
Teilen Sie:
Mark hat über 4 Jahre lang Demos entwickelt, POCs implementiert und ahnungslosen Kollegen bei Vonage seinen Humor aufgedrückt. Er programmiert seit 1979 professionell und seine technische Erfahrung reicht von FORTRAN auf Lochkarten bis hin zu React Native in der Cloud. Seine Kreativität und Begeisterung für die Entwicklung und den Austausch von Technologielösungen wird nur noch von seiner Vorliebe für Dad-Witze übertroffen.
Demo zur Sprechertagebuchführung mit Vonage Video und Deepgram
Lesedauer: 5 Minuten
Viele Arbeitnehmer auf der ganzen Welt sind wieder im Büro, aber die Nutzung von Videokonferenzsystemen nimmt nicht ab! Die meisten heute auf dem Markt befindlichen Systeme sind für einen Sprecher pro Videostream ausgelegt, was zu einem Chaos in den von mehreren Sprechern gemeinsam genutzten Büroraumsystemen führt. Stellen Sie sich vor, Sie lesen die Niederschrift eines Austauschs zwischen drei Personen, ohne dass die verschiedenen Sprecher identifiziert werden können. Das kann ziemlich verwirrend werden.
Um diese Komplexität zu bewältigen, setzen Konferenzsysteme zunehmend auf Funktionen der künstlichen Intelligenz. Die neueste Generation von Technologien geht über einfache Untertitel und Übersetzungen hinaus und nutzt die Leistung von KI, um die Komplexität von Raumsystemen und hybriden Videoszenarien zu verwalten.
Zu wissen, wer was zu wem gesagt hat, ist wichtig, um einem Gespräch einen Sinn zu geben und um Sitzungsnotizen und -abschriften einen Mehrwert zu verleihen. Die Identifizierung von Sprechern geht über das Verstehen von Gesprächen hinaus und ermöglicht einen Mehrwert wie Sitzungsnotizen und -abschriften. Aus einer einzigen Audioquelle herauszufinden, wer spricht, ist eine Aufgabe, an die sich Menschen speziell angepasst haben, die aber für Maschinen eine komplexe Herausforderung darstellt. Dieser Prozess wird als Diarisierung der Sprecher.
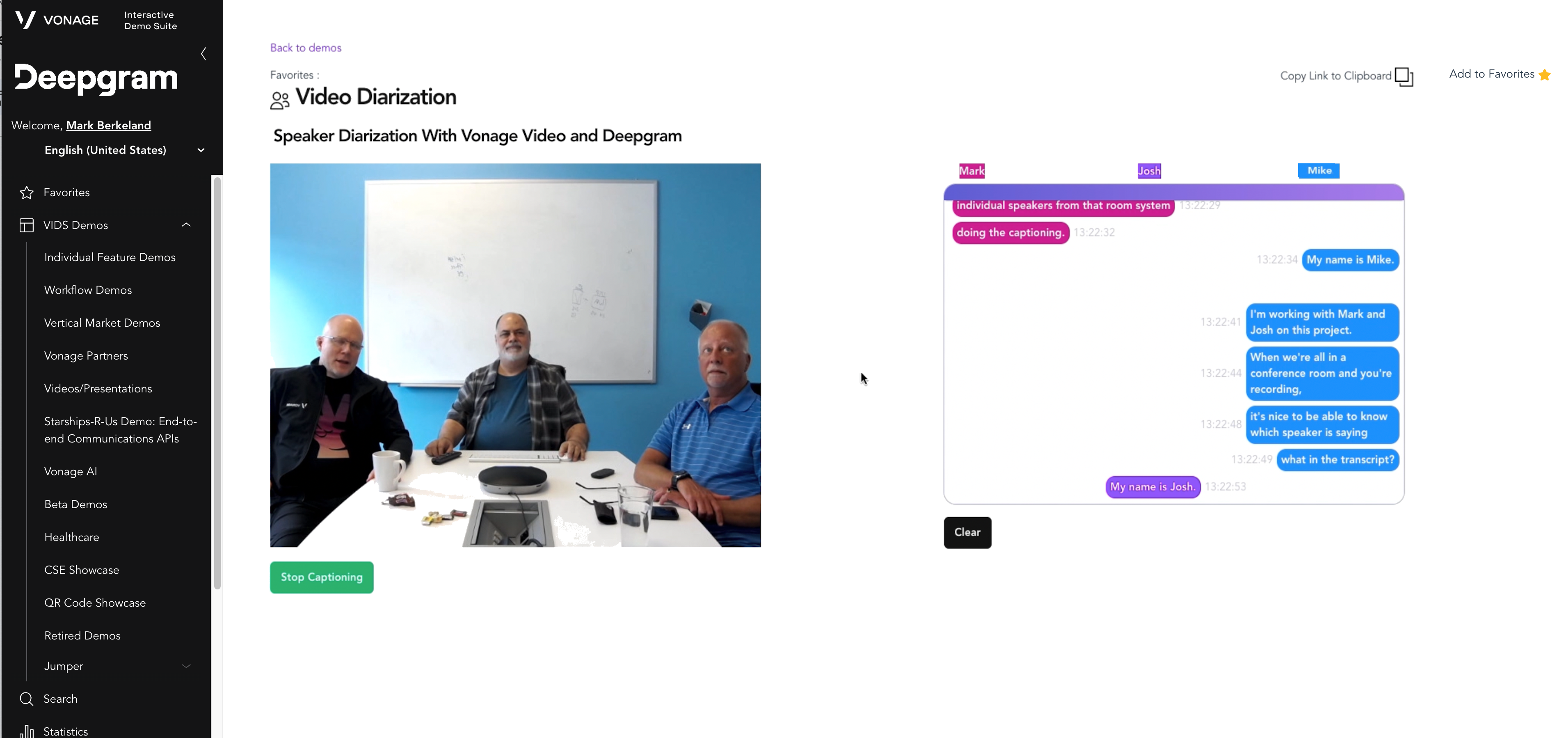
In diesem Blog zeigen wir Ihnen, wie wir ein Videokonferenzsystem für Raumsysteme mit mehreren Sprechern und Diarisierung aufgebaut haben.
Unten sehen Sie ein Video von dieser Demo in Aktion!
Um diese Lösung umzusetzen, mussten wir sicherstellen, dass:
Das Videokonferenzsystem verfügte über einen sicheren Zugang zu Rohdaten auf dem Server um die schnellsten Verarbeitungszeiten zu gewährleisten, sowie auf die Aufzeichnung von SIP-Geräten für alle Teilnehmer, die sich einwählen.
Der automatische Spracherkennungsdienst (ASR) könnte die einzelnen Sprecher in einem Audiostrom trennen, so dass die Äußerungen der einzelnen Sprecher eindeutig identifiziert werden.
Die Erlangung dieser Fähigkeiten war entscheidend, um das volle Potenzial von Konferenzsystemen für Raumsysteme und hybride Anwendungsfälle zu erschließen und eine nützliche und benutzerfreundliche Videoanwendung zu erstellen (siehe unten):
 vonage_video_api_diarization_demo.png
vonage_video_api_diarization_demo.png
Was ist eine Sprechertagebuchführung?
Bei der Sprechertagung wird ein Audiostrom in Segmente unterteilt, die der Identität des Sprechers entsprechen, unabhängig vom Kanal. Die Diarisierung von Sprechern wird im Allgemeinen in vier große Teilaufgaben aufgeteilt:
Erkennung - Finden Sie Audioregionen, die Sprache im Gegensatz zu Stille oder Rauschen enthalten.
Segmentierung - Die erkannten Regionen werden in kleinere Audioabschnitte unterteilt und getrennt.
Darstellung - Verwenden Sie einen diskriminierenden Vektor zur Darstellung dieser Segmente.
Zuschreibung - Fügen Sie jedem Segment auf der Grundlage seiner diskriminativen Repräsentation eine Sprecherbezeichnung hinzu.
Die verschiedenen ASR-Anbieter bieten unterschiedliche Diarisierungsfunktionen an. Unser Partner Deepgram hat einen der robustesten Funktionssätze implementiert, die wir auf dem Markt gesehen haben, mit mehr als einem Dutzend Sprachen und ohne Begrenzung der Anzahl der aktiven Sprecher. Sie können mehr über diese Lösung erfahren hier.
Erfahren Sie mehr über Sprechertagebuchführung in diesem Deepgram (https://blog.deepgram.com/what-is-speaker-diarization/)
Damit die Spracherkennung effizient arbeiten kann, muss der Zugriff auf die rohen Audioströme direkt vom Medienrouter erfolgen. Dies bietet die Vorteile einer nativen Unterstützung für alle Geräte, verbraucht einen Bruchteil der Bandbreite einer clientseitigen Lösung und kann mit Firewallsystemen funktionieren. Mit dem Vonage Video API Audio Connector können wir rohe Audioströme aus unseren Live-Videositzungen extrahieren und an Deepgram senden, um die Audioströme in Echtzeit (und auch offline) zu verarbeiten. Weitere Informationen über den Audio Connector finden Sie finden Sie hier.
Bei der Erstellung unserer Demo ging es uns darum, die Echtzeit-Tagebuchführung eines Raumsystems zu zeigen, indem wir die Video API von Vonage zur Erstellung der Videositzung und Deepgram zur Transkription der Sprache verwenden.
Aus Gründen der Klarheit haben wir keine weiteren Personen berücksichtigt, die der Konferenz beitreten, obwohl diese Lösung durchaus mit diesem Fall umgehen kann (ebenso wie mit mehreren gleichzeitigen Raumsystemen). Der Audio Connector wird gestartet, wenn wir einen neuen Herausgeber hinzufügen (der in diesem Fall ein Raumsystem ist). Die Einrichtung des AudioConnectors ist eigentlich recht einfach, da wir die StreamID für den Publisher bereits kennen (sie wird uns von der Front-End-App übermittelt). Obwohl der AudioConnector "alle" oder "eine Liste von Streams" verarbeiten kann, verwenden wir in unserem Fall nur den einen Stream, der mit dem Raumsystem verbunden ist. Beachten Sie, dass es sich dabei sogar um ein herkömmliches SIP-Raumkonferenzsystem handeln KÖNNTE.
Für die Erstellung dieser Demo benötigten wir eine Vonage Video API und einen Deepgram Account. Sie können Ihre kostenlosen Accounts erstellen hier für Vonage Video API und hier für Deepgram.
Nach der Erstellung unserer Opentok-Instanz ("opentok") und der Erstellung einer Sitzung für die Videokonferenz ("sessionId") zusammen mit einem zugehörigen Autorisierungs-Token ("token") informiert uns die Anwendung über den Stream des Raumsystems ("streamId"). Dann muss dieser Stream nur noch mit der URL eines wartenden Websockets ("url") verknüpft werden:
opentok.websocketConnect(sessionId, token, url, {
streams: [streamId],
headers: {
sessionid: sessionId,
streamId: streamId
},
audioRate: 16000,
}, function(error, socket) {
if (error) {
console.log('Error:', error.message);
} else {
console.log('OpenTok Socket websocket connected');
}
});Der Websocket wartet auf eingehende Verbindungen, und da wir die sessionId und streamId in den Headern übergeben, können wir genau wissen, welchen Stream wir transkribieren und diarisieren werden:
app.ws('/socket', async (ws, req) => {
…
ws.on('message', (msg) => {
try {
if (typeof msg === 'string') {
let config = JSON.parse(msg);
console.log("Socket string message: ", config);
// Do whatever we need here…
// the sessionId and streamId are contained in the msg!
} else {
Wo die "msg" ankommt als:
Socket string message: {
'content-type': 'audio/l16;rate=16000',
event: 'websocket:connected',
sessionid: '1_MX40NjQyMzI5Mn5-MTY4NjA5MDM1MTkwNX5yUVlkZmp0bE9jMk5rQTAyVxxxxxxxxx-xx',
streamId: '553236ce-xxxx-xxxx-8cb4-9dd17b3119dc'
}Wir können nun unseren eingehenden Audiostrom direkt in das Streaming-Modell von Deepgram einbinden. Wenn wir sehen, dass der Audio Connector Websocket eine Verbindung herstellt, weisen wir Deepgram an, einen Websocket zu öffnen. Für unsere Demo haben wir festgestellt, dass die Verwendung des "phonecall"-Modells in der "enhanced"-Ebene wirklich gute Ergebnisse liefert, und wir haben das Standard-Audio-Connector-Format von "16000" für die Abtastrate und "linear16" für das Audioformat verwendet. Klicken Sie hier für Informationen zu den Deepgram-Funktionen und -Optionen. Außerdem (und das ist hier der springende Punkt) weisen wir Deepgram an, die Diarisierung zu verwenden ("diarize: true"):
const deepgramLive = deepgram.transcription.live({
punctuate: true,
model: 'phonecall',
tier: 'enhanced',
language: “en - US”,
,
diarize: true,
encoding: 'linear16',
sample_rate: 16000,
endpointing: 10,
});Wir können dann diese Deepgram-Verbindung nutzen, um nach Transkriptionsergebnissen zu suchen (mehr dazu später), indem wir einen "Listener" einrichten:
deepgramLive.addListener('transcriptReceived', async (transcription) => {
Ok, unsere Rohrleitungen sind nun alle vorbereitet... Zeit, den Hahn aufzudrehen!
Im Audio-Connector-Websocket stellen wir jedes Mal, wenn wir ein Audiopaket von unserem Raumsystem erhalten (mit anderen Worten, wenn der Nachrichtentyp "binär" ist), zunächst sicher, dass Deepgram bereit ist, Daten zu empfangen:
if ((deepgramLive.getReadyState() === 1)) {
Und wenn das der Fall ist, geben wir die Daten einfach so weiter, wie sie sind!
deepgramLive.send(msg);
Sobald Deepgram genügend Daten hat, um die Beschriftung zu erstellen, ruft es uns über den oben erwähnten "Hörer" zurück. Deepgram liefert uns eine ganze Reihe von Informationen über das transkribierte Audiomaterial (ich empfehle dringend einen Blick in ihre ausgezeichnete Dokumentation um ein gutes Gefühl für die Fülle der bereitgestellten Informationen zu bekommen), aber der Teil, den wir für unsere Raumsystem-Diarisierung am meisten brauchen, ist die Reihe der "Wörter" (genauer gesagt, die "punctuated_word "s, da wir Deepgram gebeten haben, jeden Satz für uns zu interpunktieren). Die Deepgram-Tagebuchaufzeichnung funktioniert auf Wortbasis und kann auch bei sich überschneidenden Sprechern differenzieren, also wollen wir uns jedes WORT ansehen und es nach Personen aufschlüsseln. Wir erstellen ein Array, in dem jeder Eintrag "das, was dieser bestimmte Sprecher gesagt hat" ist, und gehen dann die Wörter durch, wobei wir sie nach Sprechern aufschlüsseln und neu zusammensetzen:
let words = transcription.channel.alternatives[0].words
let message = [];
words.forEach(function each(word) {
if (word.speaker in message) {
message[word.speaker] += " " + word.punctuated_word
} else {
message[word.speaker] = word.punctuated_word
}
});Wir haben jetzt message[0] mit dem, was der erste Redner gesagt hat, message[1] mit dem, was der zweite Redner gesagt hat, usw.
Und das war's! Wir können diese Meldungen an die grafische Benutzeroberfläche zurücksenden, die sie dann entsprechend anzeigt.
Jetzt haben wir ein Raumsystem, das Besprechungsnotizen aufnimmt und mit mehreren Sprechern umgehen kann, auch wenn sie sich im selben Raum befinden!
Klicken Sie hier um ein Video von dieser Demo in Aktion zu sehen!
Sie können auch eine persönliche Demo anfordern von einem unserer Experten anfordern. Wenn Sie Fragen oder Anregungen haben, können Sie uns auf dem Vonage Entwickler-Slack oder senden Sie uns einen Tweet auf Twitter.
Teilen Sie:
Mark hat über 4 Jahre lang Demos entwickelt, POCs implementiert und ahnungslosen Kollegen bei Vonage seinen Humor aufgedrückt. Er programmiert seit 1979 professionell und seine technische Erfahrung reicht von FORTRAN auf Lochkarten bis hin zu React Native in der Cloud. Seine Kreativität und Begeisterung für die Entwicklung und den Austausch von Technologielösungen wird nur noch von seiner Vorliebe für Dad-Witze übertroffen.