シェア:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.
Vonage Video APIによる注意検出
所要時間:1 分
この記事は以下の協力により執筆された。 タルハ・アフサン
現代社会では、オンラインでの交流がますます増えている。ここ数年で、オンライン授業やミーティングは普通の生活の一部となった。この移行には多くの利点がある一方で、取り組むべき興味深い問題も生じている。そのひとつが、ユーザーの注目度の確保である。
注意検出技術を使えば、教育分野やオンライン会議のような分野に大きな影響を与えることができる。プレゼンターは、会議や講義のある部分において、参加者の関心がどのように変化するかを理解することができる。また、教師が生徒の注意力を確認するのにも利用できる。
今日は、Vonage Video APIを使って、顔ランドマーク検出を利用して参加者のアテンション・スコアを計算するビデオ会議アプリケーションを作ります。
あなたのマシンでアプリをセットアップするには、まずレポをクローンする:
git clone https://github.com/hamzanasir/attention-detection.git
素晴らしい!リポジトリに移動して、関連するパッケージをインストールしよう:
npm install
ここでVonage API KeyとSecretをセットアップする必要がある。まずはenvテンプレートをコピーしましょう:
cp .envcopy .env
あとは TOKBOX_API_KEYと TOKBOX_SECRETをあなたの認証情報に置き換えるだけです。API Key と Secret は Video API のプロジェクトページにあります。 アカウント.
でアプリを起動できる:
npm start
このブログで説明するコードはすべて、`public/js/app.js`ファイルにある。
ユーザーの注意を計算するためには、まず3次元空間でユーザーの顔のランドマークを取得する必要があります。具体的には、三角法を使ってユーザーの顔のヨー、ピッチ、ロール(下図参照)を計算します。簡単のため、ここではヨーとピッチのみに注目します。
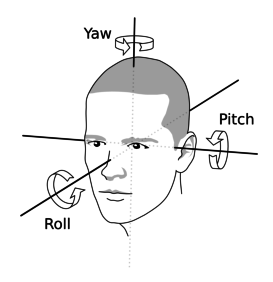 The yaw, pitch and roll angles in the human head motion
The yaw, pitch and roll angles in the human head motion
この2つの角度から、ユーザーに総合的なアテンション・スコアを提供することができる。
TensorFlowのMediaPipeを使用する。 顔検出モードを使用します。MediaPipeを使用する理由は、深度センサーを必要とせずに、機械学習を使って顔の表面の深さを推測し、3次元のランドマークをすぐに提供してくれるからです。
 Face landmarks visualization from MediaPipe
Face landmarks visualization from MediaPipe
MediaPipeの詳細については こちら
ピッチを計算するために、468個の顔ランドマーク(顔メッシュライブラリ)を使用します。同様に、ヨーについては、xおよびz平面におけるユーザーの目の外側の角に対応するランドマークを使用します。
この2つの点について、その2点間の中間点を計算し、ユーザーのカメラに対する角度を atan2(逆正接)関数を使ってユーザーのカメラに対する角度を計算します。以下にコード例を示します:
const radians = (a1, a2, b1, b2) => Math.atan2(y: b2-a2, x: b1-a1);
const angle = {
yaw: radians(mesh[33][0], mesh[33][2], mesh[263][0], mesh[263][2]),
pitch: radians(mesh[10][1], mesh[10][2], mesh[152][1], mesh[152][2])
};
ここで、算出したピッチとヨーを使って、ユーザーに何らかのアテンション・スコアを割り当てる必要がある。我々のケースで使用するアプローチは、"Attention Span Prediction Using Head-Pose Estimation With Deep Neural Network "に影響を受けている。ディープ・ニューラル・ネットワークによる頭部姿勢推定を用いた注意持続時間の予測", IEEE Accessに掲載された。
基本的には、各角度の計算値に基づいて0~2(0は注目度が低く、2は注目度が高い)のスコアを割り当てる。スコアは、IEEE Accessの論文 getScore関数を使用する:
const getScore = (degree) => {
degree = Math.abs(radiansToDegrees(degree));
if (degree < 10) {
return 2;
}
if (degree < 30) {
const adjust = (degree - 10) * 0.05;
return 2.0 - adjust;
}
return 0;
};
そして、2つのスコアの積をとり、ユーザーの最終的なアテンションスコアを出します。総合的な注意力のスコアが出たら、次に、ユーザーが自分の注意力のレベルを簡単に視覚化できるように、注意力を分類します。私たちはこの分類を、集中力なしから集中力ありまでの4つのカテゴリーに分けます。総合的な注意レベルを計算する手順をご覧いただけます:
 Pseudocode for our function to evaluate concentration level.
Pseudocode for our function to evaluate concentration level.
そして、気配りのカテゴリーは以下の通り:
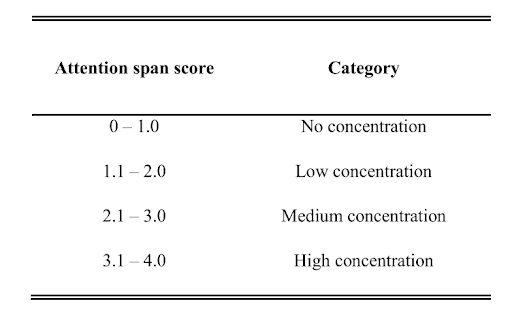 Attention score categorization
Attention score categorization
これらの図は、注意力スコアを計算するための理論的アルゴリズムを表していることに注意することが重要です。現実には、注意力スコアのカテゴリーなど、いくつかの点を微調整したいと思うかもしれません。私たちのアプリケーションで行ったそのような変更の1つは、注目度スコアのカテゴリに yaw_scoreと pitch_scoreを足し算するのではなく、掛け算にしたことです。
各参加者のCPU/GPUを節約するために、各参加者が自分のマシンで各参加者の顔メッシュ分析を実行する代わりに、コールに参加する全員が自分のアテンション・スコアのメトリクスを担当することにしよう。そこで、アルゴリズムを session.publishエンドポイントで初期化します:
session.publish(publisher, async (err) => {
if (err) {
console.log('Error', err);
} else {
const publisherElement = document.getElementById('publisher');
streamId = publisher.stream.id;
const webcam = publisherElement.querySelector('video');
await runFacemesh(webcam);
}
});
を詳しく見てみよう。 runFacemeshメソッドを詳しく見てみよう:
const runFacemesh = async (webcamRef) => {
const net = await faceLandmarksDetection.load(faceLandmarksDetection.SupportedPackages.mediapipeFacemesh, { maxFaces: 1 });
setInterval(() => {
detect(net, webcamRef);
}, 500);
};
detect関数を使いますが、基本的にはこの関数を何回実行するかで、カメラでレンダリングされたフレームのアテンションスコア指標が得られます。つまり、この関数を1秒間に何回実行するかによって、アテンションメトリック分析の1秒あたりのフレーム数が決まります。現在、この関数は500ミリ秒ごとに実行されるように設定されているので、実質的にモデルFPS(Frames Per Second)は2ということになります。
次に、スコアを生成し、そのスコアを他の参加者全員に知らせるという、アルゴリズムの重要な部分を見てみよう:
// This runs face landmark model
const face = await net.estimateFaces({ input: video, predictIrises: true });
// Getting points from the model
const { mesh } = face[0];
const radians = (a1, a2, b1, b2) => Math.atan2(b2 - a2, b1 - a1);
// Generating angles between points and axis
const angle = {
yaw: radians(mesh[33][0], mesh[33][2], mesh[263][0], mesh[263][2]),
pitch: radians(mesh[10][1], mesh[10][2], mesh[152][1], mesh[152][2]),
};
// Calculating attention score
const score = getScore(angle.yaw) * getScore(angle.pitch);
const signalScore = { attention: score, streamId };
// Sending attention score to all other participants in call
session.signal(
{
type: 'attentionScore',
data: JSON.stringify(signalScore)
},
function(error) {
if (error) {
console.log("signal error ("+ error.name+ "): " + error.message);
}
}
);
このコードの塊は威圧的に見えるかもしれませんが、実際には、パブリッシャーの現在のフレームでフェイシャルランドマークライブラリを実行し、検出された顔の特定のポイント間の角度で私たちのアルゴリズムを実行し、そしてすべての参加者に注目スコアを放送しているだけです。 getScoreアルゴリズムを実行し、検出された顔の特定のポイント間の角度を計算し、そして注目スコアをすべての参加者にブロードキャストしているのです。
アテンション・スコアが通知されたら、受信側でそれを確実に処理し、好きなように扱う必要がある。このプロジェクトで行ったように)リアルタイムUIとして表示することもできるし、通話期間中のアテンションメトリクスのマッピングに使用できるデータストアに保存することもできる。可能性は無限だ!
アテンションは、会話、スピーチ、講義、その他あらゆる人と人とのやりとりを測定するための重要な要素である。私たちは現在、顔のメッシュ分析を使ってそれを推定し、ビデオ通話に統合する方法を学びました。この推定は、虹彩の動きや複数の顔認識など、より多くのデータソースによってさらに改善することができる。
このアプリの完全な動作バージョンは GitHub
アテンションディテクションが機能したかどうかお知らせください!Vonage開発者 Slackコミュニティに参加してください。 VonageDev.
シェア:
Hamza is a Software Engineer based in Chicago. He works with Webrtc.ventures, a leading company in providing WebRTC solutions. He also works as a Full Stack Developer at Vonage helping out with the Video Platform to better serve its customer’s needs. As a proud introvert, he likes to spend his free time playing with his cats.