
シェア:
Vonageのプリンシパル・データサイエンティスト。計算神経科学の博士号を持ち、倫理的なデータサイエンスへの情熱をすべてのプロジェクトに注いでいる。彼の過去の仕事には、低コストで利用しやすい額電極技術を利用したALS患者のためのフェイシャルジェスチャーコントロールコミュニケーションツールを作成するための助成金を受けた研究プロジェクトを率いたことなどがある。
ループの中の男 vs ループの中のLLM
所要時間:1 分
AIでは、人間による監視("man in the loop")と自動化("LLM in the loop")のバランスを取ることが、現実世界のソリューションを構築する上で極めて重要です。私たちVonage AI(Vonage内でAIサービスの開発を担当するチーム)は、コールセンターでの正確なテープ起こしに対する需要の高まりに対応するため、STT(Speech-to-Text)システムを再設計する際にこの課題に直面しました。
従来のベンチマークの限界を克服するため、我々は大規模言語モデル(Large Language Models:LLM)を用いた新しいアプローチを開発し、複数のSTTプロバイダーからの出力を処理することで、高品質の参照用書き起こしを生成した。LLMは、人間が生成した参考文献や単一の「グランドトゥルース」に依存する代わりに、入力全体の言語と文脈の理解を利用して、コンセンサスとなる書き起こしを合成する。
このLLMに由来するリファレンスは、スケーラブルで偏りのない、文脈を考慮した各プロバイダのワードエラーレート(WER)の計算を可能にする。
この投稿では、このLLMベースの手法が従来のベンチマーキングとどのように比較されるのか、その点に焦点を当てて紹介する:
現在のベンチマーク手法の限界
LLMはどのように参考文献の書き起こしを合成するか
実験から得られた主な結果
Vonage AIでは、人工知能で可能なことの限界を押し広げることに専念する研究者とエンジニアのチームです。インテリジェント・コミュニケーションに対するVonageのコミットメントの一環として、私たちは最先端の会話AIとコアな機械学習研究の両方に注力し、堅牢でスケーラブルかつ先進的なAIソリューションを提供しています。この記事では、私たちの研究の取り組みの1つである、動きの速いマルチモデルの世界における書き起こし精度のベンチマーク方法の再考についてご紹介します。
数年前、顧客のコールセンターに存在するさまざまな方言に対応するため、STTモデルを微調整していたときのことだ。 顧客のコールセンターの様々な方言に対応するSTTモデルを微調整する際、音声の断片を書き写す人間のアノテーターに大きく依存していました。これらの書き起こしは、社内のモデルをトレーニングし評価するための「グランドトゥルース」の役割を果たしました。
このプロセスは時間がかかり、開発サイクルを遅らせる。
コストが高いため、効果的な規模拡大は難しい。
人間のレビュアーは、多くの場合、既存の書き起こしから始めるため、修正に固有のバイアスが生じる可能性がある。
この作業は精神的に負担が大きく、時間の経過とともにヒューマンエラーの可能性が高まる。
しかし、その挑戦は報われた。微調整を重ねた独自のモデルは、最終的に我々の特定のユースケースにおいて、主要なサードパーティ製ソリューションを凌駕したのだ。
顧客のニーズが進化するにつれ、私たちは手作業によるラベリングで新たな課題に直面しました。
新しい言語や方言をサポートするには、それぞれの言語に精通した専門家を雇う必要があった。
医療転写のような業界特有のユースケースをテストするには、その分野に精通した人間が必要だった。
先進的なオープンソースモデルの急速な成長により、評価、展開、微調整の選択肢が増えました。したがって、手作業による転記に何週間も待たされることなく、精度を評価するためのスケーラブルで一貫性のある方法が必要でした。
その結果、私たちは新しい時代を迎えた:ループの中のLLM
グランドトゥルースのために音声の書き起こしを人間に頼る代わりに、私たちはラージ言語モデル(LLM)を使って参照用の書き起こしを生成しています。LLMは様々な書き起こしシステムからの出力を分析し、音声の部分的なセグメントではあるモデルの出力と一致し、音声の別の部分では別のモデルの出力と一致することもあります。
賢くて速いレフェリーがいるようなものだ:
同じ音声の複数の書き起こしを読む
文脈や言葉のニュアンスを理解する
モデルを比較するための、信頼できる公平な「基準」を作成する。
このコンセプトを検証するために、以前に手動でラベル付けした有名なコーパスを処理した。このコーパスを用いて、LLM駆動パイプラインの精度を推定すると同時に、手作業によるラベリング作業の本来の貢献を評価した。
これが私たちがデザインしたものだ:
社内モデル、オープンソースモデル、サードパーティプロバイダーを含む複数のSTTシステムを使って、同じ5~15秒の音声断片を書き起こした。
各クリップについて、元の人間のラベルとともにすべての書き起こしを収集した。次に、LLMにこれらの選択肢(出典は盲検化されている)を提示し、そのスニペットについて最も正確で可能性の高い書き起こしを生成するよう依頼した。
このLLMが生成した「合成グランドトゥルース」(~300サンプル)を使って、各STTシステムのワードエラーレート(WER)を計算した。
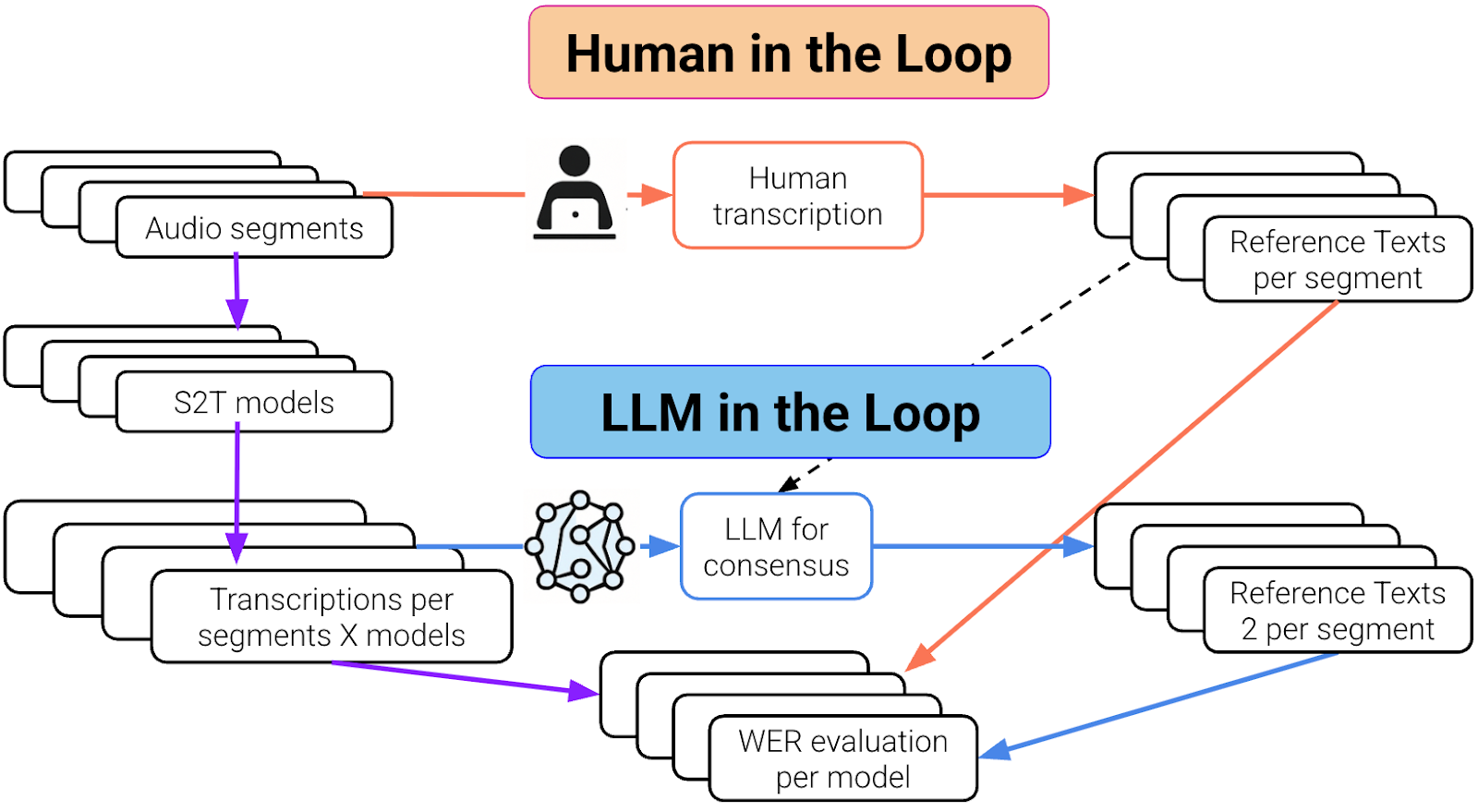 Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
人間ループとLLMループ。紫色の部分は両ループ共通。
短いエージェントのオーディオスニペットに対して、様々なプロバイダから次のようなSTT出力があったとします:
 Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
これらの転写は、書式、数値表現、正確さにおいて様々であり、異なるモデルからの典型的な出力を反映している。
LLMは2つの整列された参照転写を生成するよう指示される:
アルファベット順:
24時間を過ぎると、到着の8日前までのキャンセルは50ドルの手数料がかかることになる。
英数字による参照:
24時間を過ぎると、到着8日前までのキャンセル料が50ドルになる。
このアプローチは、異なるタイプのモデル出力間の公平な(そしてフォーマットに偏らない)比較を保証する。非フォーマット化モデル(私たちのソリューションなど)は非フォーマット化参照に対して測定され、フォーマット化対応モデルは同等の意味を保持するフォーマット化参照に対して測定される。
以下のモデルがテストされた:
Vonage AI (VAI)- 同じチームによって手動でラベル付けされたデータで訓練された、社内の微調整されたモデル
Vonage AI (VAI) - このユースケース用にチューニングされていない旧バージョンモデル。
ヒト標識による転写
OpenAIのオープンソース3モデル: ウィスパーラージ(V3), ウィスパー・ミディアム, ウィスパー・スモール
サードパーティ・プロバイダー2社
人間によるリファレンスの役割を検証するため、LLMベースの評価パイプラインを2つの構成で使用した:
ラベルイン:ヒトの転写は、参照合成のためにLLMに示された代替出力の中に含まれていた。
ラベルアウト:人間の転写は、LLMに示された選択肢から除外された(盲検化された)。
LLMが生成したリファレンスの頑健性と、ヒト標識データによってもたらされる潜在的なバイアスを評価するために、この2つを比較した。
主な評価指標として、単語誤り率(WER)を使用した。これは書き起こしの品質に関する標準的な尺度である。WER は、基準となる文字と比較することで、書き起こしに含まれる誤りの数を定量化します。これらのエラーは3つのカテゴリーに分類されます:
挿入:追加された単語
削除:見逃した単語
置き換え:正しい言葉の代わりに間違った言葉を使う
WERは式を使って計算される:
 Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
WERが低いほど、より正確な転写であることを示す。
 Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
WERはどちらのセットアップでもほぼ同じで、LLMが生成したリファレンスの頑健性が実証された。
ほとんどのモデルで、ラベルイン、ラベルアウトの両設定で安定したランキングとWER値。
「3rd-Party 2」は、人間のラベルを除外した場合に顕著な改善を示し(WER 10.5 → 9.5)、人間のアノテーションよりもLLMが生成した出力とのアライメントが良好であることを示唆している。
この評価では、人間がラベル付けした書き起こしの方が、ほぼすべての自動化モデルよりもWERが高かった。これは、コーパスが英語を母国語としない人々によって書き起こされたものであり、アノテーションツールがタイポのセーフガードを欠いていたことから予想されたことである。
同じチームによって人間のラベルでトレーニングされたVAIファインチューニング・モデルは、チューニングされていないモデルを上回り(WER 13.7 → 12.5)、その不完全さにもかかわらず、このようなデータの有用性を示している。
これらの結果は、LLMが生成した参照用トランスクリプションが、STTシステムのベンチマークとして信頼性が高く、一貫性があり、スケーラブルであることを示している。人間がラベル付けしたデータの有無にかかわらず、評価全体のWERと順位がほぼ同じであることから、パイプラインの頑健性が浮き彫りになった。
モデルによっては、LLMのトークン化や書式設定の方が適している場合もあるが(「3rd-Party 2」に見られるように)、全体的には、LLMに由来する参考文献は、公正で再現性のある評価方法を提供している。
重要なことは、人間によってラベル付けされたリファレンスは高いエラー率を示したが、モデルのトレーニングには依然として価値があるということである。このようなデータでファインチューニングを行うことで、モデルの性能が大幅に向上し、評価が自動化できる場合でも、モデル開発におけるラベル付きデータの役割が再確認された。
LLMは信頼性の高い参照転写を生成することができ、スケーラブルで高スループットのベンチマークをサポートする。
ヒト標識のリファレンスはもはや評価には必要ないが、トレーニングにはまだ利点がある。
この方法によって、新しいモデル、言語、ドメインにまたがる公正なベンチマークが加速され、手作業による転記が不要になる。
独自のAIエージェントを構築し、さまざまなソリューションをベンチマークしたいですか?独自の AI Studioエージェントと組み合わせることができます。 Deepgramのようなサードパーティソリューション と組み合わせてみてください。
ご質問がある場合、またはあなたが作っているものを共有したい場合は、こちらをクリックしてください。
登録する 開発者ニュースレター
フォローする X(旧ツイッター)最新情報
チュートリアルを見る YouTubeチャンネル
LinkedInの LinkedIn の Vonage デベロッパーページ
最新の開発者向けニュース、ヒント、イベント情報をお届けします。