベンチマークで勝っているとしたら、ウェブ・アプリケーションの開発ではそれほど普及していないSQLiteを、私たちが何にでも使っているのは明らかだ。まず、書き込み速度は かなり 遅い。SQLiteはシングルスレッドで約300件のインサートを書き込めるのに対し、MySQLは最大5万件(環境による)。これは大きな違いだ。
2つ目の注意点は、SQLiteにはシングルスレッドのロック機構があるということです。読み取り中または書き込み/更新中のレコードには、5つの書き込み可能な状態があります。書き込み時、レコードのロック状態は EXCLUSIVE,に変更される。しかし、MySQLはMVCC(Multi-Version Concurrency Control)を使用しており、多くの同時読み取りと書き込みが可能である。
私が常に人々に思い出させようとしている質問のひとつは、次のようなものだ。 あなたのユースケースは何ですか? クラウドネイティブやKubernetesの世界では、「PHPが遅い」のは「Nodeにはイベントループがあるからだ」と主張する人が多い。 現実的にするのか」ということだ。 ユーザーデータを保存したり、CSVや画像をアップロードしたりするのであれば、それは本当に必要なことなのか? 本当に 言語やフレームワークの選択による違いが本当にわかるのでしょうか?多くの場合、おそらくそうではないだろう。これはSQLiteとMySQLでも同じだ:SQLiteは今でも素晴らしい選択肢です。 いくつかの しかしもっと重要なのは、あなたのアプリで2万人のユーザーがデータベースに書き込むつもりなのか、ということだ。グローバル・タクシー・アプリケーションの次のイテレーションを書くのであれば、そうだろう。私がここで言いたいのは、SQLiteは多くの人が思っているよりもはるかに多くの開発ケースに適しているということだ。
ウェブストームIDEおよびそれを使用するための基本的な知識
To complete this tutorial, you will need a Vonage API account. If you don’t have one already, you can sign up today and start building with free credit. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard.

話はもう十分なので、本番レベルの SQLite を タイプスクリプト.によって生成された Webhook を読むことができるアプリケーションを公開します。 Vonage Messages API によって生成された Webhook を読むことができるアプリケーションを公開します。.まず、プロジェクト用に新しいディレクトリを作成し、そこに移動して、新しい Node プロジェクトを作成します。
npm init --yesこれは package.jsonのデフォルト値が使われる。次に、TypeScriptをインストールする必要がある:
npm install typescript
npx tsc --initTypescriptはプレーンなJavaScriptにコンパイルされ、設定ファイル tsconfig.json,を使用します。この設定ファイルを開き、定型文を以下のように置き換えてください:
{
"compilerOptions": {
"target": "es2016",
"module": "CommonJS",
"rootDir": "./",
"outDir": "./dist",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true,
"moduleResolution": "node",
"baseUrl": ".",
"paths": {
"@prisma/client":["node_modules/@prisma/client"]
}
},
"include": ["src/**/*.ts"]
}この構成で注目すべき重要な部分は以下の通りだ:
TypeScriptは、存在しなければ作成されるディレクトリにコンパイルされます。
dist.これがアプリケーションのエントリポイントとなる。お気づきのように プリズマが
pathsキーにあることに気づくだろう。これは、Prismaをインストールする際に、(ある意味で)コンパイルする必要があるからです。Prismaでモデルを定義すると、generateコマンドを使用して特注のPrismaクライアントが作成されます。
私たちには6つの依存関係がある:
Prisma: 私たちの オブジェクトリレーショナルマッパー
tsノード出力ディレクトリにコンパイルすることなくTypeScriptを実行できる。
ノデーモン私たちの開発サーバーでは、コードが変更されるとリロードされます。
ドットエンブ環境変数を扱う)
エクスプレスルーター
Sqliteデータベース接続用
これらをコマンドラインで一発インストールできる:
npm install prisma ts-node nodemon dotenv express @types/express sqlite3プリズマは ORMです。で、データモデル、マイグレーション、その他すべてのクエリを処理できます。Prismaディレクトリをセットアップするには、そのためのinitコマンドを実行する必要があります:
npx prisma init --datasource-provider sqlite --output ../generated/prismaこのコマンドは、コンパイルされたClientクラスを ../generated/prismaディレクトリに出力し、SQLiteがデータベース・ソースであることを指示します。このコマンドを実行すると、Prismaは必要な依存関係を尋ねてきます。 .envファイルを設定します。このファイルは後で設定します。
SQLiteはライブラリで扱われるファイルなので、ドライバをサポートしている最近のIDEのほとんどで作成できる。あなたのプロジェクトを でプロジェクトを開く。.右側のパネルにある Database アイコンをクリックします。をクリックし、新規データベースを作成します。Data Source "を選択し、"SQLite "が表示されるまで下にスクロールします。新しいデータベースを作成するためのモーダルが表示されます:
 Jetbrains Supports A Massive List of DBsタイプとしてSQLiteを選択すると、作成ポップアップが表示されます:
Jetbrains Supports A Massive List of DBsタイプとしてSQLiteを選択すると、作成ポップアップが表示されます:
 Create Your DatabaseWebStormを使用したことがない場合、初めてこの操作を行うと、IDEはSQliteドライバがインストールされていないことを検知します。
Create Your DatabaseWebStormを使用したことがない場合、初めてこの操作を行うと、IDEはSQliteドライバがインストールされていないことを検知します。 Test Connectionオプションの代わりに警告が表示されます。ドライバを持っていない場合は、リンクをクリックしてインストールしてください。
フィールドで Nameフィールドで identifier.sqliteを ウェブフックに、ファイル名を webhooks.sqlite.ファイルはプロジェクト・ルートに置きたいので、ファイル・フィールドの右にあるドットを押して、場所が正しいことを確認してください。そしてokをクリックする。
Prismaクライアントは prisma/schema.prismaで設定されていますが DATABASE_URLファイルから .envファイルから取得します。あなたの envを開き、次のように置き換えます:
DATABASE_URL="file:../webhooks.sqlite"Prismaは、特注のORMクライアントを node_modulesディレクトリに生成するように設定されています。ディレクトリに生成されるように設定されています。 @prismaディレクトリに生成させたくないので schema.prismaファイルで、データソースの下のクライアント設定を次のように置き換えます:
generator client {
provider = "prisma-client-js"
output = "../node_modules/.prisma/client"
}これは、生成されたクライアントを新しいディレクトリに置くようにPrismaに指示するものです、 .prisma.後でExpressでレコードを作成するときに、Prismaにクライアントをインポートする場所を指示します。
マイグレーションが実行されるモデルを作成する必要がある。Prismaでは、データベース・モデルをすべて手作業で入力する必要があります。さて、私たちは Vonage Messages API ウェブフックのWebhookリファレンスに移動したらどうだろう? OpenAPI specをコピーして、AIにモデルを書いてもらったらどうだろう?私がやったのはまさにそれだ。
 Auto-generated AI code from OpenAPI specs手間を省くために、以下のモデルをあなたの
Auto-generated AI code from OpenAPI specs手間を省くために、以下のモデルをあなたの schema.prisma below にコピーしてください:
model WebhookEvent {
id String @id @default(uuid())
channel String
messageUuid String @unique
to String
from String
timestamp DateTime
contextStatus String
messageType String
location Location?
createdAt DateTime @default(now())
}
model Location {
id String @id @default(uuid())
webhookId String @unique
lat Float
long Float
webhook WebhookEvent @relation(fields: [webhookId], references: [id], onDelete: Cascade)
}これでマイグレーションを実行すれば、これらのモデルのテーブルがデータベースに生成されます。
npx prisma migrate dev --name webhooksPrismaは、データベースに加えられたすべての変更の記録となるマイグレーションを作成しました。フィールド名を変更したいですか?はい、新しいマイグレーションをソースコードにコミットします。これであなたは、アプリケーションのデータベースを正しい状態にする方法の全記録を、コードで持つことができる。
最後のタスクは、Webhookを利用するExpressアプリを作成することです。プロジェクトルートに srcという名前の新しいディレクトリを作成し index.ts.以下のようになります:
import express, { Express, Request, Response } from "express";
import dotenv from 'dotenv';
import { PrismaClient } from ".prisma/client"
dotenv.config();
const app: Express = express();
const port = process.env.PORT;
const prisma = new PrismaClient();
app.use(express.json())
app.get('/', (req: Request, res: Response) => {
res.send('Express + TypeScript Server');
});
app.post('/webhook', async (req, res) => {
try {
const { channel, message_uuid, to, from, timestamp, context_status, message_type, location } = req.body
// Save the webhook data in the database
const webhook = await prisma.webhookEvent.create({
data: {
channel,
messageUuid: message_uuid,
to,
from,
timestamp: new Date(timestamp),
contextStatus: context_status,
messageType: message_type,
location: location ? {
create: {
lat: location.lat,
long: location.long
}
} : undefined
},
include: { location: true } // Optional: Include related location in the response
})
console.log('Webhook saved:', webhook)
res.status(201).json({ message: 'Webhook saved successfully', webhook })
} catch (error) {
console.error('Error saving webhook:', error)
res.status(500).json({ error: 'Internal server error' })
}
})
app.listen(port, () => {
console.log(`[server]: Server is running at http://localhost:${port}`);
});ここで解き明かすことはかなり多いので、一行ずつ見ていこう:
import { PrismaClient } from ".prisma/client".prismaディレクトリからインポートしていることを確認してください。app.use(express.json())は、ExpressがJSONを処理する必要があることを確認することである。app.post('/webook')は、Vonageがデータを送信する新しいエンドポイントを定義します。
POSTエンドポイントを定義します。ウェブフック・クロージャーで定義された
constWebhookクロージャで定義されたフィールドは、必要なフィールドをすべて不変変数に抽出し、データベースに書き込まれます。最後に
prisma.webhookEvent.create()が呼び出され、入力されたデータがSQLiteデータベースに書き込まれる。
コマンドラインからPrismaクライアントを再構築する機能と、TypeScriptでコンパイルするために追加したオプションが必要です。あなたの scriptsセクションの package.jsonファイルのセクションを次のように変更します:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "npm run prisma:generate && npx tsc",
"start": "node dist/src/index.js",
"dev": "nodemon --exec ts-node src/index.ts",
"prisma:generate": "prisma generate"
}ここでアプリケーションを実行するには、まずアプリを distディレクトリにビルドし、Prismaを再生成してTypeScriptコンパイラーを呼び出した後で、Expressアプリを起動します。
npm run buildnpm run startお気づきかもしれないが、TypeScriptコンパイラを実行するコマンド npm run devTypeScriptコンパイラーを実行するコマンドと nodemonファイルが変更されるたびにdevビルドを行う
最後の部分は、データを送信することだ。そのためにはまず、ngrokを使ってローカル・アプリケーションをインターネットに公開する必要がある。そのためには、ターミナルで新しいタブを開いて実行する:
ngrok http 3000学ぶ ngrokの詳細.
ngrokがポートをオープンしたら、パブリックURLができるはずです。これをVonageに設定する。
アプリケーションを作成するには アプリケーションの作成ページでアプリケーションの名前を定義します。
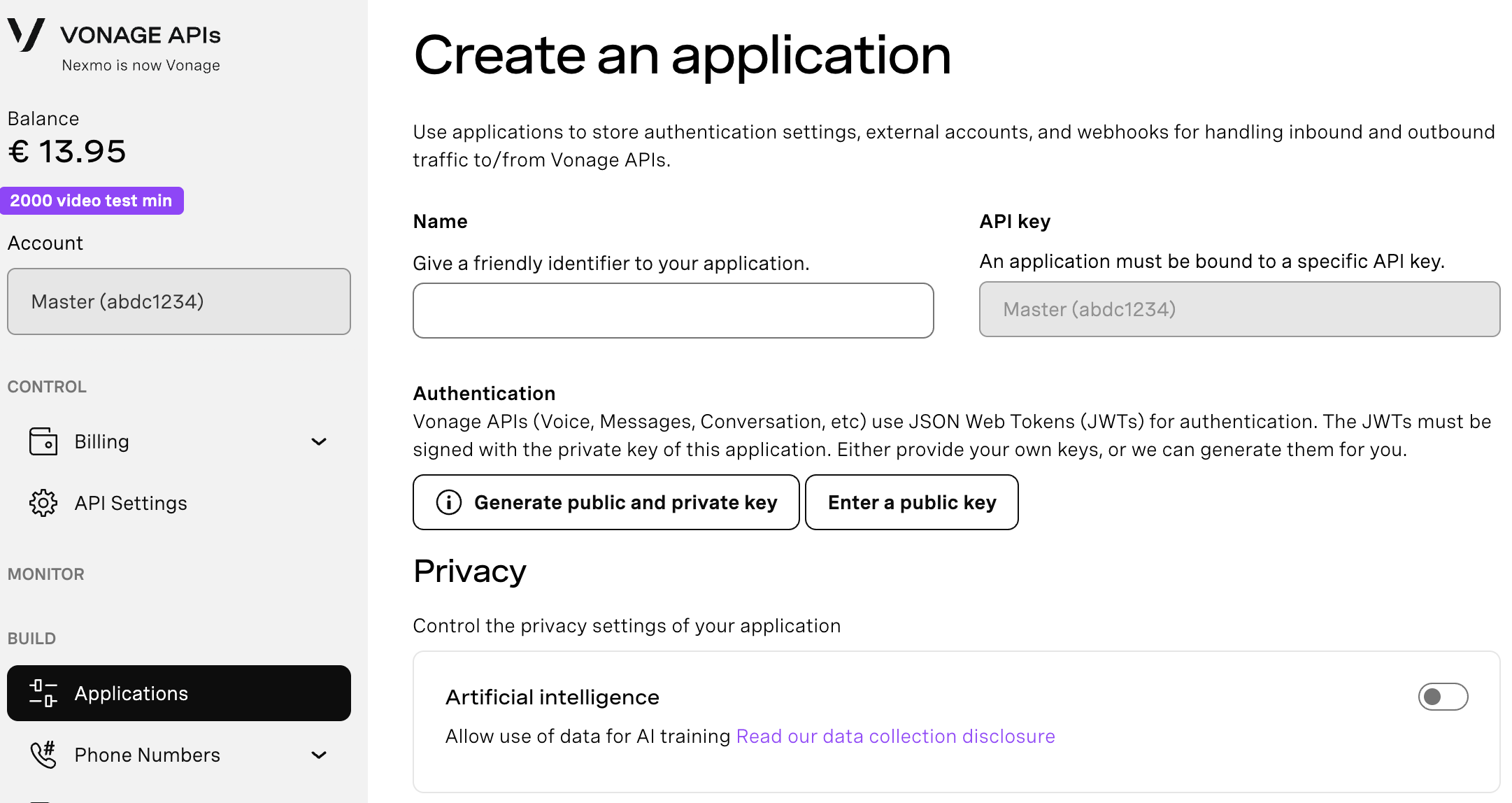
Webhooksを使用するAPIを使用する場合は、秘密鍵が必要です。Generate public and private key "をクリックすると、自動的にダウンロードが始まります。この鍵は紛失すると再ダウンロードできません。この鍵は紛失しても再ダウンロードできません。 private_<あなたのアプリID>.key.この鍵はAPIコールの認証に使用できます。 注意:アプリケーションを保存するまで、キーは機能しません。
必要な機能(Voice、Messages、RTCなど)を選択し、必要なWebhook(イベントURL、応答URL、受信メッセージURLなど)を提供します。これらはチュートリアルで説明します。
保存してデプロイするには、"Generate new application "をクリックして設定を確定します。これでアプリケーションはVonage APIで使用する準備が整いました。
公開鍵や秘密鍵、その他のオプションは、完全な統合を行うわけではなく、いくつかのデータを生成するだけなので、ここではあまり重要ではない。何が 重要なのは 重要なのは、Ngrokが生成したURLをこれらのインバウンドオプションの両方に貼り付けることです。 /webhookこれはExpressで作成されたルートです。先に進んでアプリケーションを作成し、メッセージ機能はこのようになるはずです:
 Configuring your Vonage Application Webhooksこのアプリケーションに添付された番号へのすべての返信は、現在経由で転送されます。インバウンドURLとしてここに入力したURLへのWebhook。
Configuring your Vonage Application Webhooksこのアプリケーションに添付された番号へのすべての返信は、現在経由で転送されます。インバウンドURLとしてここに入力したURLへのWebhook。
バーチャル電話番号を購入するには APIダッシュボードにアクセスし、以下の手順に従ってください。
 Purchase a phone number
Purchase a phone number
あなたの APIダッシュボード
BUILD & MANAGE > Numbers > Buy Numbersを開きます。
必要な属性を選択し、検索をクリックします。
ご希望の番号の横にある購入ボタンをクリックし、購入を確定する。
バーチャルナンバーを購入したことを確認するには、左側のナビゲーションメニューの「BUILD & MANAGE」から「Numbers」、「Your Numbers」の順にクリックします。
購入した番号にメッセージを送ると、すべての配線が行われ、イベントと受信メッセージが新しいSQLiteデータベースに直接書き込まれる。ここでは、私のお気に入りのツールを使っている、 HTTPieを使ってウェブフックの送信をテストしてみた:
 Successful Persistence WinsPHPStormのデータベースパネルからwebhooksテーブルを開くと、レコードが正しく永続化されていることが確認できます:
Successful Persistence WinsPHPStormのデータベースパネルからwebhooksテーブルを開くと、レコードが正しく永続化されていることが確認できます:
 Database Query View in WebStorm
Database Query View in WebStorm
このデモはSQLiteのパワーを示している。 このコードで このコードで入力されたデータを永続化するために、私たちは何もしていない。Dockerも、リレーショナル・システムのクラウド・スピンアップも使っていない。この紹介は、SQLiteが便利になる可能性のある場所へのポインターの役割を果たす。ローテーションのログファイルや、機械が生成したデータではなく人間が生成したデータの少量バッチ、セッションデータなどだ。同時実行やトラフィックがそれほど気にならない場合は、Redisのような高速なセットアップが可能だと考えてください。しかし、すべてのことに言えることだが、エンジニアのモットーである「It Depends®」を忘れないでほしい。
ご質問がある場合、またはあなたが作っているものを共有したい場合は、こちらをクリックしてください。
会話に参加する VonageコミュニティSlack
登録する 開発者ニュースレター
フォローする X(旧ツイッター)最新情報
チュートリアルを見る YouTubeチャンネル
LinkedInの LinkedIn の Vonage デベロッパーページ
最新の開発者向けニュース、ヒント、イベント情報をお届けします。