
シェア:
Benjamin AronovはVonageの開発者支援者です。彼はRuby on Railsのバックグラウンドを持つ実績のあるコミュニティ・ビルダーです。Benjaminは故郷であるテルアビブのビーチを楽しんでいる。テルアビブを拠点に、世界最高のスタートアップの創設者たちと出会い、学ぶことができる。技術以外では、完璧なパン・オ・ショコラを求めて世界中を旅するのが好き。
インテント分類階層の構築方法
所要時間:1 分
会話型AIエージェントは、貴社の最も重要なリソースである従業員の時間を節約する素晴らしい方法です!エージェントはインタラクティブなFAQのようなものですが、より柔軟性があります。エージェントを正しく構築すれば、顧客体験を劇的に向上させることができます。しかし、問題は、どのように正しく構築するかということです。
ありがたいことに、AI Studioのチームがあなたのために大変な作業をしてくれました!大規模AIエージェント(50以上のインテント)のパフォーマンスを大幅に改善することができました。これらの技術により、一部のエージェントでは、成功したコールが55%増加し、人間のエージェントへのリクエストが83%減少しました。
この投稿では、以下の階層を構築する方法について説明します。 インテント分類で階層を構築する方法について説明します。トピックには、一般的なNLUのベストプラクティス、階層分類の構築例、AI Studioで会話AIエージェントを設計する際のヒントが含まれます。
NLUとは? 自然言語理解NLU(自然言語理解)とは、コンピュータがテキストの意図を理解するためのプロセスである。NLUは、ユーザーがコンピューターと会話する際に、コンピューターがその意味を理解する方法です。このソフトウェアは、意図の分類とエンティティの抽出を通じてこれを行います。
インテントの分類はとても簡単なように思えますよね?エージェントはユーザ入力を分解し、定義したインテントにマッピングするだけです。しかし、実際にはモデルを混乱させることは非常に簡単です。
銀行のような金融機関のために設計されたエージェントのシナリオを考えてみましょう。このコンテキストにおいて、顧客は、ローンリクエスト、ローンステータスのチェック、一般的なローン情報の検索など、ローンに関連する様々なインタラクションを開始するかもしれません。
ローン」や「住宅ローン」といった用語が、「住宅ローンの担当者と話す」や「住宅ローンの提案を受ける」といったフレーズのように、多様な文脈で使用される場合に問題が生じる。このように1つの分類ノード内で同じキーワードが広範囲に使用されると、モデルによる誤分類を引き起こす可能性がある。
この問題を軽減するために、私たちは、基本的に2つの分類ノードからなる2つのレイヤーを持つ階層構造を実装することを提案する。最初のレイヤーは、「ローン」や「住宅ローン」のような核となる概念の分類に重点を置き、2番目のレイヤーは、ユーザーのクエリ(リクエスト、ステータス、代表者など)に関連する特定のアクションや意図を識別することに特化する。この階層的アプローチは、モデルの精度を高め、類似しているが文脈上異なる意図を誤分類する可能性を減らすことを目的としている。
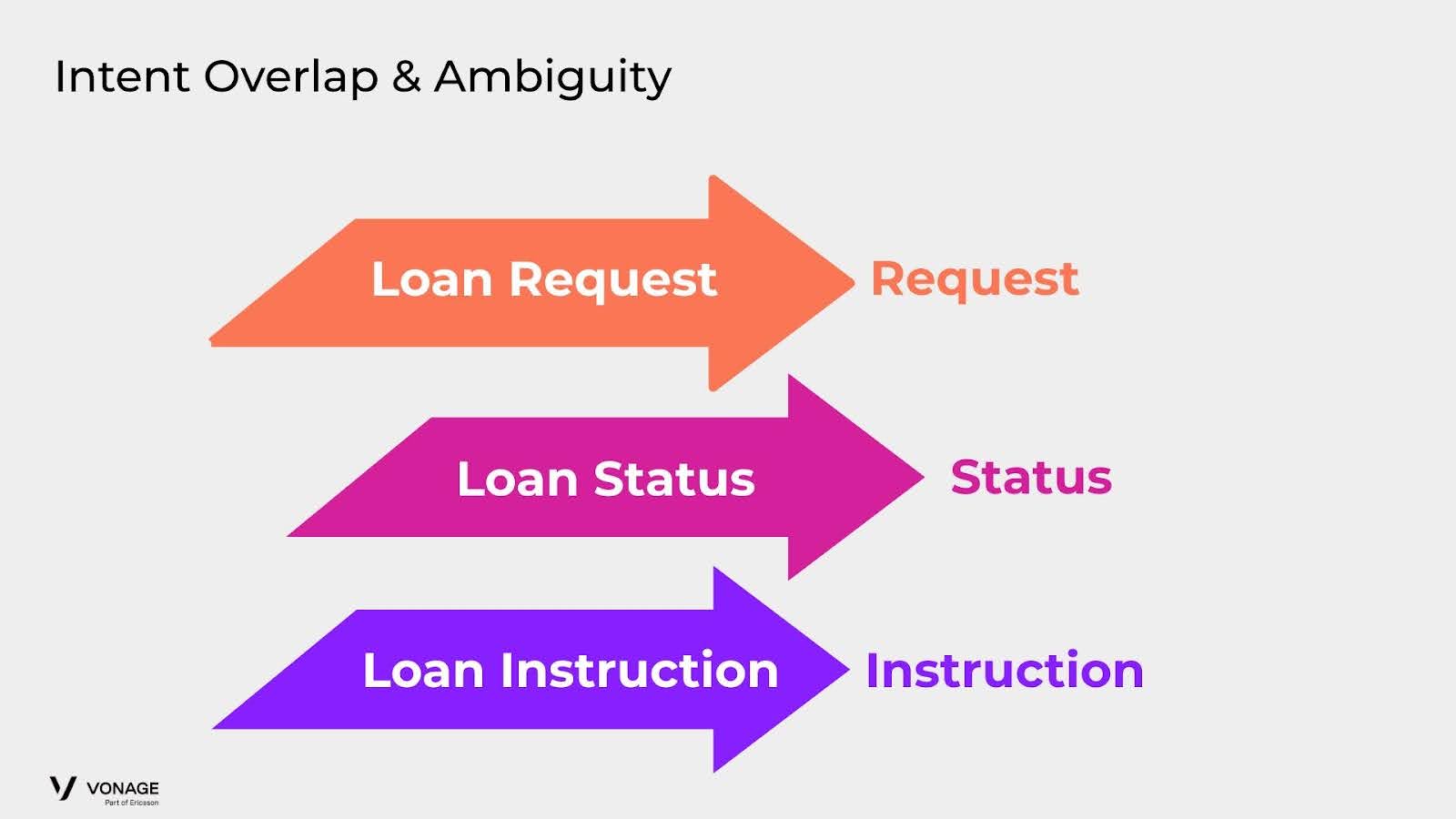 Intent Overlap & Ambiguity
Intent Overlap & Ambiguity
さらに トレーニングセット各インテントを構成するトレーニングセットには非常に類似した表現があるため、非常に一貫性を持たせる必要があります。トレーニングセットに曖昧な単語を追加すると、一貫性のない適用をした場合に予期しない動作を引き起こす可能性があります。
例えば、(Loan) Request インテントに "I want to ask for a loan" という表現が含まれているとします。今、ユーザがエージェントに "I want to ask for a loan status "と尋ね、(Loan) Statusにルーティングするはずです。Statusのトレーニングセットに "I want to "と "loan "を含む表現が含まれていない限り、Requestにルーティングされる可能性が非常に高くなります。この問題を解決するためには、トレーニングデータはあいまいなフィラー/サポート語に対して極めて一貫性がある必要があります。そのため、あらゆる場所にフィラーを追加するか、あらゆる場所からフィラーを削除する必要がある。多くの場合、省略する方が簡単です。
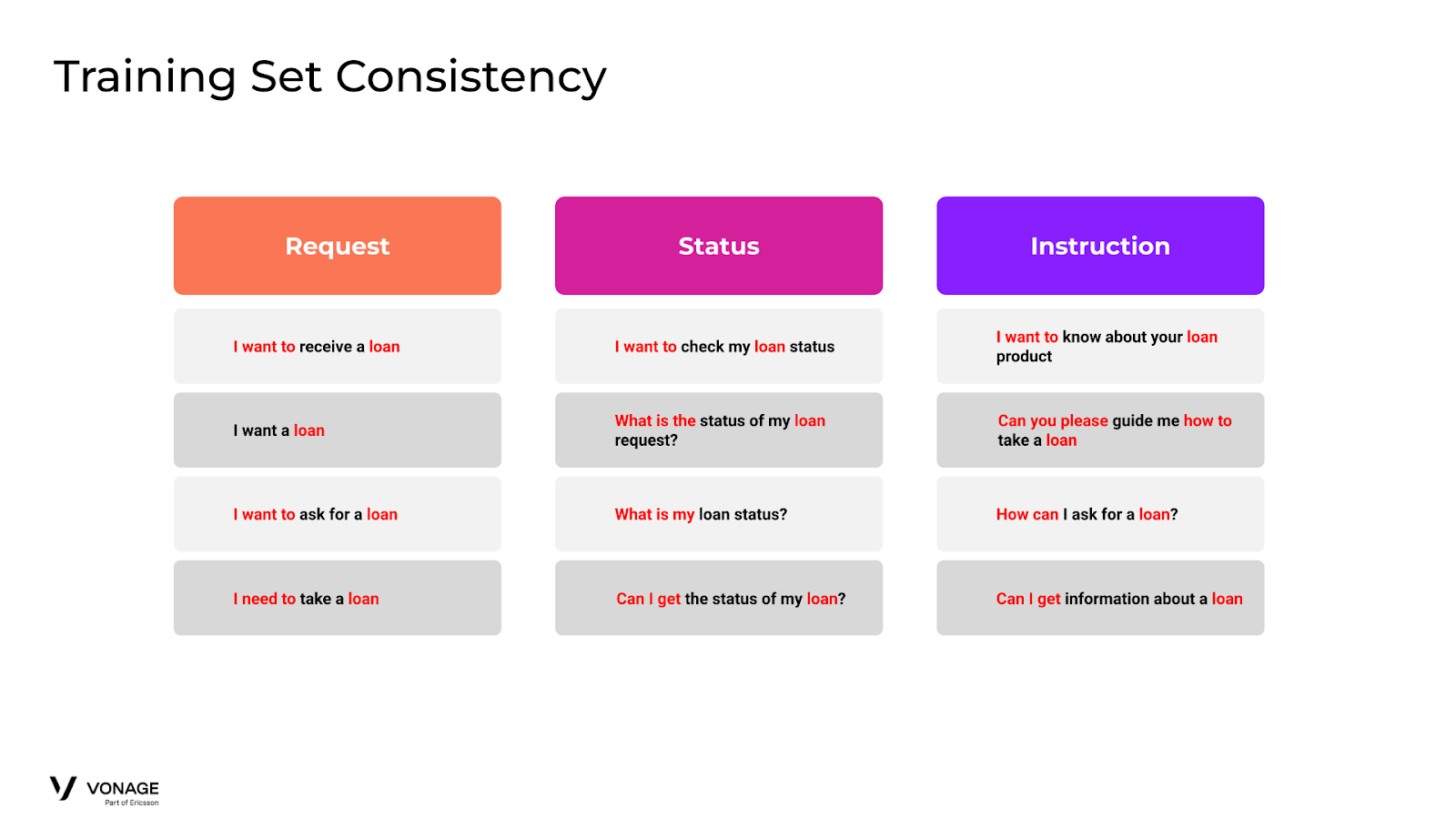 Training Set Consistency
Training Set Consistency
ここで、銀行エージェントに2つの新しいインテントを追加したいとします:コールバックとセールスです。コールバックは、カスタマーサポートの担当者から折り返し電話をもらいたいユーザのためのもので、セールスは、営業部門の誰かから電話をもらいたいユーザのためのものです。
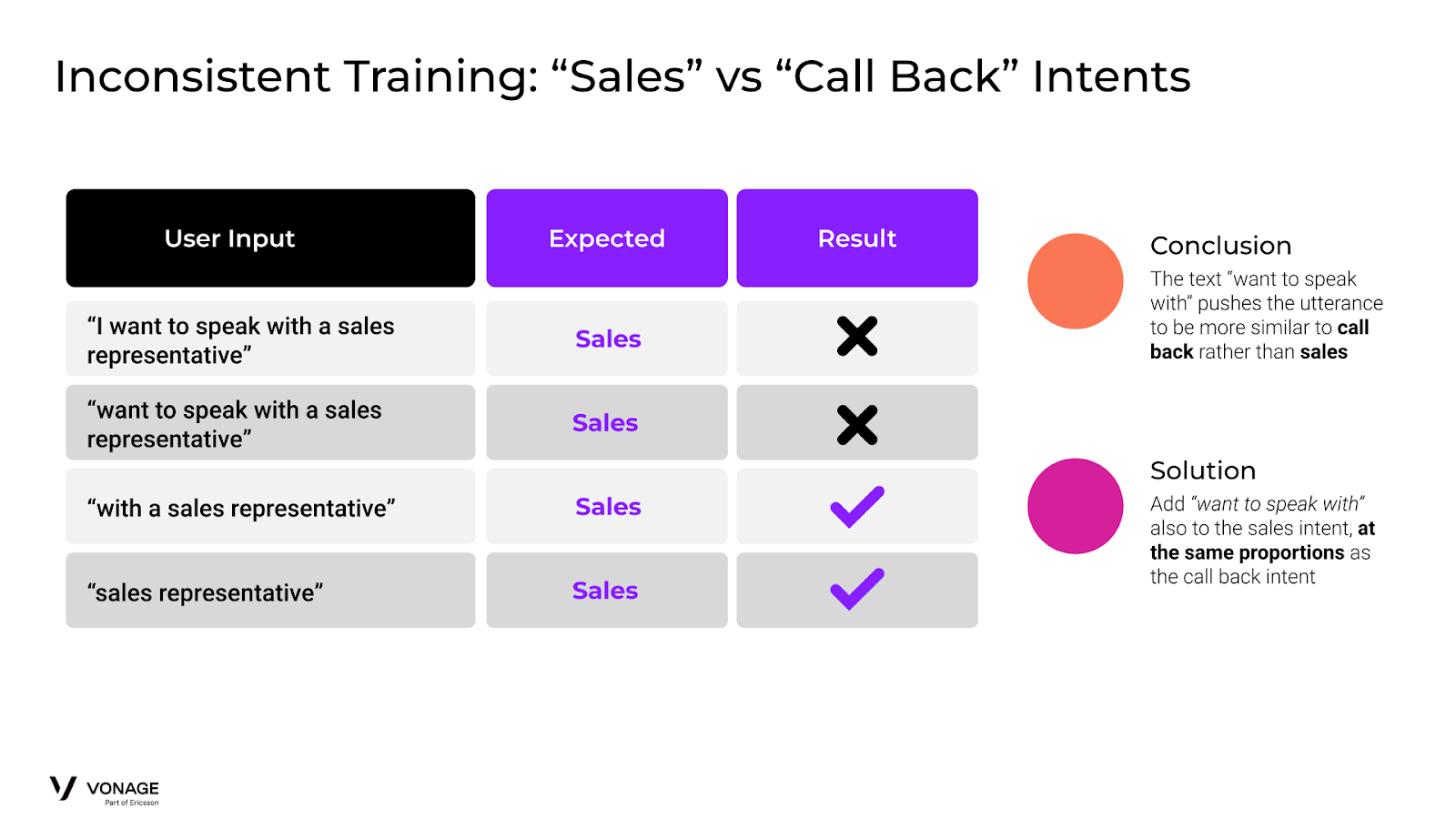 Inconsistent Training Example
Inconsistent Training Example
以下はすべて「売上高」に分類されると予想される:
営業担当者と話したい
営業担当者と話したい
営業担当者と
営業担当者
しかし、図にあるように、「want to speak with」を持つ最初の2つのユーザー入力は、結局「コールバック」に分類される。それは、"speak with "という単語がセールスよりもコールバックに近いからです。
解決策は、「営業」インテントに「話したい」を含むトレーニングデータを追加することです。これは、「コールバック」トレーニングセットの類似トレーニングデータのトレーニングデータと同じ割合でなければなりません。
より複雑なエージェントでは、この2つのインテントは他のインテントに比べて非常に似ているかもしれません。階層的な分類が、エージェントがこのようなきめ細かな区別ができるようになるのにどのように役立つかは、後ほど説明する。
インテントの重複を避けるためにインテントをサニタイズし、トレーニングセットを一貫性のあるものにすることは、クラシフィケーションを改善するための良いスタートです。そして、厄介なユーザは、私たちが望むように行動することはありません!
階層的分類は、一度に1つの変数またはトピックにのみ分類を集中させるために、分類のレベルを作成するので、このような大規模なエージェントに役立ちます。段階的に分類することで、エージェントは、最大の差別化要因によってインテントをグループに分類することが最も効果的です。最大の差別化によるグループ分けは、重複や曖昧さを排除するのに役立ちます。
段階に分類するのは簡単なように思えるかもしれないが、意図のグループ分けにはさまざまな方法があることがすぐにわかる。名詞でグループ化するか、動詞でグループ化するかである。
名詞は、ユーザが問い合わせる可能性のあるエージェント内の項目です。これらは、ユーザのリクエストの直接の対象であると考えてください。ほとんどの場合、これらはあなたのビジネスが提供する製品やサービスです。名詞の例としては、"レイトチェックアウト"、"バースデーパッケージ"、"1:1コンサルテーション "などがあります。
一方、動詞は名詞に対して誰かが取りたい行動である。予約する」、「予約をキャンセルする」、「予約を変更する」という顧客の要求の違いを考えてみよう。
銀行のシナリオを拡大するとしよう。ローンを提供するだけでなく、保険も提供したいと思います。保険については、ユーザーに「保険をリクエストする」、「保険状況を確認する」、「一般的な保険情報」というオプションも与えます。分類器は、たくさんの学習データからユーザーの入力を比較する必要があります。
これこそ、階層化がエージェントのパフォーマンスを向上させるシナリオです。最初のステップは、トピックをグループ化することです。この例では、トピックをグループ化する方法がいくつかあります。製品別またはサービス別にグループ化できます。
この図は、動詞でグループ分けする方法を示している:
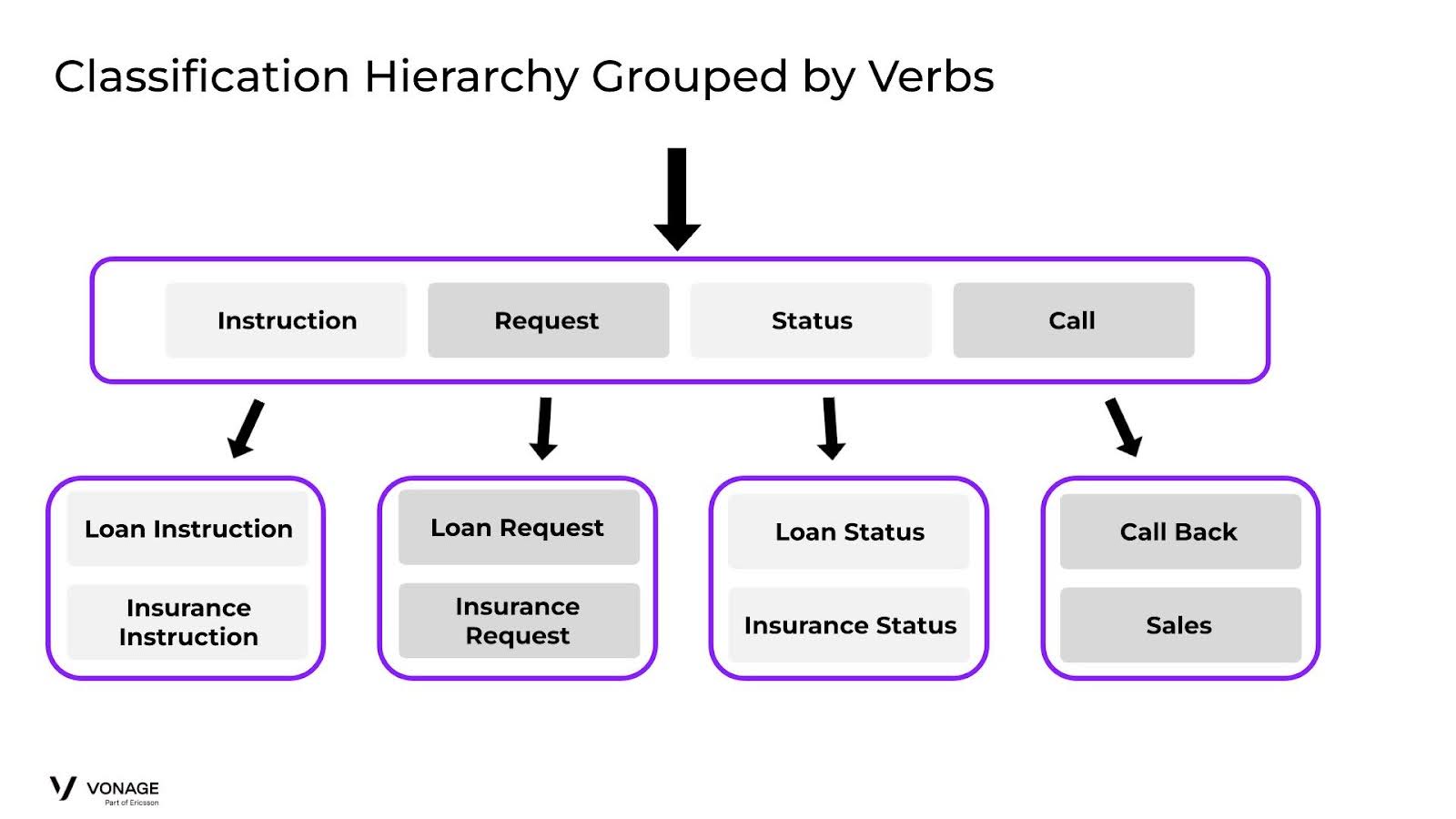 Hierarchy Grouped By Verbs
Hierarchy Grouped By Verbs
グループ分けは論理的に理にかなっており、最初の分類器は高い結果で通過するかもしれませんが、2段階目の分類ではどうなるでしょうか?先に見たように、ローン指示と保険指示のようなユーザー入力のようなものを比較する場合、曖昧性が高くなる可能性があるため、分類器は第2ラウンドで問題を抱えることになります。このような場合、トレーニングセットの重複が多くなり、データの一貫性を保つために細心の注意を払う必要があります。
では、インテントを名詞でグループ化するとどうなるか、試してみよう:
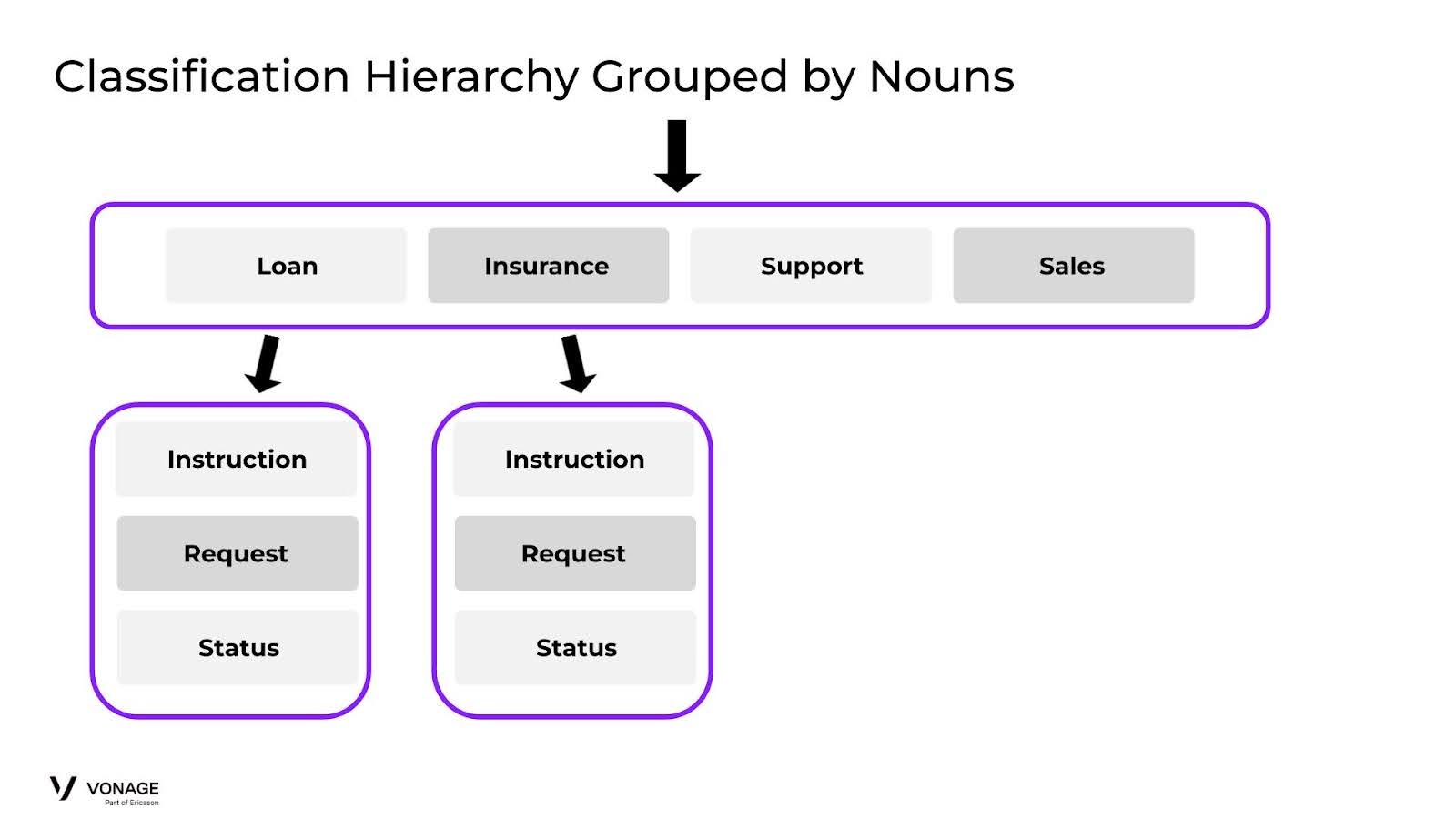 Hierarchy Grouped By Nouns
Hierarchy Grouped By Nouns
ここでわかることは、サポートとセールスを即座に区別するという複雑なレイヤーを取り除いただけでなく、より重要なことは、第2ラウンドで、より分類しやすいグループ分けを作ったということです。ローン」と「保険」の各グループでは、先ほどのように、各インテントがほとんど重複しないように絞り込むことができます。
理論を理解したところで、実践的なガイドに入ろう。
実世界のデータを持っているなら、それは素晴らしいことだ!ステップ2に進んで、中核となるトレーニングデータに集中し、異常値はとりあえず除外してください。
そうでなければ、ユーザーがフィラー言葉や不必要な余分な言葉を使わずに話していると想像してください。思いつく限りのユーザー表現を書き出してみましょう。これがあなたの理想とするトレーニングセットです。
御社の商品/オファーに対して考えられるすべての類義語を想像してみてください。
例:部屋/予約/予約/滞在
バンクのトピックを名詞を中心とした大まかなグループに整理したように、トピックも大まかな名詞/名詞句のカテゴリーに分類します。この時点で、補助動詞/動詞を特定し始めることができます。
現実の世界では、ユーザーは原始人のような行動をとる。彼らは非常に多くの場合、動詞よりも名詞で答える。名詞を中心にグループ化することで、より高いパフォーマンスを得ることができる。
曖昧性が高い可能性が最も高いのはどこか?曖昧性が高いケースでは、トレーニングデータを追加して、異なるグループ間で標準化し、統一されたフレーズを作成します。上記のセールスとコールバックの意向の例で見たように、曖昧性の高いグループのトレーニングデータを正規化します。
ほとんどのユースケースを解決した後でも、広い範囲のトピックに当てはまらないインテントがあることに気づくかもしれません。このような場合、どこに勘定すべきでしょうか?
これらの意向は、あなたのモデルによって否定される可能性が最も高い時点で追加する べきである。栄養士のエージェントがあり、インテントの1つが健康食品であるとします。しかし、ユーザが「ピザを注文できますか?モデルは、ピザがそこに行くべきでないにもかかわらず、ユーザーを "Healthy Foods "インテントにプッシュする可能性が高いです。図を見てください:
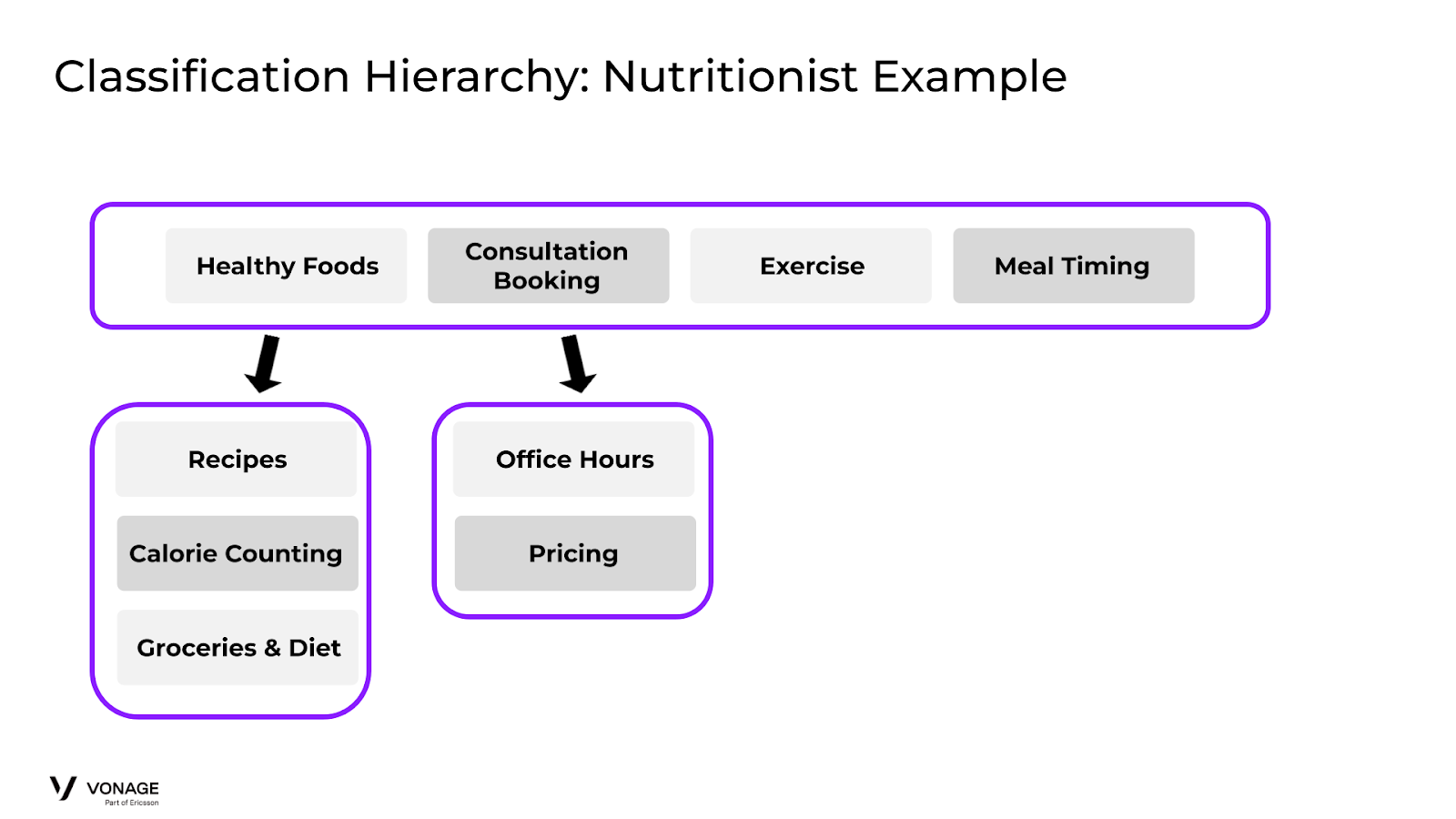 Classification Hierarchy: Nutritionist Example
Classification Hierarchy: Nutritionist Example
私たちの解決策は、デフォルトの行動を捕捉し、それに従ってルーティングするために、新しい「ネガティブ」インテントを作成することです。そこで、これらの「ネガティブ」なケースを捕捉し、適切なフローに誘導する「Unhealthy Foods」インテントを作成します。更新された分類
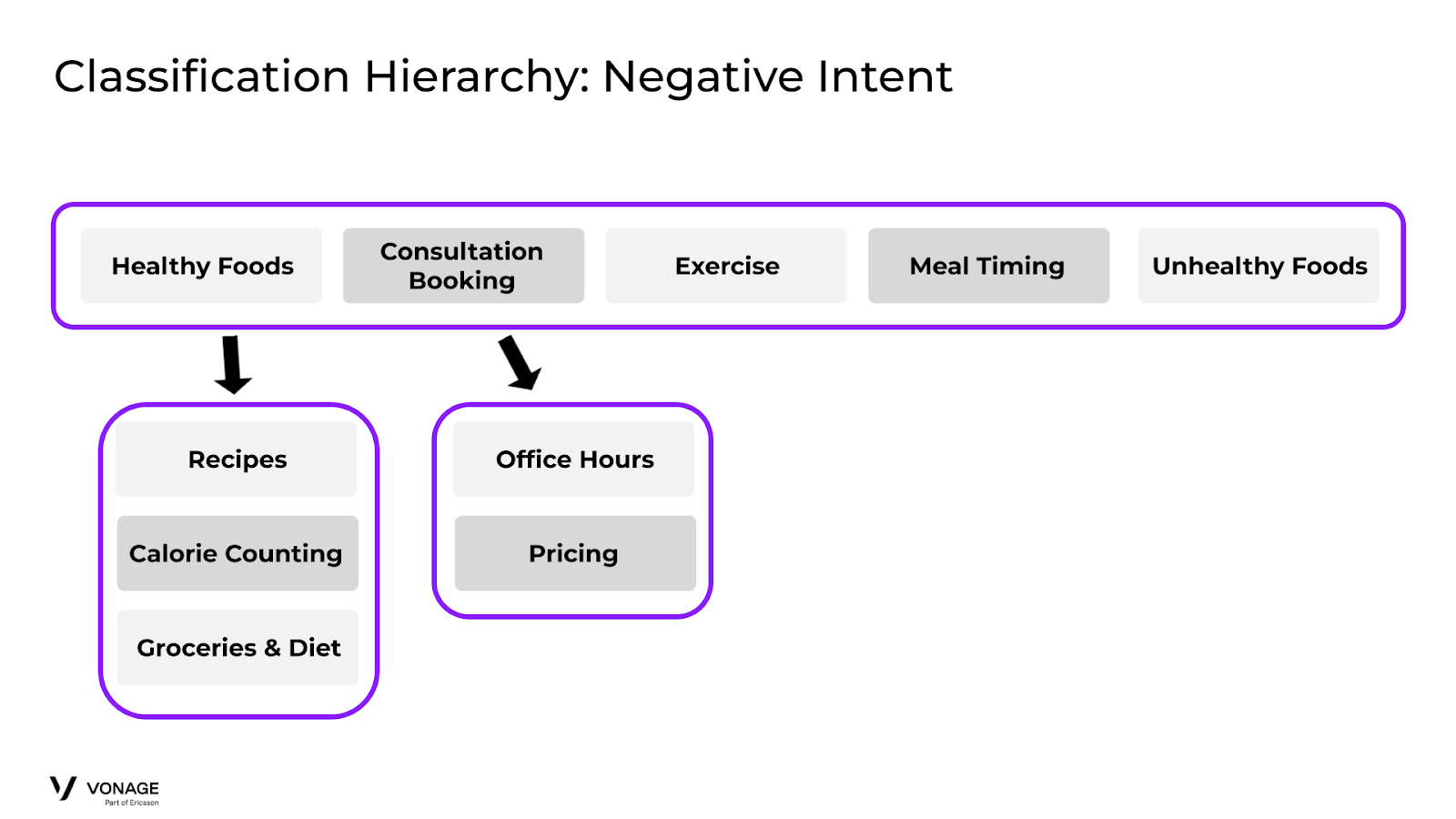 Classification Negative Intent Example
Classification Negative Intent Example
AI Studioは、ドラッグアンドドロップで簡単にエージェントを構築することができます。しかし、エージェントの規模が大きくなり始めると、数十から数百のノードを追跡することが非常に難しくなります。エージェントの構成が管理できなくなるだけでなく、ブラウザウィンドウで多数のノードを読み込む際に、Studioの動作が重くなります。
このような問題は、前もってエージェントを計画し、サブフロー機能を使用することで、回避することができます。 サブフロー機能.ベストプラクティスのために、各インテントは独自のサブフローを持つべきです。これらのサブフローは、それぞれトピックグループレベルで結合します。これらの各グループは、メインレベルまで流れます。作業を開始する前に階層的な分類を作成することで、サブフローの整理が容易になり、将来の技術的負債を防ぐことができます。
エージェントの最初のバージョンを作成した後、階層に「漏れ」があることに気づくかもしれません。少数のユーザが誤って間違ったフローに入ってしまうかもしれません。完璧な階層モデルを再設計するために頭を壊すのではなく、「流れに身を任せましょう!」。
例えば、あるホテルに「イーグルスネスト」と呼ばれるプレミアムレストランパッケージがあったとします。ユーザーは、それが「Eagles Nest」と呼ばれていることを知らないので、「ホテルのプレミアム・オファー」を尋ねるか、他の用語を使用します。ホテル用のトップレベル分類器とイーグルスネスト用のトップレベル分類器がありました。ホテル」用の学習データが多すぎたため、ユーザーからの問い合わせが「イーグルズ・ネスト」ではなく「ホテル」になってしまうことが多かったのです。そこで、エージェント全体を再設計する代わりに、Hotelにサブフローを追加し、Eagles Nestに戻します。最終的なエージェントでは、このサブフローは3つか4つの異なる場所に配置されます。
ユーザーがあまりにも単純な入力をすることに加え、多くの場合、詳細な質問ではなく、質問している主題を言います。これを処理し、ユーザーエクスペリエンスを向上させる素晴らしい方法は、最高レベルの分類で「キャッチ」インテントを作成することです。
例えば、「ドクター・スミスに手術の予約をしたいのですが」と言う代わりに、「予約の質問」や「手術の質問」と言う。
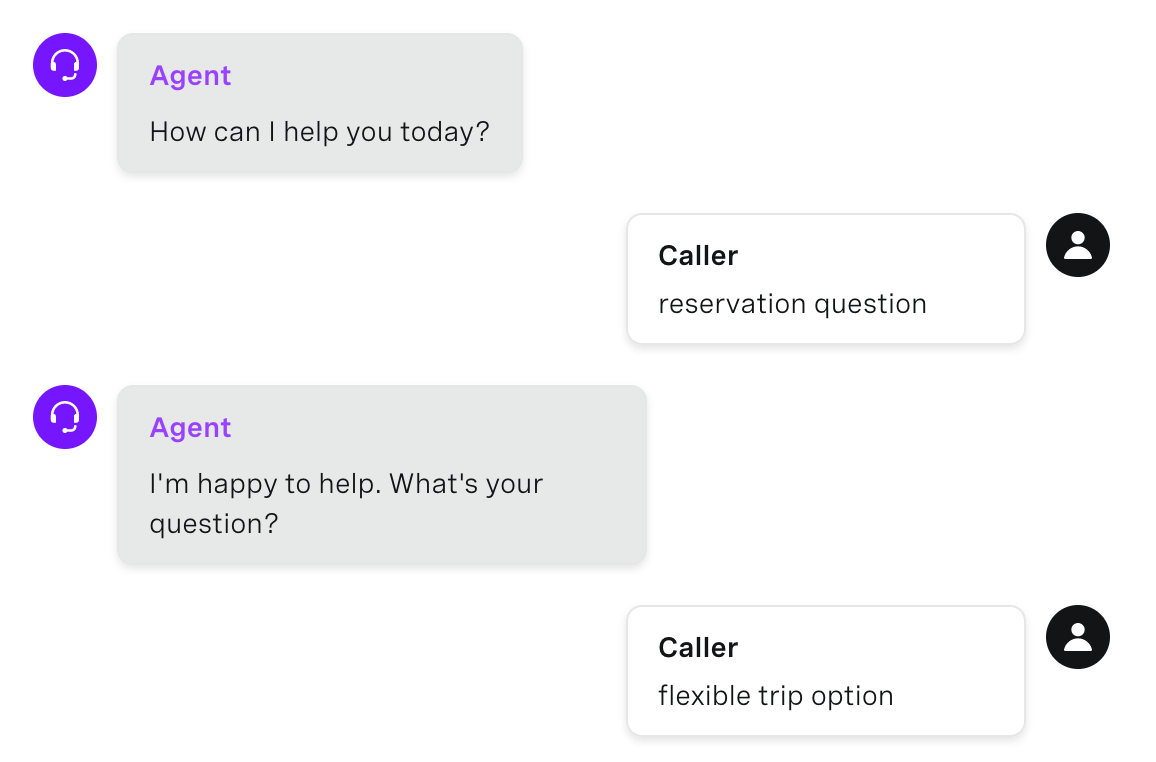 Question Deflection Example
Question Deflection Example
私たちは、質問に関する入力のためのこのシンプルなキャッチオールを追加することで、バーチャルエージェントが助けてくれるという自信をユーザーに持たせることができることを発見した。
会話AIエージェントにおける分類階層のパワーをご理解いただけたと思います!これらのステップを覚えて、あなたの会社のヒーローになりましょう:
トレーニングデータを見直す
データを整理し、曖昧性が高い可能性のある場所を特定する。
階層的な分類を作成する
ビルドアウト・エージェント
テスト、テスト、テスト
この記事をお楽しみいただけましたら、Vonage Developerまでお知らせください。 コミュニティSlack.この投稿は、コミュニティメンバーからの質問に触発されています!また X(旧 Twitterでフォローすることもできます。