
Share:
Karl is a Developer Advocate for Vonage, focused on maintaining our Ruby server SDKs and improving the developer experience for our community. He loves learning, making stuff, sharing knowledge, and anything generally web-tech related.
Video + AI: Configurable Audio Processing for Video Applications
Time to read: 6 minutes
Earlier this year, I wrote about a Node application I'd built to transcribe audio from a video call using the Vonage's Video API's Audio Connector feature. The main objective of the application and accompanying blog post was to demonstrate a base-level use-case for the Audio Connector. When thinking about audio processing, transcription is probably one of the first things that comes to mind, so it made sense to focus on this use-case as an introduction to the feature. There is, though, so much more you can do with audio processing, as you may already have seen in other articles in this series, so I thought it might be interesting to build some more features into that application in order to demonstrate a few other use-cases. You can view the updated app on GitHub.
In this article I will briefly outline the added features before providing a high-level explanation of some of the implementation in code. The article is not going to cover the overall architecture or the implementation of the initial iteration of the application, so you may want to read that article first. You can also examine the code (as it was at that point in history) on our Vonage Community GitHub org.
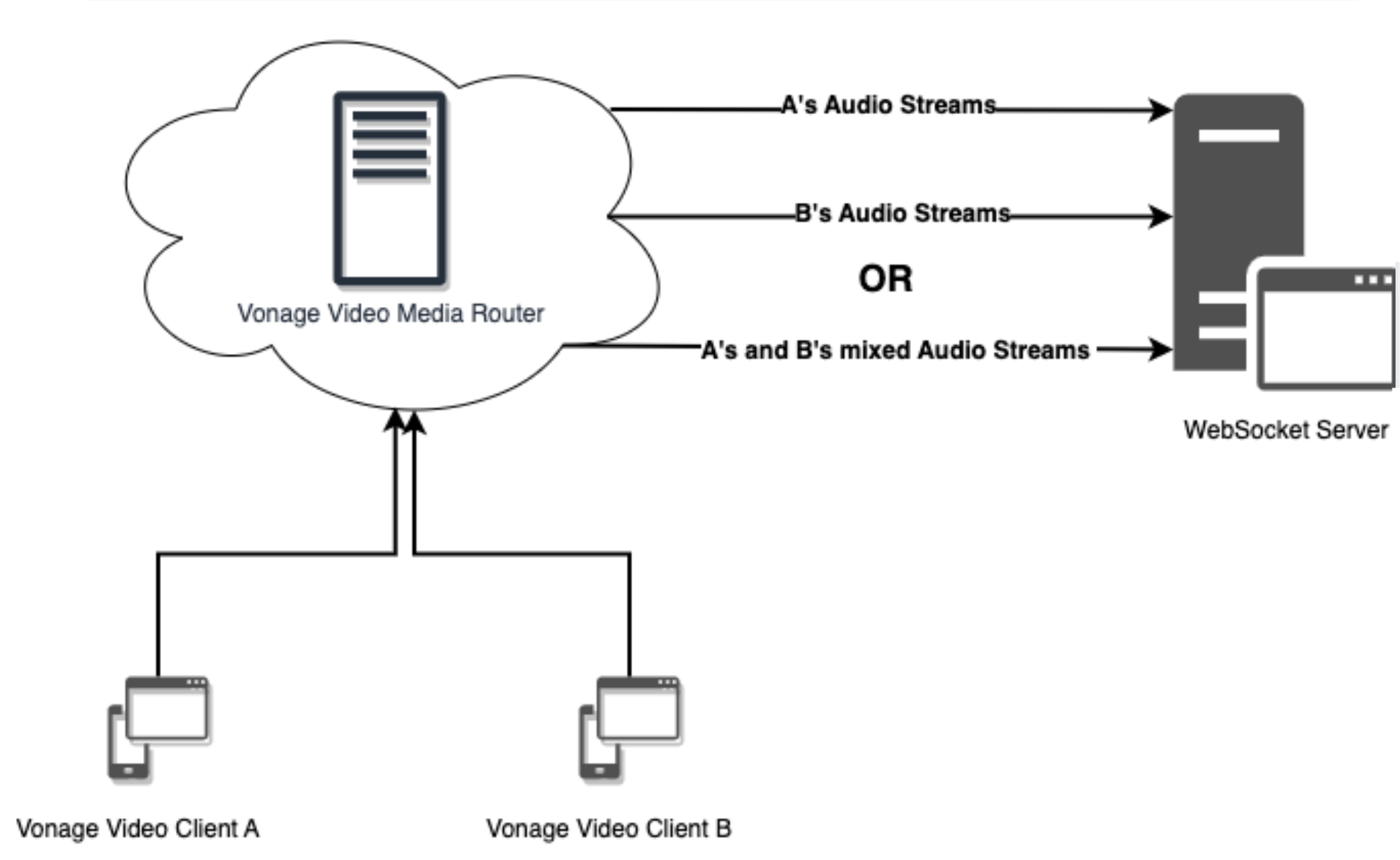
Before outlining the application's new features, just a quick reminder of what Audio Connector is. Audio Connector is a feature of the Vonage Video API that lets you send one or more raw audio streams (either individually or mixed) from a Vonage Video session, via your own WebSocket server, to external services for further processing.
 Audio Connector process flow diagram
Audio Connector process flow diagram
You use it by making a REST API call to Vonage's Video API, detailing the stream or streams that you want the audio for, as well as the WebSocket address to send them to. Essentially, the function of the Audio Connector is to extract audio data from a video call and send that data to a WebSocket. What you then do with that audio data is completely up to you.
You can read more about Audio Connector in the Video API documentation.
In the first iteration of the application, we used the Symbl.ai JavaScript SDK to send the audio data to Symbl's streaming API for transcription. Let's now look at some of the new audio processing features in the current iteration of the app.
As well as transcription, the demo app now provides a number of specific insights based on the audio from a video call.
Questions: Questions are extracted from the audio when a participant in the video call says something as part of the conversation that is framed as a question, for example, "when is the budget for this project?"
Action Items: Similar to questions, these are extracted from a conversation when something is framed as a specific task to be completed, for example "I will complete the blog post by the end of the current sprint."
Topics: Topics are extracted from a conversation when a word or phrase is detected which is determined to be an important keyword.
The new features were implemented in such a way as to provide configurable options for which parts of the audio the end-user would want to process.
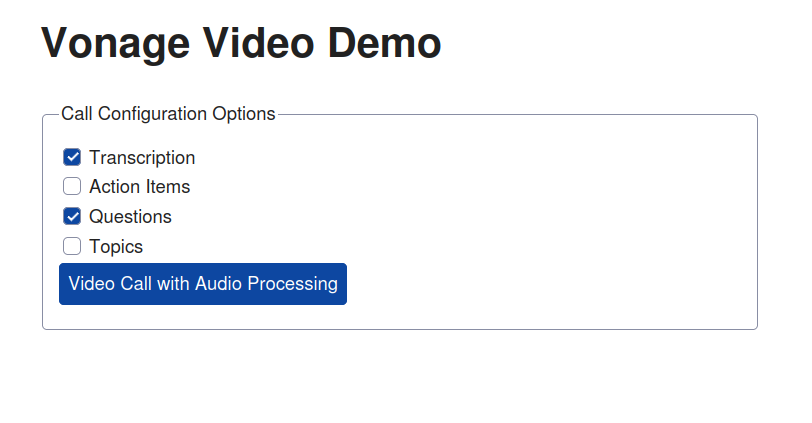
The application flow starts with a form containing a series of checkboxes, each corresponding to a processing option. The user selects the options they want and clicks on the 'Video Call with Audio Processing' button.
 Application Config Options Screen
Application Config Options Screen
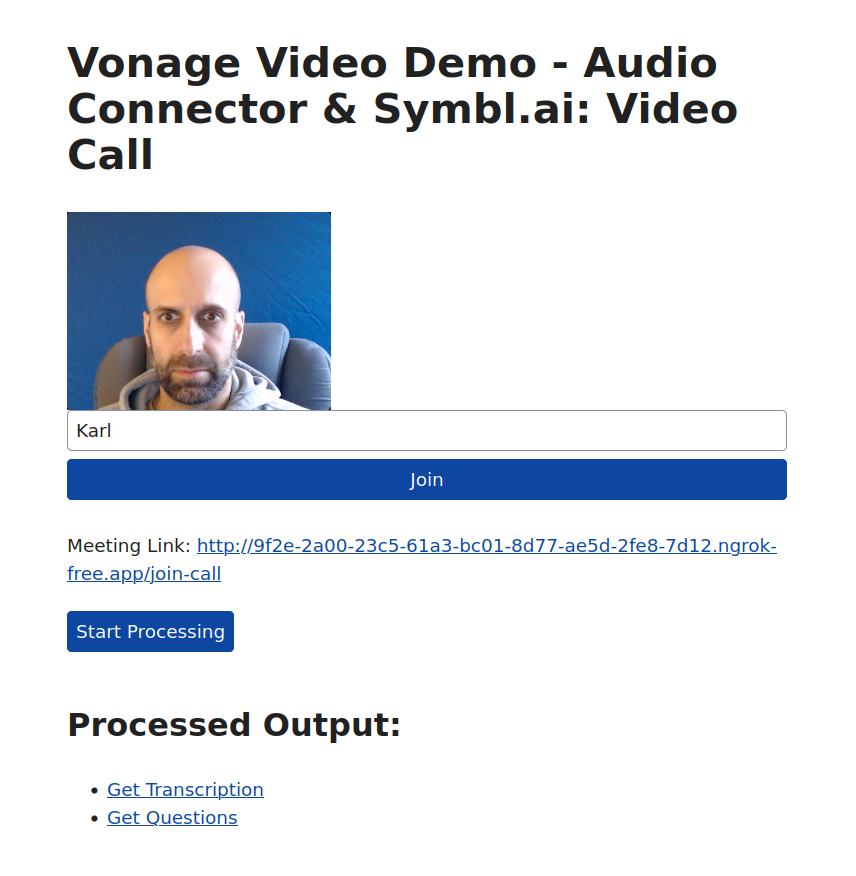
This then takes them to the main call screen, where they can enter their name and start the call. There is a button to start audio processing, and links to pages showing the processed audio for the options selected.
 Main call screen
Main call screen
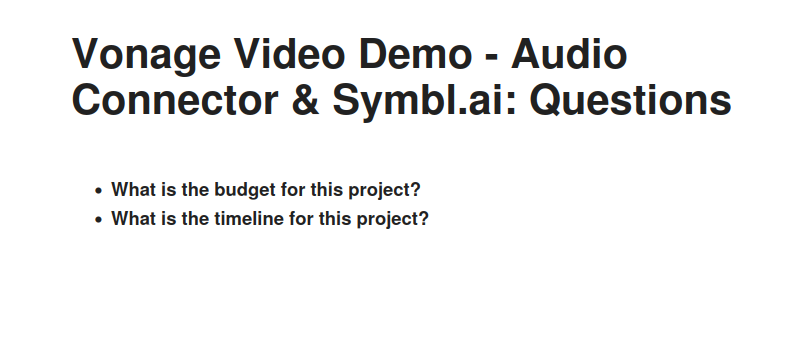
Clicking on the 'Get Questions' link, for example, would take the user to a page listing all the questions detected during the video call.
 Questions output screen
Questions output screen
In the initial iteration of the app, the transcription processing was handled via Symbl.ai's Streaming API, more specifically, by using the JavaScript SDK to make a request to the API using its sendAudio method. There were two main aspects to implementing this:
Defining a handler for speech being detected by the Symbl SDK's
startRealtimeRequestmethod invocation.Doing something with the returned data (which in this case meant storing it in a
transcriptionsarray). This array was made available via theapp.contextobject, so that its contents could then later be rendered as required.
The new processing features (questions, action items, and topics) are also available via Symbl's Streaming API, but require additional handlers. I also decided to store the response data for the different handlers in separate arrays (although I could alternatively have stored them in the same array and filtered them when rendering).
Another aspect of the new features is the fact that they are configurable. So when invoking startRealtimeRequest, I only wanted to add the handlers that were necessary.
The logic for managing all of this was extracted to a SymblProcessor class, and rather than a transcriptions array being defined on app.context within the index.js file, a SymblProcessor object is instantiated and added to the context:
app.context.symblProcessor = new SymblProcessor();Much of the new implementation is handled by this SymblProcessor class.
class SymblProcessor {
constructor() {
this.messages = [];
this.insights = [];
this.topics = [];
this.config = {
transcription: false,
actionItems: false,
questions: false,
topics: false
};
}
setConfig(config) {
config.forEach(option => this.config[option] = true);
}
sethandlers() {
let handlers = {};
if (this.config.transcription) { handlers.onMessageResponse = this.onMessageResponseHandler; }
if (this.config.actionItems || this.config.questions) { handlers.onInsightResponse = this.onInsightResponseHandler; }
if (this.config.topics) { handlers.onTopicResponse = this.onTopicResponseHandler; }
return handlers;
}
setInsightTypes() {
let insightTypes = [];
if (this.config.actionItems) { insightTypes.push('action_item'); }
if (this.config.questions) { insightTypes.push('question'); }
return insightTypes;
}
getTranscriptions() {
return this.messages.map(message => ({id: message[0].from.id, name: message[0].from.name, transcription: message[0].payload.content}));
}
getActionItems() {
let actionItems = this.insights.filter(insight => insight[0].type == 'action_item');
return actionItems.map(item => item[0].payload.content);
}
getQuestions() {
let questions = this.insights.filter(insight => insight[0].type == 'question');
return questions.map(question => question[0].payload.content);
}
getTopics() {
return this.topics.map(topic => topic[0].phrases);
}
onMessageResponseHandler = (data) => {
this.messages.push(data);
}
onInsightResponseHandler = (data) => {
this.insights.push(data);
}
onTopicResponseHandler = (data) => {
this.topics.push(data);
}
}
The class defines a constructor with separate arrays for messages (transcriptions), insights (which contains both questions and action items), and topics, as well as setting a default config.
It then has three methods (setConfig, sethandlers, and setInsightTypes) for updating the config object (based on the options chosen by the user) and then using that updated config to determine the handlers and insightTypes settings for the symblSdk.startRealtimeRequest call.
The remaining methods are the definitions for the handlers themselves (which essentially just push the returned data to the appropriate array) and methods for retrieving data from the arrays and filtering and/or mapping it as necessary in order for it to then be displayed in the relevant views.
There are some additional changes to the app, such as updates to the postSymblCall controller, postSymblProcessing controller, additional routes, route handlers and views, and some restructuring/ renaming of files, functions, etc. I won't go into detail on these changes, since they are primarily just to facilitate the extraction of much of the processing logic to the SymblProcessor class.
As a final note here, I just wanted to highlight one aspect of using the Audio Connector feature, which might determine how you implement an application which uses it.
The /connect endpoint of the Vonage Video API, which is used to start an Audio Connector WebSocket connection, gives you the option of passing a streams array as part of the request body, containing the IDs of the streams for which the audio should be sent to the WebSocket.
{
"sessionId": "Vonage Video API session ID",
"token": "A valid Vonage Video API token",
"websocket": {
"uri": "wss://service.com/ws-endpoint",
"streams": [
"streamId-1",
"streamId-2"
],
"headers": {
"headerKey": "headerValue"
},
"audioRate" : 8000
}
}If this streams property is omitted, then combined audio of all the streams in the session is sent.
Since the initial implementation of this app was focused on transcription, and I wanted specific pieces of transcribed audio to be attributed to individual identified speakers within the video call, the app was implemented by making multiple requests to this endpoint, each specifying a single stream, and defining a different web socket for each stream.
If, however, the requirements of your application didn't need you to attribute transcribed audio to individual identified speakers (say for example you wanted to collate questions raised on the call but didn't need to know who had asked the question), then it would probably make more sense to combine the audio and send it to a single web socket endpoint.
Hopefully, this article has given you some ideas about the kinds of features you can build using Audio Connector and maybe inspired you to go and build something awesome!
If you have any comments or questions or just want to share a project you built with Audio Connector, feel free to reach out to us in our Vonage Developer Slack.