
The Return of SQLite
OK, I’ll admit it; it’s not a return. Let’s call it more of a reimagining. SQLite has been around since the year 2000, and its original intended use was for missile tracking aboard United States Navy destroyers. It’s certainly proved its credentials as a relational database system, although the past 10 years have seen the rise of NoSQL, document-oriented database systems, which might have somewhat taken the limelight away from it. In this article, I’ll explore SQLite’s overlooked potential and demonstrate just how quick it is to spin up with production-grade architecture in mind.OK, I’ll admit it; it’s not a return. Let’s call it more of a reimagining. SQLite has been around since 2000. While the past decade has seen the rise of NoSQL and document-oriented databases that have taken much of the spotlight, SQLite remains a powerful option. Originally developed for missile tracking on United States Navy destroyers, it has quietly proven itself as a reliable relational database. Chances are, you're overlooking its potential in production-grade architecture. In this article, I'll show you just how fast and easy it is to get SQLite up and running.
>> TL;DR: You can find the full source code on GitHub.
Quite the introduction then, but what do software engineers, specifically web application developers, know SQlite as? Well, it mostly has two reputations:
I need to run my tests and don’t want to spin up a full Postgres server, so why not just use this little useful file thing to run it?
It’s for embedded systems because it’s small, right? But that’s no use for my web application, which will generate mountains of data.
There’s no arguing with point number one; SQLite is incredibly useful for testing. You have, say, your existing architecture in code: migrations, seeders, and the like. So, when you run your test suite, instead of using a database server that is SQL-compatible, such as MySQL, MariaDB, or Postgres, you run all the same code but with a blank SQLite file. Great. But what about point 2?
 Just one file: portability at its finestYes, it’s small. Even better, connectivity is simple: it’s just a file.
Just one file: portability at its finestYes, it’s small. Even better, connectivity is simple: it’s just a file.
There’s a whole host of IDE plugins and compatibility - Jetbrains’ IDEs have a database panel that can create a new SQLite file, and VSCode has plenty of plugins to also handle this for you. I mean, for the real heavy developers, you can create it directly from Vim.
The footprint out of the box is a mere 699kb. That’s it. No service to run, no background processes—just a file.
This is vastly different to the resources required to spin up a fully MySQL server.
Now, we get to the question most people want to ask: If it’s this simple, why don’t we use SQLite in more web applications?
The answer usually comes down to assumptions. Server-based relational databases dominate, but with a little consideration, you might realize that SQLite is a perfect fit for our actual requirements.
Read and write speed is one of the biggest differences. SQLite, for a medium database of a couple of million rows, is incredibly fast. Benchmarks vary, but solo queries take up to 5ms, in comparison to a maximum average of around 10ms for MySQL.
However, if SQLite killed it on all benchmarks, clearly we’d be using it for everything when it’s not that prevalent in web application development. Firstly, the write speed is a lot slower. SQLite can write approximately up to 300 inserts on a single thread, compared to up to 50k in MySQL (depending on the environment). That’s a big difference.
The second thing to note is that SQLite has a single-thread locking mechanism; records that are being read or written/updated have five possible write states. When writing, a record’s lock state is changed to EXCLUSIVE, which restricts any other concurrent actions. MySQL, however, uses MVCC, or Multi-Version Concurrency control, which will allow for many concurrent reads and writes.
One of the questions I constantly try to remind people of is What is your use case? In the world of cloud-native and Kubernetes, many argue that“PHP being slow” is because “Node has an event loop”, but what I urge people to think about is “what is your application going to realistically do?If you’re going to be storing some user data or uploading some CSVs and images, are you really going to see the difference between the choice of language and framework? In many cases, probably not. This is also the same with SQLite vs. MySQL: SQLite is still a fantastic choice if you have some data, but more importantly, are you going to have 20,000 users writing to the database in your app? If you’re writing the next iteration of a global taxi application, then sure. What I’m saying here is that SQLite is far better suited to a lot of development cases than many realise.
WebStorm IDE and basic knowledge of using it
Basic knowledge on how to use an HTTP testing client, such as HTTPie or Insomnia
To complete this tutorial, you will need a Vonage API account. If you don’t have one already, you can sign up today and start building with free credit. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard.

Enough talk, it’s time to show how few lines of code we can write to demonstrate a production-level SQLite write with Typescript. We’re going to expose an application that will be able to read webhooks generated by the Vonage Messages API. Firstly, make a new directory for your project, navigate into it, and create a new Node project.
npm init --yesThis will use the default values for your package.json that is created. Next, we need to install TypeScript:
npm install typescript
npx tsc --initTypescript compiles into plain JavaScript and uses a configuration file tsconfig.json, which is created on installation. Open this config, and replace the boilerplate with the following:
{
"compilerOptions": {
"target": "es2016",
"module": "CommonJS",
"rootDir": "./",
"outDir": "./dist",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true,
"moduleResolution": "node",
"baseUrl": ".",
"paths": {
"@prisma/client":["node_modules/@prisma/client"]
}
},
"include": ["src/**/*.ts"]
}Important parts of this config to note are:
TypeScript will compile to a directory that will be created if it does not exist, named
dist. This will be the entry point to your application.You’ll notice that Prisma is in the
pathskey. This is because, when we install Prisma, it also needs to be compiled (in a way). When we define models within Prisma, it then uses a generate command to create a bespoke Prisma client.
We have six dependencies:
Prisma: our object relational mapper
ts-node: enables us to run TypeScript without compiling to the output directory
nodemon: for our development server, code is reloaded when changed
dotenv: for handling environment variables)
Express: our router
Sqlite: for our database connection
You can install these all in one hit on the command line:
npm install prisma ts-node nodemon dotenv express @types/express sqlite3Prisma is an ORM that can handle your data models, migration, and all other queries. To set up your Prisma directory, we need to run the init command for it:
npx prisma init --datasource-provider sqlite --output ../generated/prismaThis command will configure Prisma to output a compiled Client class into the ../generated/prisma directory, and tells it that SQLite is our database source. When running this command, Prisma will ask you for any extra required dependencies, and then sets up your .env file. We’ll configure this file later.
As SQLite is a file handled by a library, you can create it with most modern IDEs that have driver support. Now open your project in Webstorm. Then click on the Database icon on the right-hand panel. Then click the “+” button to create a new database. Select Data Source and scroll down until you see SQLite. This gives you your modal for creating a new database:
 Jetbrains Supports A Massive List of DBsChoose SQLite as your type, and you will get the creation pop-up:
Jetbrains Supports A Massive List of DBsChoose SQLite as your type, and you will get the creation pop-up:
 Create Your DatabaseThe first time you do this, if you haven’t used WebStorm before, the IDE will detect that you do not have the SQlite drivers installed as a warning rendered in place of where the
Create Your DatabaseThe first time you do this, if you haven’t used WebStorm before, the IDE will detect that you do not have the SQlite drivers installed as a warning rendered in place of where the Test Connection option is. If you don’t have the drivers, click the link to install them.
In the Name field, change identifier.sqlite to webhooks, and the filename to webhooks.sqlite. You want the file to be located in your project root, so hit the dots to the right of the file field to ensure the location is correct. Then click ok.
Your Prisma client is configured in prisma/schema.prisma, but it pulls in the DATABASE_URL env var from your .env file. Open your env, and replace it like so:
DATABASE_URL="file:../webhooks.sqlite"Prisma is configured out of the box to generate the bespoke ORM client in the node_modules directory. We don’t want it to be generated in the @prisma directory so in the schema.prisma file, replace the client settings like so, below the datasource:
generator client {
provider = "prisma-client-js"
output = "../node_modules/.prisma/client"
}What this does is tell Prisma to put the generated client into a new directory, .prisma. Later on, when creating a record in Express, we will tell Prisma where to import the client from.
We need to create a model that a migration will then run. What I did here was a neat little hack - Prisma needs you to type out all of your database models manually. Well, we’re consuming a Vonage Messages API webhook, so what if I navigated to the webhook reference in the OpenAPI spec, copied the example JSON, and then got AI to write me the model? That’s exactly what I did.
 Auto-generated AI code from OpenAPI specsI’ll save you the legwork, you can copy the following models into your
Auto-generated AI code from OpenAPI specsI’ll save you the legwork, you can copy the following models into your schema.prisma belowthe datasource and client:
model WebhookEvent {
id String @id @default(uuid())
channel String
messageUuid String @unique
to String
from String
timestamp DateTime
contextStatus String
messageType String
location Location?
createdAt DateTime @default(now())
}
model Location {
id String @id @default(uuid())
webhookId String @unique
lat Float
long Float
webhook WebhookEvent @relation(fields: [webhookId], references: [id], onDelete: Cascade)
}Now you can run the migration, and it will generate tables in the database for these models.
npx prisma migrate dev --name webhooksPrisma has now created the migration for you, which serves as a record of every change made to the database. Want to rename a field? Yep, new migration, committed to the source code. You now have a total record of how to get your application database into the correct state, in code.
Your final task is to create the Express app that will consume the webhook. Create a new directory in your project root named src and create a new TypeScript file named index.ts. It looks like this:
import express, { Express, Request, Response } from "express";
import dotenv from 'dotenv';
import { PrismaClient } from ".prisma/client"
dotenv.config();
const app: Express = express();
const port = process.env.PORT;
const prisma = new PrismaClient();
app.use(express.json())
app.get('/', (req: Request, res: Response) => {
res.send('Express + TypeScript Server');
});
app.post('/webhook', async (req, res) => {
try {
const { channel, message_uuid, to, from, timestamp, context_status, message_type, location } = req.body
// Save the webhook data in the database
const webhook = await prisma.webhookEvent.create({
data: {
channel,
messageUuid: message_uuid,
to,
from,
timestamp: new Date(timestamp),
contextStatus: context_status,
messageType: message_type,
location: location ? {
create: {
lat: location.lat,
long: location.long
}
} : undefined
},
include: { location: true } // Optional: Include related location in the response
})
console.log('Webhook saved:', webhook)
res.status(201).json({ message: 'Webhook saved successfully', webhook })
} catch (error) {
console.error('Error saving webhook:', error)
res.status(500).json({ error: 'Internal server error' })
}
})
app.listen(port, () => {
console.log(`[server]: Server is running at http://localhost:${port}`);
});There’s quite a bit to unpack here, so let’s go through line by line:
import { PrismaClient } from ".prisma/client"makes sure that you import from the .prisma directory.app.use(express.json())is to make sure that Express knows it needs to handle JSON.app.post(‘/webook’) defines a new
POSTendpoint to which Vonage will be sending data.The
constdefined in the webhook closure extracts all the fields you need to immutable variables, which will be written to the databaseFinally,
prisma.webhookEvent.create()is called, which then writes the incoming data to your SQLite database.
You will need the ability to rebuild your Prisma client via the command line, plus the options added for the TypeScript compiled to work. In the scripts section of your package.json file, change it to the following:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "npm run prisma:generate && npx tsc",
"start": "node dist/src/index.js",
"dev": "nodemon --exec ts-node src/index.ts",
"prisma:generate": "prisma generate"
}To run your application here, first build the app into the dist directory and then l fire up the Express app, after you have regenerated Prisma and called the TypeScript compiler.
npm run buildnpm run startYou might have noticed that I have also added the command npm run dev which will run the TypeScript compiler and nodemon, which will do a dev build each time a file changes.
The last part is sending the data itself. To do this, firstly, we’ll need to expose our local application to the internet by using ngrok. To do so, open a new tab in your terminal and run:
ngrok http 3000Learn more about ngrok.
Once ngrok has opened up your ports, you should now have a public URL. This is now going to be configured in Vonage.
To create an application, go to the Create an Application page on the Vonage Dashboard, and define a Name for your Application.
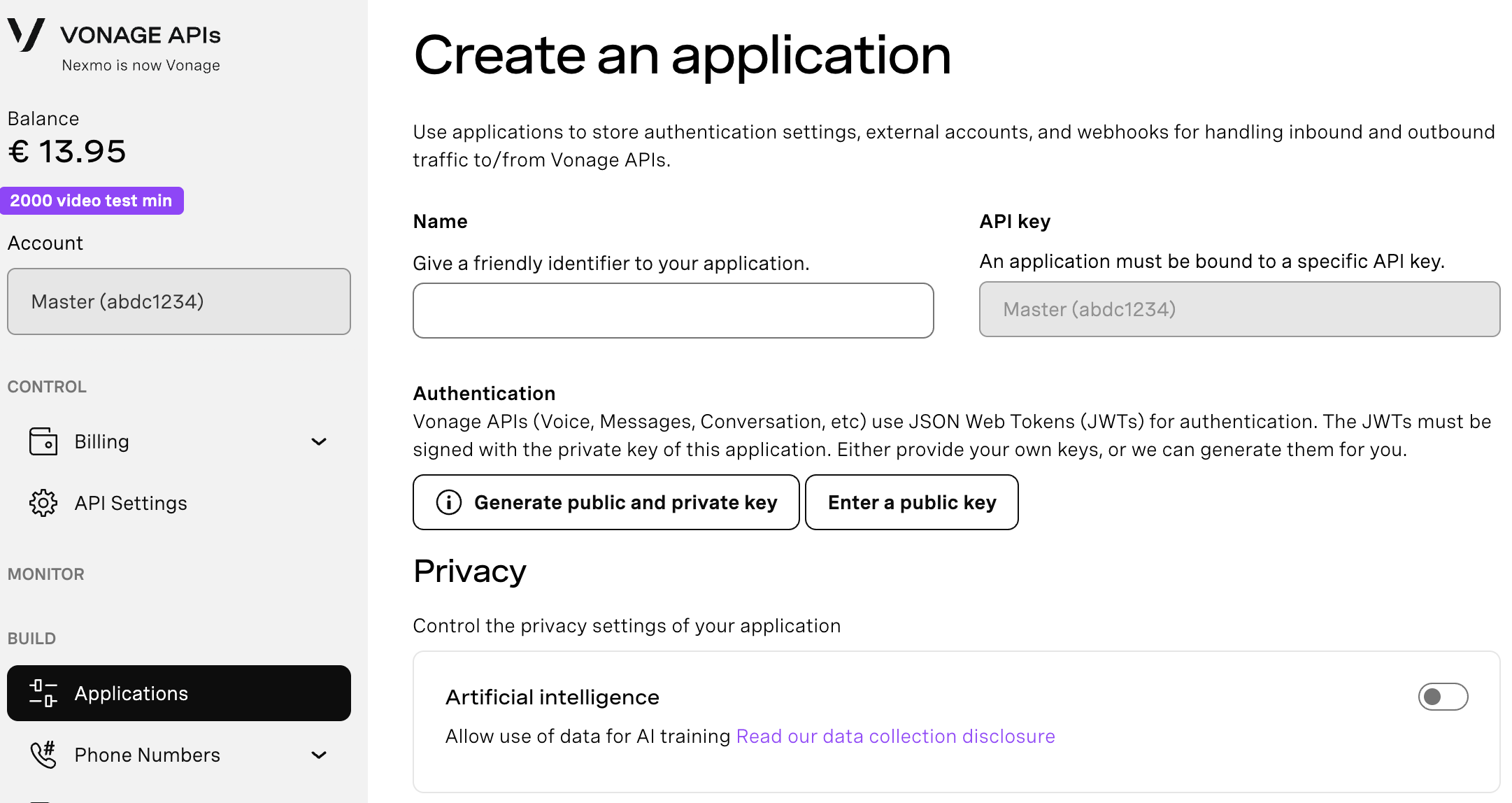
If needed, click on "generate public and private key". A private key (.key file) will be generated. Download and store it securely. This key is needed for authentication when making API requests. Note: Private keys will not work unless the application is saved.
Choose the capabilities you need (e.g., Voice, Messages, RTC, etc.) and provide the required webhooks (e.g., event URLs, answer URLs, or inbound message URLs). These will be described in the tutorial.
To save and deploy, click "Generate new application" to finalize the setup. Your application is now ready to use with Vonage APIs.
The public and private keys and any other option here aren’t really important as we aren’t doing a full integration, just generating some data. What is important is that you paste your Ngrok-generated URL into both of these inbound options, followed by /webhook as this is the route that has been created in Express. Go ahead and create the application, the messages capability should look like this:
 Configuring your Vonage Application WebhooksAny replies to the number attached to this application will now be forwarded via. Webhook to the URL you have put in here for the Inbound URL.
Configuring your Vonage Application WebhooksAny replies to the number attached to this application will now be forwarded via. Webhook to the URL you have put in here for the Inbound URL.
To buy a virtual phone number, go to your API dashboard and follow the steps shown below.
 Purchase a phone number
Purchase a phone number
Go to your API dashboard
Navigate to BUILD & MANAGE > Numbers > Buy Numbers.
Choose the attributes needed and then click Search
Click the Buy button next to the number you want and validate your purchase
To confirm you have purchased the virtual number, go to the left-hand navigation menu, under BUILD & MANAGE, click Numbers, then Your Numbers
Our configuration is now complete: send a message to the number you purchased, and all of the wiring will happen to write in the event and incoming message straight to your new SQLite database. Here I’ve used a favourite tool of mine, HTTPie, to test sending the webhook:
 Successful Persistence WinsThrough the PHPStorm Database Panel, open up the webhooks table, and we see the record has been persisted correctly:
Successful Persistence WinsThrough the PHPStorm Database Panel, open up the webhooks table, and we see the record has been persisted correctly:
 Database Query View in WebStorm
Database Query View in WebStorm
This demo shows the power of SQLite: we didn’t do a whole lot to get this code to persist incoming data. No Docker, no cloud spinups of Relational systems. This introduction serves as a pointer to where SQLite could well come in handy: smaller volumes of log files on rotation, smaller batches of human rather than machine-generated data, and session data. Think of it as a speedy setup akin to Redis when concurrency and traffic aren’t such a concern. But, as with all things, remember the engineers’ motto: It Depends®.
Got any questions or comments? Join our thriving Developer Community on Slack, follow us on X (formerly Twitter), or subscribe to our Developer Newsletter. Stay connected, share your progress, and keep up with the latest developer news, tips, and events!


