AIオーディオアプリ向けAudio Connector SDKとPipecat Serializerのご紹介
所要時間:1 分
リアルタイムAIアプリケーションは、開発者が音声やビデオ体験を構築する方法を変えつつあります。テープ起こしサービス、会話エージェント、リアルタイム翻訳、センチメント分析など、最新のアプリケーションでは、録音の終了時やファイルのアップロード後だけでなく、動いている生の音声にアクセスすることがますます必要になっています。
PipecatオープンソースのフレームワークであるPipecatは、AIワークフローをオーケストレーションするためのモジュール式でベンダーニュートラルなプラットフォームを提供することで、VonageのVideoおよびVoice APIとオーディオコネクタの統合を強化します。超低遅延、高度な音声アクティビティ検出、マルチモーダルサポートなどの機能により、Pipecatは開発者が非常に応答性が高く自然な会話AI体験を作成することを可能にします。その柔軟性により、さまざまなAIモデルやサービスとのシームレスな統合が可能になり、リッチなリアルタイム音声・動画アプリケーションの構築に理想的な選択肢となります。
この次世代のインテリジェント・アプリケーションをサポートするために、Vonageは開発者向けに特別に設計された2つの補完的なツールを発表しました。 Vonage Audio Connector PythonサーバSDKそして Pipecat用Vonageシリアライザー.Vonage Audio Connector Python Server SDKとVonage Serializer for Pipecatです。この2つのツールを組み合わせることで、Vonage VideoおよびVoiceセッション、WebSocketサーバー、OpenAI、Deepgram、AWS Nova SonicなどのAIフレームワーク間で音声をストリーミングすることが劇的に簡単になります。
このブログでは、これらのツールの概要を説明し、それらがどのように組み合わされているかを説明し、最初のAIを搭載したエージェントを展開するためのリファレンスを提供します。
多くのAIワークフロー(音声テキスト変換、LLM駆動分析、音声合成、マルチモーダル知覚)は、リアルタイムの音声に依存しています。Vonage Voice and Video APIを使用する開発者は、アクティブなセッションから音声を受信し、それを処理し、応答を送り返すためのシンプルで信頼性の高い方法を長い間求めてきました。
Vonageオーディオ・コネクタVideo API および Voice API ウェブソケット統合により、開発者はVonage SessionsをAIワークフローに橋渡しするWebSocketサーバを構築することができます。
しかし、低レイテンシーのWebSocketサーバーを構築し、バイナリーオーディオフレームを管理し、サンプルレートを調整し、ステートフルな接続を維持することは、複雑でエラーが発生しやすい場合があります。このような複雑さは、実験、概念実証の開発、本番環境でのデプロイメントをしばしば遅らせます。
Vonage Audio Connector SDKはこの摩擦を取り除きます。
ツールチェーンは、以下のようなリアルタイムのAI体験を幅広くサポートしている:
音声テキスト起こし
LLMベースのミーティング・アシスタント
ライブ・コールにおけるセンチメントまたはインテント分析
対話型音声ボット
リアルタイム言語翻訳
自動化されたメモ取りや要約
音声モデレーションとコンプライアンス検出
次の図は、WebSocketを介してAudio Connector SDKと統合されたビデオセッションまたは音声会話のアーキテクチャを示しています。 SDK は Python パッケージ (PyPIで入手可能) で、Vonage セッションから WebSocket オーディオ・ストリームを管理する複雑さを抽象化します。
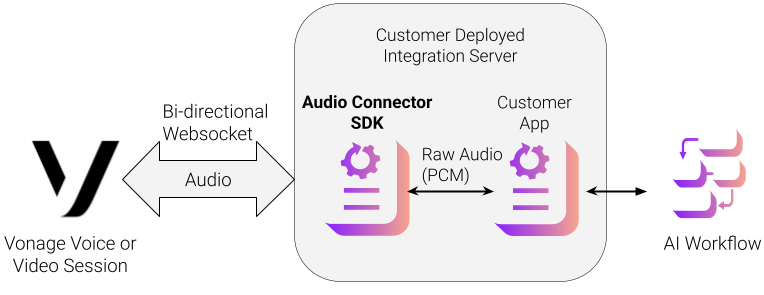
イベント駆動型WebSocketサーバーPCMオーディオ送受信用
8kHz、16kHz、24kHzサンプルのサポート自動フレーム処理
クリーンな非同期コールバック接続、切断、メッセージ、エラーイベント用
内蔵バッファリングとタイミングコントロールスムーズな再生
複数同時接続マルチエージェントまたはマルチパーティシパントワークフローに対応
TLSサポートセキュアな本番環境向け
これによって開発者は、WebSocketインフラを記述する必要なく、トランスクリプション・パイプライン、分析ツール、音声アシスタントなど、作りたいものに完全に集中することができる。
SDKは、Pythonパッケージマネージャを使用して、Pythonパッケージインデックスからインストールすることができます。
pip install vonage-audio-connector-server
SDK開発者ガイド SDK開発者ガイドには、WebSocket サーバーの設定/起動、セッションとオーディオ管理のための非同期ハンドラの設定、WebSocket を介した Video セッションへのオーディオのインジェクションの基本的なリファレンスが記載されています。
SDKを使用してVideo SessionからサーバへのWebSocket接続を開く方法については、以下のページを参照してください。 Audio Connector 開発者ページ.SDKを使用してVoice ConversationからサーバーへのWebSocket接続を開く方法については、Voice WebSockets開発者ページでご覧いただけます。 Voice WebSockets開発者ページ.
Audio Connector SDK を使用するためのサンプルコードは GitHub リポジトリ
Pipecatは、オーディオ、ビデオ、画像、テキストにわたる複雑なAIワークフローをオーケストレーションするためのオープンソースのフレームワークである。音声に特化したアプリケーションには、新しい Pipecat用Vonageシリアライザーは、Vonage VoiceおよびVideoセッションとPipecat処理パイプライン間のブリッジとして機能します。
インバウンドのVonageオーディオフレームをPipecatの内部フレームフォーマットに変換します。
サンプルレートとオーディオエンコーディングの調整
DTMFおよびその他のメタデータをサポート
アウトバウンドのPipecatオーディオフレームをVonage WebSocketフレームに変換します。
つまり、開発者はメディア翻訳コードを書くことなく、PipecatのAIノード(OpenAI Realtime、Deepgram、Whisper、ElevenLabsなど)の増加するリストを使用できる。
シリアライザーは、ライブ参加者の音声と、完全にプログラム可能なAIワークフローを直結します。
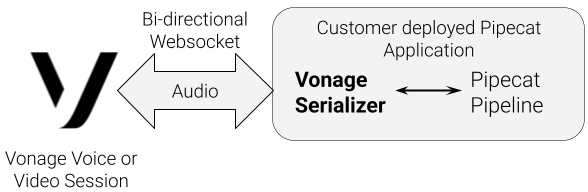
シリアライザ シリアライザーガイドは、PipecatでVonage Serializerを設定するための基本的なリファレンスを提供します。
使用方法 Vonage Audio Connector SDKまたは Pipecat Serializerを使用することで、開発者はWebSocketサーバやメディアパイプラインを再発明することなく、クリーンでモダンでPythonに適した方法でリアルタイムオーディオエージェントを構築することができます。
音声ボットの構築、音声テキストとLLMの統合、リアルタイム合成応答の生成、通話行動の分析など、これらのツールは必要な基盤を提供します。
始める準備ができたら、探検してみよう:
PyPIパッケージの PyPIパッケージオーディオコネクタSDK
サンプルアプリケーションSDK用
について Vonage Pipecatシリアライザ
Vonageの例 Pipecat repoにある
これらのツールを使えば、最初のAIエージェントを数分で導入し、Vonageプラットフォーム上で完全にインテリジェントなメディア対応アプリケーションを自信を持って構築することができます。
ご質問がある場合、またはあなたが作っているものを共有したい場合は、こちらをクリックしてください。
登録する 開発者ニュースレター
フォローする X(旧ツイッター)最新情報
チュートリアルを見る YouTubeチャンネル
LinkedInの LinkedIn の Vonage デベロッパーページ
最新の開発者向けニュース、ヒント、イベント情報をお届けします。