
IBM WatsonとPythonを使ったリアルタイムの電話トランスクリプション
所要時間:1 分
WebSocketの機能はとても素晴らしいものだと思います。Webフレームワークの中で、電話の音声をリアルタイムでストリームすることができます(音声をストリームバックすることも可能です)。
このリアルタイム・ストリームにアクセスすることで、シグナリングだけでなく、通話の内容を使って興味深いことを行う可能性が大きく広がる。例えば、AIボットと双方向の会話をしたり、通話音声を別のプラットフォームにフィードしてリアルタイムのセンチメント分析を行ったり、通話内のキーワードを監視して顧客との会話を追跡したりすることができる。
このような例の大半では、まず音声をテキストに変換する必要があります。これは音声認識または文字起こしとして知られています。通常、サービスでは音声認識をリアルタイムで行う必要がありますが、そのためには語彙をあらかじめ定義されたいくつかの単語やフレーズに限定しなければなりません。銀行に電話したとき、自動応答で用件を聞かれたことがあるかもしれない。トランスクリプションは会話全体を処理することができるが、歴史的にはオフラインのバッチプロセスであった。テープ起こしサービスが録音を書き起こした後、コールバックであなたに通知します。
最近のAIプラットフォームの発展により、私たちはリアルタイムで全文書き起こしができるようになりました。これを特にうまく実現しているプラットフォームのひとつが、IBM Watsonだ。WatsonはWebSocketインターフェースを公開しており、通話の音声ストリームを送ることができる。このインターフェースの形式は、NexmoのWebSocketインターフェースによく似ている。
IBMが提供する ワトソンREST、HTTP(ウェブフック・コールバック付き)、ウェブソケットなど、いくつかの異なるチャンネルで音声テキスト変換サービスを提供している。大まかには、どれも同じように動作する。音声のチャンクを渡すと、ワトソンが書き起こしで応答する。有効化できるオプションはいろいろある。 中間結果これは部分的な書き起こしを与えるもので、Watsonがより多くの文脈で音声を理解できるようになったときに更新されます。
また 言語モデルを指定する必要がある。Watson には、個別の英国英語と米国英語を含む、多数の言語のモデルがあります。ソース音声が電話によるものである場合、最良の結果を得るためには、ナローバンドモデルを使用する必要があります。
このデモでは、WebSocketインターフェースに接続する。つまり、ストリームをチャンクに分割するための無音検出のようなことをしなくても、Vonageからの音声をそのままWatsonにストリーミングできるということだ。
Watsonは、あなたが音声を送信したのと同じWebSocket接続で文字起こしデータを応答するため、NexmoとIBMを直接接続することはできません。その代わりに、Nexmoから音声を受信してパケットをWatsonに転送するリレーサーバーを実行する必要がある。
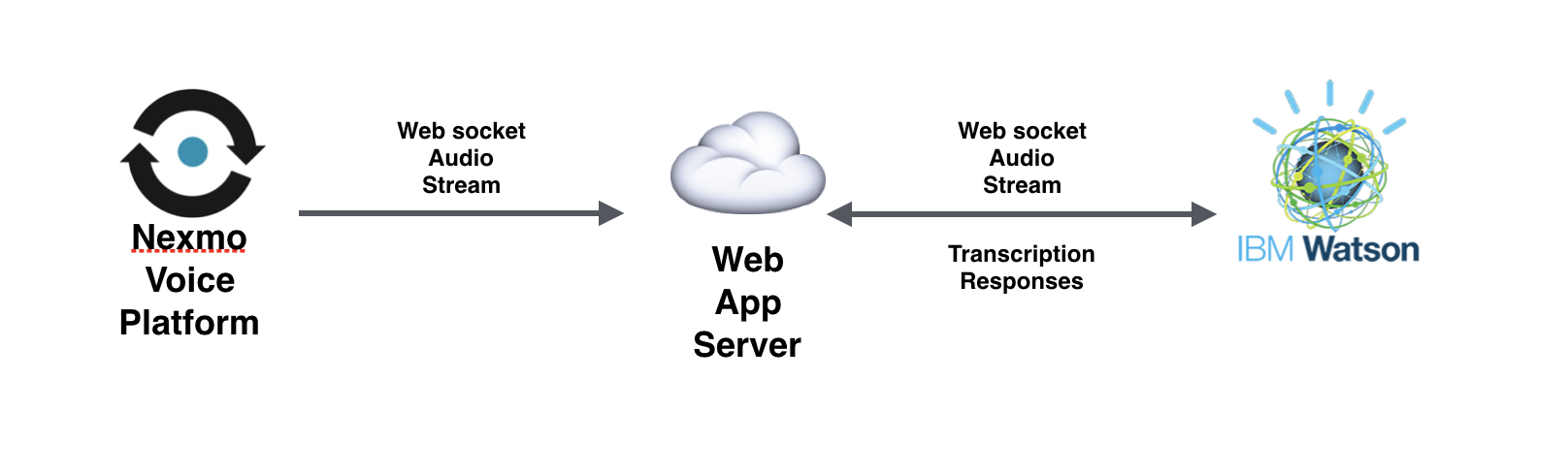 The flow of the application featured in this article
The flow of the application featured in this article
コードは Github.以下、何が起こっているのか見ていこう。
他のNexmo音声アプリケーションと同様に、NCCOを返す応答URLを持つアプリケーションをセットアップする必要があります。そのNCCOをWebアプリサーバーから提供します。このNCCOは、Nexmoに短いハローメッセージを再生するように指示し、その後、コールをWebSocketに接続します。これがNCCOです:
[{
"action": "talk",
"text": "Please wait while we connect you to Watson"
},
{
"action": "connect",
"endpoint": [{
"type": "websocket",
"uri" : "ws://example.com/socket",
"content-type": "audio/l16;rate=16000",
"headers": {}
}]
}]見ての通り、これは非常に簡単なNCCOで、発信者に挨拶し、WebSocketサーバーに接続する。
Vonage がコールを WebSocket サーバーに接続したら、Watson WebSocket インターフェースへの新しい接続を開始する必要があります。Watson に接続するには、ユーザー名とパスワードを使ってトークンをリクエストする必要があります。これらは Watson [https://www.ibm.com/watson/developercloud/doc/common/getting-started-credentials.html]service credentials のセットにサインアップすることで取得できます。
これらのクレデンシャルは以下のオブジェクトのようになる:
{
"url": "https://stream.watsonplatform.net/speech-to-text/api",
"username": "aaaaaaaa-1111-bbbb-2222-cccccccccccc",
"password": "ABC123def456"
}このオブジェクトを使って、トークンを返すようにリクエストする関数を作ることができる:
def gettoken():
resp = requests.get('https://stream.watsonplatform.net/authorization/api/v1/token', auth=(d['username'], d['password']), params={'url' : d['url']})
token = None
if resp.status_code == 200:
token = resp.content
else:
print resp.status_code
print resp.content
return tokenこの関数を使用して、Watson WebSocket サービスの URI を作成することができます:
uri = 'wss://stream.watsonplatform.net/speech-to-text/api/v1/recognize?watson-token={}&model={}'.format(gettoken(), language_model)
language_modelは、コードの冒頭で別の変数に指定してある。
この URI を使って、Watson への新しい WebSocket 接続を作成し、受信する WebSocket 接続の中にオブジェクトとして作成する。(self.watson_future)
VonageからWebSocketにメッセージが届いたら、WSHandlerのon_message関数でそれを処理する。まず watson_futureオブジェクトの yield を呼び出し、Watson 接続への参照を取得します。
新しい接続でVonageから受け取る最初のメッセージは、音声フォーマットを含むテキストメッセージになる。Watsonにストリームをどのように書き起こして欲しいかを伝えるために、メッセージにいくつかの追加パラメータを追加する必要がある。そのメッセージは以下のようなものになる:
{
"interim_results": true,
"action": "start",
"content-type": "audio/l16;rate=16000"
}ここで重要なパラメーターは "action "である:「これは Watson にこれが書き起こしストリームの開始であることを伝えます。これは、Watson が最初に推測した文字起こしを送信し、より良い答えが得られたら、後のメッセージでそれを更新する可能性があることを意味します。1つの書き起こしに対してWatsonから複数のメッセージを受け取る可能性があるため、IDを見てテキストを構成する必要があります。
Watson へのソケット接続がメッセージを受信すると、on_watson_message コールバックを呼び出します。この関数は今のところメッセージを画面に表示するだけですが、この例から拡張して好きなように転記を処理することができます。
ワトソンへの接続に成功すると、以下のようなメッセージが表示されます:
{
"state": "listening"
}ワトソンにオーディオをストリーミングすると、次のようなトランスクリプション・メッセージが表示されます:
{
"results": [
{
"alternatives": [
{
"confidence": 0.617,
"transcript": "hello this is the test "
}
],
"final": true
}
],
"result_index": 0
}これらの回答で注目すべき点は以下の通りである:
信頼度-これは、ワトソンが書き起こしが正確であるとどれだけ確信しているかを示す。上のテストを見てわかるように、私は「こんにちは、これはテストです」と答えましたが、ワトソンは少し間違えました。しかし、信頼度はわずか0.617である。この応答はまだ意味があり、メッセージの本質的な部分はそこにある。
時には、関連する信頼値を持つ複数のトランスクリプトオプションが表示されることもあります。同様に、どのように処理を進めるかを決定するために信頼値を使用することができます。例えば、ユーザーに再度質問をしたいかもしれません。
最終-これは、そのフレーズを書き写す最終パスであることを意味します。以下のように、ワトソンがメッセージの一部だけを書き写した中間結果が表示されることもあります:
{
"results": [
{
"alternatives": [
{
"transcript": "one two three four "
}
],
"final": false
}
],
"result_index": 3
}
{
"results": [
{
"alternatives": [
{
"transcript": "one two three four five six seven eight "
}
],
"final": false
}
],
"result_index": 3
}
{
"results": [
{
"alternatives": [
{
"confidence": 0.982,
"transcript": "one two three four five six seven eight nine ten "
}
],
"final": true
}
],
"result_index": 3
}この例では、10までゆっくり数えたので、Watsonはカウントの途中でトランスクリプション・イベントを送信した。result_indexの値を見ると、同じ値であることがわかる。最後のものだけが finalにセットされている。 trueにセットされ、完全な文字列を含んでいる。
ユーザーが通話を切ると、Nexmo は WebSocket 接続を閉じます。on_close ハンドラを使ってこのイベントを捕捉し、接続を閉じる前に Watson に stop アクションを送ることができます。