Your AI Agent Is Lying to You: How Workflows Create Reliable Results
Time to read: 15 minutes
In this article, you’ll learn how the Vonage AI team used workflows to make agentic AI systems more predictable, reproducible, and production-ready.
Generative AI is probabilistic by nature. Ask an AI model to write an email, summarize a meeting, or generate code, and slightly different results between runs usually are not a problem. In many creative or exploratory tasks, variation is part of the value.
Analytical systems are different.
When AI systems are used to rank employees, generate operational reports, review customer interactions, or identify business trends, consistency matters. If the same query against the same data produces different answers every time, it becomes difficult to trust the output or make decisions based on it.
During internal experiments at Vonage, we observed this firsthand while building AI-driven analytics workflows for customer experience data. In one run, an agent ranked Maria as the top support representative. Fifteen minutes later, using the same setup, the same system ranked James first instead. A third run produced Priya as the top result.
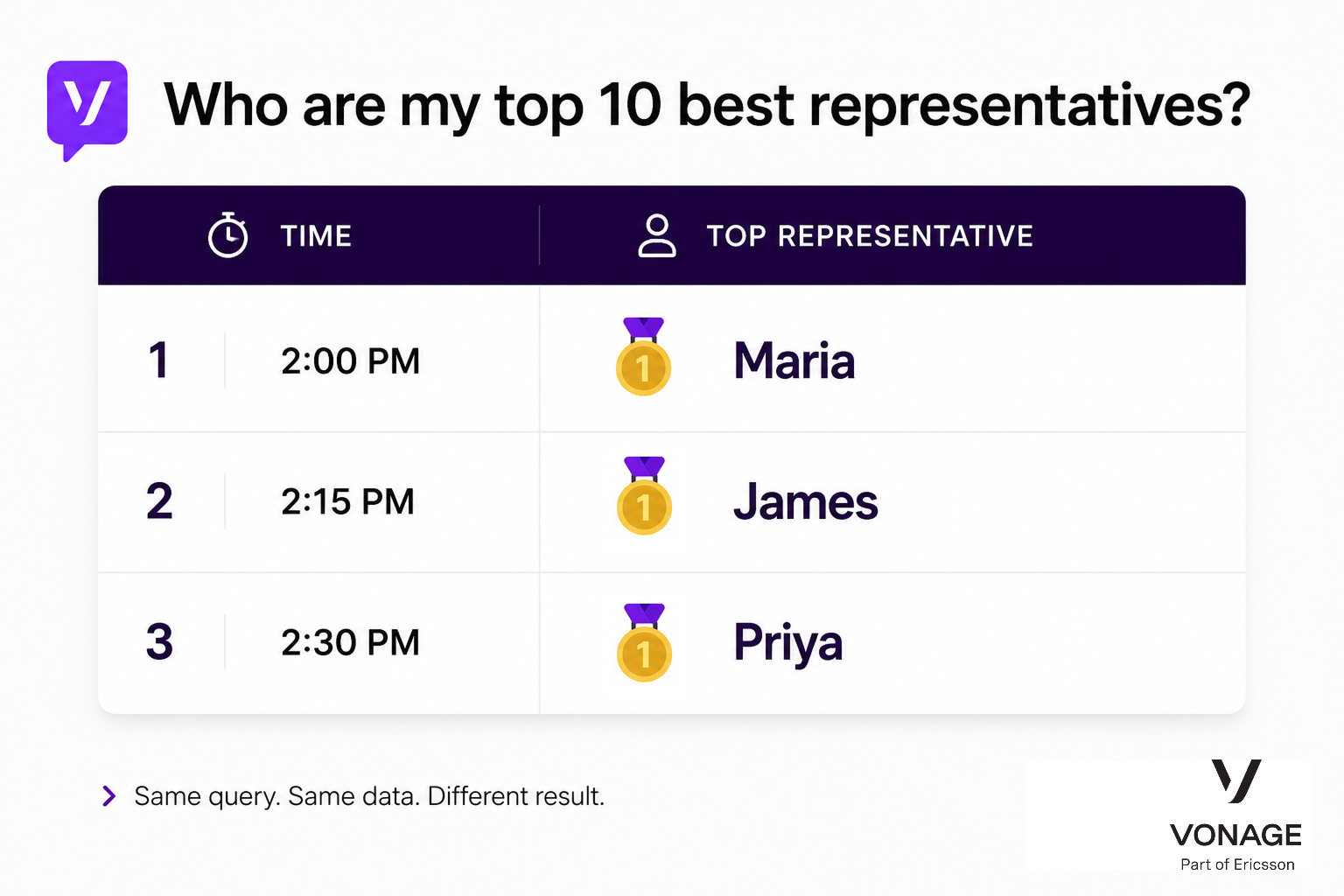 The same AI analytics query produced different top-ranked representatives across repeated runs, despite using the same dataset and prompt.
The same AI analytics query produced different top-ranked representatives across repeated runs, despite using the same dataset and prompt.
For exploratory analysis, this kind of variability can be acceptable. But for scheduled dashboards, operational reviews, quality assurance workflows, or compliance reporting, inconsistent outputs quickly become a production problem.
This raised an important question for the Vonage AI team: how do you make agentic systems more predictable when consistency matters?
To investigate this, we ran a series of experiments comparing standard agentic execution against workflow-driven execution paths designed to lock analytical methodology, reduce reasoning drift, and improve reproducibility. The results showed that workflows can significantly improve consistency in AI-driven analytical systems without removing the flexibility that makes agents useful in the first place.
Modern agentic systems do more than generate text. They reason through problems, choose analytical methodologies, write intermediate code, apply calculations, and determine how results should be presented.
Small differences in reasoning early in an agentic execution loop can compound into materially different outputs later in the process.
During our experiments, we repeatedly observed the same pattern: identical queries against identical datasets produced different results across runs. A request like:
“Who are my top 10 best representatives?”
could produce three different top-ranked employees within the span of half an hour.
The underlying data never changed. What changed was the agent’s reasoning process.
To answer a query like this, an agent has to make a series of decisions before it writes a single line of analysis code:
Which metrics matter most?
How should those metrics be weighted?
How should values be normalized?
Which thresholds or filters should apply?
How should the final results be presented?
Those decisions are not explicitly defined in the prompt. The model infers them during execution, and small differences in reasoning can lead to different analytical approaches.
In one run, the agent might prioritize customer sentiment and empathy scores. In another, it might weigh resolution rate more heavily or exclude low-volume representatives entirely. The result is a different calculation path and, ultimately, a different ranking.
This kind of variability is manageable during exploration. But in production systems—where reports, dashboards, audits, and operational decisions depend on consistency—it becomes a reliability problem.
Most modern AI agents use a reasoning pattern commonly called ReAct (Reason → Act → Observe). Instead of generating a single response, the agent works through a sequence of decisions and tool calls.
A simplified execution flow might look like this:
Reason → Understand the dataset
Act → Query available columns
Observe → Review available features
Reason → Select metrics and methodology
Act → Generate analysis code
Observe → Evaluate results
Reason → Format the final response
Every reasoning step creates another opportunity for divergence.
A small change early in the process—like selecting different metrics or assigning slightly different weights—can alter every downstream step that follows. The agent may generate different analysis code, apply different filters, or calculate scores differently, even when the original query and dataset remain identical.
The diagram below illustrates how a single reasoning decision can push the agent into completely different execution paths.
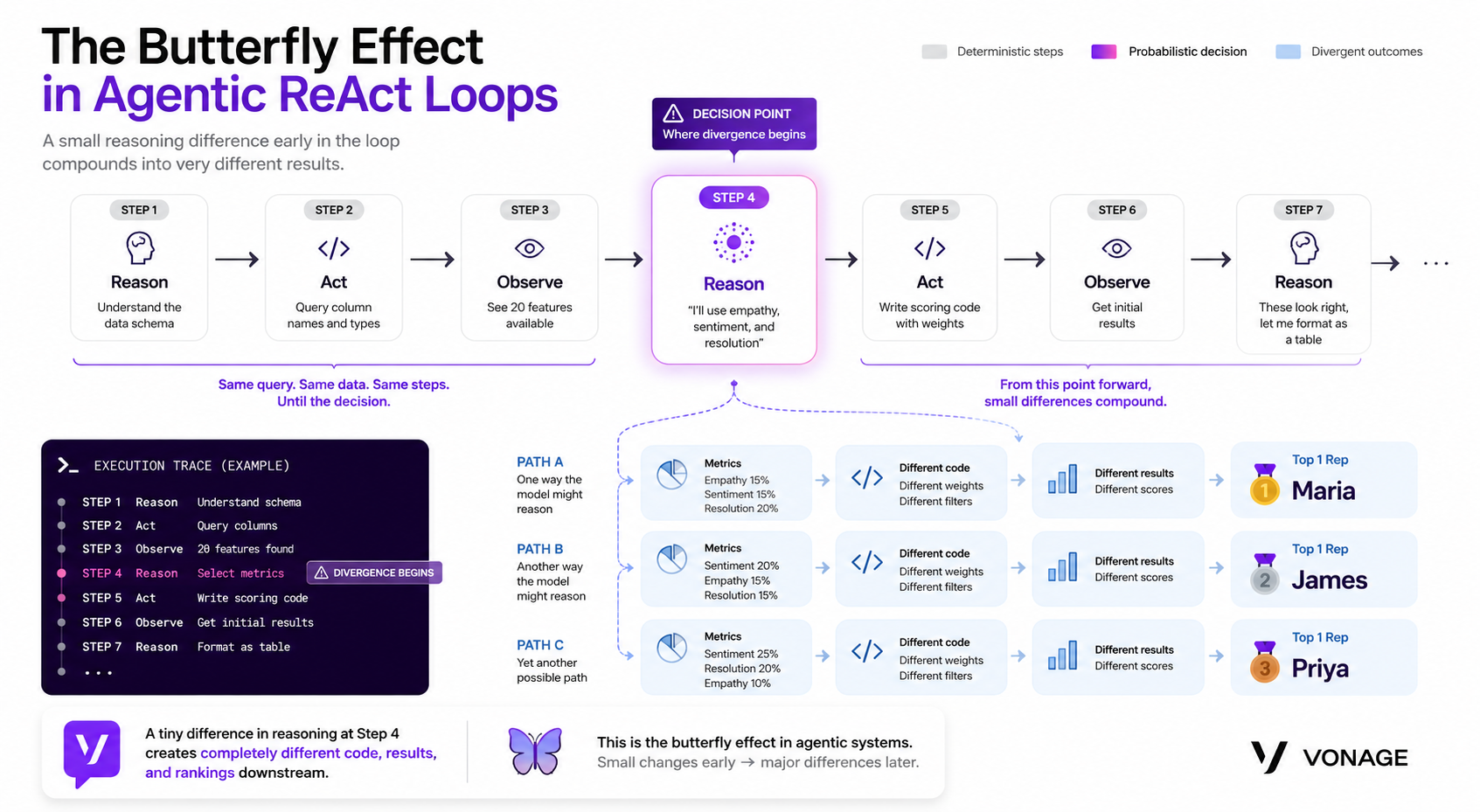 A small reasoning difference inside a ReAct loop can compound into different analytical methodologies, calculations, and final outputs across repeated agent runs.
A small reasoning difference inside a ReAct loop can compound into different analytical methodologies, calculations, and final outputs across repeated agent runs.
This compounding effect is one of the core challenges in production agentic systems. The longer the reasoning chain becomes, the more opportunities there are for outputs to drift between runs.
To reduce this variability, we explored whether workflows could constrain the parts of the system most responsible for analytical drift.
Instead of allowing the agent to invent a new methodology every time a query runs, a workflow provides a predefined execution path based on a validated “golden run.” The workflow preserves the analytical structure that produced a trusted result, including:
selected metrics
calculation logic
thresholds and filters
output structure and formatting
Note >> See the full experiment setup and golden run in the accompanying Github repo.
The agent still executes the analysis and interacts with live data, but the critical methodological decisions are no longer re-derived on every run.
A simplified workflow step might look like this:
STEP 2: Aggregate Agent Performance Metrics
PURPOSE: Calculate average performance metrics across all calls
ACTION: Group by agent_id and calculate averages
OUTPUT: Consistent scoring dataset for ranking
The goal was not to make agents deterministic in the traditional software sense. Instead, we wanted to test whether workflows could reduce reasoning drift enough to make analytical outputs more stable, reproducible, and production-ready.
To evaluate whether workflows could reduce variability in analytical agent systems, we ran a series of controlled experiments using real customer experience data.
We tested the same analytical queries repeatedly against a call center dataset containing:
~3,900 customer interactions
33 support representatives
20 extracted performance features
All experiments used Claude Opus 4.5 through AWS Bedrock with default temperature settings.
For each test case, we first ran the query 10 times using a standard agentic execution flow. We then created a workflow from one validated “golden run” and executed that workflow 10 additional times against the same dataset.
The goal: measure how much the outputs changed between runs, and whether workflows could reduce that drift.
Note >> Exact experiment setup can be seen in the appendix on Github.
Our first experiment focused on a simple analytical query:
“Who are my top 10 best representatives based on overall performance metrics?”
At first glance, this appears straightforward. But the agent still needs to make several analytical decisions before it can generate a ranking:
Which metrics matter most?
How should those metrics be weighted?
How should scores be normalized?
Which filters or thresholds should apply?
Without a workflow, those decisions changed from run to run.
Across 10 independent executions of the same query, the agent repeatedly generated different analytical approaches. It changed metric weights, used different scoring scales, and varied how many performance factors were included in the ranking.
In some runs, customer sentiment carried the highest weight. In others, the resolution rate became the dominant factor. Some executions used a 0–1 scoring scale, while others switched to a 0–100 scale.
Those small methodological changes produced different outcomes. Three different representatives took the No. 1 position across 10 runs.
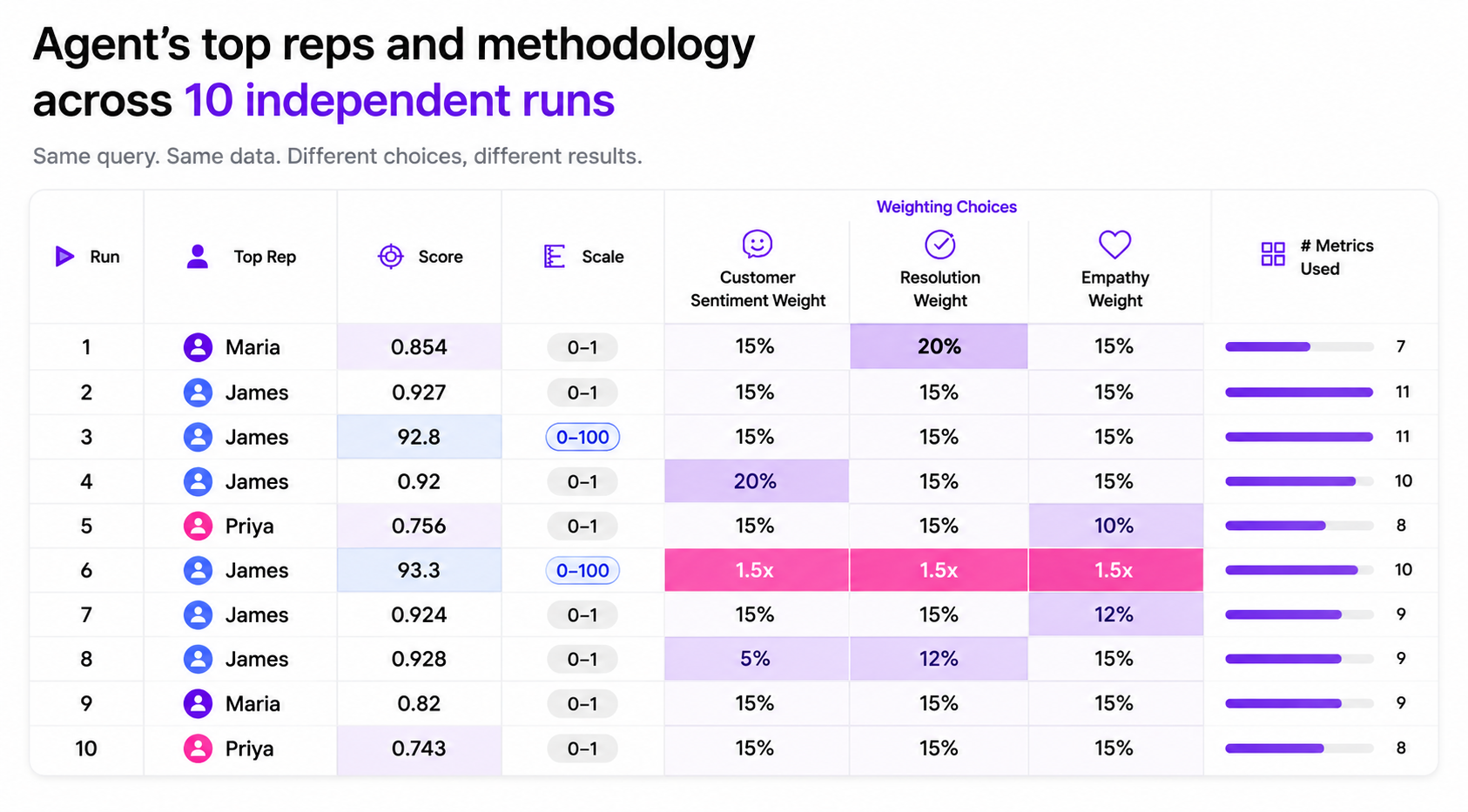 Repeated executions of the same AI ranking query produced different scoring methodologies, metric weights, and top-ranked representatives across 10 independent runs.
Repeated executions of the same AI ranking query produced different scoring methodologies, metric weights, and top-ranked representatives across 10 independent runs.
The variability was not caused by changing data. The ranking drift came from the agent continuously reinterpreting how the analysis itself should work.
To measure whether workflows reduced this drift, we repeated the experiment using a workflow generated from a validated “golden run.”
Without a workflow, the rankings changed significantly between executions. Different representatives appeared, disappeared, or moved dramatically between runs. Some executions even returned fewer than 10 results because the agent formatted the response differently.
With a workflow in place, the rankings became far more stable. The same representative ranked No. 1 in every workflow run, the same representative ranked No. 2 in every workflow run, and the full set of top 10 representatives remained identical across executions.
Only minor ordering differences appeared lower in the rankings.
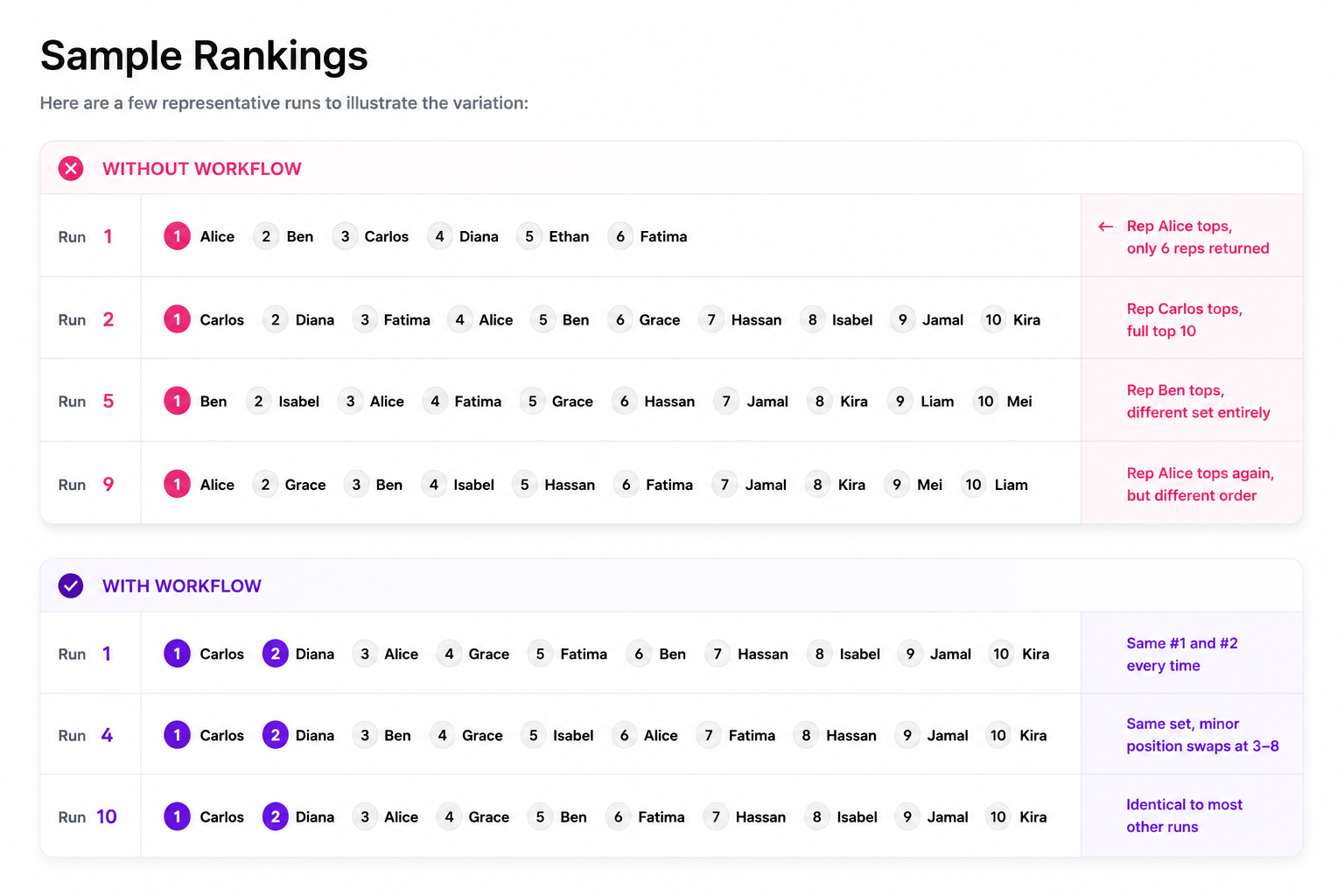 Workflow-constrained executions produced significantly more stable ranking results across repeated runs compared to fully dynamic agentic execution.
Workflow-constrained executions produced significantly more stable ranking results across repeated runs compared to fully dynamic agentic execution.
The consistency improvements were measurable across every ranking metric we evaluated:
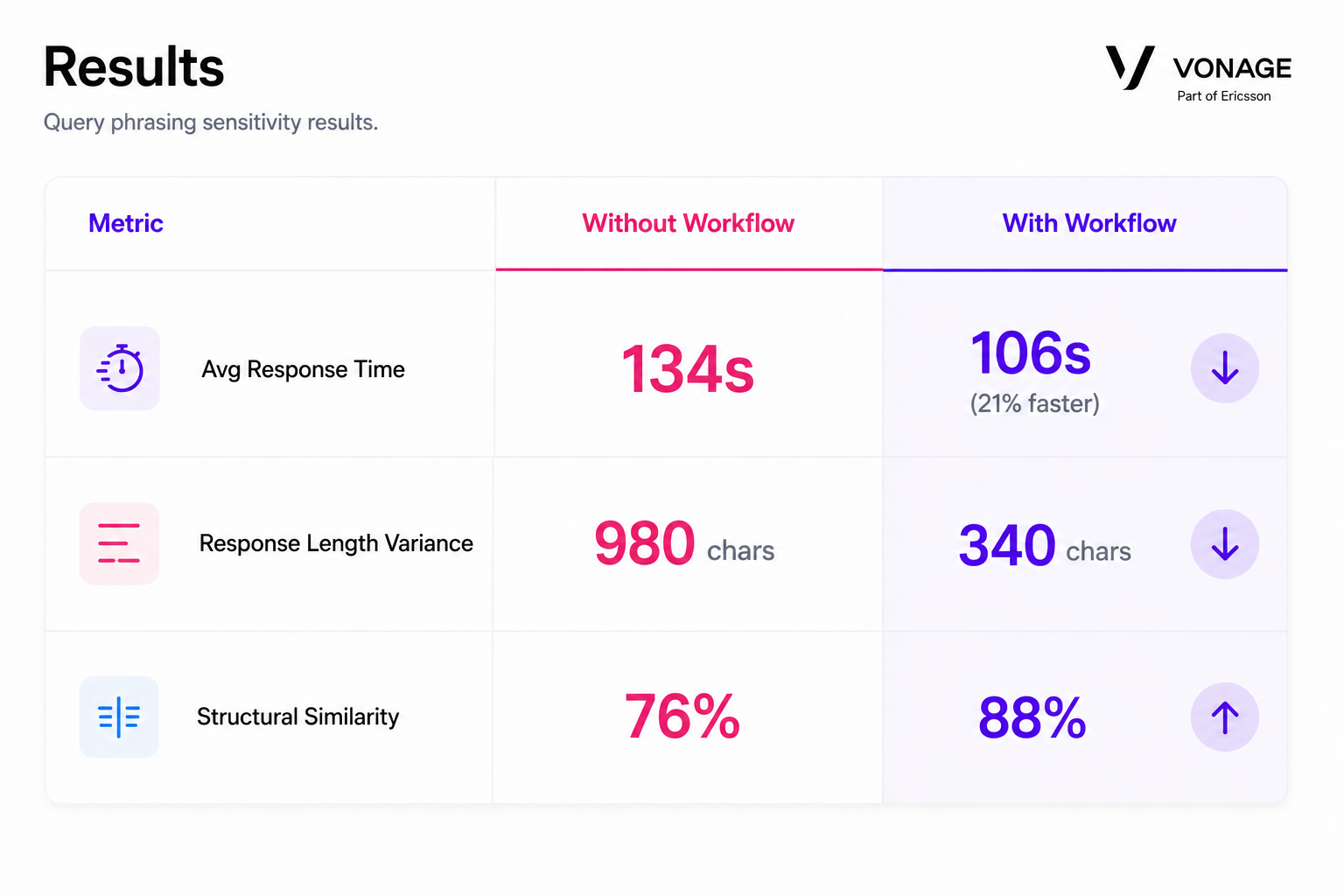
Top-1 consistency improved from 60% to 100%
Top-10 overlap became completely stable across workflow runs
Ranking similarity increased significantly between executions
Workflows reduced both ranking drift and methodology drift. We’ll return to two important implications (correctness and execution speed) in the takeaways section.
Our second experiment tested how sensitive the agent was to small variations in natural language phrasing.
We asked the same question four slightly different ways:
“Who are my top 10 best reps?”
“Show me the 10 highest performing reps”
“List the best 10 reps by performance”
“Which reps have the best metrics?”
Each variation was executed multiple times both with and without workflows.
Without a workflow, these small wording changes often produced noticeably different analytical behavior. Terms like “best reps,” “highest performing,” and “best metrics” pushed the agent toward different interpretations of the task. In some runs, the analysis focused more heavily on measurable KPIs like resolution rate, while other runs emphasized sentiment or broader composite scoring.
Humans generally interpret these phrases as equivalent. The agent did not.
With workflows enabled, the phrasing became far less important because the execution methodology was already defined. Instead of reinventing the analysis for every wording variation, the system reused the same validated execution path.
The results showed measurable improvements in both consistency and execution stability.
 Workflow-constrained executions produced more consistent analytical structures and response formats across different phrasings of the same query.
Workflow-constrained executions produced more consistent analytical structures and response formats across different phrasings of the same query.
Workflows reduced the impact of linguistic ambiguity and made the system’s behavior more predictable across semantically similar requests.
Ranking variability is easy to notice. Aggregation drift is often harder to detect—but much more dangerous in production reporting systems.
To test how agents handled more complex analytical tasks, we repeatedly ran the following query against the same dataset:
“Calculate the average sentiment score grouped by call_reason_category, and identify which categories have declining trends.”
Unlike a simple ranking query, this type of request forces the agent to make several layered analytical decisions during execution:
How should categories be grouped?
How should averages be calculated?
How should "declining" be defined?
Which filters or thresholds should apply?
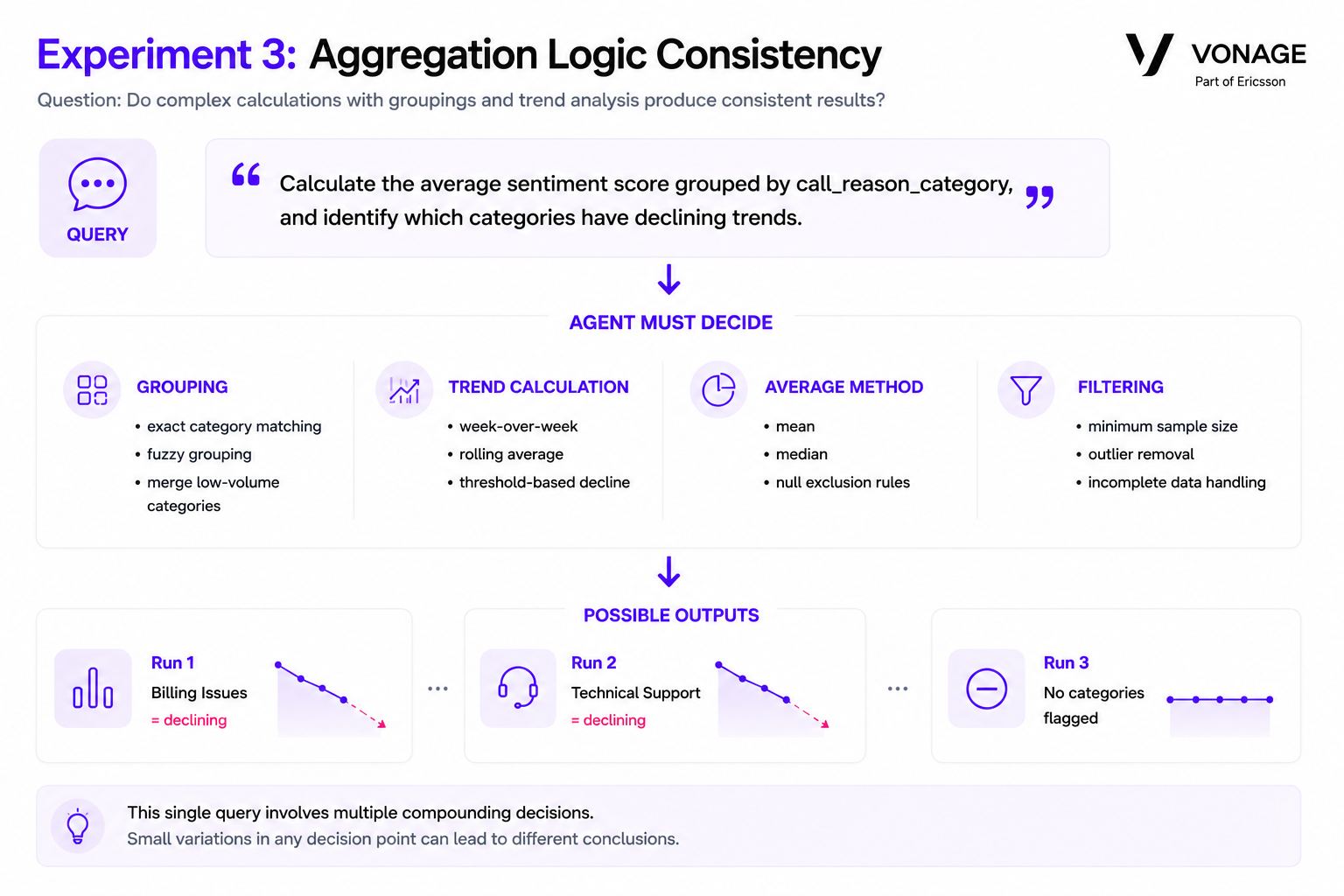 Complex aggregation queries require agents to make multiple methodological decisions that can lead to inconsistent analytical outcomes across repeated runs.
Complex aggregation queries require agents to make multiple methodological decisions that can lead to inconsistent analytical outcomes across repeated runs.
Without workflows, these decisions varied noticeably between runs. Some executions used different time windows for trend analysis; others grouped categories differently; some filtered out low-volume categories entirely, while others included them.
As a result, the same category could appear as “declining” in one run and “stable” in another, even though nothing in the data changed.
This type of variability matters because aggregation queries sit at the center of operational reporting systems. Dashboards, KPI reviews, compliance reports, and executive summaries all depend on calculations producing consistent results over time.
With workflows enabled, the aggregation methodology remained stable across executions. Grouping logic, trend calculations, thresholds, and filtering rules were preserved from the validated workflow definition, producing reproducible outputs across repeated runs.
Workflows reduced the risk of analytical drift in reporting scenarios where consistency is not just useful, but legally required.
Our final experiment focused on queries with intentionally ambiguous or conflicting criteria.
We asked the agent:
“Find reps with compliance risks who also have high customer satisfaction.”
This type of request appears frequently in operational analytics. Teams often need to identify unusual combinations of signals, such as employees who generate strong customer feedback while also triggering elevated compliance concerns.
The challenge is that terms like “high customer satisfaction” and “compliance risk” are not mathematically defined in the query itself. The agent must decide what those thresholds mean during execution.
Without workflows, those definitions changed significantly between runs.
In some executions, “high satisfaction” meant scores above 4.5. In others, the threshold dropped closer to 3.0. The definition of “compliance risk” also shifted depending on how the agent interpreted escalations, audit findings, or policy violations.
As a result, the same query returned anywhere from 5 to 16 representatives.
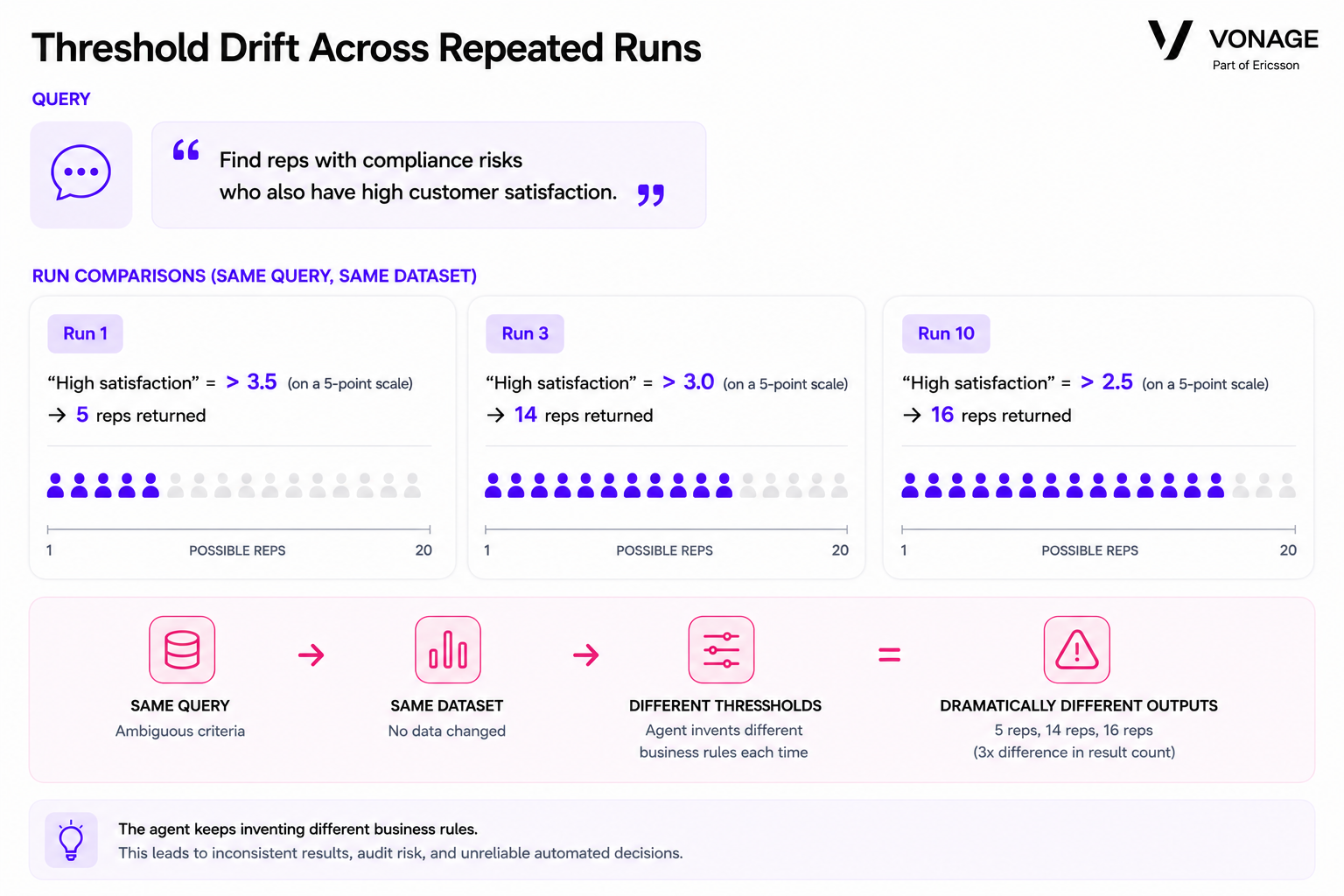 Ambiguous analytical criteria caused the AI agent to apply different thresholds across repeated runs, producing significantly different result counts from the same query and dataset.
Ambiguous analytical criteria caused the AI agent to apply different thresholds across repeated runs, producing significantly different result counts from the same query and dataset.
With workflows enabled, those threshold decisions were preserved from the validated workflow definition, producing substantially more stable outputs across runs.
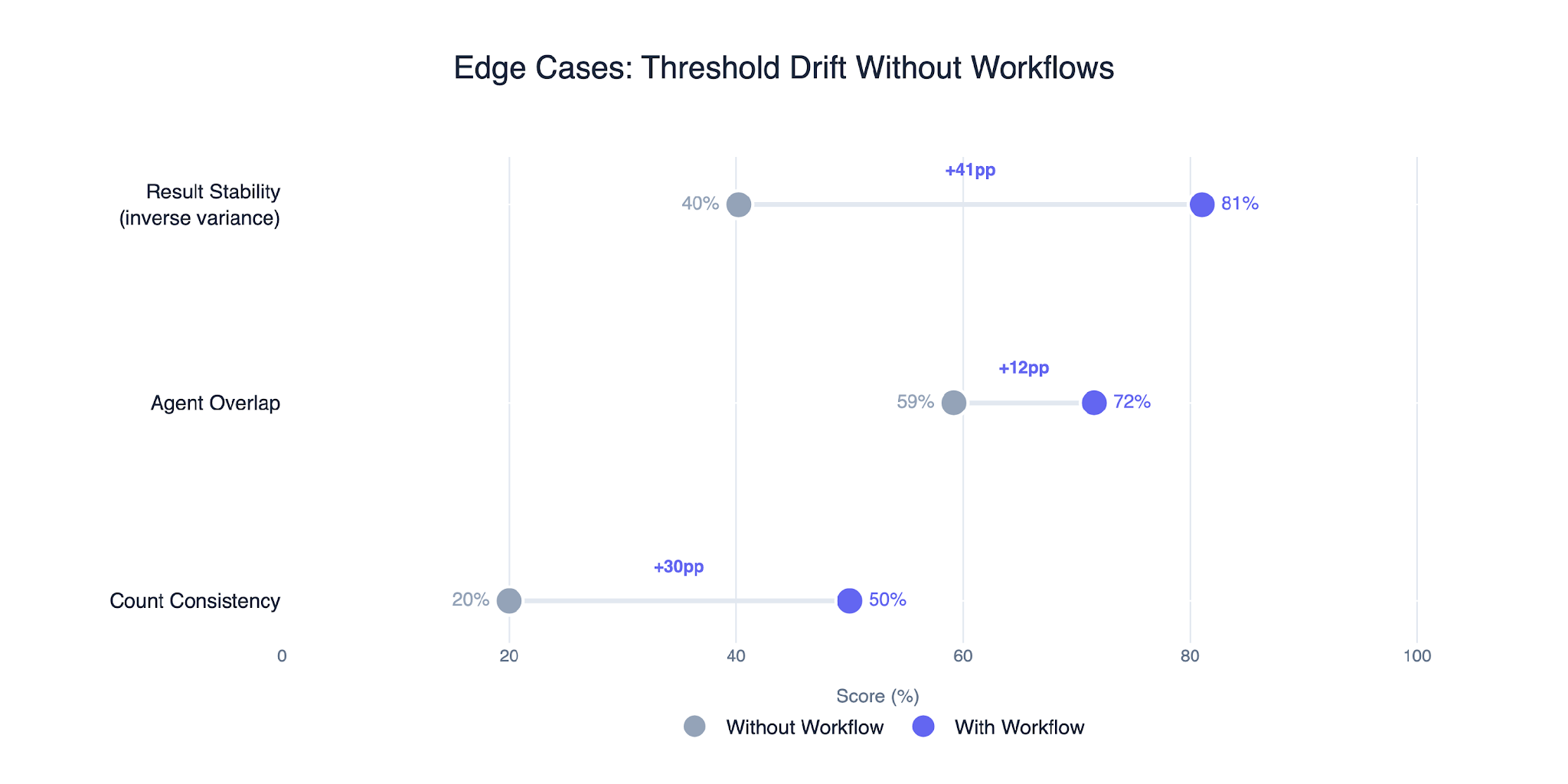 Workflows improved consistency and result stability for ambiguous edge-case queries by preserving threshold definitions across repeated runs.
Workflows improved consistency and result stability for ambiguous edge-case queries by preserving threshold definitions across repeated runs.
Even with workflows, edge cases remained harder to stabilize than the ranking experiments earlier in the article. Ambiguous business language naturally introduces more variance than clearly defined analytical tasks.
However, workflows still reduced threshold drift significantly and improved consistency across:
result counts
representative overlap
output stability
This is important for operational systems like:
anomaly detection
audit reporting
compliance reviews
automated alerting systems
In these environments, inconsistent thresholds can produce false positives, false negatives, or entirely different sets of flagged results from one execution to the next.
Across all four experiments, the agent kept changing how it performed the analysis. Each time it needed to make an ambiguous decision, it created variability in the results.
Without workflows, the agents repeatedly changed how they approached the analysis itself. They selected different metrics, adjusted thresholds, interpreted phrasing differently, and modified grouping or filtering logic between runs—even when the original query and dataset never changed.
Workflows reduced that variability by preserving the analytical methodology from a validated “golden run.”
The biggest source of inconsistency was the analytical methodology changing underneath the system.
Across the experiments, agents repeatedly drifted in areas such as:
metric weighting
threshold definitions
grouping logic
filtering rules
trend calculations
scoring formulas
Each small reasoning change created downstream differences in code generation, calculations, rankings, and outputs.
Workflows constrained those decisions by preserving:
fixed metrics
fixed thresholds
fixed calculation paths
fixed execution order
Instead of rebuilding the methodology during every execution, the system reused a validated analytical process.
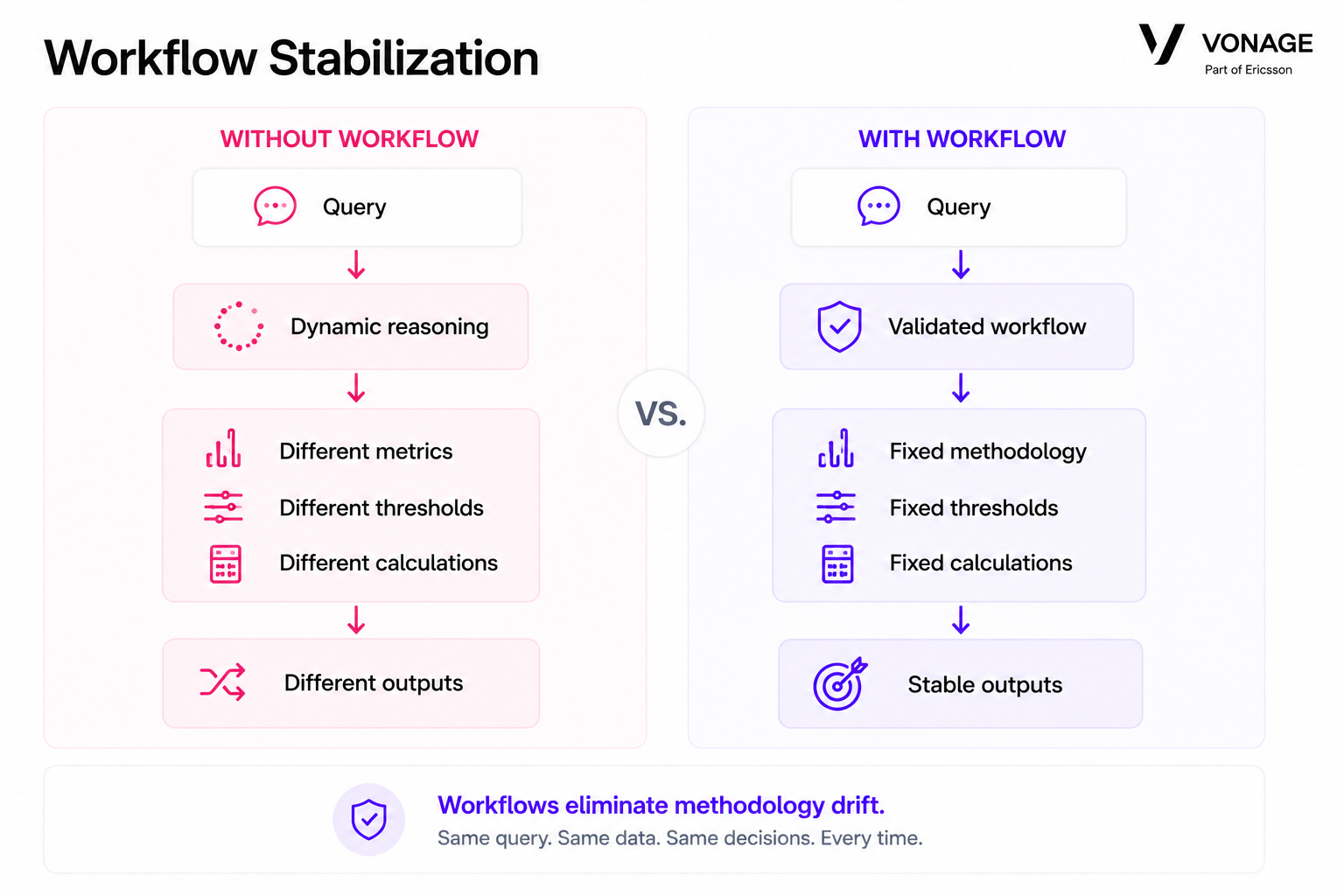 Workflows stabilize AI analytical systems by preserving validated methodologies, thresholds, and calculations across repeated executions."That reduced both reasoning drift and output drift across repeated runs.
Workflows stabilize AI analytical systems by preserving validated methodologies, thresholds, and calculations across repeated executions."That reduced both reasoning drift and output drift across repeated runs.
The impact became clear. With workflows enabled, we observed:
more stable rankings
reproducible aggregation outputs
more predictable result counts
fewer formatting variations
more consistent analytical structure
This matters because production systems depend on outputs remaining stable over time. Dashboards, QA systems, compliance reviews, and automated reporting pipelines all assume that the same query against the same data should produce materially similar results.
Without that consistency, downstream systems become difficult to trust.
The experiments also showed that workflows were most effective when the analytical task itself was well defined. Clear ranking and aggregation tasks stabilized significantly more than highly ambiguous edge-case queries.
One of the biggest lessons from the experiments was that consistency and correctness are not the same thing.
A workflow can reliably preserve a methodology that is statistically weak, operationally flawed, or biased.
In one ranking experiment, the consistently top-ranked representative also had one of the smallest sample sizes in the dataset. The workflow reproduced the same result every time, but that did not automatically make the conclusion trustworthy.
Workflows preserve analytical decisions. They do not validate whether those decisions are correct.
Human review still matters:
metric selection must be evaluated carefully
thresholds require domain expertise
aggregation logic needs validation
edge cases require operational judgment
This becomes important before workflows are promoted into production systems that influence business decisions or customer outcomes.
The goal is not simply reproducibility. The goal is reproducible and well-governed analysis.
Workflow executions were consistently faster across the experiments.
Without workflows, the agent spent time repeatedly:
exploring the dataset
reconsidering methodologies
revising calculations
retrying analytical approaches
generating alternate execution paths
Each additional reasoning step introduced more LLM calls, more execution overhead, and more opportunities for divergence.
With workflows, much of that exploratory reasoning was removed. The execution path was already defined, so the system could focus on running the analysis rather than reinventing it.
Fewer analytical detours resulted in:
shorter execution paths
lower response times
more predictable runtime behavior
The performance gains were not perfectly deterministic, but the trend remained consistent across all experiments: fewer analytical detours resulted in faster and more stable execution.
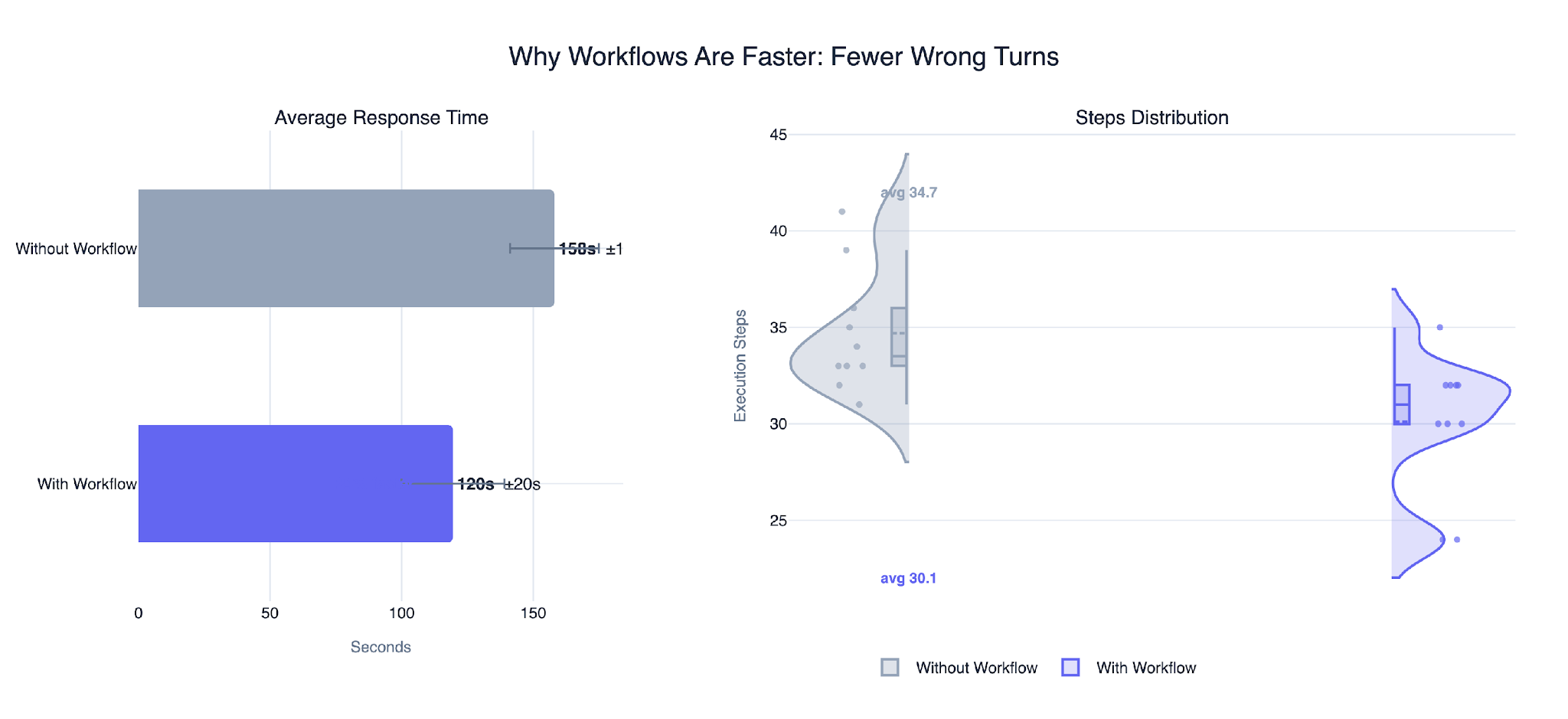 Workflow-constrained executions completed faster and required fewer reasoning steps than fully dynamic agentic executions.
Workflow-constrained executions completed faster and required fewer reasoning steps than fully dynamic agentic executions.
The experiments showed that workflows are most valuable in systems where consistency matters more than exploration.
Workflows are a strong fit when:
Reports need to be reproducible.
Outputs feed downstream systems or dashboards.
Analytical logic must remain stable over time.
The results are reviewed operationally or audited later.
Teams need consistent rankings, thresholds, or calculations across repeated runs.
This is especially important for:
operational reporting
compliance reviews
QA systems
anomaly detection
automated alerting
customer analytics platforms
In these environments, reproducibility matters much more than creativity.
However, workflows are not the right solution for every use case.
Dynamic agentic reasoning still provides value when:
exploring unfamiliar datasets
brainstorming hypotheses
generating alternate analytical perspectives
experimenting with methodologies
searching for unexpected patterns
In those scenarios, variability can actually be useful because it helps surface different approaches and insights.
The key tradeoff is flexibility versus consistency. Workflows intentionally constrain parts of the reasoning process so analytical behavior becomes more predictable over time.
AI agents are powerful because they can reason dynamically, adapt to context, and generate analytical approaches on the fly. But that flexibility also introduces variability.
Across all four experiments, the same pattern emerged: when analytical methodology was left fully dynamic, outputs drifted between runs—even when the query and underlying data never changed.
Workflows reduced that drift by preserving the critical decisions behind the analysis, including metrics, thresholds, grouping logic, and execution paths.
They do not make agentic systems perfectly deterministic, and they do not guarantee correctness. Human review, validation, and domain expertise still matter.
But when consistency, reproducibility, and operational reliability are important, workflows provide a practical way to make agentic systems substantially more predictable in production environments.
Have a question or want to share what you're building?
Subscribe to the Developer Newsletter
Follow us on X (formerly Twitter) for updates
Watch tutorials on our YouTube channel
Connect with us on the Vonage Developer page on LinkedIn
Stay connected and keep up with the latest developer news, tips, and events.
The experiments in this article were supported by a validated "golden run" workflow, along with experiment configurations, metric definitions, and implementation examples.
For readers interested in exploring the methodology in more detail, we've published the complete supporting materials on GitHub:
Build Predictable Agentic Workflows Repository
The repository includes:
the full seven-step golden run workflow,
experiment configurations,
metric definitions,
validation and edge-case handling examples,
and the diagrams used throughout this article.