
Video + AI: Live-Übersetzungen mit Audio Connector
Lesedauer: 4 Minuten
Stellen Sie sich vor, Sie führen ein Video-Gespräch mit Menschen aus der ganzen Welt, die ihre eigene Muttersprache sprechen, und jeder versteht den anderen. Der Ton des Sprechers wird in Text übersetzt, den die anderen Teilnehmer in ihrer eigenen Sprache lesen können. In diesem Blog-Beitrag werden wir erläutern, wie dies möglich ist. Eine der Hauptkomponenten ist die neue Funktion Audio Connector, die gerade veröffentlicht wurde.
Kurz gesagt, mit Audio-Anschlusskönnen die Audioströme Ihrer gerouteten Videoanrufsitzungen einzeln (A, B) oder kombiniert (A+B) an einen WebSocket-Server gesendet werden, insgesamt bis zu 50 Streams.
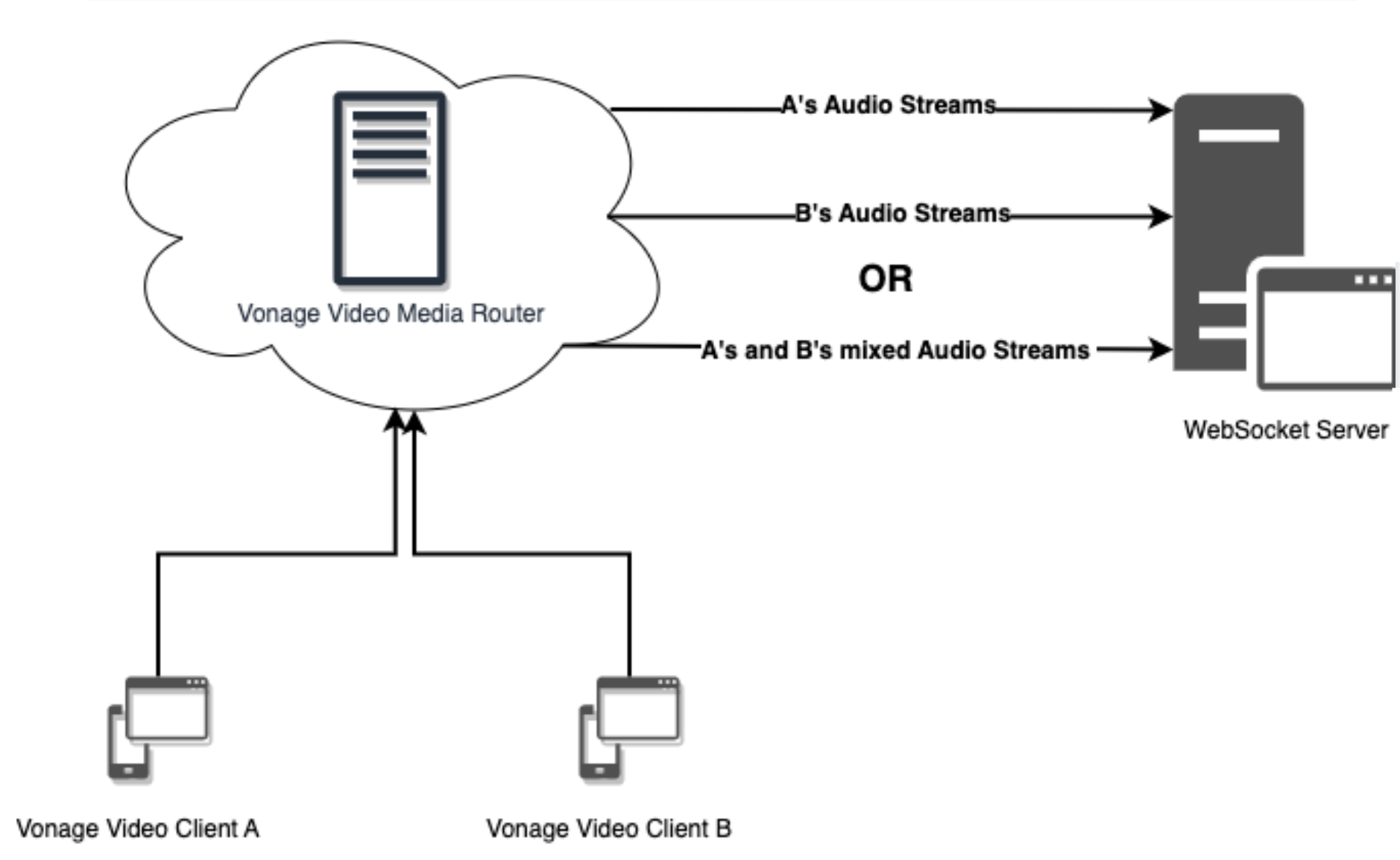 Audio Connector Diagram
Audio Connector Diagram
Es gibt kein Funktionskennzeichen oder einen Schalter, der aktiviert werden muss, um Audio Connector zu verwenden. Er ist standardmäßig aktiviert und wird nach der Anzahl der gesendeten Teilnehmer-Audiostreams berechnet. Alles, was wir tun müssen, ist einen WebSocket-Server zu erstellen, um die Audioströme zu empfangen.
Die Möglichkeit, Audioströme zu isolieren und zu analysieren, eröffnet eine Vielzahl neuer Möglichkeiten. Eine davon, die wir in diesem Blog-Beitrag besprechen, ist die Verwendung von künstlicher Intelligenz für Echtzeit-Übersetzungen mit Microsofts Azure AI Speech Service.
Wenn Sie den Code und eine Demo in Aktion sehen möchten, können Sie sich das GitHub-Repository für eine NodeJS-basierte Anwendung einsehen. Mit einem Klick auf die Schaltfläche "Bereitstellen" und der Eingabe einiger Anmeldedaten können Sie die Echtzeit-Live-Übersetzungen in einem Videoanruf erleben.
Wie bereits erwähnt, benötigen Sie einige Anmeldedaten, um die Demoanwendung auszuführen.
Sie finden den Vonage Video API Schlüssel und das Geheimnis im Dashboardentweder in einem früheren Projekt oder in einem neu erstellten Projekt.
 Vonage Project Credentials
Vonage Project Credentials
Auf der Microsoft-Seite müssen Sie eine Speech Services-Ressource im Azure-Portal. Nach der Erstellung benötigen Sie einen der Schlüssel (einer von beiden ist in Ordnung) und den Wert unter "Standort/Region".
 Microsoft Azure Project Credentials
Microsoft Azure Project Credentials
Wenn Sie diese Anmeldedaten zusammen mit der Domäne der laufenden Anwendung eingeben, können Sie Ihren Namen eingeben, die Sprachen auswählen, in denen Sie sprechen werden, und die Übersetzung lesen. Teilen Sie die URL und lassen Sie einen oder zwei Freunde an Ihrer Video-Sitzung teilnehmen.
In diesem Abschnitt beschreibe ich, was hinter den Kulissen der Demo-Anwendung geschieht. Um so code-agnostisch wie möglich zu sein, werde ich über Methoden im Allgemeinen sprechen und auf die Dokumentation verweisen, so dass Sie in der Lage sein werden, die Dinge in der Programmiersprache Ihrer Wahl zu implementieren. Ich habe meine Demo-Anwendung unter Verwendung von NodeJS.
Der Videoanruf ist ein einfacher, normaler Videoanruf, wie er in diesem Beispielprojekt oder einer, der mit unseren neuen Video-Webkomponenten. Der einzige Unterschied besteht darin, dass der Benutzer vor Beginn der Sitzung seinen Namen und die gewünschten Sprachen eingeben kann.
Sobald der Videoanruf stattfindet, bedeutet dies, dass Audio für den Audio Connector vorhanden ist, um mit dem Senden an einen WebSocket-Server zu beginnen. Wenn Sie nicht sicher sind, wie Sie einen WebSocket-Server erstellen, können Sie nach <your programming language> WebSocket server und hoffentlich werden viele Tutorials und Bibliotheken in den Suchergebnissen erscheinen. Wenn nicht, gibt es immer einen KI-Chatbot, den Sie fragen können. Haha
Um Ihre Audioströme an Ihren neu erstellten WebSocket-Server zu senden, bietet Vonage in den verschiedenen Server-SDKs eine Methode (Java, NodeJS, PHP, Python, Ruby, .NET), um eine WebSocket-Verbindung zu starten. Wenn Sie Ihre serverseitige Sprache nicht sehen, können Sie auch einen REST-Endpunkt.
Jetzt, da Ihr WebSocket-Server Audioströme empfängt, ist es an der Zeit, mit der Übersetzung zu beginnen. Microsofts Azure AI-Sprachdienst kann Audio aus mehr als 30 Sprachen übersetzen. Microsoft hat Speech Service SDKs für C++, C#, Go, Java, JavaScript/NodeJS, Objective-Cund Python.
Zuerst müssen Sie Ihre Sprachübersetzungskonfiguration mit Ihrem Schlüssel und Ihrer Region festlegen. In Ihrem Sprachen-SDK sollte es etwas ähnliches geben wie SpeechTranslationConfig mit einem fromSubscription in der Sie Ihre Anmeldedaten eingeben können. Wo Sie die Spracherkennung und die Zielsprachen einstellen, hängt davon ab, ob Sie einen kombinierten Stream oder mehrere einzelne Streams senden.
Auf Ihrem WebSocket-Server möchten Sie die vom Audio Connector gesendeten Daten sammeln, um sie mit künstlicher Intelligenz zu übersetzen. Dazu muss zumindest in NodeJS ein Push Stream für den Audio Input Stream erstellt werden. So funktioniert es.
Audio Connector sendet verschiedene Arten von WebSocket-Nachrichten:
Es gibt textbasierte Nachrichten, die die anfängliche Nachricht, Aktualisierungen, wenn ein Audiostream stummgeschaltet/freigegeben wird, und wenn die Verbindung getrennt wird, enthalten. Diese Nachrichten enthalten die Informationen zum Audioformat, Daten zum Status der Verbindung und alle benutzerdefinierten Kopfdaten, die Sie beim Erstellen der Verbindung gesendet haben.
Der andere Typ sind binäre Audionachrichten, die den Audiostrom darstellen. Diese wollen Sie dem Push-Stream hinzufügen, damit die künstliche Intelligenz sie übersetzen kann.
Um zwischen Text- und Audionachrichten zu unterscheiden, versuche ich, die Nachricht in JSON zu parsen. Wenn ich keinen Fehler erhalte, bedeutet dies, dass es sich um eine Textnachricht handelt. Wenn ich einen Fehler erhalte, bedeutet dies, dass es sich um eine binäre Audionachricht handelt, die dem Push-Stream hinzugefügt wird.
Da wir nun einen Audioeingangsstrom haben, der vom Push-Stream geliefert wird, müssen wir das Audio vom Stream-Eingang konfigurieren, damit das Speech SDK das Audio analysieren und übersetzen kann. Um mit dem "Verstehen" des Streams zu beginnen, wird ein Übersetzungserkenner unter Verwendung der Audio- und Sprachübersetzungskonfigurationen erstellt. Der Übersetzungserkenner wird dann gestartet, um kontinuierlich zu versuchen, zu erkennen, was im Audiostrom gesagt wird.
Während die Übersetzungserkennung versucht herauszufinden, was gesagt wird, werden Teilübersetzungen abgefeuert. Sobald der Übersetzungserkenner glaubt, den Satz vollständig verstanden zu haben, wird eine endgültige Übersetzung präsentiert.
Die fertigen Übersetzungen werden dann in die Videositzung über die Vonage Video Signal-Funktion auf den Bildschirmen der Teilnehmer angezeigt werden.
Ich dachte, es wäre eine coole Funktion, die Möglichkeit hinzuzufügen, alle Teilnehmer des Videoanrufs stumm zu schalten und den Browser den übersetzten Text mit einer synthetischen Stimme vorlesen zu lassen. Wenn Sie es ausprobieren, lassen Sie uns wissen, wie es läuft in der Entwickler-Community Slack oder auf X, früher bekannt als Twitter. @VonageDev.