
Partager:
Hamza est un ingénieur logiciel basé à Chicago. Il travaille avec Webrtc.ventures, une entreprise leader dans la fourniture de solutions WebRTC. Il travaille également en tant que développeur Full Stack chez Vonage en aidant la plateforme Video à mieux répondre aux besoins de ses clients. Fier d'être introverti, il aime passer son temps libre à jouer avec ses chats.
Transcription Voice avec Symbl.ai et l'API Video de Vonage
Temps de lecture : 3 minutes
La transcription vocale, la synthèse vocale et le sous-titrage en direct sont très demandés dans le monde d'aujourd'hui où les réunions vidéo/audio sont une forme principale de communication. Symbl.ai excelle dans l'intelligence conversationnelle. Aujourd'hui, nous allons intégrer le sous-titrage en direct dans notre solution de démarrage de télésanté SimplyDoc. Kit de démarrage de télésanté SimplyDoc en utilisant l'API de streaming et de compréhension de Symbl.ai. Notre vidéo et notre audio seront alimentés par Video API de Vonage. Commençons.
Nous obtenons la piste audio en appelant la méthode OT.initPublisher() en appelant la méthode Celle-ci renvoie un éditeur objet. Nous pouvons appeler .getAudioSource() sur cet objet pour recevoir un objet MediaStreamTrack.
Cet objet MediaStream contient la piste audio de l'éditeur que nous devons envoyer à Symbl.ai. Nous allons utiliser l Web Audio API pour manipuler la piste audio sous une forme que nous pouvons envoyer à Symbl.ai via WebSockets. Pour que l'API Audio Web fonctionne, nous avons besoin d'un objet MediaStream. Il existe un objet API qui peut nous permettre d'utiliser directement l'objet MediaStreamTrack, mais au moment où nous écrivons ces lignes, elle n'est disponible que sur Firefox.
const audioTrack = publisher.getAudioSource()
const stream = new MediaStream();
stream.addTrack(audioTrack);Nous avons maintenant l'objet stream que nous pouvons utiliser avec l'API Web Audio pour créer un tampon audio à envoyer à Symb.ai.
Tout d'abord, il est important de comprendre un peu l'API audio Web puisque nous l'utiliserons pour traiter notre audio sur le frontend. Imaginez l'API audio Web comme une boîte de nuit dans laquelle nous déclarons chaque composant. Tout d'abord, nous déclarons l'objet AudioContext, qui est comme le châssis extérieur de la boîte de nuit.
const AudioContext = window.AudioContext;
const context = new AudioContext();Maintenant que nous avons déclaré notre contexte audio, nous sommes prêts à lui donner une source. Imaginez la source comme la cassette ou le CD qui entre dans le boombox.
const source = context.createMediaStreamSource(stream);
const processor = context.createScriptProcessor(1024, 1, 1);
const gainNode = context.createGain();Dans ces trois lignes de code, nous déclarons d'abord notre nœud source, puis nous déclarons notre nœud ScriptProcessorNodeet enfin notre `gainNode`. Aucun de ces trois nœuds ne fait quoi que ce soit pour l'instant car nous ne les avons pas connectés ensemble. Le `gainNode` est comme le bouton de volume de la boombox et le nœud processeur est comme le lecteur magnétique ou l'aiguille qui lit les données de la cassette ou du CD.
Il s'agit maintenant de les relier entre eux.
source.connect(gainNode);
gainNode.connect(processor);
processor.connect(context.destination);Ici, nous connectons la source au `gainNode`. Nous pouvons utiliser le `gainNode` pour augmenter ou diminuer le volume de la source. Ainsi, si le microphone d'une personne est trop bas, nous pouvons augmenter la valeur du gain pour l'atténuer.
gainNode.gain.value = 2;Ce n'est pas nécessaire pour ce tutoriel, car nous supposons que tout le monde a un microphone convenable.
Nous connectons ensuite la sortie du `gainNode` au nœud processeur. Le nœud processeur prend trois arguments : la taille de la mémoire tampon, le nombre de canaux d'entrée et le nombre de canaux de sortie. Nous avons choisi 1024 comme taille de tampon parce qu'elle se situe dans la partie inférieure du spectre des images-échantillons (256, 512, 1024, 2048, 4096, 8192, 16384). Cela signifie que nous obtiendrons une meilleure latence/performance au prix d'un son extrêmement précis. Si vous avez l'impression que Symbl.ai manque des mots dans votre audio, l'augmentation de ce paramètre pourrait vous aider. Notez que cela résultera en un appel plus fréquent de l'événement onaudioprocess sera appelé plus souvent, ce qui pourrait ralentir votre machine.
En ce qui concerne onaudioprocessc'est l'événement qui sera déclenché chaque fois que le nœud processeur aura un tampon audio prêt pour la taille spécifiée. Symbl.ai aime préparer le tampon à envoyer comme suit :
processor.onaudioprocess = (e) => {
// convert to 16-bit payload
const inputData = e.inputBuffer.getChannelData(0) || new Float32Array(this.bufferSize);
const targetBuffer = new Int16Array(inputData.length);
for (let index = inputData.length; index > 0; index--) {
targetBuffer[index] = 32767 * Math.min(1, inputData[index]);
}
// Send audio stream to websocket.
if (ws.readyState === WebSocket.OPEN) {
ws.send(targetBuffer.buffer);
}
};
};
Nous verrons plus loin dans cet article comment envoyer le tampon à l'aide de WebSockets.
Enfin, nous renvoyons le nœud du processeur vers la destination. La destination est comme les haut-parleurs du boombox.
Voici un diagramme de ce que nous avons construit jusqu'à présent à l'aide de l'API audio Web.
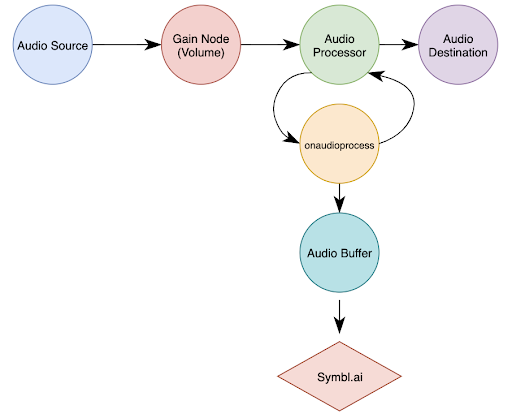
Et voilà, notre boombox est prêt à fonctionner !
Maintenant, créons une connexion WebSocket avec Symbl.ai afin d'envoyer le tampon audio que nous avons préparé dans les étapes précédentes et de recevoir les observations de Symbl.ai.
const accessToken = accessToken;
const uniqueMeetingId = btoa("user@example.com");
const symblEndpoint = `wss://api.symbl.ai/v1/realtime/insights/${uniqueMeetingId}?access_token=${accessToken}`;Pour générer le jeton d'accès, veuillez suivre ce guide.
L'identifiant unique de la réunion peut être n'importe quel hachage ou chaîne unique. Il s'agit simplement d'un exemple de création d'une chaîne cryptée unique à partir d'un courrier électronique. Maintenant, déclarons nos listeners.
// Fired when a message is received from the WebSocket server
ws.onmessage = (event) => {
// You can find the conversationId in event.message.data.conversationId;
const data = JSON.parse(event.data);
if (data.type === 'message' && data.message.hasOwnProperty('data')) {
console.log('conversationId', data.message.data.conversationId);
}
if (data.type === 'message_response') {
for (let message of data.messages) {
console.log('Transcript (more accurate): ', message.payload.content);
}
}
if (data.type === 'topic_response') {
for (let topic of data.topics) {
console.log('Topic detected: ', topic.phrases)
}
}
if (data.type === 'insight_response') {
for (let insight of data.insights) {
console.log('Insight detected: ', insight.payload.content);
}
}
if (data.type === 'message' && data.message.hasOwnProperty('punctuated')) {
console.log('Live transcript (less accurate): ', data.message.punctuated.transcript)
}
console.log(`Response type: ${data.type}. Object: `, data);
};
// Fired when the WebSocket closes unexpectedly due to an error or lost connection
ws.onerror = (err) => {
console.error(err);
};
// Fired when the WebSocket connection has been closed
ws.onclose = (event) => {
console.info('Connection to websocket closed');
};
Nous avons choisi d'utiliser la clé data.message.punctuated.transcript qui fournit une transcription en direct. Cela se fait au détriment d'une certaine précision, mais vous pouvez décider de l'utilisation des données. Lorsque la connexion WebSocket s'ouvre, nous devons envoyer un message à Symbl.ai décrivant notre réunion et les intervenants impliqués. Cela nous aide à créer une transcription après l'appel, ainsi que d'autres choses comme l'agenda de l'orateur.
// Fired when the connection succeeds.
ws.onopen = (event) => {
ws.send(JSON.stringify({
type: 'start_request',
meetingTitle: 'Websockets How-to', // Conversation name
insightTypes: ['question', 'action_item'], // Will enable insight generation
config: {
confidenceThreshold: 0.5,
languageCode: 'en-US',
speechRecognition: {
encoding: 'LINEAR16',
sampleRateHertz: 44100,
}
},
speaker: {
userId: 'example@symbl.ai',
name: 'Example Sample',
}
}));
};
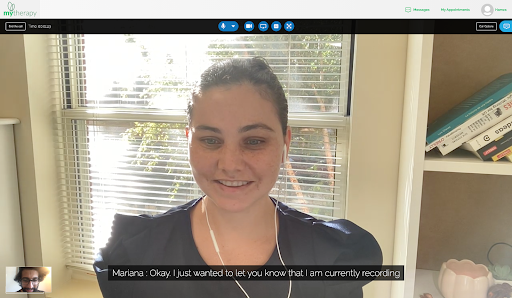
Et voilà, le cœur de notre démo Speech to Text est terminé ! Avec un peu de travail sur l'interface utilisateur, voici à quoi ressemble un appel avec transcription vocale :
Partager:
Hamza est un ingénieur logiciel basé à Chicago. Il travaille avec Webrtc.ventures, une entreprise leader dans la fourniture de solutions WebRTC. Il travaille également en tant que développeur Full Stack chez Vonage en aidant la plateforme Video à mieux répondre aux besoins de ses clients. Fier d'être introverti, il aime passer son temps libre à jouer avec ses chats.