
シェア:
David is a Software Architect working on Vonage Call Centre, focussing on infrastructure, internal platform and frontend. He has experience across multiple industries including finance, IoT and Cloud Communications.
セルフサービス・データストア
所要時間:1 分
従来、データストアは専門チームによって管理され、セットアップと管理に多くの労力を要してきた。このアプローチはモノリシックなアーキテクチャでは有効だ。しかし、変更の割合が高く、それぞれが独自のデータストアを持つことを目的とするマイクロサービスでは、このモデルはスケールしません。 このため、マイクロサービスの作成にはコストがかかり、チームは中央集権的なチームに依存することになる。
VCC (コンタクトセンター)テクノロジー・チームのこの問題に対する解決策は セルフサービスモデルに移行することでした。しかし、セルフサービス自体は非常に抽象的な概念であるため、私たちの最初のタスクは、セルフサービスのデータストアが実際に何を意味するのかを定義することでした。
データストアとはデータのコレクションを永続的に保存・管理するためのリポジトリ."私たちにとっては、これが対象となる:
MySQLなどのリレーショナル・データベース
DynamoDBなどのNoSQLデータベース
キャッシュ 例:Redis
Elasticsearchのような他のストア
これらのセルフサービスとは、チームができることを意味する:
データストアの作成と管理
スキーマを変更する
安全なデータ変更
デバッグや本番サポートのためのアクセスを含む、データストアのサポート
これらのこと自体は非常に簡単だ。しかし、解決する以上の問題を生み出さないためには、次のようなことも考える必要がある:
自動テストとゲートを使用したベストプラクティスを組み込んだツーリング 品質ゲート
コンプライアンスを確保するためのすべてのアクセスと変更の監査証跡
マルチテナンシー・バリアとファサード(マイクロサービスごとにデータベース・クラスタを持つのは必ずしも経済的ではない)
ホットホットレプリケーションの複雑さ(必要な場合
使いやすさ、堅牢性、内部の複雑さの隠蔽
データストアの主要な利害関係者(データストアを運用するチームとデータストアを使用する機能チーム)は、どちらもセルフサービスから利益を得ますが、その方法は異なります。組織構造によっては、これらが同じチームである可能性さえあります!以下の2つのグラフは、セルフサービスを採用し、それを改善し続けた場合と、何もしなかった場合のシナリオを、1年半にわたって示したものです。
これらのグラフは、スキーマ・マイグレーションの実行、データ変更の実行などのBAU(Business as Usual)タスクが、データストアの需要が時間の経過とともに増加するにつれて、チームにどのような影響を与えたかを示すものです。
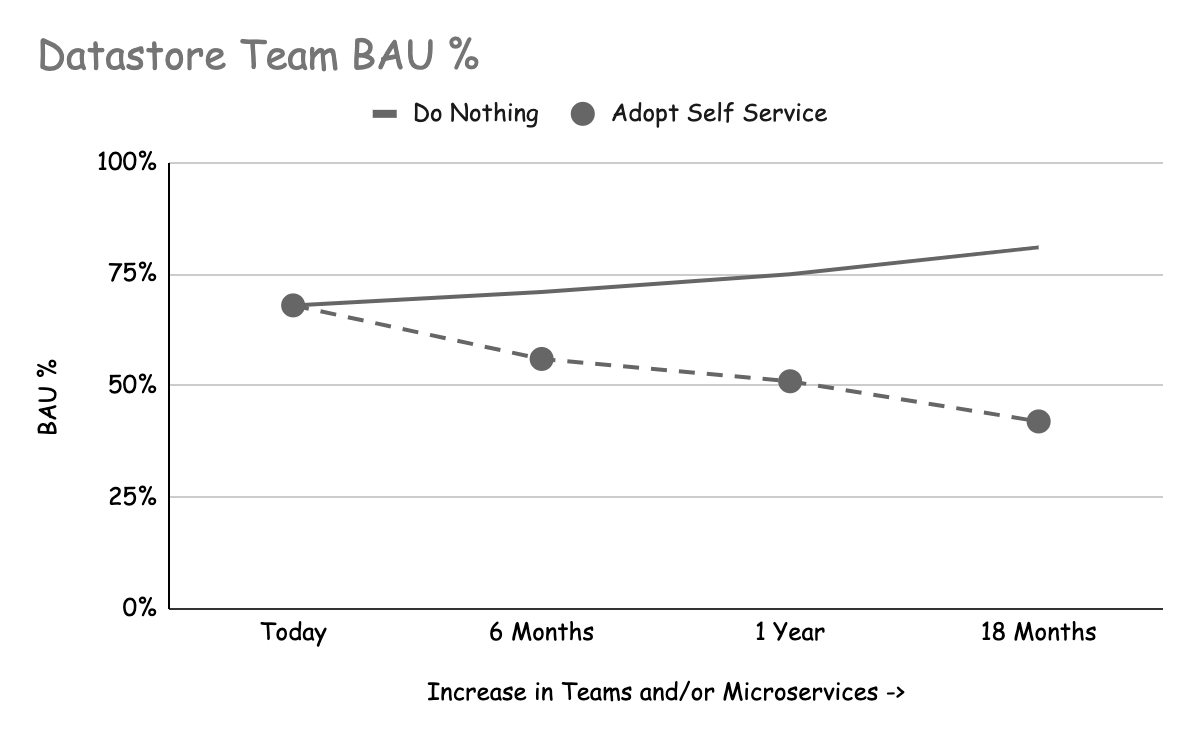 Impact from BAU tasks increases over time
Impact from BAU tasks increases over time
もしあなたの組織がマイクロサービスやチームの数を増やしているのであれば、BAUの量がデータストア・チームを圧倒する時が来るでしょう。人員を増やすことで対処することもできますが、それでは需要に追いつかない可能性が高いです。セルフサービス戦略に移行することで、スキーマ移行などのタスクを削除してBAUを削減し、データストア・チームはより価値の高いタスクに集中できるようになります。
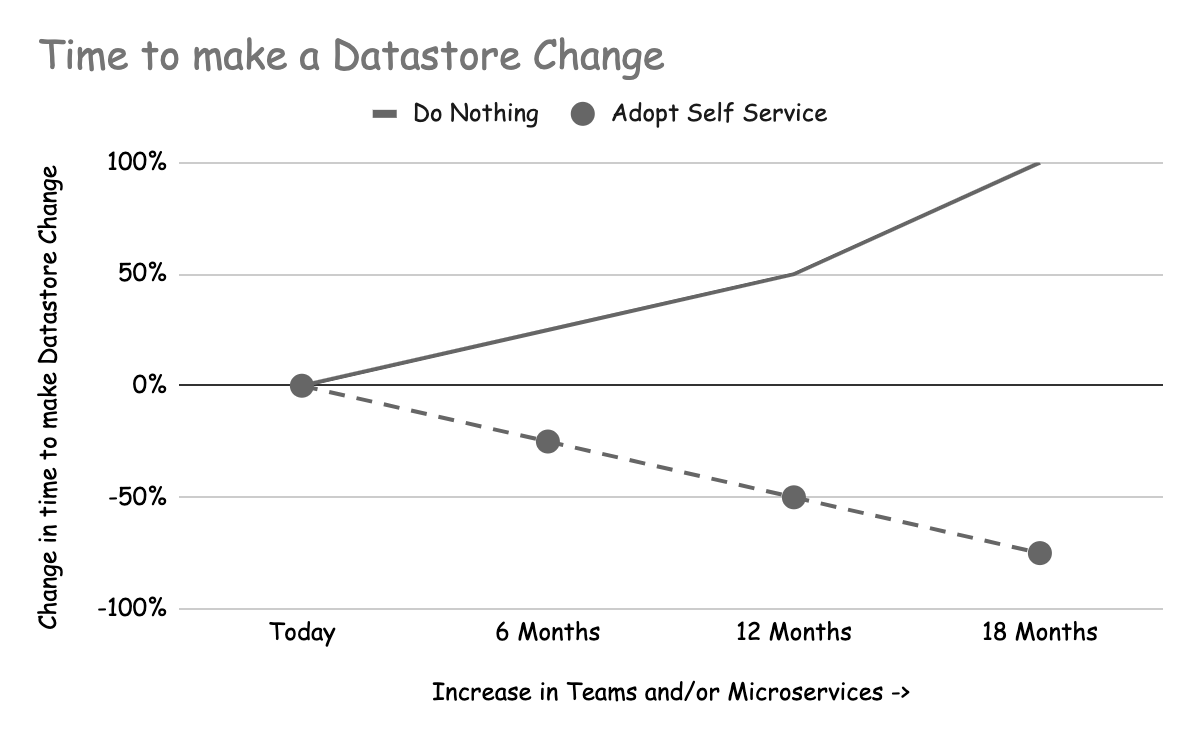 Time to make a datastore change increases over time
Time to make a datastore change increases over time
さらにセルフサービス機能を追加すれば、データストアの変更をより迅速かつ低コストで行えるようになるため、フィーチャー・チームもセルフサービスのメリットを享受できるようになります。フィーチャー・チームがデータストア・チームに変更を依存している場合、そのチームがボトルネックとなり、変更コストが増大する可能性があります。このコストは主に経過時間に現れます。もしデータストアチームが負担し始めると、フィーチャーチームは要求した変更を確実に実行するためにトラッキングを開始しなければならなくなるかもしれません。
セルフサービス・データストアとは何か、なぜそれが必要なのかをご理解いただけたと思う。
VCCに取り組んでいるチームは、以下のセルフサービスを採用している。 AWS Aurora MySQLのセルフサービスを採用しており、CI パイプラインの一部としてサービスの新しいスキーマを自動的に作成し、スキーマを変更することができる。また、データベースの認証情報やマイクロサービスへのアクセス設定も行います。
マイグレーションを実行するプロセス(下図に示す)には、マイグレーションを実行するためのDockerコンテナの作成をオーケストレーションするラムダが含まれる。CIシステムとスキーマ移行システム間の通信にはメッセージングが使用される。スキーマがまだ存在しない場合は、このプロセスによってデータベースも作成される。
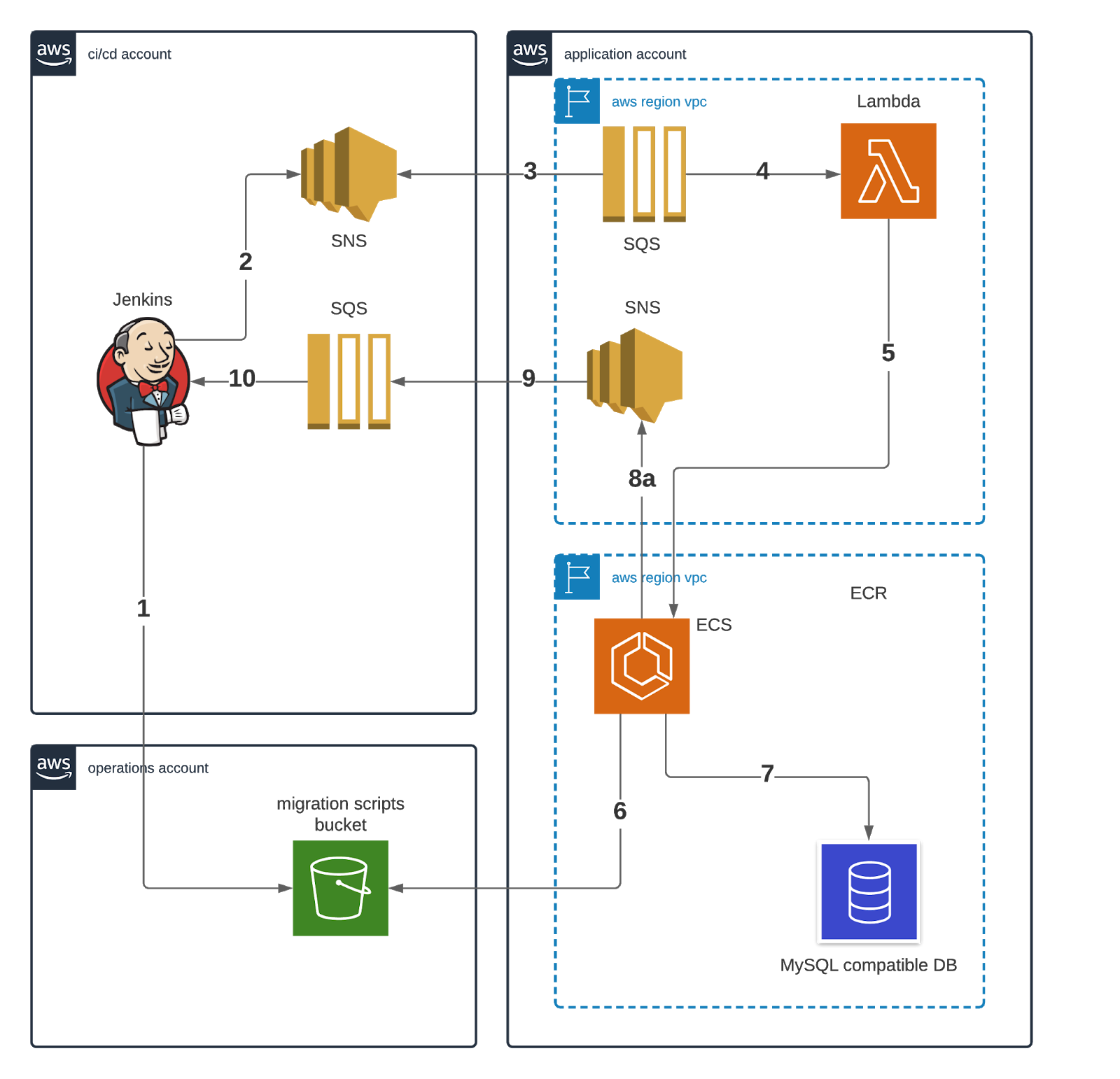
マイグレーション・プロセスのワークフローは、Jenkinsがスキーマの新バージョンのデプロイを要求し、(1)マイグレーション・スクリプト・バケットにマイグレーションをアップロードし、(2)SNSトピックにパブリッシュする。これは(3)SQSによってピックアップされ、SQSはトピックを購読し、(4)スキーマ・マイグレーション・ラムダをトリガーする。
スキーママイグレーションラムダ(5)はECSタスクを開始し、その(6)コンテナはマイグレーションスクリプトバケットからマイグレーションを取り出し、そして(7)実行します。 フライウェイを実行します。マイグレーションが完了すると、(8)コンテナはSNSメッセージをパブリッシュし、(9)CI/CDのSQSキューに拾われ、(10)Jenkinsジョブの状態を更新して完了とする。
これをサポートするために、私たちはまた、私たちのアーキテクチャ特有のベストプラクティスに関するガイドラインを構築しました(例えば、ホットホット・マルチクラスター・レプリケーションに関する考慮事項や、チームが一般的な落とし穴を回避できるようにするためのマイグレーションに関するベストプラクティスなど)。
次に、セルフサービスによるデータ変更、より多くのメトリクスの提供、詳細なクエリ分析のためのツールなど、セルフサービス機能の追加を検討しています。監査証跡との統合により、安全で摩擦の少ないデータアクセスを可能にしたいと考えています。また、すでに行った作業が期待通りの効果をもたらしているかどうかも確認する必要があります。
最後に、私たちはVonageの他の部分が私たちが行った作業を活用できるかどうかを調べています。これは、Vonage Communications Platformを構築し、社内プラットフォームの共通アーキテクチャーを構築する上で、特に重要なことです。 内部プラットフォームの共通アーキテクチャを構築しています。