
Partager:
Ancien développeur .NET Advocate @Vonage, ingénieur logiciel polyglotte full-stack, AI/ML
Détection de visages en temps réel en .NET avec OpenCV et Video API de Vonage
Temps de lecture : 13 minutes
Note : Certains des outils ou méthodes décrits dans cet article peuvent ne plus être pris en charge ou ne plus être d'actualité. Pour obtenir un contenu ou une assistance actualisés, consultez nos derniers articles ou notre Documentation
La vision par ordinateur est mon domaine de prédilection en informatique. Il combine mes quatre matières préférées - la programmation, l'algèbre linéaire, les probabilités et le calcul - en quelque chose de pratique et de puissant. Dans cet article, nous allons étudier une application intéressante de la vision par ordinateur, la détection des visages, et intégrer cette fonctionnalité dans une application OpenTok Windows Presentation Framework (WPF).
Pour nous aider à démarrer, nous travaillerons à partir de l'outil CustomVideoRender Video de Vonage. Actuellement, cet exemple ajoute une nuance de bleu à votre image vidéo lorsque vous activez le filtre. Nous allons supprimer cette nuance de bleu et ajouter la détection des visages au moteur de rendu. Et si vous y croyez, cette fonction de détection des visages sera environ 30 fois plus rapide que le filtre bleu. Pour réaliser cette prouesse, nous allons appliquer le filtre de Viola-Jones pour la détection de caractéristiques à l'aide d'Emgu CV.
Si vous n'avez pas envie de suivre l'intégralité de ce tutoriel, vous pouvez trouver un exemple fonctionnel sur GitHub. Assurez-vous simplement d'échanger les paramètres comme indiqué dans le Guide de démarrage rapide à partir du repo d'échantillons principal
Je ne m'étendrai pas trop sur le fonctionnement de la méthode Viola-Jones, mais pour ceux que cela intéresse, voici un bref rappel du contexte. Le cœur de l'algorithme Viola-Jones est triple. Tout d'abord, il utilise ce que l'on appelle des caractéristiques de type Haar, qui peuvent ressembler à de simples formes noires et blanches.
 Haar-like feature shapes source: Source https://scc.ustc.edu.cn/
Haar-like feature shapes source: Source https://scc.ustc.edu.cn/
Mais en réalité, il s'agit de détecteurs de caractéristiques très simples qui peuvent nous en apprendre beaucoup sur l'ombrage relatif d'une image :
 Harr-like Features over Faces source http://www.willberger.org/cascade-haar-explained/
Harr-like Features over Faces source http://www.willberger.org/cascade-haar-explained/
Lorsqu'elle est superposée à une image, la somme de la région blanche est soustraite de la somme de la région noire, ce qui nous indique la différence d'ombrage entre les régions. Ces calculs, lorsqu'ils sont effectués en cascade sur de nombreuses caractéristiques, peuvent nous donner une bonne idée de l'emplacement d'un visage sur une image. Ces caractéristiques étant très simples, elles ne varient pas en fonction de l'échelle, ce qui signifie qu'elles permettent de trouver des visages dans une image, quelle que soit sa taille.
Cette méthode fait un excellent travail de détection des visages dans une image, mais sans la dernière innovation majeure de l'article, cette méthode serait d'une lenteur paralysante, plutôt que d'une rapidité lumineuse. Les auteurs ont introduit le concept d'image intégrale - une image intégrale est une image où chaque pixel est égal à la somme de la région située au-dessus et à gauche du pixel. En calculant cela sur une image d'entrée, nous pouvons effectuer des calculs sur des caractéristiques de type Haar avec une complexité temporelle de O(1) plutôt que de O(N*M), où N et M sont respectivement la hauteur et la largeur de la caractéristique de type Haar. La combinatoire ne fonctionne donc pas seulement, mais elle joue en notre faveur, puisque nous essayons de construire un détecteur de visages qui fonctionne rapidement.
Visual Studio - J'utilise 2019, mais les versions antérieures devraient fonctionner.
Minimum .NET Framework 4.6.1 - vous pouvez utiliser une version antérieure à 4.5.2, mais vous devrez utiliser EmguCV au lieu de Emgu.CV pour votre paquet NuGet OpenCV.
Exemple de CustomVideoRenderer - Voici l'exemple que nous allons adapter.
Un compte Video API de Vonage - si vous n'en avez pas déjà un inscrivez-vous ici.
Une clé API, un ID de session et un jeton de votre compte API Video de Vonage - voir la section Guide de démarrage rapide dans le répertoire pour plus de détails.
Tout d'abord, ouvrons le fichier de solution CustomVideoRenderer. Dans MainWindow.xaml.cs, mettez vos informations d'identification si vous ne l'avez pas déjà fait. Ensuite, mettez à jour le csproj pour cibler le .NET Framework 4.6.1.
Pour ce faire, ouvrez la solution dans Visual Studio, faites un clic droit sur le fichier du projet et cliquez sur "Propriétés". Dans l'onglet Applications, changez le cadre cible en 4.6.1.
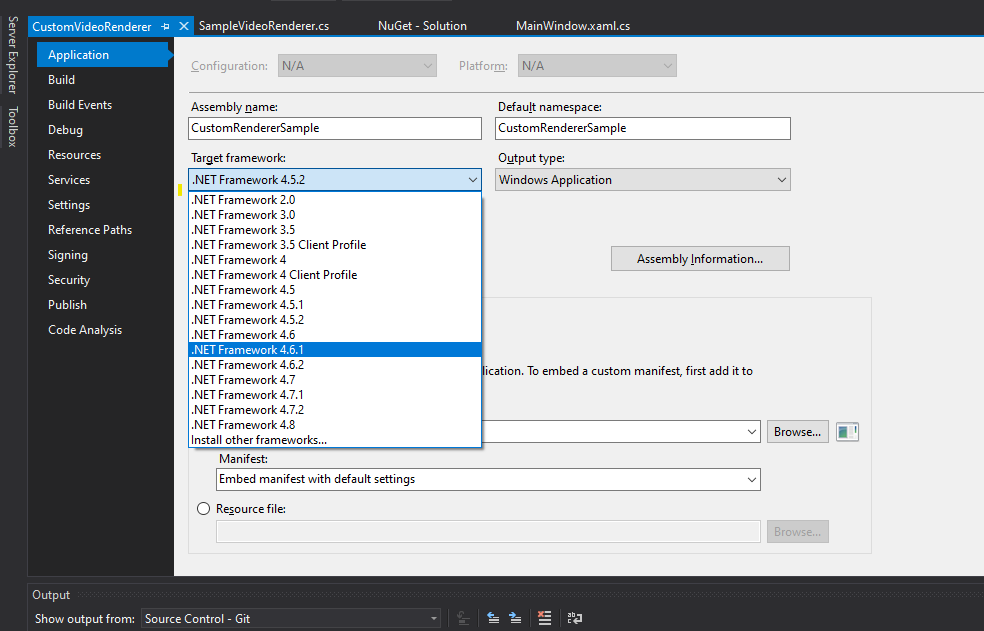 Upgrade .NET version
Upgrade .NET version
Ensuite, ajoutez les paquets NuGet suivants en plus de ce qui se trouve déjà dans l'application :
Emgu.CV.runtime.windows - J'utilise 4.2.0.3662
WriteableBitmapEx - J'utilise la version 1.6.5
Téléchargez les deux fichiers suivants à partir de OpenCV:
haarcascade_frontalface_default.xml
haarcascade_profileface.xml
Placez ces fichiers à côté de votre projet et configurez-les pour qu'ils soient copiés dans votre répertoire de construction lorsqu'il est construit. Cela peut impliquer la mise en place d'un événement post-construction si votre instance de Visual Studio n'est pas aussi coopérative que la mienne :
copy $(ProjectDir)\haarcascade_profileface.xml $(ProjectDir)$(OutDir)
copy $(ProjectDir)\haarcascade_frontalface_default.xml $(ProjectDir)$(OutDir)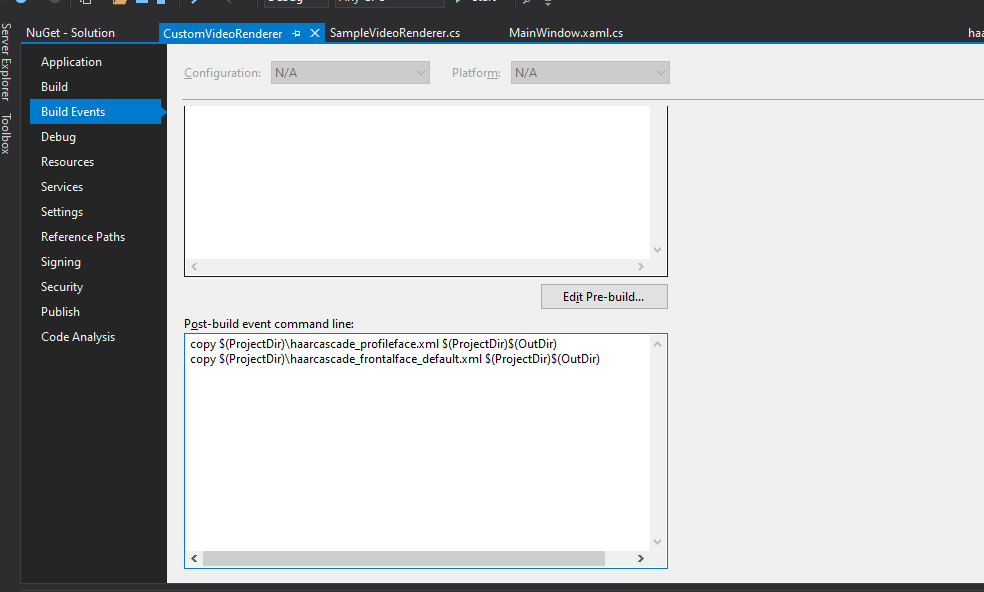 Displaying Post Build Events Screen
Displaying Post Build Events Screen
À ce stade, vous devriez être en mesure de lancer l'application et de vous connecter à un appel. Étant donné que Windows ne permet pas à plusieurs applications d'accéder simultanément à votre caméra, vous devrez peut-être rejoindre l'appel à partir d'un autre ordinateur à l'aide de l'API vidéo de Vonage. Video API Playground de Vonage
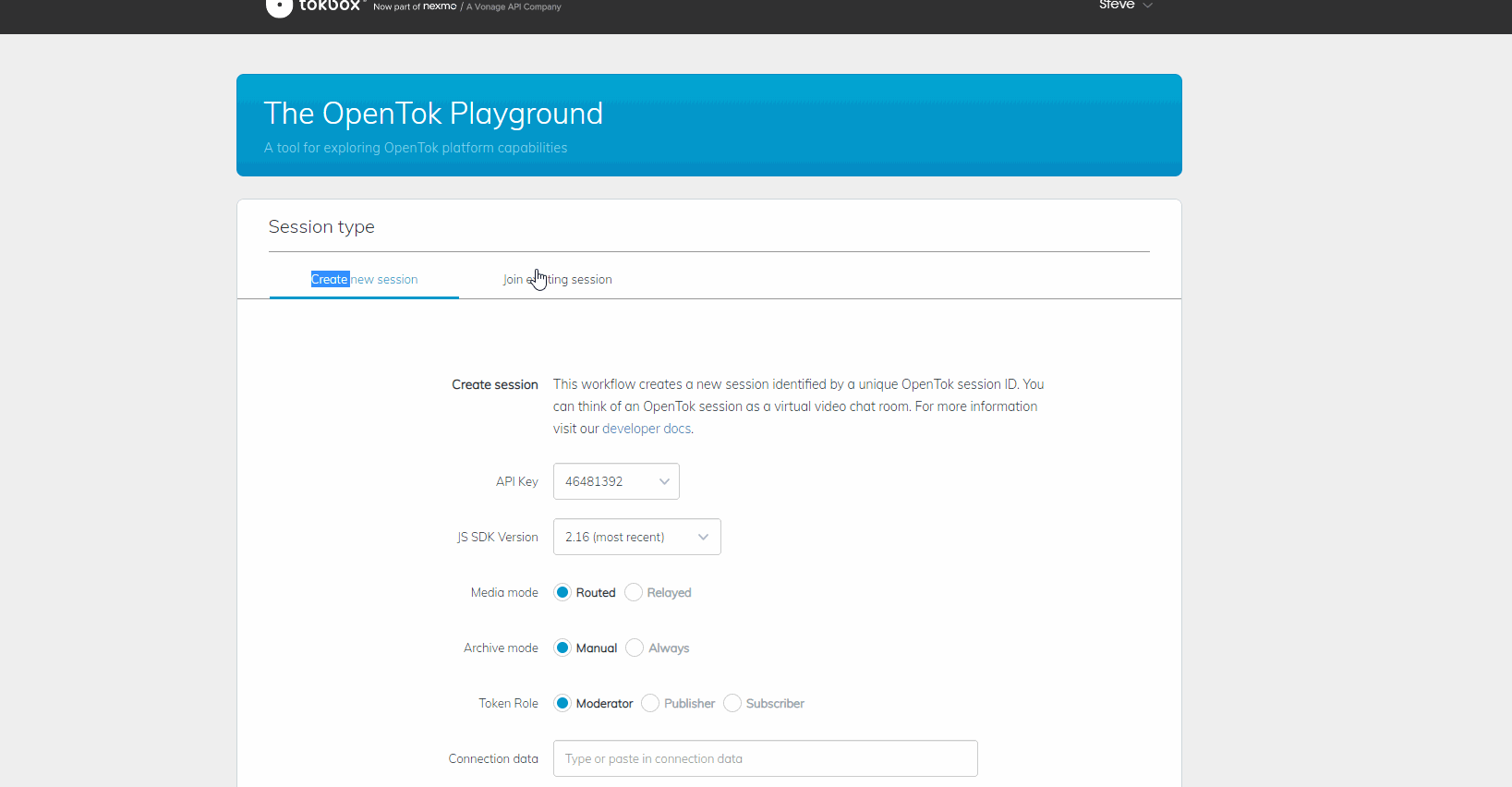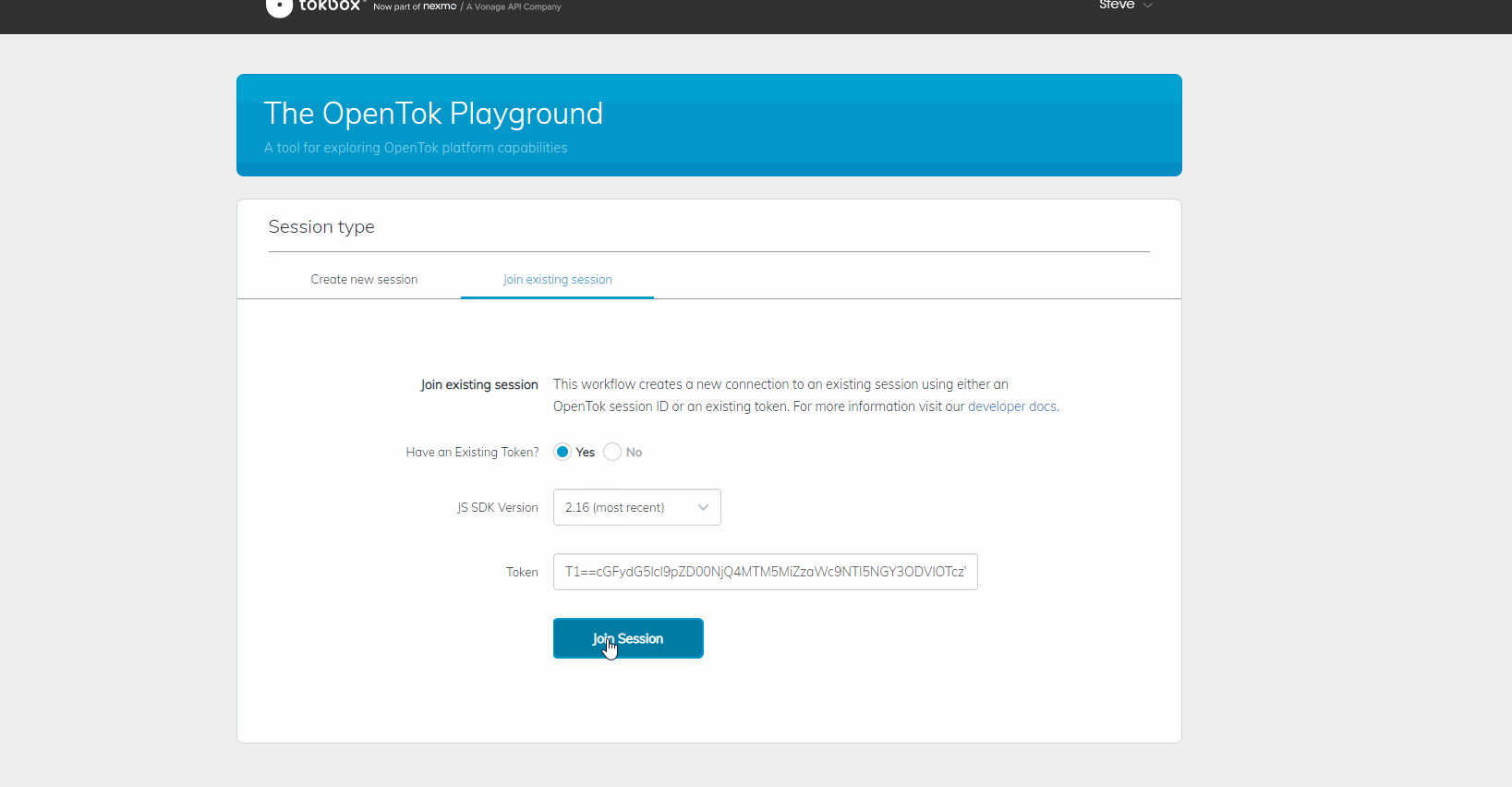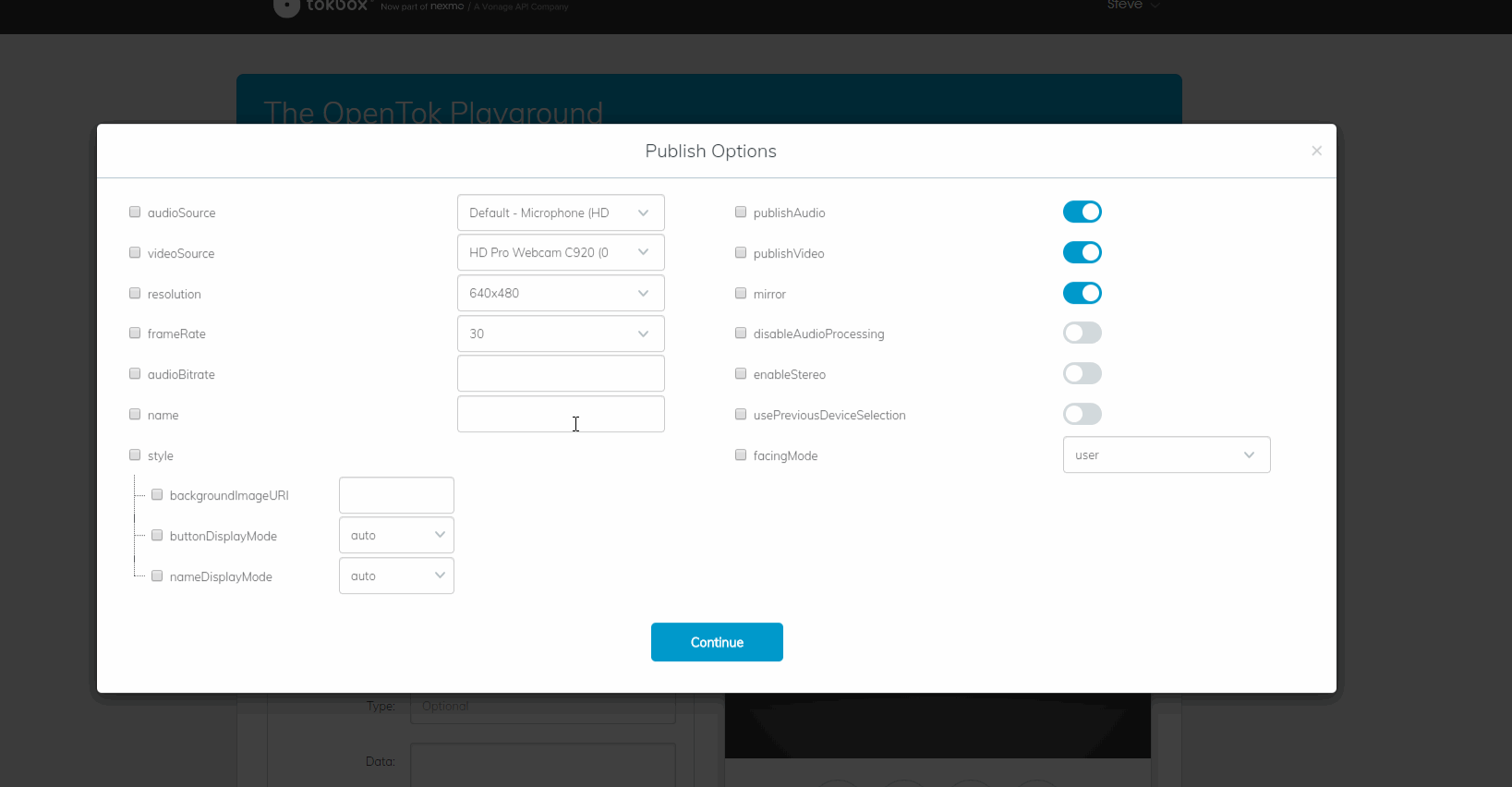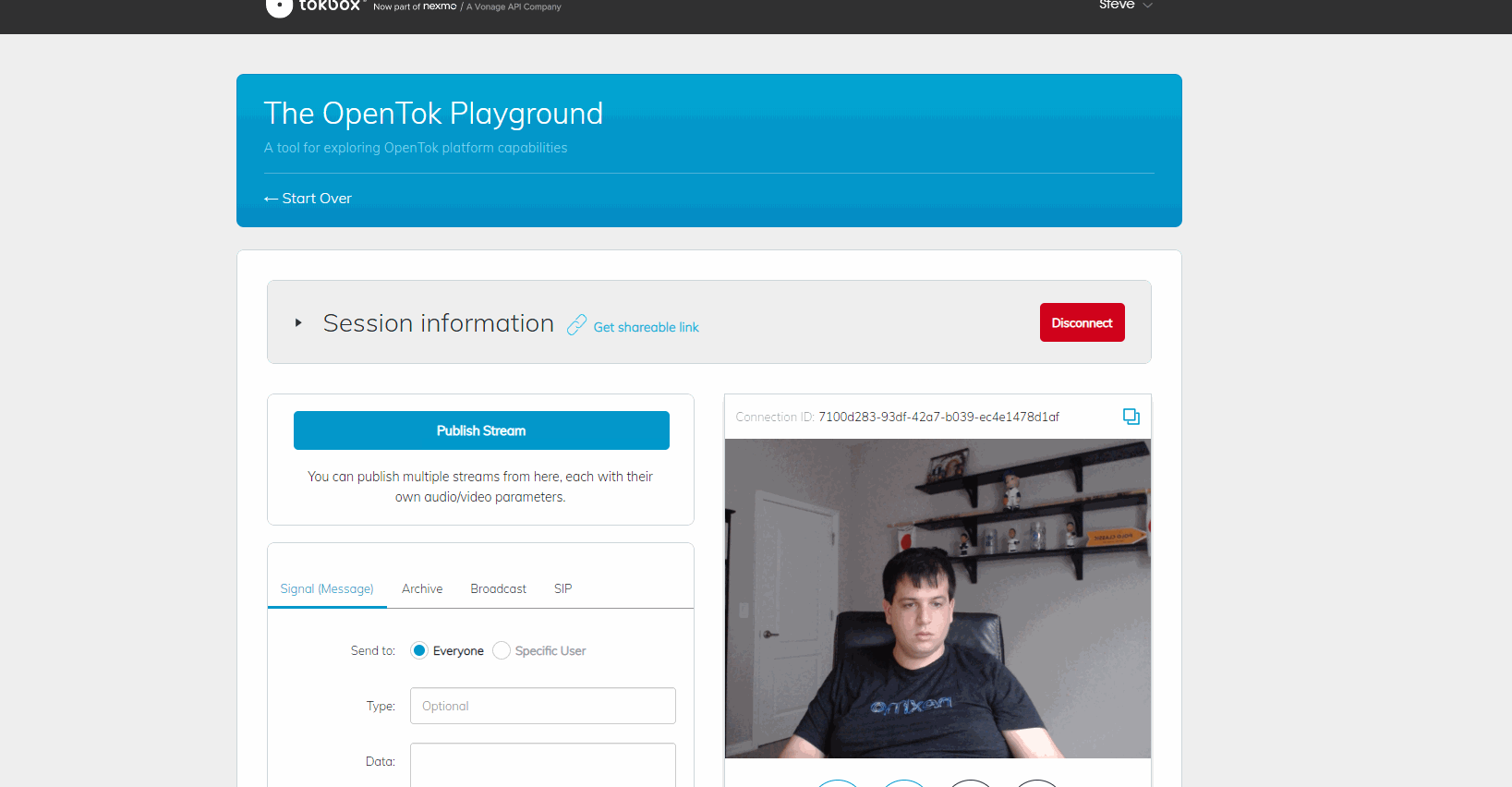 Running in Playground
Running in Playground
Maintenant, si nous connectons notre appel, cela devrait ressembler à ceci dans l'application Windows :
 Display Without Filter Windows App
Display Without Filter Windows App
Et si nous activons le bouton de filtrage, l'image ressemblera davantage à ce qui suit :
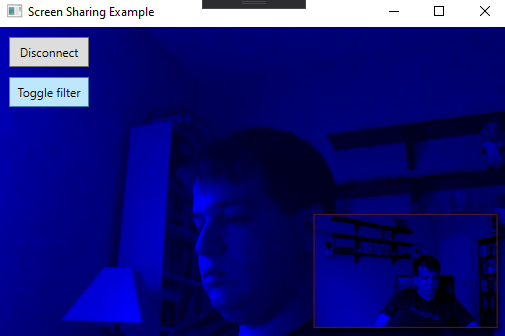 Display With Blue Filter Windows App
Display With Blue Filter Windows App
Pour l'instant, tout ce qui se passe, c'est que si vous cliquez sur le bouton "toggle filter", l'application appliquera une teinte bleue à chaque image qui entre dans le moteur de rendu.
Plutôt que d'utiliser le VideoRenderer standard, nous créons notre propre moteur de rendu personnalisé, SampleVideoRendererqui étend Control et met en œuvre l'interface IVideoRenderer de l'API Video de Vonage. Cette interface est assez simple : elle ne comporte qu'une seule méthode, RenderFrameNous prenons l'image et la dessinons sur une image bitmap dans le contrôle. Cela nous permet d'intervenir à chaque fois qu'une image apparaît, de lui appliquer ce que nous voulons et de la rendre.
Avec ce Custom Renderer, nous avons donc tout ce qu'il faut pour commencer à ajouter le CV à notre application. Ouvrons SampleVideoRenderer.cs et avant de faire quoi que ce soit d'autre, ajoutons les importations suivantes :
using Emgu.CV;
using Emgu.CV.Structure;
using System.Diagnostics;
using System.Drawing;
using System.Collections.Concurrent;
using System.IO;
using System.Threading;Pendant que vous y êtes, renommez EnableBlueFilter en DetectingFaces (assurez-vous d'utiliser la fonction de renommage de votre IDE) et faites-en une propriété public get, private set plutôt qu'un champ public comme ceci :
public bool DetectingFaces { get; private set; }Cela va casser certaines choses, mais la façon de les corriger devrait bientôt devenir évidente. Pour l'instant, nous allons continuer.
Ajoutez les constantes suivantes à votre moteur de rendu :
private const double SCALE_FACTOR = 4;
private const int INTERVAL = 33;
private const double PIXEL_POINT_CONVERSION = (72.0 / 96.0);L'échelle SCALE_FACTOR est l'échelle à laquelle nous allons réduire les images pour le traitement - 4 signifie que nous allons redimensionner les images à un quart de leur taille avant de lancer la détection. Le INTERVAL est le nombre de millisecondes entre les images que nous tenterons de capturer à partir du flux. 33 correspond approximativement au nombre de millisecondes entre les images d'un flux 30FPS, le paramètre as-is signifie donc qu'il fonctionne à pleine vitesse. Le paramètre PIXEL_POINT_CONVERSION est le ratio de pixels par point sur un écran de 96 DPI (ce que j'utilise). Naturellement, ce ratio peut être mieux calculé lorsque nous prenons en compte la sensibilité au DPI, mais nous allons utiliser ce ratio pour l'instant. Nous en avons besoin uniquement parce que, pour une raison quelconque, la bibliothèque Bitmap Extensions que nous utilisons semble vouloir dessiner X en points et Y en pixels 🤷♂️.
J'ai brièvement abordé le fonctionnement des fonctions de type Haar plus haut, mais pour un examen plus approfondi, n'hésitez pas à consulter l'article de Viola-Jones de Viola-Jones. L'avantage d'OpenCV (et d'EmguCV par extension), c'est qu'une grande partie de ces éléments nous est épargnée.
Poursuivons avec notre SampleVideoRenderer. Descendez et ajoutez deux CascadeClassifiers statiques en tant que champs :
static CascadeClassifier _faceClassifier;
static CascadeClassifier _profileClassifier;Ensuite, dans le constructeur, ils sont initialisés avec leurs fichiers respectifs :
_faceClassifier = new CascadeClassifier(@"haarcascade_frontalface_default.xml");
_profileClassifier = new CascadeClassifier(@"haarcascade_profileface.xml");Ces fichiers XML décrivent les caractéristiques de Haar au classificateur suffisamment bien pour l'entraîner. À ce stade, nous avons donc entraîné le classificateur !
Pendant que nous classifions, nous ne voulons pas bloquer le thread principal. Nous allons donc mettre en œuvre le modèle producteur-consommateur. Nous allons utiliser BlockingCollections. Plus précisément, nous allons utiliser un ConcurrentStack, car les images les plus pertinentes et les plus récentes ne font qu'un. Ajoutez les champs suivants à notre classe :
private System.Drawing.Rectangle[] _faces = new System.Drawing.Rectangle[0];
private BlockingCollection<Image<Bgr, byte>> _images = new BlockingCollection<Image<Bgr, byte>>(new ConcurrentStack<Image<Bgr, byte>>());
private CancellationTokenSource _source;
private Stopwatch _watch = Stopwatch.StartNew();Le tableau _faces va contenir les visages que nous avons détectés avec notre classificateur, tandis que la collection, initialisée avec une ConcurrentStack, va être la collection LIFO des images que nous allons traiter. _images initialisée avec une ConcurrentStack, sera la collection LIFO des images que nous allons traiter. La source CancellationTokenSource est ce que nous allons utiliser pour nous retirer de la boucle de traitement le moment venu. Le chronomètre va nous servir de gardien du temps en nous empêchant d'essayer de détecter des images trop rapidement.
Mettons maintenant en œuvre notre boucle de traitement. Ajoutez la méthode suivante à votre code :
private void DetectFaces(CancellationToken token)
{
System.Threading.ThreadPool.QueueUserWorkItem(delegate
{
try
{
while (true)
{
var image = _images.Take(token);
_faces = _faceClassifier.DetectMultiScale(image);
if(_faces.Length == 0)
{
_faces = _profileClassifier.DetectMultiScale(image);
}
if (_images.Count > 25)
{
_images = new BlockingCollection<Image<Bgr, byte>>(new ConcurrentStack<Image<Bgr, byte>>());
GC.Collect();
}
}
}
catch (OperationCanceledException)
{
//exit gracefully
}
}, null);
}Il se passe beaucoup de choses dans cette méthode. Tout d'abord, nous allons exécuter l'opération sur l'un des Daemons disponibles du ThreadPool. Ensuite, nous allons procéder à un traitement en boucle serrée. Nous appelons Take à la collection bloquante pour extraire une image de la pile. Cet appel Take bloquera s'il n'y a rien dans la collection, et lorsque nous signalons l'annulation, il lancera une exception OperationCanceledException, que nous rattraperons ci-dessous, ce qui nous permettra de sortir de la boucle de manière élégante. Avec l'image, il assignera la collection _faces au résultat de DetectMultiScalequi est la méthode de détection des visages. Si elle ne trouve rien, elle réessayera avec le classificateur de visage de profil.
Lorsque tout cela est terminé, nous vérifions la collection d'images pour voir si elle dépasse une certaine limite (nous utilisons 25 comme exemple ici). Si elle a dépassé cette limite, parce que le classificateur a pris du retard, nous allons vider la collection en la ré-instanciant, puis nous allons demander au ramasse-miettes de venir collecter ces images. Pourquoi appeler le ramasse-miettes ? C'est le sujet d'un autre article de blog, mais essentiellement si vos objets sont trop grands (plus de 85 000 octets), ils sont poussés sur le Grand tas d'objets (Large Object Heap), auquel le ramasse-miettes attribue une priorité inférieure à celle des autres objets (puisqu'il est assez coûteux en calcul de libérer la mémoire). En pratique, cela signifie que si vous traitez des objets de grande taille assez rapidement, vous devez vous assurer qu'ils sont nettoyés, faute de quoi vous obtiendrez une utilisation importante de la mémoire.
Si vous suivez mes conseils de performance ci-dessous, vous n'aurez jamais besoin d'utiliser ce code, mais je le laisse pour que les gens ne voient pas de pics massifs dans l'utilisation de la mémoire lorsqu'ils effectuent des réglages.
Ajoutez maintenant le code suivant à votre moteur de rendu :
public void ToggleFaceDetection(bool detectFaces)
{
DetectingFaces = detectFaces;
if (!detectFaces)
{
_source?.Cancel();
}
else
{
_source?.Dispose();
_source = new CancellationTokenSource();
var token = _source.Token;
DetectFaces(token);
}
}Ceci va gérer le basculement du détecteur de visage pour votre moteur de rendu. Si vous lui demandez de s'arrêter, il demandera à la source de jetons d'annuler, ce qui vous permettra de sortir de la boucle de manière élégante. Si vous lui dites de démarrer, il se débarrassera de l'ancienne CancellationTokenSource, la réinitialisera, prendra un jeton et démarrera la boucle de traitement avec ce jeton.
Ajoutons également un finalisateur pour nous assurer que la tâche de détection des visages est annulée lorsque le moteur de rendu s'arrête :
~SampleVideoRenderer()
{
_source?.Cancel();
}
Jusqu'à présent, nous avons posé toutes les bases nécessaires à la détection des visages. A partir de là, il s'agit juste de faire en sorte que notre moteur de rendu effectue la détection des visages sur chaque image. Allez maintenant dans la méthode RenderFrame du SampleVideoRenderer. Supprimez les deux boucles for imbriquées et remplacez ce code par :
using (var image = new Image<Bgr, byte>(frame.Width, frame.Height, stride[0], buffer[0]))
{
if (_watch.ElapsedMilliseconds > INTERVAL)
{
var reduced = image.Resize(1.0 / SCALE_FACTOR, Emgu.CV.CvEnum.Inter.Linear);
_watch.Restart();
_images.Add(reduced);
}
}
DrawRectanglesOnBitmap(VideoBitmap,_faces);Il va extraire l'image directement du tampon que notre filtre précédent copiait, puis pousser la nouvelle image sur notre pile de blocage, et enfin dessiner les rectangles sur les faces détectées. Sous la méthode RenderFrame ajoute la méthode DrawRectanglesOnBitmap qui ressemblera à
public static void DrawRectanglesOnBitmap(WriteableBitmap bitmap, Rectangle[] rectangles)
{
foreach (var rect in rectangles)
{
var x1 = (int)((rect.X * (int)SCALE_FACTOR) * PIXEL_POINT_CONVERSION);
var x2 = (int)(x1 + (((int)SCALE_FACTOR * rect.Width) * PIXEL_POINT_CONVERSION));
var y1 = rect.Y * (int)SCALE_FACTOR;
var y2 = y1 + ((int)SCALE_FACTOR * rect.Height);
bitmap.DrawLineAa(x1, y1, x2, y1, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x1, y1, x1, y2, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x1, y2, x2, y2, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x2, y1, x2, y2, strokeThickness: 5, color: Colors.Blue);
}
}Cela dessinera le rectangle sous forme de 4 lignes séparées sur le bitmap et l'affichera - notez que nous utilisons la fonction PIXEL_POINT_CONVERSION sur le x uniquement.
J'ai remarqué que l'élément PublisherVideo dans la fenêtre principale est un peu petit pour que je puisse voir ce qui s'y passe. Pour mes tests, j'ai donc doublé ou quadruplé la taille de la fenêtre. Pour ce faire, il suffit d'ajuster la hauteur et la largeur à la ligne 12 de MainWindow.xaml.
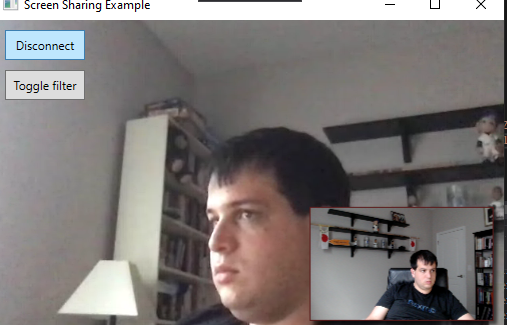
Nous sommes maintenant prêts à lancer l'application et à appuyer sur le bouton Toggle Filter dans le coin supérieur gauche de l'écran. Cela activera le filtre. Vous devriez le voir sur votre aperçu, et si vous vous connectez à un appel, vous pourrez également voir que la détection faciale fonctionne sur les participants distants.
 Display Example With Face Detection
Display Example With Face Detection
Vous constaterez que cette méthode de détection des caractéristiques est à la fois précise et rapide. Le filtre s'exécute en 10 ms environ, contre 30 ms pour le filtre bleu modifié. Et comme le traitement principal s'exécute sur un thread de travail et que le dessin proprement dit prend moins d'une milliseconde, ce filtre est en fait environ trente fois plus rapide, ce qui signifie que l'ajout de la détection faciale est pratiquement gratuit du point de vue de l'interface utilisateur.
Aucune discussion sur la vision par ordinateur ne serait complète sans un petit mot sur le réglage paramétrique. Il y a toutes sortes de paramètres que vous pouvez potentiellement régler ici, mais je vais seulement me concentrer sur deux d'entre eux :
Intervalle entre les trames
Facteur d'échelle
Comme mentionné précédemment, les 33 millisecondes entre les images me convenaient, surtout si je réglais le facteur d'échelle de manière appropriée. Le facteur d'échelle est l'élément le plus important pour les performances. Si vous réglez le facteur d'échelle sur 1 - en d'autres termes, essayez de prendre une image complète (dans mon cas, 1280x720) - cela représente 921 000 pixels à traiter toutes les 33 millisecondes, ce qui a un coût substantiel en termes de performances. Sur ma machine, cela tournerait à environ 200 ms par image, mettrait mon processeur à rude épreuve et, sans l'appel explicite au ramasse-miettes, ferait exploser l'utilisation de la mémoire. N'oubliez pas que le facteur d'échelle est quadratique, donc en fixant le facteur d'échelle à 4, le nombre de pixels diminue d'un facteur de 16. D'après mes tests, je n'ai constaté aucune perte de précision lors du redimensionnement.
Nous allons en rester là pour l'instant, mais j'espère que ce billet incitera le lecteur à reconnaître l'immense potentiel d'OpenCV dans .NET. Voici quelques applications intéressantes pour lesquelles vous pourriez l'utiliser, à titre d'exemple :
Ajouter des filtres et intégrer la réalité augmentée dans vos applications. Consultez quelques articles sur Homographies et les algorithmes de suivi des caractéristiques. Personnellement, j'aime bien ORB (ne serait-ce que parce qu'il est beaucoup plus libre que les autres algorithmes de suivi des caractéristiques !)
Vous pouvez intégrer la fonction Far End Camera Control (FECC) dans votre application et régler les mouvements de la caméra pour qu'elle suive votre visage !
Une fois que vous avez trouvé le retour sur investissement des visages dans votre image, vous pouvez effectuer plus efficacement des opérations telles que l'analyse des sentiments.
Comme on peut l'imaginer, il s'agit de la première étape de la reconnaissance faciale.
Vous pouvez trouver un exemple de ce tutoriel sur GitHub ici
Pour tout ce que vous voulez savoir sur l'API Video de Vonage, consultez notre site
Pour tout ce que vous voulez savoir sur OpenCV, consultez leur docs
Consultez la page wiki d'Emgu pour en savoir plus sur l'utilisation d'Emgu en particulier. Si vous êtes un fan d'OpenCv Python comme moi, vous n'aurez aucun problème à utiliser Emgu.