
シェア:
アクサ・マンサードのテクノロジー・ビジネスアナリスト。データサイエンス、アナリティクス、プロダクトリサーチ、テクニカルライティングの経験を持つ。データ収集、探索、変換/整理、モデリング、実用的なビジネス洞察の導出など、エンドツーエンドのデータ分析プロジェクトに従事し、ナレッジリーダーシップを発揮。
Pythonの機械学習によるSMSスパム検出
この記事は2025年4月に更新されました。
このチュートリアルでは、SMSスパム検出Webアプリケーションを構築します。このアプリケーションは、Flaskフレームワークを使用してPythonで構築され、SMSスパムを検出するために学習させる機械学習モデルを含みます。私たちは Vonage SMS API と連携し、Vonage アカウントに登録した電話番号に送信された SMS メッセージを分類できるようにします。
バーチャル電話番号を購入するには APIダッシュボードにアクセスし、以下の手順に従ってください。
 Purchase a phone number
Purchase a phone number
あなたの APIダッシュボード
BUILD & MANAGE > Numbers > Buy Numbersを開きます。
必要な属性を選択し、検索をクリックします。
ご希望の番号の横にある購入ボタンをクリックし、購入を確定する。
バーチャルナンバーを購入したことを確認するには、左側のナビゲーションメニューの「BUILD & MANAGE」から「Numbers」、「Your Numbers」の順にクリックします。
このプロジェクトのファイル・ディレクトリの概要を以下に示す:
├── README.md
├── dataset
│ └── spam.csv
├── env
│ ├── bin
│ ├── etc
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
├── model
│ ├── spam_model.pkl
│ └── tfidf_model.pkl
├── notebook
│ └── project_notebook.ipynb
├── requirements.txt
├── script
└── web_app
├── app.py
├── static
└── templatesこのチュートリアルのステップを通じて、上記のディレクトリ・ツリーにすべてのファイルを作成します。
このプロジェクト特有の様々なPython依存のために、隔離された環境を作る必要がある。
まず、新しい開発フォルダを作成します。ターミナルで
次に、新しいPython仮想環境を作成する。もし アナコンダを使用している場合は、以下のコマンドを実行できます:
そして、この環境を有効にする:
Pythonの標準ディストリビューションを使用している場合は、以下のコマンドを実行して新しい仮想環境を作成してください:
MacまたはLinuxコンピュータで新しい環境を有効にするには、以下を実行する:
Windowsコンピュータを使用している場合は、以下の手順で環境をアクティブにします:
仮想環境の作成とアクティベーションに使った方法にかかわらず、プロンプトは以下のように変更されているはずだ:
次に、このチュートリアルに必要なパッケージをすべてインストールします。新しい環境に、以下のパッケージ(ライブラリーと依存関係を含む)をインストールします:
注:再現可能なデータ・サイエンス・プロジェクトを作成するには、ここに掲載したバージョンにこだわること。これらはこの記事を書いている時点の最新版である。
これらのパッケージの詳細は以下の通り:
ジュピターラボはモデル構築とデータ探索のためのものだ。
フラスコはアプリケーション・サーバーとページを作るためのものだ。
lightgbmは、我々のモデルを構築するための機械学習アルゴリズムである
ネクスモはVonageアカウントとやりとりするためのPythonライブラリです。
matplotlib, plotly, plotly-expressはデータ可視化用
python-dotenvは API キーやその他の設定値のような環境変数を管理するためのパッケージです。
nltkは自然言語操作用
numpyは配列計算用
パンダは構造化データを操作し、扱うためのものだ。
正規表現は正規表現操作
scikit-learnは機械学習ツールキットである
ワードクラウドは、テキストからワードクラウド画像を作成するために使用される
インストール後、Jupyterラボを起動してください:
これにより、人気のあるJupyterラボのインターフェイスがウェブブラウザで開き、インタラクティブなデータ探索とモデル構築を行うことができる。
Jupyterラボのインターフェイスを以下に示す。 Jupyterlab.
環境の準備ができたので、SMSのトレーニング・データをダウンロードし、SMSメッセージを分類する簡単な機械学習モデルを構築します。このプロジェクトのスパムデータセットは、以下からダウンロードできます ここから.このデータセットには、スパムとハム(正規)のそれぞれのラベルを持つ5574通のメッセージが含まれています。データセットの詳細は こちら.このデータを使って、SMSをスパムかスパムであるかを正しく分類できる機械学習モデルを学習します。これらの手順は、Jupyterノートブック(ファイル・ディレクトリの名前は'project_notebok')で行う。
ここでは、さまざまなテクニックを駆使してデータを分析し、その理解を深めていく。
このプロジェクトに必要なライブラリは、以下のように project_notebook.ipynbにインポートできる:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly_express as px
import wordcloud
import nltk
import warnings
warnings.filterwarnings('ignore')という名前のデータセット・ディレクトリにあるスパム・データセットは、次のようにしてインポートできる。 spam.csvディレクトリにあるスパムデータセットは次のようにインポートできる:
df = pd.read_csv("../dataset/spam.csv", encoding='latin-1')注意:このデータセットの文字コードはlatin-1(ISO/IEC 8859-1)である.
次に、データセットの概要を説明する:
df.head()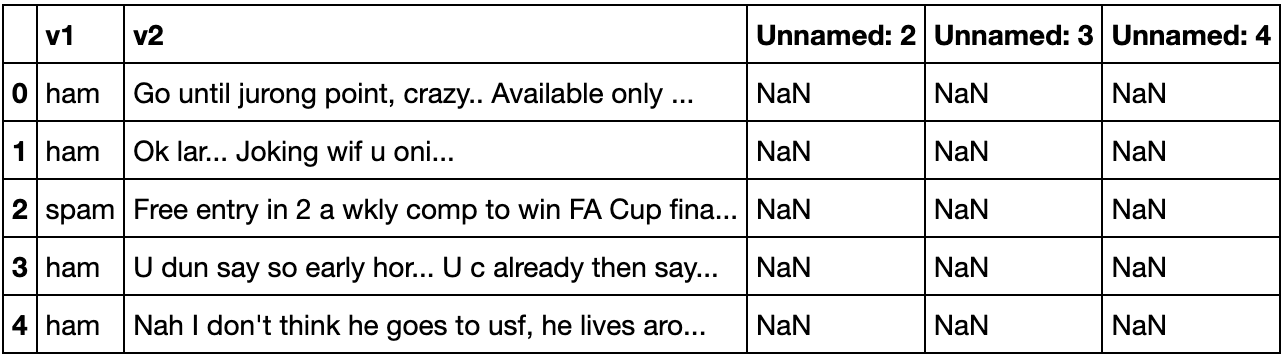 Dataset overview
Dataset overview
データセットには5つのカラムが含まれる。列v1はデータセットのラベル("ham "または "spam")で、列v2はSMSメッセージのテキストを含む。Unnamed: 2"、"Unnamed: 3"、"Unnamed: 4 "の各カラムには、欠損値を表す "NaN"(数字ではない)が含まれている。これらは必要ではないので、モデルを構築するのに役立たないので削除してもよい。以下のコード・スニペットは、データセットのわかりやすさを向上させるために、カラムを削除し、名前を変更します:
df.drop(columns=['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], inplace=True)
df.rename(columns = {'v1':'class_label','v2':'message'},inplace=True)
df.head() Rename columns
Rename columns
ラベルの分布を見てみよう:
fig = px.histogram(df, x="class_label", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"])
fig.show()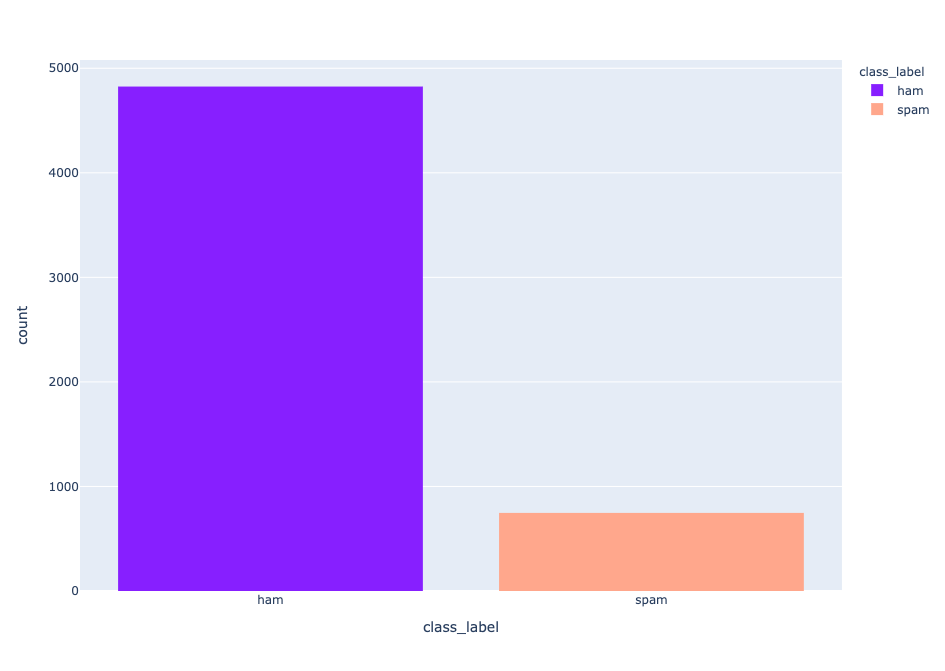 Distributions of labels
Distributions of labels
747通がスパム、4825通がハムというアンバランスなデータセットである。
fig = px.pie(df.class_label.value_counts(),labels='index', values='class_label', color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()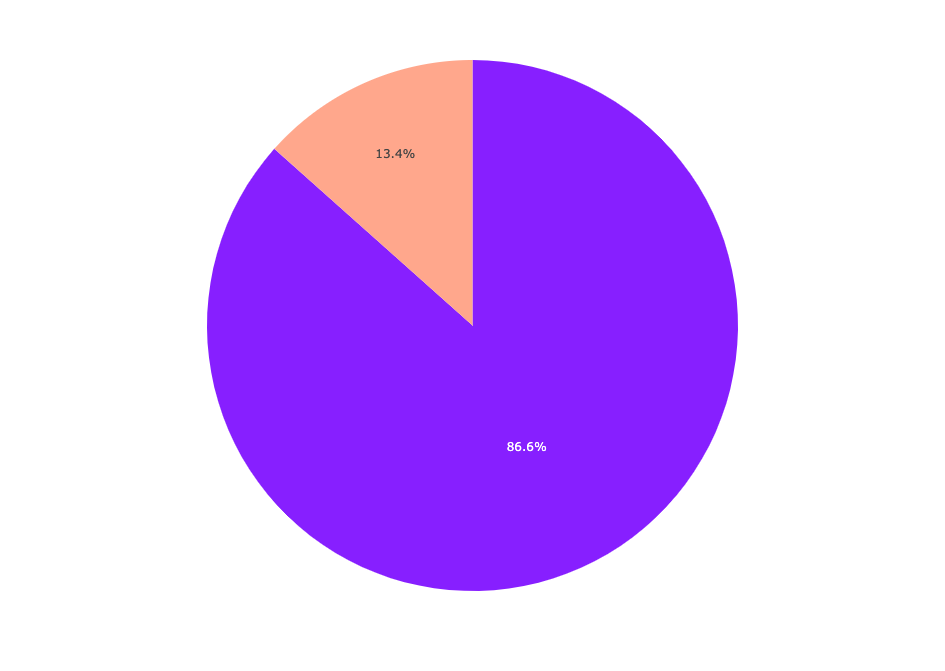 Labels pie chart
Labels pie chart
スパムはデータセットの13.4%を占めるが、ハムは86.6%を占める。
次に、機能工学を少し掘り下げてみよう。メッセージの長さから、何らかのヒントが得られるかもしれない。見てみよう:
df['length'] = df['message'].apply(len)
df.head() Message length
Message length
fig = px.histogram(df, x="length", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()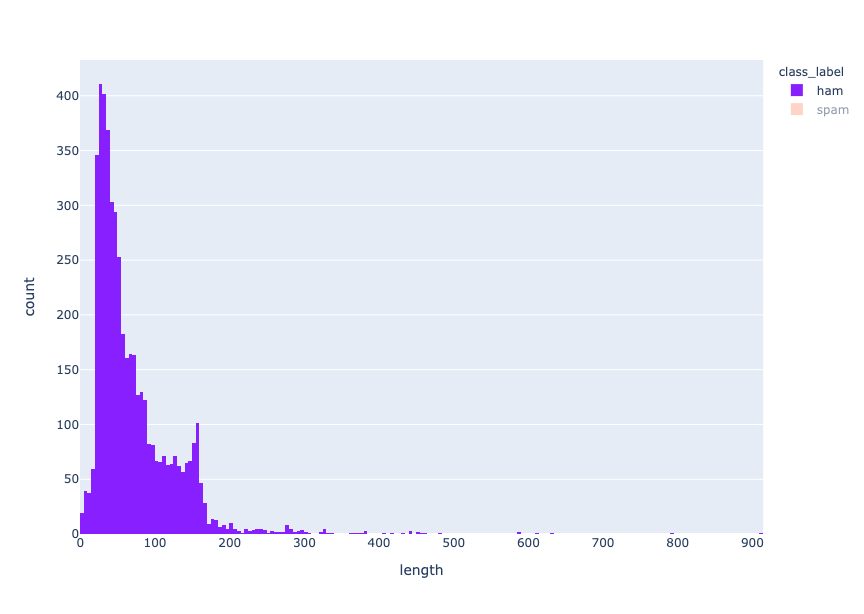 length distribution - ham
length distribution - ham
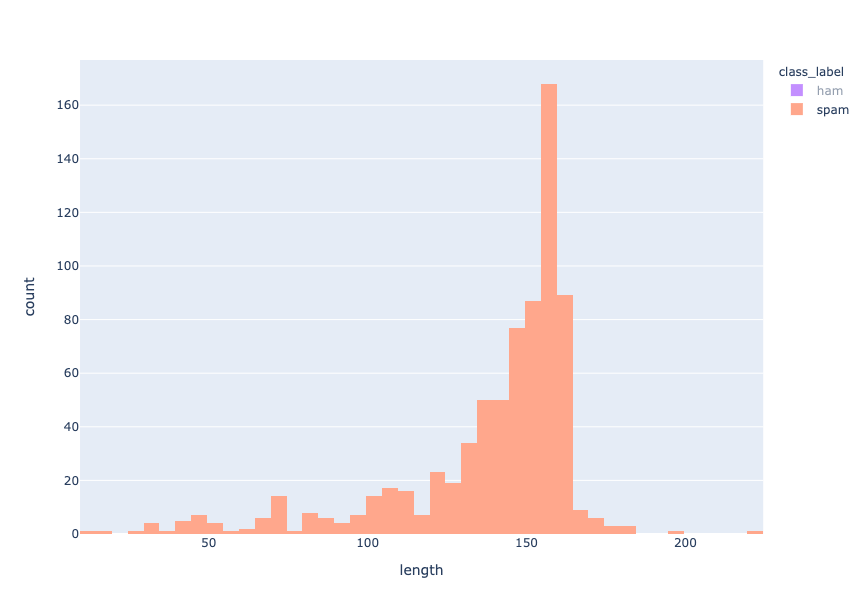 Length distribution - spam
Length distribution - spam
ハムメッセージとスパムメッセージの長さの分布は、それぞれ30-40文字と155-160文字を中心としていることから、ハムメッセージはスパムメッセージよりも短いことがわかる。
スパムとハムで最もよく使われる単語を見ることは、データセットをよりよく理解するのに役立つ。ワードクラウドを使えば、それぞれのクラスでどのような単語が優勢なのかを知ることができる。
ワードクラウドを作るには、まずクラスを2つのpandasデータフレームに分け、以下のように簡単なワードクラウド関数を追加する:
data_ham = df[df['class_label'] == "ham"].copy()
data_spam = df[df['class_label'] == "spam"].copy()
def show_wordcloud(df, title):
text = ' '.join(df['message'].astype(str).tolist())
stopwords = set(wordcloud.STOPWORDS)
fig_wordcloud = wordcloud.WordCloud(stopwords=stopwords, background_color="#ffa78c",
width = 3000, height = 2000).generate(text)
plt.figure(figsize=(15,15), frameon=True)
plt.imshow(fig_wordcloud)
plt.axis('off')
plt.title(title, fontsize=20)
plt.show()以下は、スパムSMSのワードクラウドを表示するコードです:
show_wordcloud(data_spam, "Spam messages") word cloud spam
word cloud spam
ハムSMSのワードクラウドも表示できます:
show_wordcloud(data_ham, "ham messages")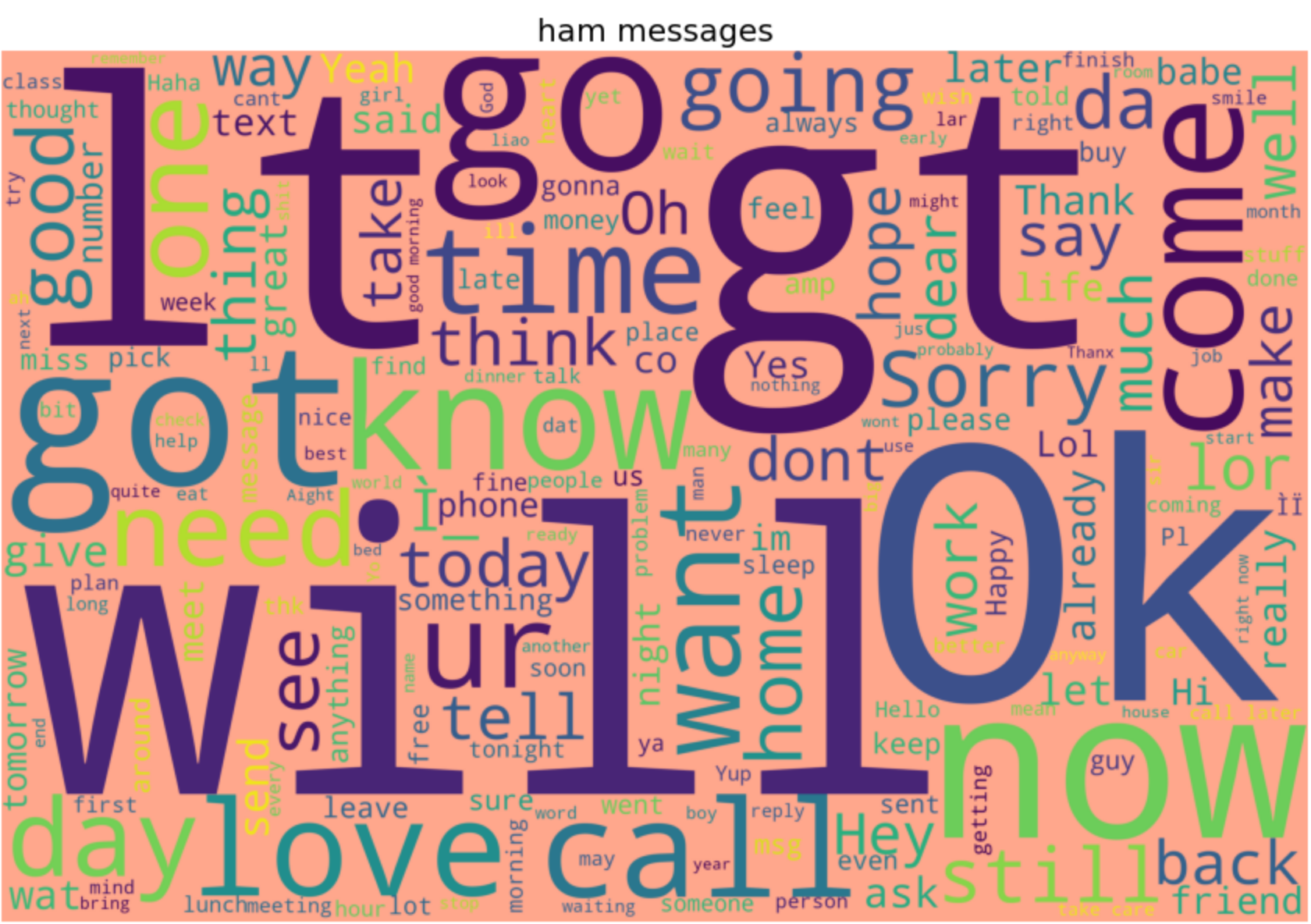 word cloud ham
word cloud ham
データをコンピュータが理解できるものに変換するプロセスは、前処理と呼ばれる。この記事の文脈では、機械学習アルゴリズムのためにテキストデータを準備するプロセスとテクニックが含まれる。
まず、ラベルを数値形式に変換する。ディープラーニング・モデルは数値形式のデータを必要とするため、これはモデル学習の前に不可欠だ。
df['class_label'] = df['class_label'].map( {'spam': 1, 'ham': 0})次に、正規表現(Regex)を使ってメッセージの内容を処理し、電子メールやウェブのアドレス、電話番号、数字を統一し、記号をエンコードし、句読点や空白を削除し、最後にすべてのテキストを小文字に変換する:
# Replace email address with 'emailaddress'
df['message'] = df['message'].str.replace(r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
# Replace urls with 'webaddress'
df['message'] = df['message'].str.replace(r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
# Replace money symbol with 'money-symbol'
df['message'] = df['message'].str.replace(r'£|\$', 'money-symbol')
# Replace 10 digit phone number with 'phone-number'
df['message'] = df['message'].str.replace(r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
# Replace normal number with 'number'
df['message'] = df['message'].str.replace(r'\d+(\.\d+)?', 'number')
# remove punctuation
df['message'] = df['message'].str.replace(r'[^\w\d\s]', ' ')
# remove whitespace between terms with single space
df['message'] = df['message'].str.replace(r'\s+', ' ')
# remove leading and trailing whitespace
df['message'] = df['message'].str.replace(r'^\s+|\s*?$', ' ')
# change words to lower case
df['message'] = df['message'].str.lower()今後は、メッセージの内容からストップワードを取り除きます。ストップワードとは、検索エンジンがエントリーを検索するためにインデックスを作成する際や、検索クエリの結果としてエントリーを取得する際に無視するようにプログラムされている単語のことで、「the」、「a」、「an」、「in」、「but」、「because」などがこれにあたります。
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
df['message'] = df['message'].apply(lambda x: ' '.join(term for term in x.split() if term not in stop_words))次に、接辞を取り除くことによって、単語の基本形を抽出します。これはステミングと呼ばれます。ステミングは、木の枝を茎まで切り落とすこと に例えることができます。ステミングアルゴリズムには、次のようなものがあります:
ポーターのステマーアルゴリズム
ロビンス・シュテマー
ドーソン・シュテマー
クロベッツ・シュテマー
ゼロックス・ステマー
Nグラムステマー
スノーボール・ステマー
ランカスター・シュテマー
これらのステミングアルゴリズムの中には、積極的で動的なものもあります。英語以外の言語に適用されるものもあり、テキストデータのサイズはさまざまな効率に影響します。この記事では、計算速度の点から Snowball Stemmer を使用しました。
注意: これらのステミングアルゴリズムを使用する場合は、ステムの過剰またはステムの不足に注意し てください。
ss = nltk.SnowballStemmer("english")
df['message'] = df['message'].apply(lambda x: ' '.join(ss.stem(term) for term in x.split()))機械学習アルゴリズムは、生のテキストを直接扱うことはできない。テキストは数値に、より具体的には数値のベクトルに変換されなければならない。メッセージ(文章中のテキストデータ)を単語に分割してみよう。これは自然言語処理タスクで必要なことで、各単語をキャプチャし、さらに分析する必要がある。まず、テキストから特徴を抽出するために、BOW(Bag of Words)モデルを作成する:
sms_df = df['message']
from nltk.tokenize import word_tokenize
# creating a bag-of-words model
all_words = []
for sms in sms_df:
words = word_tokenize(sms)
for w in words:
all_words.append(w)
all_words = nltk.FreqDist(all_words)総語数を見てみよう:
print('Number of words: {}'.format(len(all_words))) Number of words 6526
Number of words 6526
次に、テキストデータ中の上位10個の一般的な単語をプロットする:
all_words.plot(10, title='Top 10 Most Common Words in Corpus');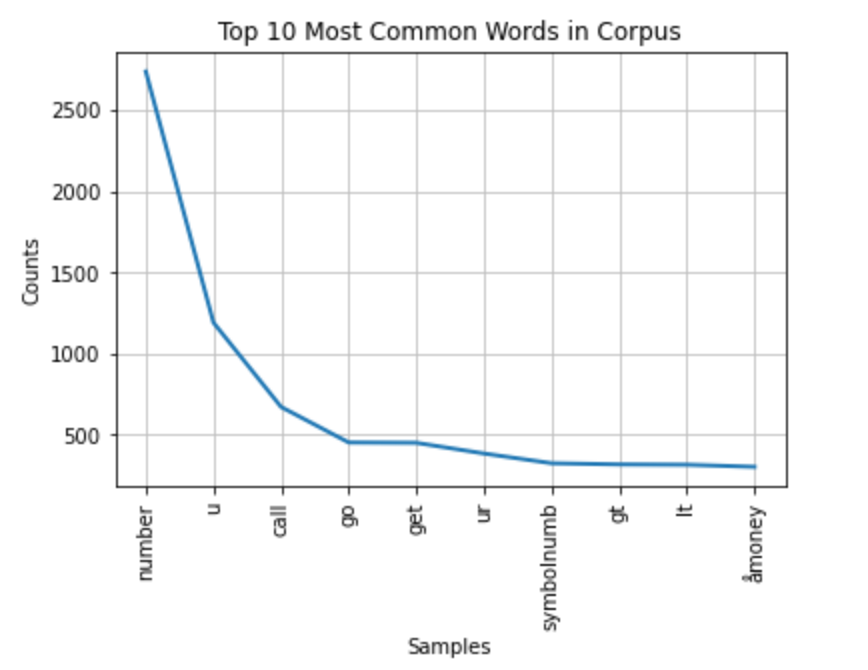 Most common words
Most common words
次に、テキストデータの中で単語がどれだけ重要であるかを評価するために、NLPの手法である項頻度-逆文書頻度を実装する。要するに、この技法は「関連する単語」とは何かを定義するだけである。この NLP テクニックから作成された tfidf_model は、後でウェブアプリケーションのテストデータを変換するために、ローカルディスクに保存(シリアライズ)されます:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
tfidf_vec=tfidf_model.fit_transform(sms_df)
import pickle
#serializing our model to a file called model.pkl
pickle.dump(tfidf_model, open("../model/tfidf_model.pkl","wb"))
tfidf_data=pd.DataFrame(tfidf_vec.toarray())
tfidf_data.head() tfidf
tfidf
得られたデータフレームの形状は、5572 x 6506である。機械学習モデルの性能を訓練・検証するためには、データをそれぞれ訓練データセットとテストデータセットに分割する必要がある。訓練セットは、後で訓練セットと検証セットに分割する必要があります。
### Separating Columns
df_train = tfidf_data.iloc[:4457]
df_test = tfidf_data.iloc[4457:]
target = df['class_label']
df_train['class_label'] = target
Y = df_train['class_label']
X = df_train.drop('class_label',axis=1)
# splitting training data into train and validation using sklearn
from sklearn import model_selection
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,Y,test_size=.2, random_state=42)検証セットの分割比率はトレーニングデータの20%である。
我々はLightGBMとして知られる機械学習アルゴリズムを利用する。これは、ツリーベースの学習アルゴリズムを使用する勾配ブースティングのフレームワークである。以下のような利点がある:
より速いトレーニングスピードと高い効率性
メモリ使用量の削減
より良い精度
並列学習とGPU学習のサポート
大規模データの取り扱いが可能
このプロジェクトのパフォーマンス指標はF1スコアである。この指標は、精度とリコールの両方を考慮してスコアを計算する。F1スコアは1が最高値で、0が最低値である。
import lightgbm as lgb
from sklearn.metrics import f1_score
def train_and_test(model, model_name):
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f'F1 score is: {f1_score(pred, y_test)}')
for depth in [1,2,3,4,5,6,7,8,9,10]:
lgbmodel = lgb.LGBMClassifier(max_depth=depth, n_estimators=200, num_leaves=40)
print(f"Max Depth {depth}")
print(" ")
print(" ")
train_and_test(lgbmodel, "Light GBM") F1 score
F1 score
この反復から、Max Depthが6(6)のとき、F1スコアが0.9285714285714285と最も高いことがわかる。さらに、モデルに最適なパラメータをランダムグリッド探索します:
from sklearn.model_selection import RandomizedSearchCV
lgbmodel_bst = lgb.LGBMClassifier(max_depth=6, n_estimators=200, num_leaves=40)
param_grid = {
'num_leaves': list(range(8, 92, 4)),
'min_data_in_leaf': [10, 20, 40, 60, 100],
'max_depth': [3, 4, 5, 6, 8, 12, 16, -1],
'learning_rate': [0.1, 0.05, 0.01, 0.005],
'bagging_freq': [3, 4, 5, 6, 7],
'bagging_fraction': np.linspace(0.6, 0.95, 10),
'reg_alpha': np.linspace(0.1, 0.95, 10),
'reg_lambda': np.linspace(0.1, 0.95, 10),
"min_split_gain": [0.0, 0.1, 0.01],
"min_child_weight": [0.001, 0.01, 0.1, 0.001],
"min_child_samples": [20, 30, 25],
"subsample": [1.0, 0.5, 0.8],
}
model = RandomizedSearchCV(lgbmodel_bst, param_grid, random_state=1)
search = model.fit(X_train, y_train)
search.best_params_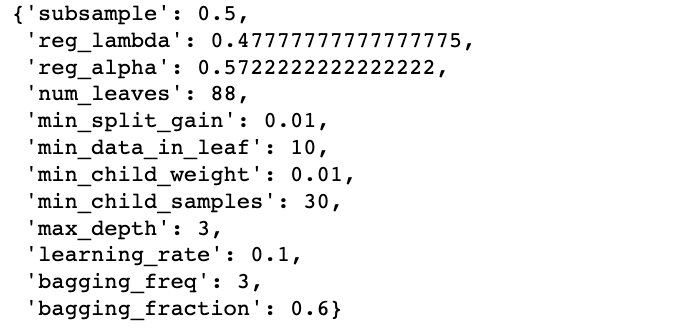 best parameters search
best parameters search
最適なパラメータを使ってモデルを訓練する:
best_model = lgb.LGBMClassifier(subsample=0.5,
reg_lambda= 0.47777777777777775,
reg_alpha= 0.5722222222222222,
num_leaves= 88,
min_split_gain= 0.01,
min_data_in_leaf= 10,
min_child_weight= 0.01,
min_child_samples= 30,
max_depth= 3,
learning_rate= 0.1,
bagging_freq= 3,
bagging_fraction= 0.6,
random_state=1)
best_model.fit(X_train,y_train) Trained model
Trained model
モデルの性能を予測でチェックしてみよう:
prediction = best_model.predict(X_test)
print(f'F1 score is: {f1_score(prediction, y_test)}') Model prediction
Model prediction
最後のステップとして、ウェブアプリがまだ見たことのないデータを予測できるように、データセットに対して完全なトレーニングを行う。モデルをローカル・マシンに保存する:
best_model.fit(tfidf_data, target)
pickle.dump(best_model, open("../model/spam_model.pkl","wb"))
学習済みモデルができたので、Vonage SMS API経由で送受信されたメッセージを読み、スパムか迷惑メールかに分類するFlaskアプリケーションを作成します。最終的な結果は、このセクションで定義するSMSダッシュボードに表示されます。
ディレクトリは web_appディレクトリで構成されている:
├── app.py
├── static
│ ├── Author.png
│ ├── style.css
│ ├── style2.css
│ └── vonage_logo.svg
└── templates
├── inbox.html
├── index.html
└── predict.htmlコード・エディターで、新しいファイル名を .env(先頭のドットに注意)という名前の新しいファイルを開き、以下のクレデンシャルを追加する:
API_KEY=<Your API key>
API_SECRET=<Your API secret>
これはセキュリティ上重要なことで、アプリケーションに秘密をハードコードしてはならない。
次に app.pyという名前のファイルを web_appファイルを作成します。Webアプリケーションをうまく構築するために、ライブラリをインポートします。続いて、Vonage API の認証情報を .envファイルから Vonage API の認証情報を読み込み、Flask アプリを起動します。また、保存したモデルをノートブックからインポートします。
import os
import warnings
import nexmo
from flask import Flask, render_template, url_for, request, session
import pickle
import pandas as pd
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("API_KEY")
API_SECRET = os.getenv("API_SECRET")
client = nexmo.Client(key=API_KEY, secret=API_SECRET)
warnings.filterwarnings("ignore")
app = Flask(__name__)
# secret key is needed for session
app.secret_key = os.getenv('SECRET_KEY')Flaskアプリケーションインスタンスの後、様々なサーバーロギング間隔でデータ保持を支援するためにFlaskセッションを利用します。これらのセッションにはシークレットキーが必要です。 .envファイルにシークレットキーの値を保存し、APIクレデンシャルと同じようにロードします。
次に、ルートに関連する3つの関数を定義する: home(), inbox()そして predict().これらのルートのそれぞれのテンプレートは index.html, inbox.htmlと predict.htmlです、 stlye.cssと stlye2.css.
home/indexルートは、メッセージを送るインターフェイスを提供する:
@app.route('/', methods=['GET', 'POST'])
def home():
return render_template('index.html')インターフェイスを以下に示す:
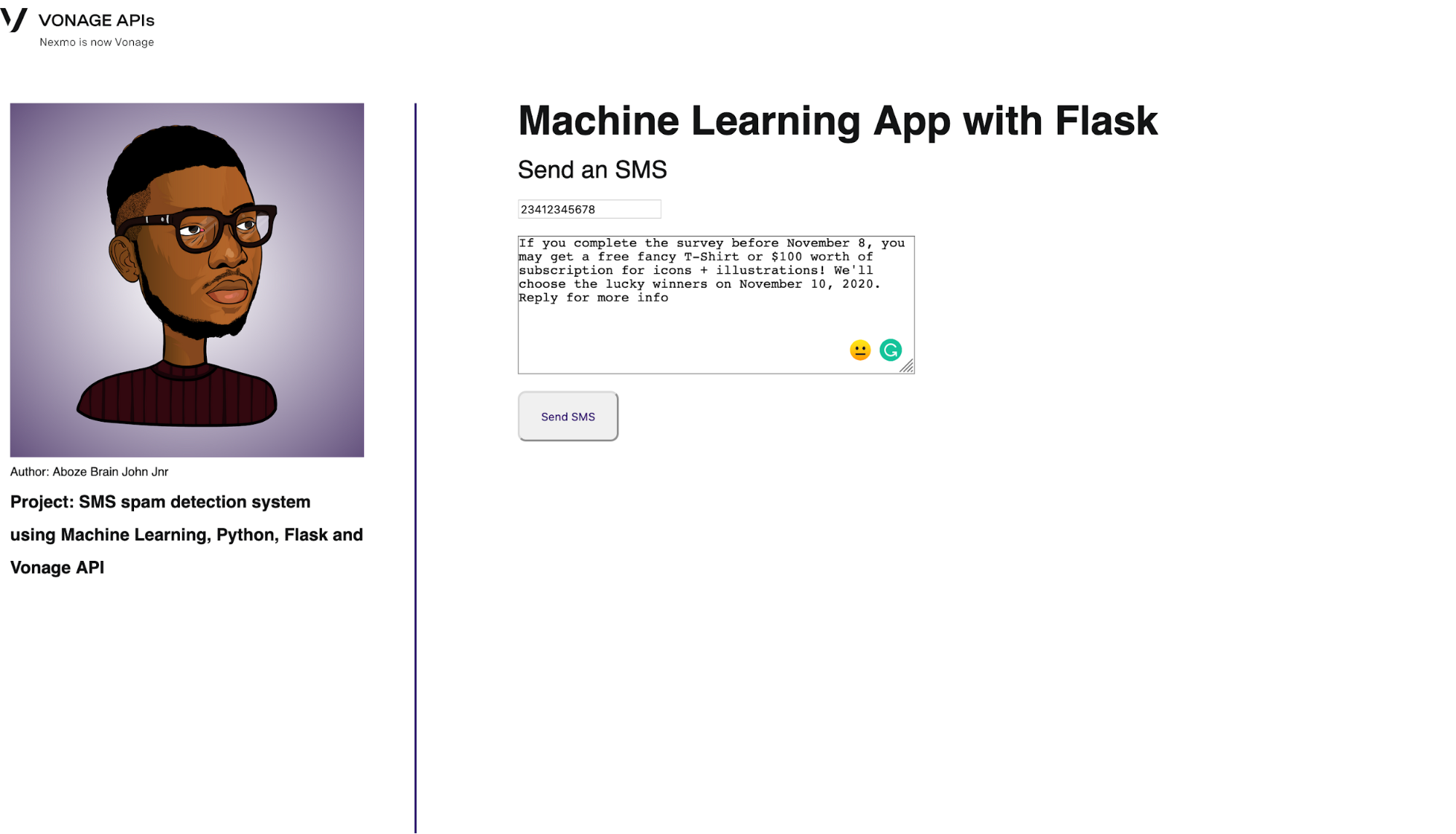 Home interface
Home interface
のサポートファイル index.htmlディレクトリの templatesディレクトリにあるサポート・ファイルは次のようになるはずだ:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Spam detection Project</title>
<link rel="stylesheet" href="../static/style.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Machine Learning App with Flask</h1>
<p>Send an SMS</p>
<form action="/inbox" method="POST">
<input id="to_number" class="form-control" name="to_number" type="tel" placeholder="Phone Number"/>
<br>
<br>
<textarea id="message" class="form-control" name="message" placeholder="Your text message goes here" rows="10" cols="50"></textarea>
<br>
<br>
<input type="submit" class="btn-info" value="Send SMS">
</form>
</div>
</section>
</body>
</html>
次のルートはinboxルートで、インデックスから送信されたメッセージと送信者の電話番号が格納されます。Vonage SMS API はここで、クライアント・オブジェクトを開始し、メッセージを送信するために利用される:
@app.route('/inbox', methods=['GET', 'POST'])
def inbox():
""" A POST endpoint that sends an SMS. """
# Extract the form values:
to_number = request.form['to_number']
message = request.form['message']
session['to_number'] = to_number
session['message'] = message
# Send the SMS message:
result = client.send_message({
'from': 'Vonage APIs',
'to': to_number,
'text': message,
})
return render_template('inbox.html', number=to_number, msg=message)インターフェイスを以下に示す:
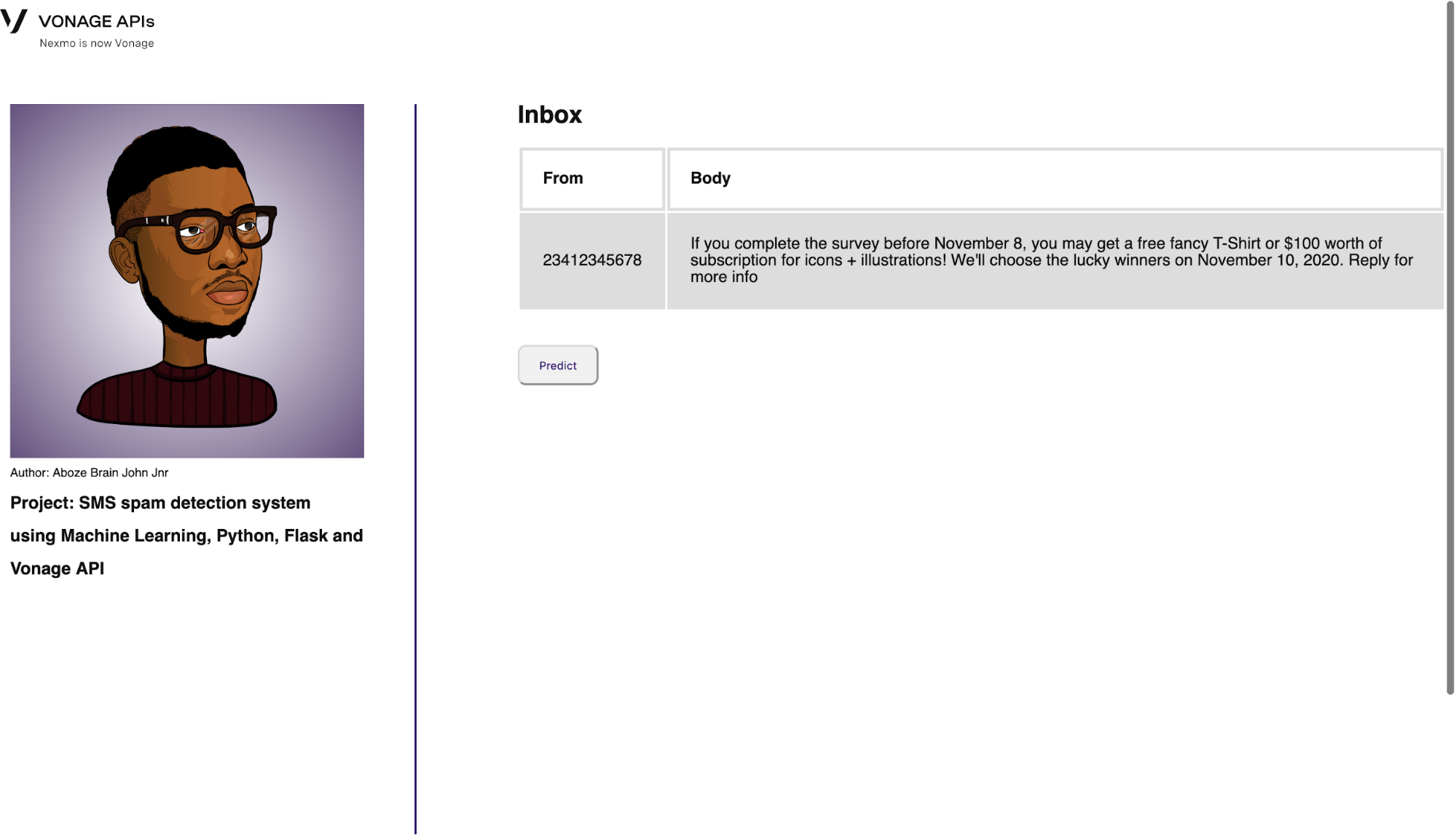 Inbox interface
Inbox interface
のサポートファイル inbox.htmlディレクトリの templatesディレクトリにあるサポート・ファイルは次のようになる:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Inbox</h1>
<br>
<table class="table" >
<tr>
<th scope="col">From</th>
<th scope="col">Body</th>
</tr>
<tr scope='row'>
<td>{{number}}</td>
<td>{{msg}}</td>
</tr>
</table>
<br>
<br>
<form action="/predict" method="POST">
<input type="submit" class="btn-info" value="Predict">
</form>
<!-- <input type="submit" class="btn-info" value="Predict" formaction="/predict" method="POST"> -->
</div>
</section>
</body>
</html>
最後のルートは予測である。これは、機械学習モデルを訓練するために使用される以前のすべての前処理技術を、受信トレイのメッセージという形で新しいデータに適用します:
@app.route('/predict', methods=['POST'])
def predict():
model = pickle.load(open("../model/spam_model.pkl", "rb"))
tfidf_model = pickle.load(open("../model/tfidf_model.pkl", "rb"))
if request.method == "POST":
message = session.get('message')
message = [message]
dataset = {'message': message}
data = pd.DataFrame(dataset)
data["message"] = data["message"].str.replace(
r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
data["message"] = data["message"].str.replace(
r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
data["message"] = data["message"].str.replace(r'£|\$', 'money-symbol')
data["message"] = data["message"].str.replace(
r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
data["message"] = data["message"].str.replace(r'\d+(\.\d+)?', 'number')
data["message"] = data["message"].str.replace(r'[^\w\d\s]', ' ')
data["message"] = data["message"].str.replace(r'\s+', ' ')
data["message"] = data["message"].str.replace(r'^\s+|\s*?$', ' ')
data["message"] = data["message"].str.lower()
stop_words = set(stopwords.words('english'))
data["message"] = data["message"].apply(lambda x: ' '.join(
term for term in x.split() if term not in stop_words))
ss = nltk.SnowballStemmer("english")
data["message"] = data["message"].apply(lambda x: ' '.join(ss.stem(term)
for term in x.split()))
# tfidf_model = TfidfVectorizer()
tfidf_vec = tfidf_model.transform(data["message"])
tfidf_data = pd.DataFrame(tfidf_vec.toarray())
my_prediction = model.predict(tfidf_data)
return render_template('predict.html', prediction=my_prediction)インターフェイスを以下に示す:
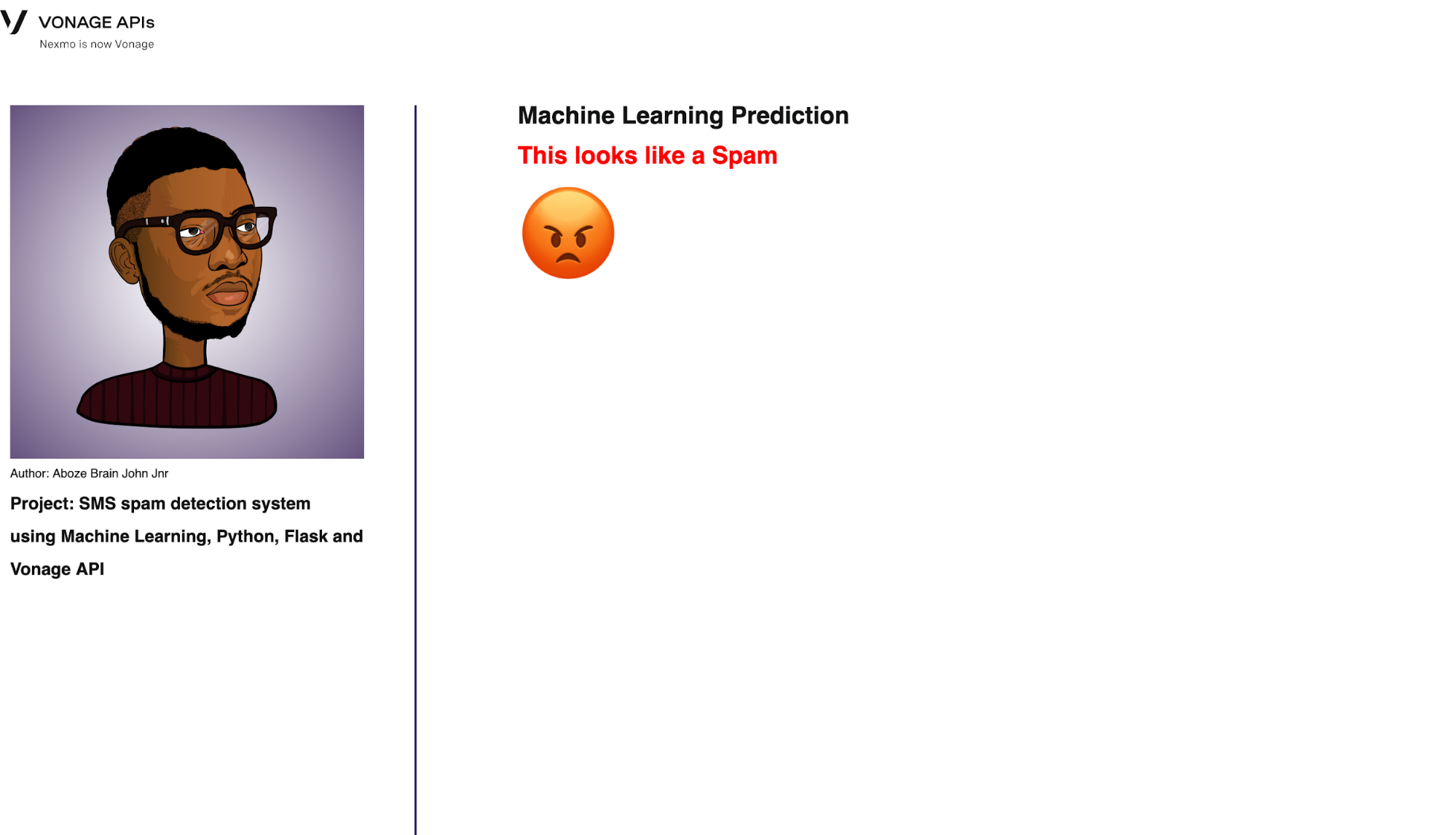 Prediction interface
Prediction interface
のサポートファイル predict.htmlディレクトリの templatesディレクトリにあるサポート・ファイルは次のようになる:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main results">
<h1>Machine Learning Prediction</h1>
{% if prediction == 1%}
<h2 style="color:red; font-size: x-large;">This looks like a Spam</h2>
<span style='font-size:100px;'>😡</span>
{% elif prediction == 0%}
<h2 style="color:green; font-size: x-large;">This looks like a Ham</h2>
<span style='font-size:100px;'>😀</span>
{% endif %}
</div>
</section>
</body>
</html>
Pythonファイルの最後に、ローカルサーバーを起動するコードを追加する:
if __name__ == '__main__':
app.run(debug=True)このプロジェクトで使用する2つのサポート・スタイルシートのminified cssを以下に示す。
に対して style.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}.main h1{font-size:40px;padding-bottom:15px}.main p{font-size:24px;padding-bottom:15px}.btn-info{color:#310069;height:50px;width:100px;border-radius:8px}に対して style2.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}td,th{border:3px solid #ddd;text-align:left;padding:20px}tr:nth-child(even){background-color:#ddd}input{width:80px;height:40px;border-radius:8px;color:#310069}button{width:80px;height:40px;border-radius:8px;color:#310069}これでアプリケーションをテストすることができます!サーバーを起動するには、ターミナルでルート・フォルダーを開き、次のように実行します。 web_appディレクトリで以下を実行します:
上記の手順がすべて完了していれば、以下のようにサーバーが起動しているはずだ:
 Server output
Server output
アドレスバーに http://localhost:5000/を入力し、アプリケーションに接続します。
これでこのチュートリアルは終わりです。他のSMSの例も試してみてください。この新しい知識の素晴らしい可能性と使用例をすでに思い浮かべることができると思います。このスパムフィルターを人事ソフトウェア、チャットボット、カスタマーサービス、その他あらゆるメッセージベースのアプリケーションに統合することができます。
ご質問がある場合、またはあなたが作っているものを共有したい場合は、こちらをクリックしてください。
登録する 開発者ニュースレター
フォローする X(旧ツイッター)最新情報
チュートリアルを見る YouTubeチャンネル
LinkedInの LinkedIn の Vonage デベロッパーページ
最新の開発者向けニュース、ヒント、イベント情報をお届けします。