
Partager:
Acteur de formation avec une thèse sur la comédie, je suis venu au développement PHP par le biais de la scène des rencontres. Vous pouvez me trouver en train de parler et d'écrire sur la technologie, ou de jouer/acheter des disques bizarres de ma collection de vinyles.
Le retour de SQLite
Temps de lecture : 13 minutes
Bon, je l'admets, ce n'est pas un retour. Disons plutôt qu'il s'agit d'une réimagination. SQLite existe depuis l'an 2000, et son utilisation initiale était destinée au suivi des missiles à bord des destroyers de la marine américaine. Il a certainement fait ses preuves en tant que système de base de données relationnelle, même si les dix dernières années ont vu l'essor des systèmes de base de données NoSQL, orientés vers les documents, qui lui ont quelque peu volé la vedette. Dans cet article, je vais explorer le potentiel méconnu de SQLite et démontrer à quel point il est rapide à mettre en place avec une architecture de niveau production à l'esprit. D'accord, je l'admets, ce n'est pas un retour. Disons plutôt qu'il s'agit d'une réimagination. SQLite existe depuis 2000. Bien que la dernière décennie ait vu la montée en puissance des bases de données NoSQL et orientées documents qui ont occupé une grande partie de l'attention, SQLite reste une option puissante. Développé à l'origine pour le suivi des missiles sur les destroyers de la marine américaine, il a discrètement fait ses preuves en tant que base de données relationnelle fiable. Il y a de fortes chances que vous négligiez son potentiel dans une architecture de production. Dans cet article, je vous montrerai à quel point il est facile et rapide de mettre en œuvre SQLite.
>> TL;DR : Vous pouvez trouver le code source complet sur GitHub.
Quelle introduction donc, mais comment les ingénieurs logiciels, et plus particulièrement les développeurs d'applications web, connaissent-ils SQlite ? Eh bien, il a surtout deux réputations :
J'ai besoin d'exécuter mes tests et je ne veux pas mettre en route un serveur complet de Postgres alors pourquoi ne pas utiliser ce petit fichier utile pour l'exécuter ?
C'est pour les systèmes embarqués parce que c'est petit, n'est-ce pas ? Mais ça ne sert à rien pour mon application web, qui va générer des montagnes de données.
Le premier point est indiscutable : SQLite est incroyablement utile pour les tests. Vous avez, disons, votre architecture existante dans le code : migrations, seeders, et ainsi de suite. Ainsi, lorsque vous exécutez votre suite de tests, au lieu d'utiliser un serveur de base de données compatible avec SQL, tel que MySQL, MariaDBou Postgres, vous exécutez le même code mais avec un fichier SQLite vierge. C'est parfait. Mais qu'en est-il du point 2 ?
 Just one file: portability at its finestOui, il est petit. Mieux encore, la connectivité est simple : ce n'est qu'un fichier.
Just one file: portability at its finestOui, il est petit. Mieux encore, la connectivité est simple : ce n'est qu'un fichier.
Il existe toute une série de plugins IDE et de compatibilité - les IDE de Jetbrains ont un panneau de base de données qui peut créer un nouveau fichier SQLite, et les IDE de VSCode dispose de nombreux plugins pour gérer cela pour vous. Je veux dire, pour les vrais développeurs développeurs, vous pouvez le créer directement à partir de Vim.
L'empreinte de la boîte est d'à peine 699 kb. C'est tout. Pas de service à exécuter, pas de processus en arrière-plan, juste un fichier.
C'est très différent des ressources nécessaires à la mise en place d'un serveur MySQL complet.
Nous en arrivons maintenant à la question que la plupart des gens veulent poser : si c'est aussi simple, pourquoi n'utilisons-nous pas SQLite dans davantage d'Applications Web ?
La réponse se résume généralement à des hypothèses. Les bases de données relationnelles basées sur des serveurs dominent, mais avec un peu de réflexion, vous pourriez vous rendre compte que SQLite répond parfaitement à nos besoins réels.
La vitesse de lecture et d'écriture est l'une des plus grandes différences. SQLite, pour une base de données moyenne de quelques millions de lignes, est incroyablement incroyablement rapide. Les benchmarks varient, mais les requêtes en solo prennent jusqu'à 5 ms, contre une moyenne maximale d'environ 10 ms pour MySQL.
Cependant, si SQLite l'emportait sur tous les benchmarks, il est clair que nous l'utiliserions pour tout, alors qu'il n'est pas si répandu dans le développement d'applications web. Premièrement, la vitesse d'écriture est beaucoup beaucoup plus lente. SQLite peut écrire approximativement jusqu'à 300 insertions sur un seul thread, contre 50 000 pour MySQL (en fonction de l'environnement). C'est une grande différence.
La deuxième chose à noter est que SQLite dispose d'un mécanisme de verrouillage à un seul thread ; les enregistrements qui sont lus ou écrits/modifiés ont cinq états d'écriture possibles. Lors de l'écriture, l'état de verrouillage d'un enregistrement est modifié en EXCLUSIVE, ce qui limite toute autre action concurrente. MySQL, en revanche, utilise le MVCC (Multi-Version Concurrency Control), qui permet de nombreuses lectures et écritures simultanées.
L'une des questions que j'essaie constamment de rappeler aux gens est la suivante Quel est votre cas d'utilisation ? Dans le monde du cloud-native et de Kubernetes, beaucoup affirment que " PHP est lent " parce que " Node a une boucle d'événements ", mais ce à quoi j'invite les gens à réfléchir, c'est " qu'est-ce que votre application va de manière réaliste réaliste ? Si vous allez stocker des données d'utilisateurs ou télécharger des CSV et des images, êtes-vous vraiment vraiment voir la différence entre le choix du langage et du cadre de travail ? Dans de nombreux cas, probablement pas. Il en va de même pour SQLite par rapport à MySQL : SQLite reste un choix fantastique si vous avez quelques SQLite est toujours un choix fantastique si vous avez quelques données, mais plus important encore, allez-vous avoir 20 000 utilisateurs qui écrivent dans la base de données de votre application ? Si vous écrivez la prochaine itération d'une application de taxi mondial, alors bien sûr. Ce que je veux dire ici, c'est que SQLite est bien mieux adapté à de nombreux cas de développement que beaucoup ne le réalisent.
WebStorm IDE et connaissances de base pour l'utiliser
Connaissances de base sur l'utilisation d'un client de test HTTP, tel que HTTPie ou Insomnia
To complete this tutorial, you will need a Vonage API account. If you don’t have one already, you can sign up today and start building with free credit. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard.

Assez parlé, il est temps de montrer le peu de lignes de code que l'on peut écrire pour démontrer une écriture SQLite au niveau de la production avec Typescript. Nous allons exposer une application qui sera capable de lire les webhooks générés par l'API Vonage Messages API. Tout d'abord, créez un nouveau répertoire pour votre projet, naviguez-y et créez un nouveau projet Node.
npm init --yesCeci utilisera les valeurs par défaut pour votre package.json qui a été créé. Ensuite, nous devons installer TypeScript :
npm install typescript
npx tsc --initTypescript se compile en JavaScript simple et utilise un fichier de configuration tsconfig.json, qui est créé lors de l'installation. Ouvrez ce fichier de configuration et remplacez le modèle par ce qui suit :
{
"compilerOptions": {
"target": "es2016",
"module": "CommonJS",
"rootDir": "./",
"outDir": "./dist",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true,
"moduleResolution": "node",
"baseUrl": ".",
"paths": {
"@prisma/client":["node_modules/@prisma/client"]
}
},
"include": ["src/**/*.ts"]
}Les éléments importants de cette configuration sont à noter :
TypeScript sera compilé dans un répertoire qui sera créé s'il n'existe pas, nommé
dist. Ce sera le point d'entrée de votre application.Vous remarquerez que Prisma se trouve dans la clé
pathsdans la clé. En effet, lorsque nous installons Prisma, il doit également être compilé (d'une certaine manière). Lorsque nous définissons des modèles dans Prisma, il utilise ensuite une commande de génération pour créer un client Prisma sur mesure.
Nous avons six dépendances :
Prisma : notre mappeur relationnel objet
ts-node: nous permet d'exécuter TypeScript sans compiler dans le répertoire de sortie
nodemonpour notre serveur de développement, le code est rechargé lorsqu'il est modifié
dotenvpour la gestion des variables d'environnement)
Express: notre routeur
Sqlitepour notre connexion à la base de données
Vous pouvez les installer en une seule fois sur la ligne de commande :
npm install prisma ts-node nodemon dotenv express @types/express sqlite3Prisma est un ORM qui peut gérer vos modèles de données, la migration et toutes les autres requêtes. Pour configurer votre répertoire Prisma, nous devons exécuter la commande init :
npx prisma init --datasource-provider sqlite --output ../generated/prismaCette commande configurera Prisma pour qu'il produise une classe Client compilée dans le répertoire ../generated/prisma et lui indique que SQLite est notre source de base de données. Lors de l'exécution de cette commande, Prisma vous demandera toutes les dépendances nécessaires, et configurera ensuite votre fichier .env et configure votre fichier .env. Nous configurerons ce fichier plus tard.
SQLite étant un fichier géré par une bibliothèque, vous pouvez le créer avec la plupart des IDE modernes qui prennent en charge les pilotes. Ouvrez maintenant votre projet dans Webstorm. Cliquez ensuite sur l'icône Base de données dans le panneau de droite. Cliquez ensuite sur le bouton "+" pour créer une nouvelle base de données. Sélectionnez Data Source (Source de données) et faites défiler vers le bas jusqu'à ce que vous voyiez SQLite. Vous obtenez ainsi la fenêtre modale de création d'une nouvelle base de données :
 Jetbrains Supports A Massive List of DBsChoisissez SQLite comme type, et vous obtiendrez la fenêtre contextuelle de création :
Jetbrains Supports A Massive List of DBsChoisissez SQLite comme type, et vous obtiendrez la fenêtre contextuelle de création :
 Create Your DatabaseLa première fois que vous faites cela, si vous n'avez pas utilisé WebStorm auparavant, l'IDE détectera que vous n'avez pas les pilotes SQlite installés comme un avertissement rendu à la place de l'option
Create Your DatabaseLa première fois que vous faites cela, si vous n'avez pas utilisé WebStorm auparavant, l'IDE détectera que vous n'avez pas les pilotes SQlite installés comme un avertissement rendu à la place de l'option Test Connection à la place de l'option Si vous n'avez pas les pilotes, cliquez sur le lien pour les installer.
Dans le champ Name changer identifier.sqlite en webhookset le nom de fichier en webhooks.sqlite. Vous voulez que le fichier soit situé à la racine de votre projet, alors cliquez sur les points à droite du champ de fichier pour vous assurer que l'emplacement est correct. Cliquez ensuite sur ok.
Votre client Prisma est configuré dans prisma/schema.prismamais il récupère la variable DATABASE_URL de votre fichier .env de votre fichier. Ouvrez votre fichier envet remplacez-le comme suit :
DATABASE_URL="file:../webhooks.sqlite"Prisma est configuré d'origine pour générer le client ORM sur mesure dans le répertoire node_modules dans le répertoire Nous ne voulons pas qu'il soit généré dans le répertoire @prisma donc dans le fichier schema.prisma remplacez les paramètres du client comme suit, sous la source de données :
generator client {
provider = "prisma-client-js"
output = "../node_modules/.prisma/client"
}Cela permet à Prisma de placer le client généré dans un nouveau répertoire, .prisma. Plus tard, lors de la création d'un enregistrement dans Express, nous indiquerons à Prisma où importer le client.
Nous devons créer un modèle qu'une migration exécutera ensuite. Ce que j'ai fait ici est une petite astuce - Prisma a besoin que vous tapiez tous vos modèles de base de données manuellement. Eh bien, nous consommons un webhook de l'API webhook de l'API Messages de VonageAlors, que se passerait-il si je naviguais jusqu'à la référence du webhook dans la spécification OpenAPI specje copiais l'exemple JSON, puis je demandais à AI de m'écrire le modèle ? C'est exactement ce que j'ai fait.
 Auto-generated AI code from OpenAPI specsJe vais vous épargner le travail, vous pouvez copier les modèles suivants dans votre base de données
Auto-generated AI code from OpenAPI specsJe vais vous épargner le travail, vous pouvez copier les modèles suivants dans votre base de données schema.prisma below la source de données et le client :
model WebhookEvent {
id String @id @default(uuid())
channel String
messageUuid String @unique
to String
from String
timestamp DateTime
contextStatus String
messageType String
location Location?
createdAt DateTime @default(now())
}
model Location {
id String @id @default(uuid())
webhookId String @unique
lat Float
long Float
webhook WebhookEvent @relation(fields: [webhookId], references: [id], onDelete: Cascade)
}Vous pouvez maintenant exécuter la migration, qui générera des tables dans la base de données pour ces modèles.
npx prisma migrate dev --name webhooksPrisma a maintenant créé la migration pour vous, qui sert d'enregistrement de toutes les modifications apportées à la base de données. Vous voulez renommer un champ ? Oui, nouvelle migration, intégrée au code source. Vous disposez à présent d'un enregistrement complet de la manière dont la base de données de votre application a été mise dans le bon état, dans le code.
Votre dernière tâche consiste à créer l'application Express qui utilisera le webhook. Créez un nouveau répertoire à la racine de votre projet nommé src et créez un nouveau fichier TypeScript nommé index.ts. Il ressemble à ceci :
import express, { Express, Request, Response } from "express";
import dotenv from 'dotenv';
import { PrismaClient } from ".prisma/client"
dotenv.config();
const app: Express = express();
const port = process.env.PORT;
const prisma = new PrismaClient();
app.use(express.json())
app.get('/', (req: Request, res: Response) => {
res.send('Express + TypeScript Server');
});
app.post('/webhook', async (req, res) => {
try {
const { channel, message_uuid, to, from, timestamp, context_status, message_type, location } = req.body
// Save the webhook data in the database
const webhook = await prisma.webhookEvent.create({
data: {
channel,
messageUuid: message_uuid,
to,
from,
timestamp: new Date(timestamp),
contextStatus: context_status,
messageType: message_type,
location: location ? {
create: {
lat: location.lat,
long: location.long
}
} : undefined
},
include: { location: true } // Optional: Include related location in the response
})
console.log('Webhook saved:', webhook)
res.status(201).json({ message: 'Webhook saved successfully', webhook })
} catch (error) {
console.error('Error saving webhook:', error)
res.status(500).json({ error: 'Internal server error' })
}
})
app.listen(port, () => {
console.log(`[server]: Server is running at http://localhost:${port}`);
});Il y a pas mal de choses à décortiquer ici, alors examinons-les ligne par ligne :
import { PrismaClient } from ".prisma/client"assurez-vous que vous importez à partir du répertoire .prisma.app.use(express.json())est de s'assurer qu'Express sait qu'il doit gérer JSON.app.post('/webook') définit un nouveau point d'arrivée vers lequel Vonage enverra des données.
POSTvers lequel Vonage enverra des données.Le champ
constdéfinie dans la fermeture du webhook extrait tous les champs dont vous avez besoin dans des variables immuables, qui seront écrites dans la base de donnéesEnfin,
prisma.webhookEvent.create()est appelé, ce qui permet d'écrire les données entrantes dans votre base de données SQLite.
Vous aurez besoin de pouvoir reconstruire votre client Prisma via la ligne de commande, ainsi que les options ajoutées pour que le TypeScript compilé fonctionne. Dans la section scripts de votre fichier package.json remplacez-la par ce qui suit :
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "npm run prisma:generate && npx tsc",
"start": "node dist/src/index.js",
"dev": "nodemon --exec ts-node src/index.ts",
"prisma:generate": "prisma generate"
}Pour exécuter votre application ici, construisez d'abord l'application dans le répertoire dist puis lancez l'application Express, après avoir régénéré Prisma et appelé le compilateur TypeScript.
npm run buildnpm run startVous avez peut-être remarqué que j'ai également ajouté la commande npm run dev qui lancera le compilateur TypeScript et nodemonqui effectuera un dev build à chaque fois qu'un fichier sera modifié.
La dernière partie consiste à envoyer les données elles-mêmes. Pour ce faire, nous allons tout d'abord devoir exposer notre application locale à internet en utilisant ngrok. Pour ce faire, ouvrez un nouvel onglet dans votre terminal et exécutez :
ngrok http 3000En savoir plus plus d'informations sur ngrok.
Une fois que ngrok a ouvert vos ports, vous devriez avoir une URL publique. Celle-ci va maintenant être configurée dans Vonage.
Pour créer une application, allez à la page Créer une application sur le tableau de bord de Vonage, et définissez un nom pour votre application.
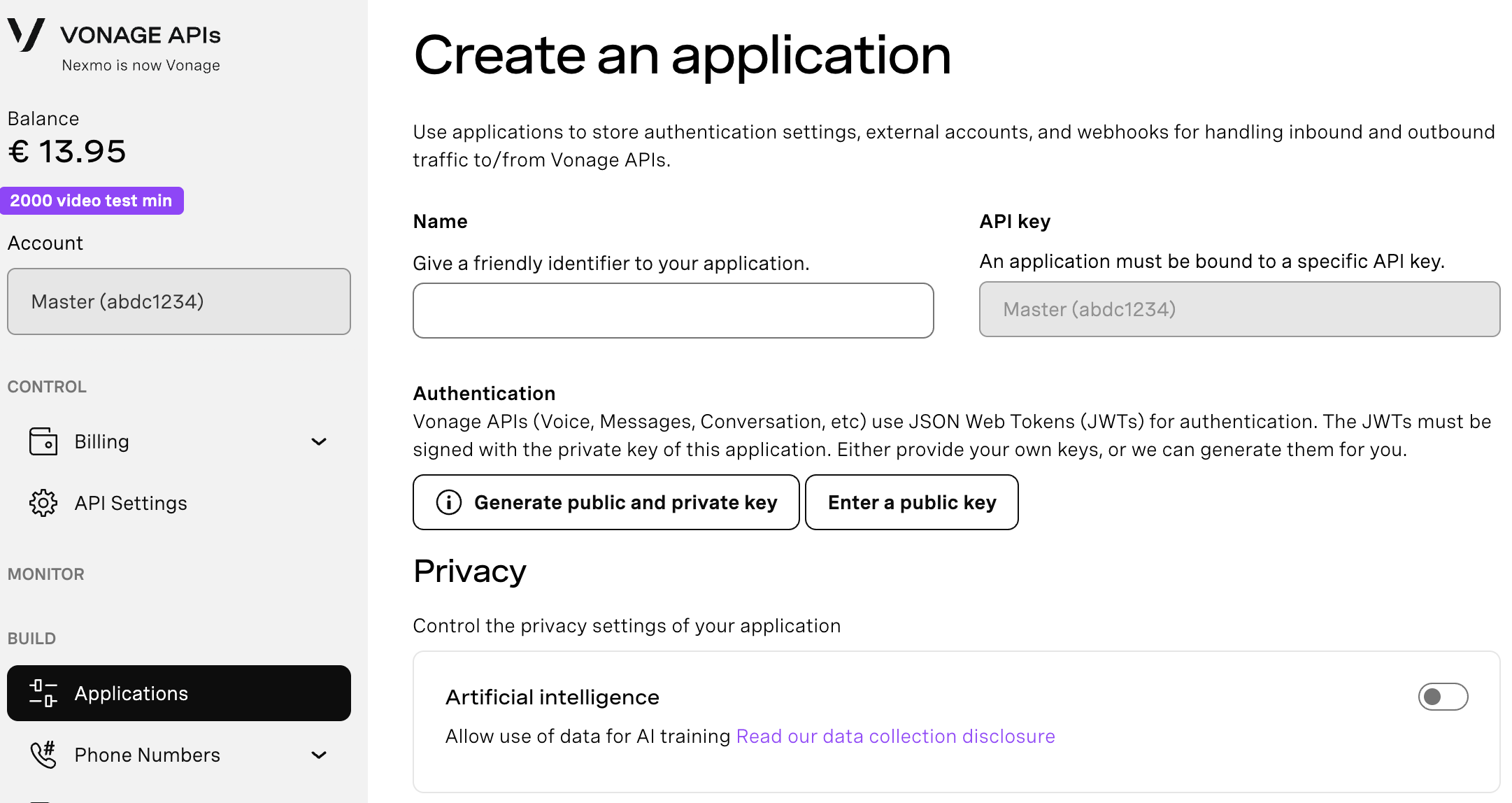
Si vous avez l'intention d'utiliser une API qui utilise des Webhooks, vous aurez besoin d'une clé privée. Cliquez sur "Générer une clé publique et privée", votre téléchargement devrait démarrer automatiquement. Conservez-la en lieu sûr ; cette clé ne peut pas être retéléchargée si elle est perdue. Elle suivra la convention de nommage suivante private_<votre identifiant d'application>.key. Cette clé peut maintenant être utilisée pour authentifier les appels à l'API. Remarque : votre clé ne fonctionnera pas tant que votre application n'aura pas été sauvegardée.
Choisissez les fonctionnalités dont vous avez besoin (par exemple, Voice, Messages, RTC, etc.) et fournissez les webhooks requis (par exemple, URL d'événement, URL de réponse ou URL de message entrant). Ces éléments seront décrits dans le tutoriel.
Pour sauvegarder et déployer, cliquez sur "Générer une nouvelle application" pour finaliser la configuration. Votre application est maintenant prête à être utilisée avec les API de Vonage.
Les clés publiques et privées et toute autre option ne sont pas vraiment importantes car nous ne procédons pas à une intégration complète, nous générons simplement des données. Ce que ce qui est important est de coller l'URL générée par Ngrok dans ces deux options d'entrée, suivies de /webhook car il s'agit de la route qui a été créée dans Express. Allez-y et créez l'application, la capacité des messages devrait ressembler à ceci :
 Configuring your Vonage Application WebhooksToutes les réponses au numéro attaché à cette application seront désormais transférées via . Webhook à l'URL que vous avez indiqué ici pour l'URL entrante.
Configuring your Vonage Application WebhooksToutes les réponses au numéro attaché à cette application seront désormais transférées via . Webhook à l'URL que vous avez indiqué ici pour l'URL entrante.
Pour acheter un numéro de téléphone virtuel, rendez-vous sur votre tableau de bord API et suivez les étapes ci-dessous.
 Purchase a phone number
Purchase a phone number
Accédez à votre tableau de bord API
Naviguez vers CONSTRUIRE & GERER > Numbers > Acheter des Numbers.
Choisissez les attributs nécessaires et cliquez sur Rechercher
Cliquez sur le bouton Acheter à côté du numéro désiré et validez votre achat
Pour confirmer que vous avez acheté le numéro virtuel, allez dans le menu de navigation de gauche, sous CONSTRUIRE & GÉRER, cliquez sur Numéros, puis sur Vos Numéros
Notre configuration est maintenant terminée : envoyez un message au numéro que vous avez acheté, et tout le câblage se fera pour écrire l'événement et le message entrant directement dans votre nouvelle base de données SQLite. J'ai utilisé ici un de mes outils préférés, HTTPiepour tester l'envoi du webhook :
 Successful Persistence WinsDans le panneau de base de données de PHPStorm, ouvrez la table des webhooks et vous verrez que l'enregistrement a été correctement persisté :
Successful Persistence WinsDans le panneau de base de données de PHPStorm, ouvrez la table des webhooks et vous verrez que l'enregistrement a été correctement persisté :
 Database Query View in WebStorm
Database Query View in WebStorm
Cette démo montre la puissance de SQLite : nous n'avons pas beaucoup d'efforts pour que ce code persiste sur les données entrantes. Pas de Docker, pas de spinups de systèmes relationnels dans le nuage. Cette introduction sert à montrer où SQLite pourrait s'avérer utile : de plus petits volumes de fichiers journaux en rotation, de plus petits lots de données générées par des humains plutôt que par des machines, et des données de session. Il s'agit d'une configuration rapide semblable à Redis lorsque la concurrence et le trafic ne sont pas des préoccupations majeures. Mais, comme pour tout, n'oubliez pas la devise des ingénieurs : It Depends®.
Vous avez une question ou souhaitez partager ce que vous construisez ?
Rejoignez la conversation sur le Communauté Vonage Slack
S'abonner à la Bulletin d'information du développeur
Suivez-nous sur X (anciennement Twitter) pour les mises à jour
Regardez les tutoriels sur notre chaîne YouTube
Connectez-vous avec nous sur la page Vonage Developer sur LinkedIn
Restez connecté et tenez-vous au courant des dernières nouvelles, astuces et événements concernant les développeurs.
Partager:
Acteur de formation avec une thèse sur la comédie, je suis venu au développement PHP par le biais de la scène des rencontres. Vous pouvez me trouver en train de parler et d'écrire sur la technologie, ou de jouer/acheter des disques bizarres de ma collection de vinyles.