
シェア:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.
ChatGPTでビデオ会議を強化:ライブAIアシスタントのご紹介
所要時間:1 分
テクノロジー、特に人工知能は、オンラインでの会話や仕事のやり方を変えました。世界がウェビナーや会議、1対1のミーティングなどオンラインでの交流にますますシフトする中、こうしたバーチャルな集まりの生産性を高めるツールの必要性は否定できない。
想像してみてほしい。バーチャルな待ち合わせの間、AIアシスタントがあなたのそばにいて、問い合わせに答えたり、行動項目のメモをとったり、必要な情報を簡潔に要約してくれたりする。今日、私たちは主に1対1の会話に焦点を当て、そのようなアシスタントを作っている。しかし、このコンセプトは多くのシナリオに適用できるため、可能性は無限大だ。それでは早速、"Sushi "を作ってみよう!
デモビデオをご覧ください:
A Vonage API アカウント.Vonage APIダッシュボードにアクセスし、APIキーとAPIシークレットをご確認ください。
(英語) OpenAIアカウントおよびAPIシークレット
ノード 16.20.1+
npm
あなたのマシンでアプリをセットアップするには、まずレポをクローンする。
git clone https://github.com/hamzanasir/vonage-openai-demo次にリポジトリに移動し、関連するパッケージをインストールする:
npm install次に、Vonage API KeyとSecretをセットアップする必要がある。.envテンプレートをコピーすることから始めよう:
cp .envcopy .envあとは.envファイルのAPI KeyとSecretをあなたの認証情報に置き換えるだけです。API Key と Secret は、Vonage Video API Account のプロジェクトページ (https://tokbox.com/account)..env ファイルは以下のようになります:
# enter your TokBox API key after the '=' sign below
TOKBOX_API_KEY=your_api_key
# enter your TokBox api secret after the '=' sign below
TOKBOX_SECRET=your_project_secretまた、OpenAIのプロジェクトを作成する必要があります。これは https://platform.openai.com/signup.サインアップしたら、API Keys セクションに行き、新しいシークレットキーを作成します。
.envファイルに秘密鍵を貼り付ける。
# enter your OpenAI Secret after the '=' sign below
OPENAI_SECRET=your_openai_secretこれでアプリを起動できる:
npm start今すぐ http://localhost:8080/.スシとの会話を開始するには、左下のキャプション開始ボタンを押して、Vonage のライブ・キャプション・サービスを開始してください。スシの声がパブリッシャーのマイクにフィードバックされないように、ヘッドフォンを装着してください。
このブログで説明するコードはすべて public/js/app.jsファイルにあります。ライブ・キャプションがどのように動作するのか興味がある方は、ぜひ routes/index.jsファイルをチェックして、キャプション・サービスがどのように開始・停止するのかを確認してください。
バーチャル・アシスタントの内部構造を把握するために、そのアーキテクチャーの枠組みを掘り下げてみよう。
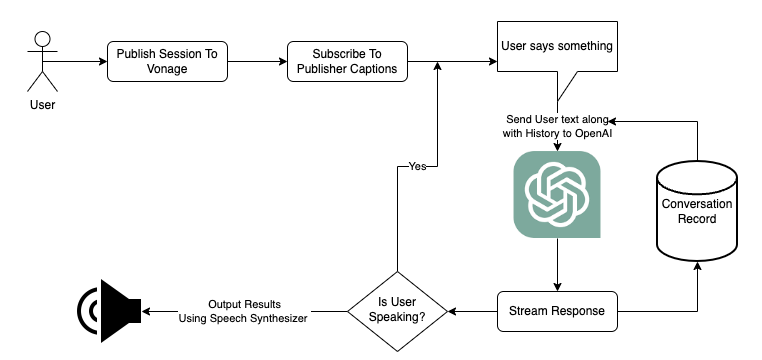
このセットアップの中心にあるのは、OpenAIのAPIを使ったユーザーの会話とインタラクションの管理です。私たちは会話の処理に優れたOpenAIのGPT-3.5 Turboモデルを選択しました。しかし、OpenAIはあなたの特定のプロジェクトの目標に合わせて様々なモデルを提供しています。
GPTにリクエストを送ると、応答を作成するのに時間がかかる。もっとダイナミックなアプローチをとりましょう。データを生成しながらストリーミングすることで、より速く、より自然な会話体験を保証します。このアプローチでは、ユーザーが会話に割り込んで誘導することもでき、現実のやり取りを模倣することができます。
GPTが回答を作成する際、生成されたテキストを音声合成ソフトを使って音声に変換します。この目的のために、より自然に聞こえる音声を提供できる有料のサードパーティ製音声合成ソフトなど、さまざまなオプションが利用可能です。私たちのプロジェクトでは、ブラウザのネイティブSpeechSynthesisUtteranceモジュールを選択しました。ユーザーの発話による中断を管理するために、ブラウザのAbortControllerを使用します。
私たちのシステムにおいて極めて重要な要素であるキャプション・サービスをどのように開始し、管理しているのかを見てみましょう。
物事を始めるために、/captions/startのPOSTでサーバを呼び出し、セッションIDを提供することで、キャプションサービスを起動します。このセットアップで、セッション内のすべての購読者のキャプションを受け取る準備ができました。しかし、パブリッシャとして自分自身のキャプションも生成したいのです。これを実現するために、自分のパブリッシャーにゼロボリュームでサブスクライブし、自分のVoiceが繰り返されないようにします。
これを実現するコードの一部を紹介しよう:
const publisherOptions = {
insertMode: 'append',
width: '100%',
height: '100%',
publishCaptions: true,
};
publisher = OT.initPublisher('publisher', publisherOptions, (err) => {
if (err) {
handleError(err);
} else {
session.publish(publisher, () => {
if (error) {
console.error(error);
} else {
const captionOnlySub = session.subscribe(
publisher.stream,
document.createElement('div'),
{
audioVolume: 0
},
);
speakText(greetingMessage);
captionOnlySub.on('captionReceived', async (event) => {
if (event.isFinal) {
stopAiGenerator();
startAiGenerator(event.caption)
}
});
}
});
}
});
このコードでは、オーディオと Video をセッションにパブリッシュし、同じインスタンスにサブスクライブしてキャプションを受け取ります。この処理をシームレスに行うために、モックサブスクライバーに 'captionReceived' イベントハンドラをアタッチします。このイベントハンドラは、私たちの発話をキャプチャします。このイベントは通常、話しているときに定期的にトリガーされるので、いつ話し終わったかを識別するために 'isFinal' ブール値を使用します。生成されたテキストの準備ができたら、さらなる処理のためにstartAiGeneratorに渡します。
私たちのロジックのバックボーンはstartAiGenerator関数の中にある。それは重い関数なので、管理しやすい断片に分解してみよう。まず、APIコールを行うためのロジックを詳しく見てみよう:
async function startAiGenerator(message) {
let aiText = '';
let utterableText = ''
abortController = new AbortController();
const userMessage = {
'role': 'user',
'content': message
}
const reqBody = {
messages: [...messages, userMessage],
temperature: 1,
max_tokens: 256,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
model: 'gpt-3.5-turbo',
stream: true
};
try {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
headers: {
'Authorization': `Bearer ${openAISecret}`,
'Content-Type': 'application/json',
},
body: JSON.stringify(reqBody),
method: 'POST',
signal: abortController.signal
});このスニペットでは、aiTextとutterableTextという2つの変数を持っています。aiTextはクエリに対する完全な応答を格納し、utterableTextはOpenAIから受信したデータの読み取り可能なストリームから、最後の完全な文またはフレーズをキャプチャします。また、アシスタントが話している間のユーザーの中断を処理するために、AbortControllerインスタンスをセットアップします。AIジェネレーターを開始する前に、別の関数stopAiGenerator()が呼び出され、進行中のAI生成プロセスを停止する。
function stopAiGenerator() {
if (abortController) {
abortController.abort();
abortController = null;
}
window.speechSynthesis.cancel();
}最後に、グローバルメッセージ配列に保存された会話の履歴を使ってOpenAIを呼び出します。それでは、OpenAIからどのようにデータをストリーミングするか見てみましょう:
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
while (true) {
const chunk = await reader.read();
const { done, value } = chunk;
if (done) {
break;
}
const decodedChunk = decoder.decode(value);
const lines = decodedChunk.split('\n');
const parsedLines = lines
.map(l => l.replace(/^data: /, '').trim())
.filter(l => l !== '' && l !== '[DONE]')
.map(l => JSON.parse(l));
for (const line of parsedLines) {
const textChunk = line?.choices[0]?.delta?.content;
if (textChunk) {
utterableText += textChunk
if (textChunk.match(/[.!?:,]$/)) {
speakText(utterableText);
utterableText = '';
}
aiText += textChunk;
}
}
}
このセグメントでは、GPTをリクエストするために使用したフェッチ・オブジェクトからリー ダーを開始します。whileループを使って、ストリームが枯渇するまで継続的に読み込みます。テキストの各チャンクについて、先に定義した2つの変数に追加します。チャンクに句読点が含まれる場合、speakText()関数をトリガーし、生成された最新の文またはフレーズを発声し、utterableTextを空文字列にリセットします。この処理は、AbortController からの stop シグナルを使用することで、いつでも停止させることができることを覚えておいてください。
最後に、ストリームを終了させるか完了させるかにかかわらず、ユーザーの入力とOpenAIの応答を以下のように保存します:
messages.push(userMessage);
messages.push({
content: aiText,
role: 'assistant'
})
自然言語処理における「プロンプト・エンジニアリング」とは、AIモデルを導くための指示や質問を作成することである。これは、特定の結果を達成するために、明確さと曖昧さの間の適切なバランスを見つけることです。適切なプロンプト・エンジニアリングによって、スシを模擬的な法律アドバイザー、医療専門家、生意気な友人などに変えることができる。このデモでは、このプロンプトを使っています:
const messages = [
{
'role': 'system',
'content': "You are a participant called Sushi in a live call with someone. Speak concisely, as if you're having a one-on-one conversation with someone. " // Prompt engineering for AI assistant
}
];アシスタントの動作を確認するために、このコードの内容を変更してみてください!
このセクションには柔軟性の余地がある。より自然で高度な音声合成ソリューションを選択することができます。これらのほとんどは有償となるため、このデモではブラウザのデフォルトのSpeechSynthesisUtterance機能を選択しています。
function speakText(text) {
let captions = '';
const utterThis = new SpeechSynthesisUtterance(text);
utterThis.voice = voices.find((v) => v.name.includes('Samantha'));
utterThis.onboundary = (event) => {
captions += `${event.utterance.text.substring(event.charIndex, event.charIndex + event.charLength)} `;
displayCaptions(captions, 'ai-assistant');
};
utterThis.onstart = () => {
animateVoiceSynthesis();
};
utterThis.onend = function() {
stopAnimateVoiceSynthesis();
};
window.speechSynthesis.speak(utterThis);
}
そこでまず、発話したいテキストでSpeechSynthesisUtteranceモジュールを初期化する。その後、ブラウザから利用可能なVoiceを設定する必要がある。これらはこのように非同期に読み込まれる:
let voices = window.speechSynthesis.getVoices();
if (speechSynthesis.onvoiceschanged !== undefined)
speechSynthesis.onvoiceschanged = updateVoices;
function updateVoices() {
voices = window.speechSynthesis.getVoices();
}私たちは オンスタートと onendイベントを使って、中央のバーをアニメーションさせ、スシがいつ話しているかを示している。さらに、onboundaryイベントを使用して、音声合成が話している単語を表示するテキスト・キャプションを挿入します。
重要なことは、これはGPTとの統合でできることの一例に過ぎないということです。このデモの目的は、次のパイプラインを作成する方法を示すことです。 VonageビデオライブキャプションとOpenAIの間のパイプラインをどのように作ることができるかを示すことです。
GPT GPTの例のサンプルセクションをご覧ください。私たちは、あなたがどんな作品を作るのか楽しみでなりません!
Vonage Video APIを使って何を作っているかお知らせください。私たちの VonageコミュニティSlack または X、旧 Twitter、 @VonageDev.
シェア:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.