
Video + AI : Traductions en direct avec connecteur audio
Temps de lecture : 5 minutes
Imaginez que vous participiez à un appel vidéo avec des personnes du monde entier parlant leur propre langue maternelle et que tout le monde se comprenne. Le son de l'orateur est traduit en texte que les autres participants peuvent lire dans leur propre langue. Dans cet article de blog, nous allons voir comment cela est possible. L'une des principales composantes est la nouvelle fonctionnalité Audio Connector qui vient d'être lancée.
En bref, avec Audio Connectorles flux audio de vos sessions d'appel vidéo acheminées peuvent être envoyés individuellement (A, B) ou combinés (A+B) à un serveur WebSocket pour un maximum de 50 flux au total.
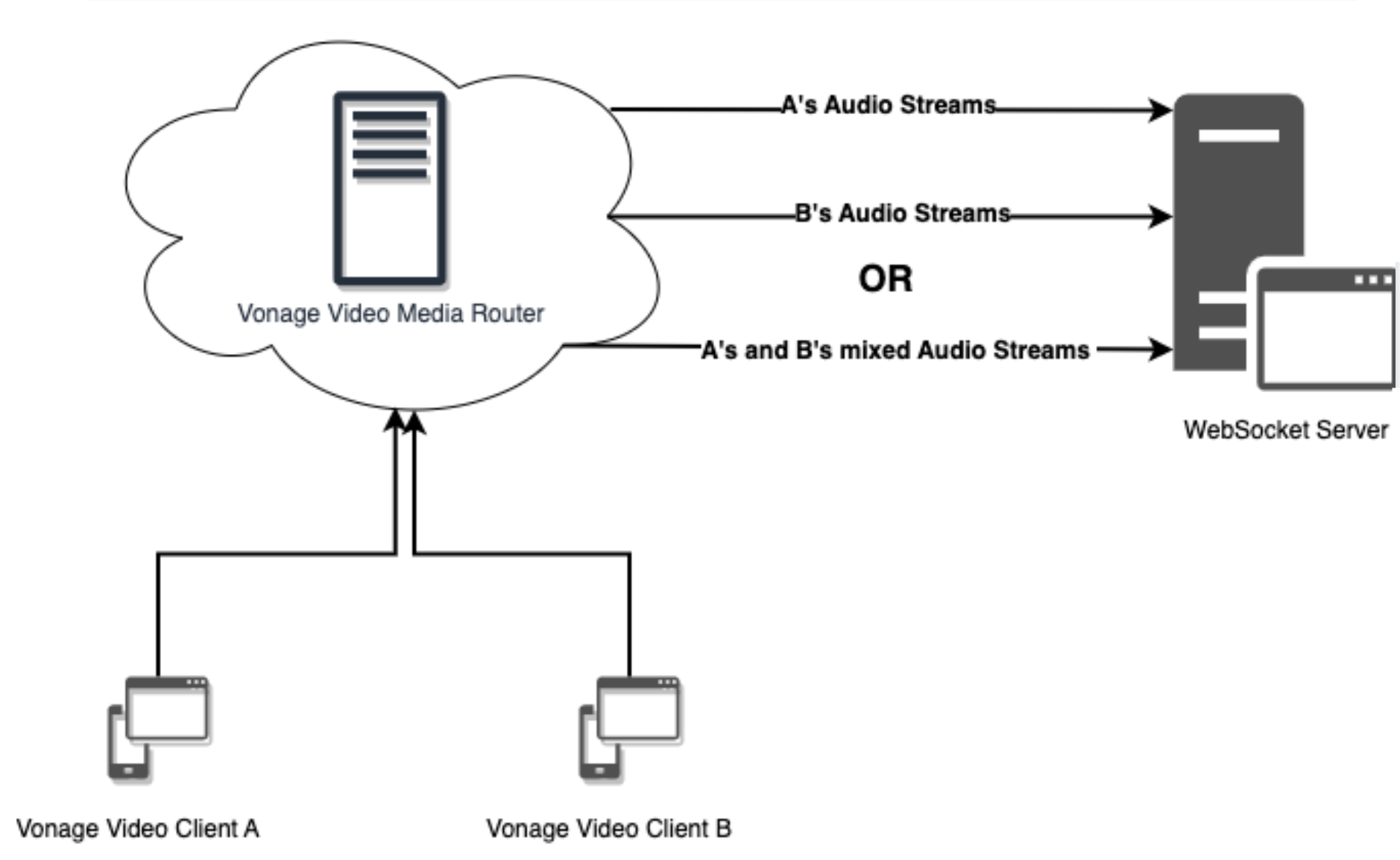 Audio Connector Diagram
Audio Connector Diagram
Il n'y a pas d'indicateur de fonctionnalité ou de commutateur à activer pour commencer à utiliser Audio Connector. Il est activé par défaut et sa tarification est basée sur le nombre de flux audio de participants envoyés. Il suffit de créer un serveur WebSocket pour recevoir les flux audio.
La possibilité d'isoler et d'analyser les flux audio ouvre de nombreuses possibilités. L'une d'entre elles, dont nous parlerons dans ce billet, est l'utilisation de l'intelligence artificielle pour effectuer des traductions en temps réel avec le service Azure AI Speech Service de Microsoft.
Si vous souhaitez voir le code et une démo en action, vous pouvez consulter le dépôt dépôt GitHub pour une application basée sur NodeJS. En cliquant sur le bouton de déploiement et en saisissant quelques informations d'identification, vous pourrez faire l'expérience de traductions en direct et en temps réel dans le cadre d'un appel vidéo.
Comme indiqué précédemment, vous aurez besoin de certaines informations d'identification pour exécuter l'application de démonstration.
Vous pouvez trouver la clé et le secret de l'API Video de Vonage dans le tableau de bordsoit dans un projet précédent, soit dans un projet nouvellement créé.
 Vonage Project Credentials
Vonage Project Credentials
Du côté de Microsoft, vous devrez créer une ressource Speech Services dans le portail Azure. Une fois créée, vous aurez besoin de l'une des clés (l'une ou l'autre convient) et de la valeur sous "Location/Region".
 Microsoft Azure Project Credentials
Microsoft Azure Project Credentials
En saisissant ces informations d'identification ainsi que le domaine de l'application en cours d'exécution, vous pouvez ensuite entrer votre nom, sélectionner les langues dans lesquelles vous vous exprimerez et lire la traduction. Partagez l'URL et demandez à un ou deux amis de se joindre à votre session Video.
Dans cette section, je décrirai ce qui se passe dans les coulisses de l'application de démonstration. Afin d'être aussi agnostique que possible en matière de code, je parlerai des méthodes en général et je pointerai vers la documentation afin que vous puissiez mettre en œuvre les choses dans le langage de programmation de votre choix. J'ai construit mon application de démonstration en utilisant NodeJS.
L'appel vidéo est juste un appel vidéo de base, comme celui que l'on trouve dans ce exemple de projet ou un appel construit à l'aide de nos nouveaux Video Web Components. La seule différence consiste à permettre à l'utilisateur de saisir son nom et les langues qu'il souhaite utiliser avant de démarrer une session.
Une fois que l'appel Video a lieu, cela signifie qu'il y a de l'audio pour que l'Audio Connector commence à l'envoyer à un serveur WebSocket. Si vous ne savez pas comment créer un serveur WebSocket, vous pouvez faire une recherche sur <your programming language> WebSocket server et, avec un peu de chance, de nombreux tutoriels et bibliothèques figureront dans les résultats de la recherche. Si ce n'est pas le cas, il y a toujours un chatbot IA à qui vous pouvez demander. Haha
Pour commencer à envoyer vos flux audio à votre serveur WebSocket nouvellement créé, Vonage fournit une méthode dans les différents SDK de serveur (Java, NodeJS, PHP, Python, Ruby, .NET) pour démarrer une connexion WebSocket. Si vous ne voyez pas votre langage côté serveur, vous pouvez également utiliser un point de terminaison point de terminaison REST.
Maintenant que votre serveur WebSocket reçoit des flux audio, il est temps de commencer la traduction. Le service Azure AI Speech Service de Microsoft peut traduire des données audio dans plus de 30 langues. Microsoft propose des kits de développement logiciel (SDK) pour le service de reconnaissance vocale en C++, C#, Go, Java, JavaScript/NodeJS, Objective-Cet Python.
Tout d'abord, vous devez configurer la traduction vocale avec votre clé et votre région. Dans le SDK de votre langue, il devrait y avoir quelque chose de similaire à SpeechTranslationConfig avec un fromSubscription dans lequel vous pouvez passer vos informations d'identification. L'emplacement de la reconnaissance vocale et des langues cibles peut dépendre du fait que vous envoyez un flux combiné ou plusieurs flux individuels.
Sur votre serveur WebSocket, vous voudrez collecter les données envoyées par le connecteur audio pour les traduire avec l'intelligence artificielle. Pour cela, il faudra créer un flux d'entrée (Push Stream) pour le flux d'entrée audio, au moins dans NodeJS. Voici comment cela fonctionne.
Le connecteur audio envoie différents types de messages WebSocket :
Il existe des messages textuels qui comprennent le message initial, des mises à jour lorsqu'un flux audio est coupé/désactivé et lorsque la connexion est déconnectée. Ces messages contiennent des informations sur le format audio, des données relatives à l'état de la connexion et toutes les données d'en-tête personnalisées que vous avez envoyées lors de la création de la connexion.
L'autre type est constitué de messages audio binaires qui représentent le flux audio. C'est ce que vous voulez ajouter au flux poussé pour que l'intelligence artificielle le traduise.
Pour différencier les messages textuels des messages audio, j'essaie d'analyser le message en JSON. Si je n'obtiens pas d'erreur, cela signifie qu'il s'agit d'un message texte. Si j'obtiens une erreur, cela signifie qu'il s'agit d'un message audio binaire qui est ajouté au flux Push.
Maintenant que nous disposons d'un flux d'entrée audio fourni par le flux Push, nous devons configurer l'audio à partir de l'entrée du flux afin que le Speech SDK puisse analyser et traduire l'audio. Pour commencer à "comprendre" le flux, un Translation Recognizer est créé à l'aide des configurations Audio et Speech Translation. Le Translation Recognizer est ensuite lancé pour essayer en permanence de reconnaître ce qui est dit dans le flux audio.
Des traductions partielles seront émises au fur et à mesure que l'outil de reconnaissance de la traduction tentera de comprendre ce qui est dit. Une fois qu'il a ce qu'il croit être une compréhension complète de ce qui a été dit dans la phrase, une traduction finalisée est présentée.
Nous prendrons ensuite ces traductions finalisées au fur et à mesure qu'elles seront présentées et nous les enverrons dans la session vidéo par l'intermédiaire de la fonction Video de Vonage Vonage pour qu'elles soient affichées sur les écrans des participants.
J'ai pensé qu'il serait intéressant d'ajouter la possibilité de mettre en sourdine tous les participants à l'appel vidéo et de faire en sorte que le navigateur lise le texte traduit avec une voix de synthèse. Si vous l'essayez, faites-nous savoir comment cela se passe dans le Communauté des développeurs Slack ou sur X, anciennement connu sous le nom de Twitter. @VonageDev.