
機械検知に答えるための機械学習モデルの構築
所要時間:1 分
留守番電話が音声通話中であることを検知する方法が必要だったことはありますか?ないですか?大丈夫です。私はした!
この投稿は、あなたがPythonの基本的な経験を持ち、機械学習のごく基本的な理解を持っていることを前提としています。機械学習に関するいくつかの基本的な概念について説明し、この投稿を通してより多くのリソースにリンクしています。
数週間前、あるセールス・エンジニアから、あるクライアントの留守番電話検知サービスについての依頼を受けた。彼らは、電話がボイスメールになったときに留守番電話にメッセージを送る方法を求めていた。
このことについて少し調べてみたが、可能なようだ。そこで、私はそれを解明することにした...。
最初に考えたのは、留守番電話の音がいつ聞こえたかを検出する機械学習モデルを構築することだった。 beepを検出する機械学習モデルを構築することだった。この投稿では、このモデルがどのように学習され、アプリケーションに導入されたかを説明します。
機械学習モデルの構築を始める前に、いくつかのデータが必要だ。この問題では、留守番電話の音声ファイルが必要だ。 beepを用意する必要がある:
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4またはこれ:
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4
ビープ音を含まないサンプルも必要だ:
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4
このようなデータはインターネット上には存在しないようなので、モデルを訓練するために、通話中のビープ音などのサンプルをできるだけ多く集める必要があった。そのために、誰でもボイスメールの挨拶メッセージを録音できるウェブページを作った。
Vonage番号に電話をかけると、アプリケーションは同じ番号への発信を作成します。着信したら、その通話を直接ボイスメールに送るだけです。そこから recordアクションを使って通話を録音し、ファイルをGoogle Cloud Storageバケットに保存します。たくさんの例を集めたら、データを見始めることができる。
どんな機械学習プロジェクトでも、最初にやるべきことのひとつは、データを見て、それが使えるものであることを確認することだ。
オーディオなので、私たちは 直接見ることはできないがしかし、mel-spectrogramを使ってオーディオファイルを視覚化することができる:
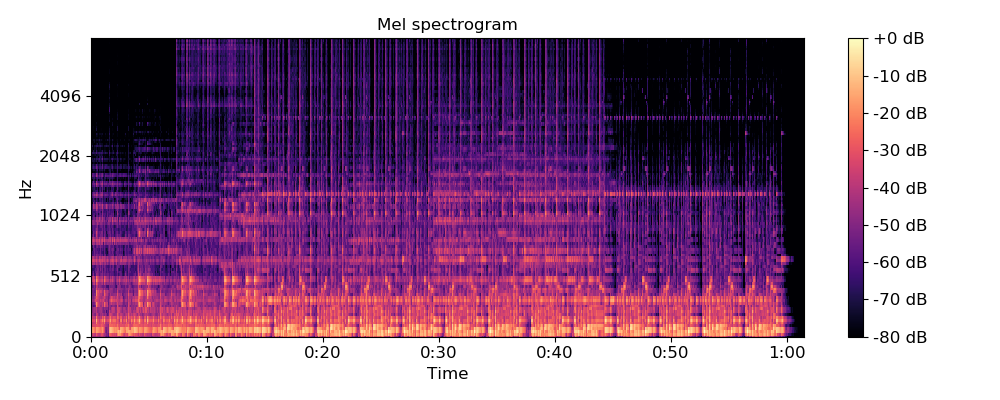
メル・スペクトログラムは、周波数の範囲を表示し(ディスプレイの一番下が最も低く、一番上が最も高い)、異なる周波数でのイベントの大きさを示します。一般的に、大きな音は明るく、静かな音は暗く表示されます。
両方のタイプの音のファイルをいくつか読み込んで、プロットし、どのように見えるかを確認する必要があります。mel-spectrogramを表示するには、Pythonパッケージの LibrosaというPythonパッケージを使って録音された音声を読み込みます。 matplotlibを使ってプロットします。
import glob
import librosa
import matplotlib.pyplot as plt
%matplotlib inline
def plot_specgram(file_path):
y, sr = librosa.load(file_path)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128,fmax=8000)
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.power_to_db(S,ref=np.max),y_axis='mel', fmax=8000,x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title(file_path.split("/")[-2])
plt.tight_layout()
sound_file_paths = [
"answering-machine/07a3d677-0fdd-4155-a804-37679c039a8e.wav",
"answering-machine/26b25bb7-6825-43e7-b8bd-03a3884ed694.wav",
"answering-machine/2a685eda-8dd9-4a4d-b00e-4f43715f81a4.wav",
"answering-machine/55b654e5-7d9f-4132-bc98-93e576b2d665.wav",
"speech-recordings/110ac98e-34fa-42e7-bbc5-450c72851db5.wav",
"speech-recordings/3840b850-02e6-11e9-aa3d-ad1a095d8d72.wav",
"speech-recordings/55b654e5-7d9f-4132-bc98-93e576b2d665.wav",
"speech-recordings/81270a2a-088b-4e3c-9f47-fd927a90b0ab.wav"
]
for file in sound_file_paths:
plot_specgram(file)それぞれのオーディオファイルがどんなものか見てみよう。
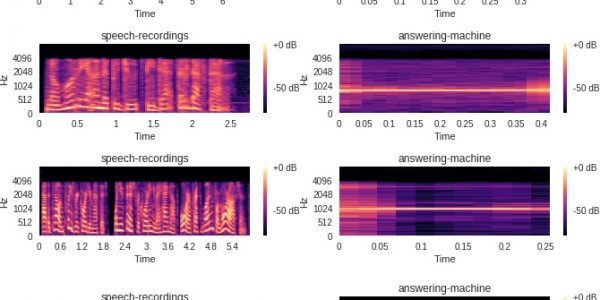
どのオーディオファイルが beepであり speech.
モデルを訓練する前に、以下の両方の録音をすべて取る。 beepsとラベル付けされている。 speechこのモデルは画像ではなく数値のみを受け付けるので、各記録を数値のベクトルに変換する。
データを計算するには メル周波数セプストラル係数 (MFCC)を使います。そして、この値をcsvに保存し、MFCCの計算をやり直さないようにする。
各オーディオサンプルについて、csvはオーディオサンプルへのパス、オーディオサンプルのラベル(beepまたは speech)、MFCC、オーディオサンプルの時間(librosaの get_durationの関数を使用)。).また、彩度を含む他のいくつかのオーディオ特性も試しました、 コントラストとtonnetz)も試した。しかし、これらの機能はモデルの最新バージョンでは使用されていません。
csvの最初の5行を見てみよう。
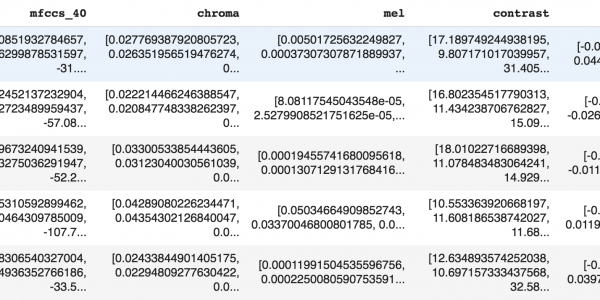
各行には、各オーディオ特徴の1次元ベクトルが含まれます。これをモデルの学習に使います。
では、このデータを使ってモデルをトレーニングしてみよう。学習にはScikit-learnパッケージを使用します。 Scikit-learnは、機械学習の専門家でなくても簡単な機械学習モデルを構築できる素晴らしいパッケージです。
各モデルについて、各音声ファイルのラベルを含むデータフレーム(beep, speech)と各サンプルのMFCCを含むデータフレームを取得し、それをtrainデータセットとtestデータセットに分割し、各モデルをデータを通して実行した。
def train(features, model):
X, y = generateFeaturesLabels(features)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
model.fit(X_train, y_train)
print("Score:",model.score(X_test, y_test))
cross_val_scores = cross_val_score(model, X, y, cv=5, scoring='f1_macro')
print("cross_val_scores:", cross_val_scores)
print("Accuracy: %0.2f (+/- %0.2f)" % (cross_val_scores.mean(), cross_val_scores.std() * 2))
predictions = model.predict(X_test)
cm = metrics.confusion_matrix(y_test, predictions)
plot_confusion_matrix(cm, class_names)
return model関数 trainは、使用したい特徴量のリスト(オーディオサンプルのMFCCと、学習したいモデル)を受け取ります。そしてスコアが表示されます。また、クロスバリデーションのスコアも表示します。これにより、モデルが正しくトレーニングされたことが確認できます。この plot_confusion_matrix関数は混同行列をプロットします。
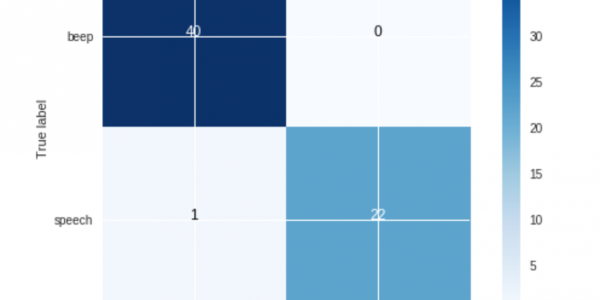
次に、以下のモデルを試し、その精度(モデルの出来を0~100%のスコアで表す)を記載した。
ランダムフォレスト分類器97%の精度
ロジスティック回帰96%の精度
サポートベクターマシン84%の精度
ガウス・ナイーブ・ベイズ98%
サポート・ベクトル・マシンを除いて、これらのモデルはすべて非常に良い結果を示した。最も優れていたのはGaussian Naive Bayesでしたので、このモデルを使用します。上のコンフュージョン・マトリックスでは、67のサンプルのうち、"a "と予測された40のサンプルが、実際には "b "であった。 beepと予測された40のサンプルは実際には beepsと予測された22のサンプルは、実際には speechであった、 speechの例であった。しかし、a と予測された1つのサンプルは、実際にはaであった。 beepであった。 speech.
モデルができたら、それをファイルに保存し、このモデルをVAPIアプリケーションにインポートする必要があります。
import pickle
filename = "model.pkl"
pickle.dump(model, open(filename, 'wb'))
最後の部分は、私たちのモデルをVAPIアプリケーションに統合することです。
ユーザーがVonageの番号にダイヤルできるアプリケーションを作ります。そして、ユーザーに電話番号を入力してもらいます。電話番号が入力されたら、その通話を現在の会話に接続し、ウェブソケットに接続します。使用方法 Vonageウェブソケットを使用することで、音声通話をアプリケーションにストリーミングすることができます。
まず、モデルをアプリケーションにロードする必要がある。
loaded_model = pickle.load(open("models/model.pkl", "rb"))ユーザーが最初にVonageの番号にダイヤルすると を返します。を返します:
class EnterPhoneNumberHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
ncco = [
{
"action": "talk",
"text": "Please enter a phone number to dial"
},
{
"action": "input",
"eventUrl": ["https://3c66cdfa.ngrok.io/ivr"],
"timeOut":10,
"maxDigits":12,
"submitOnHash":True
}
]
self.write(json.dumps(ncco))
self.set_header("Content-Type", 'application/json; charset="utf-8"')
self.finish()まず 音声合成アクションアクションを送信します。電話番号が入力されると、その数字を https://3c66cdfa.ngrok.io/ivrurlから取得します。
class AcceptNumberHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def post(self):
data = json.loads(self.request.body)
ncco = [
{
"action": "connect",
"eventUrl": ["https://3c66cdfa.ngrok.io"/event"],
"from": NEXMO_NUMBER,
"endpoint": [
{
"type": "phone",
"number": data["dtmf"]
}
]
},
{
"action": "connect",
"eventUrl": ["https://3c66cdfa.ngrok.io/event"],
"from": NEXMO_NUMBER,
"endpoint": [
{
"type": "websocket",
"uri" : "ws://3c66cdfa.ngrok.io/socket",
"content-type": "audio/l16;rate=16000"
}
]
}
]
self.write(json.dumps(ncco))
self.set_header("Content-Type", 'application/json; charset="utf-8"')
self.finish()電話番号が入力された後、私たちはURLからコールバックを受け取ります。 https://3c66cdfa.ngrok.io/ivrurlからコールバックを受け取ります。ここでは、ユーザが入力した電話番号を data["dtmf"]から入力された電話番号を受け取り 接続アクションを実行し、別のコネクトアクションをウェブソケットに実行します。これで、websocketは通話を聞くことができるようになりました。
通話がウェブソケットにストリーミングされるので、Voice Activity Detectionを使って音声のチャンクをキャプチャし、waveファイルに保存し、学習したモデルを使ってそのwavファイルで予測を行う必要がある。
class AudioProcessor(object):
def __init__(self, path, rate, clip_min, uuid):
self.rate = rate
self.bytes_per_frame = rate/25
self._path = path
self.clip_min_frames = clip_min // MS_PER_FRAME
self.uuid = uuid
def process(self, count, payload, id):
if count > self.clip_min_frames: # If the buffer is less than CLIP_MIN_MS, ignore it
fn = "{}rec-{}-{}.wav".format('', id, datetime.datetime.now().strftime("%Y%m%dT%H%M%S"))
output = wave.open(fn, 'wb')
output.setparams((1, 2, self.rate, 0, 'NONE', 'not compressed'))
output.writeframes(payload)
output.close()
self.process_file(fn)
self.removeFile(fn)
else:
info('Discarding {} frames'.format(str(count)))
def process_file(self, wav_file):
if loaded_model != None:
X, sample_rate = librosa.load(wav_file, res_type='kaiser_fast')
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
X = [mfccs]
prediction = loaded_model.predict(X)
if prediction[0] == 0:
beep_captured = True
print("beep detected")
else:
beep_captured = False
for client in clients:
client.write_message({"uuids":uuids, "beep_detected":beep_captured})
else:
print("model not loaded")
def removeFile(self, wav_file):
os.remove(wav_file)
wavファイルを入手したら librosa.loadを使ってファイルを読み込み、次に librosa.feature.mfcc関数を使ってサンプルのMFCCを生成する。次に loaded_model.predict([mfccs])を呼び出して予測を行います。この関数の出力が 0, a beepが検出されました。もし出力が 1であれば speech.が検出されたかどうかと、会話のuuidsのJSONペイロードを生成する。 beepが検出されたかどうかと、会話のuuidsのJSONペイロードを生成する。このようにして、クライアント・アプリケーションは、uuidsを使用して、通話にTTSを送信できる。
最後のステップは、ウェブソケットに接続し、ビープ音が検出されたときを観察し、ボイスメールが検出されたときに通話にTTSを送信するクライアントを構築することである。
まず、ウェブソケットに接続する必要がある。
ws = websocket.WebSocketApp("ws://3c66cdfa.ngrok.io/socket",
on_message = on_message,
on_error = on_error,
on_close = on_close)
ws.on_open = on_open
ws.run_forever()次に、ウェブソケットからの着信メッセージをリッスンする。
def on_message(ws, message):
data = json.loads(message)
if data["beep_detected"] == True:
for id in data["uuids"]:
response = client.send_speech(id, text='Answering Machine Detected')
time.sleep(4)
for id in data["uuids"]:
try:
client.update_call(id, action='hangup')
except:
pass<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-confusion-matrix.png"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-confusion-matrix-600x300.png" alt="" width="300" height="150" class="alignnone size-medium wp-image-28012" /></a>
<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-df.png"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-df-600x300.png" alt="" width="300" height="150" class="alignnone size-medium wp-image-28015" /></a>
<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-eda.jpg"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-eda-600x300.jpg" alt="" width="300" height="150" class="alignnone size-medium wp-image-28018" /></a>
受信メッセージをJSONとしてパースし、次に beep_detectedプロパティが True.であれば beepが検出されたことになる。次に、「留守番電話が検出されました」というTTSを通話に送り、それから hangupアクションを実行する。
の音声サンプルを使って、96%の精度で留守番電話検出モデルを構築した方法を紹介した。 beepsと speechの音声サンプルを使って、96%の精度で留守番電話検出モデルを構築した方法を紹介しました。うまくいけば、あなたのプロジェクトで機械学習をどのように使うことができるかを示すことができたと思います。お楽しみください!