
Partager:
Mark a développé des démos, mis en œuvre des POC et infligé son humour à des collègues peu méfiants chez Vonage pendant plus de 4 ans. Il programme professionnellement depuis 1979, et son expérience technique s'étend de FORTRAN sur des cartes perforées à React Native sur le cloud. Sa créativité et son enthousiasme pour le développement et le partage de solutions technologiques n'ont d'égal que son penchant pour les blagues de papa.
Démonstration de la diarisation du locuteur avec Vonage Video et Deepgram
Temps de lecture : 6 minutes
De nombreux travailleurs dans le monde ont repris le chemin du bureau, mais l'utilisation des systèmes de vidéoconférence ne faiblit pas pour autant ! La plupart des systèmes disponibles sur le marché aujourd'hui sont conçus pour un seul locuteur par flux vidéo, ce qui complique les systèmes de salles de bureau partagés par plusieurs locuteurs. Imaginez que vous lisiez la transcription d'un échange entre trois personnes sans pouvoir identifier les différents intervenants. Cela peut être très déroutant.
De plus en plus, les systèmes de conférence se tournent vers les capacités d'intelligence artificielle pour gérer cette complexité. La dernière génération de technologies va au-delà des simples sous-titres et traductions et emploie la puissance de l'IA pour gérer la complexité des systèmes de salle ainsi que les scénarios de vidéo hybride.
Savoir qui a dit quoi à qui est important pour donner un sens à une conversation et pour valoriser les notes de réunion et les transcriptions. L'identification du locuteur va au-delà de la compréhension de la conversation, elle permet d'apporter une valeur ajoutée aux notes de réunion et aux transcriptions. L'identification de la personne qui parle à partir d'une source audio unique est une tâche à laquelle les humains se sont spécialement adaptés, mais qui constitue un défi complexe pour les machines. Ce processus est appelé diarisation du locuteur.
Dans ce blog, nous allons montrer comment nous avons construit un système de vidéoconférence pour des salles à plusieurs locuteurs avec diarisation.
Ci-dessous, vous pouvez voir une vidéo de cette démonstration en action !
Pour mettre en œuvre cette solution, nous devions nous assurer que.. :
Le système de vidéoconférence disposait d'un accès sécurisé à l'audio brut sur le serveur afin de garantir les temps de traitement les plus rapides, ainsi qu'à la capture à partir d'appareils SIP pour tous les participants qui se connectent.
Le service de reconnaissance automatique de la parole (ASR) pourrait séparer les locuteurs individuels dans un flux audio de manière à ce que les énoncés de chaque locuteur soient identifiés de manière unique.
L'obtention de ces capacités était cruciale pour libérer tout le potentiel des systèmes de conférence pour les systèmes de salle et les cas d'utilisation hybrides et pour construire une application vidéo utile et conviviale, comme on peut le voir ci-dessous :
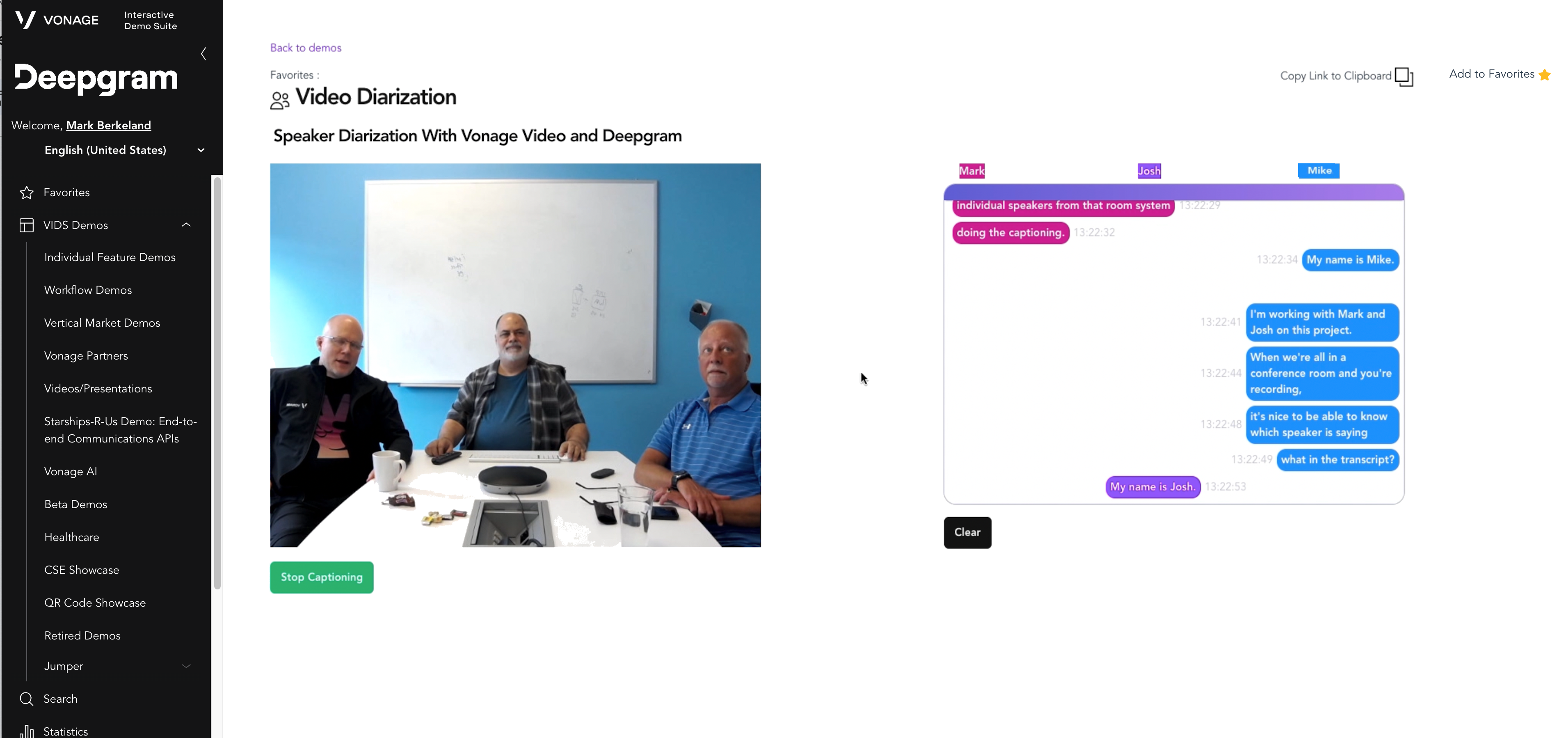 vonage_video_api_diarization_demo.png
vonage_video_api_diarization_demo.png
Qu'est-ce que la diarisation de l'orateur ?
La diarisation du locuteur est le processus de séparation d'un flux audio en segments en fonction de l'identité du locuteur, quel que soit le canal. La diarisation du locuteur est généralement divisée en quatre sous-tâches principales :
Détection - Trouver des régions audio qui contiennent de la parole par opposition au silence ou au bruit.
Segmentation - Diviser et séparer les régions détectées en sections audio plus petites.
Représentation - Utiliser un vecteur discriminant pour représenter ces segments.
Attribution - Ajouter une étiquette de locuteur à chaque segment sur la base de sa représentation discriminante.
Les fonctions de diarisation proposées par les différents fournisseurs de RPA sont plus ou moins performantes. Notre partenaire Deepgram a mis en place l'un des ensembles de fonctionnalités les plus robustes que nous ayons vus sur le marché, avec plus d'une douzaine de langues et aucune limite sur le nombre de locuteurs actifs. Pour en savoir plus sur cette solution ici.
En savoir plus sur la diarisation du locuteur dans ce Deepgram (https://blog.deepgram.com/what-is-speaker-diarization/)
Pour que la reconnaissance vocale fonctionne efficacement, il faut pouvoir accéder aux flux audio bruts directement à partir du routeur multimédia. Cela offre les avantages d'une prise en charge native de tous les appareils, utilise une fraction de la bande passante d'une solution côté client et peut fonctionner avec des systèmes protégés par un pare-feu. Grâce au connecteur audio de l'API Video de Vonage, nous pouvons extraire des flux audio bruts de nos sessions vidéo en direct et les envoyer à Deepgram pour le traitement en temps réel (ainsi que hors ligne) des flux audio. Vous pouvez trouver plus d'informations sur le connecteur audio ici.
Lorsque nous avons construit notre démo, nous voulions montrer la diarisation en temps réel d'un système de salle en utilisant Vonage Video API pour créer la session vidéo et Deepgram pour transcrire la parole.
Par souci de clarté, nous n'avons pas inclus d'autres personnes se joignant à la conférence, bien que cette solution puisse tout à fait gérer ce cas (ainsi que plusieurs systèmes de salles simultanés). Le connecteur audio démarre lorsque nous ajoutons un nouvel éditeur (qui, dans ce cas, est un système de salle). Il est en fait assez simple de configurer le connecteur audio, car nous connaissons déjà le StreamID de l'éditeur (il nous est envoyé par l'application frontale). Bien que l'AudioConnector puisse gérer "all" ou "a list of streams", dans notre cas nous n'utilisons qu'un seul flux, associé au système de salle. Notez qu'il POURRAIT même s'agir d'un système de conférence de salle SIP traditionnel.
Nous avons eu besoin d'une API Video de Vonage et d'un compte Deepgram pour créer cette démo. Vous pouvez créer vos comptes gratuits ici pour Vonage Video API et ici pour Deepgram.
Après avoir créé notre instance Opentok ("opentok") et créé une session pour la vidéoconférence ("sessionId") ainsi qu'un jeton d'autorisation associé ("token"), l'application nous informe du flux du système de salle ("streamId"). Il suffit ensuite d'associer ce flux à l'URL d'une websocket en attente ("url") :
opentok.websocketConnect(sessionId, token, url, {
streams: [streamId],
headers: {
sessionid: sessionId,
streamId: streamId
},
audioRate: 16000,
}, function(error, socket) {
if (error) {
console.log('Error:', error.message);
} else {
console.log('OpenTok Socket websocket connected');
}
});Le websocket est à l'écoute des connexions entrantes, et comme nous transmettons l'ID de session et l'ID de flux dans les en-têtes, nous sommes en mesure de savoir exactement quel flux nous allons transcrire et diariser :
app.ws('/socket', async (ws, req) => {
…
ws.on('message', (msg) => {
try {
if (typeof msg === 'string') {
let config = JSON.parse(msg);
console.log("Socket string message: ", config);
// Do whatever we need here…
// the sessionId and streamId are contained in the msg!
} else {
Où le "msg" arrive comme :
Socket string message: {
'content-type': 'audio/l16;rate=16000',
event: 'websocket:connected',
sessionid: '1_MX40NjQyMzI5Mn5-MTY4NjA5MDM1MTkwNX5yUVlkZmp0bE9jMk5rQTAyVxxxxxxxxx-xx',
streamId: '553236ce-xxxx-xxxx-8cb4-9dd17b3119dc'
}Nous pouvons maintenant connecter notre flux audio entrant directement au modèle de streaming de Deepgram. Lorsque nous voyons le connecteur audio se connecter, nous demandons à Deepgram d'ouvrir une socket. Pour notre démo, nous avons trouvé que l'utilisation du modèle "phonecall" dans le niveau "enhanced" donnait de très bons résultats, et nous avons utilisé le format par défaut de l'Audio Connector de "16000" pour le taux d'échantillonnage et de "linear16" pour le format audio. Cliquez ici pour plus d'informations sur les fonctionnalités et les options de Deepgram. pour plus d'informations sur les fonctionnalités et les options de Deepgram. Par ailleurs (et c'est en quelque sorte l'essentiel), nous demandons à Deepgram d'utiliser la diarisation ("diarize : true") :
const deepgramLive = deepgram.transcription.live({
punctuate: true,
model: 'phonecall',
tier: 'enhanced',
language: “en - US”,
,
diarize: true,
encoding: 'linear16',
sample_rate: 16000,
endpointing: 10,
});Nous pouvons ensuite utiliser cette connexion Deepgram pour écouter les résultats de la transcription (nous verrons plus tard ce que nous en faisons), en créant un "auditeur" :
deepgramLive.addListener('transcriptReceived', async (transcription) => {
Ok, notre plomberie est maintenant prête... il est temps d'ouvrir le robinet !
Dans la websocket Audio Connector, chaque fois que nous recevons un paquet audio de notre système de salle (en d'autres termes, lorsque le type de message est "binaire"), nous nous assurons d'abord que Deepgram est prêt à recevoir des données :
if ((deepgramLive.getReadyState() === 1)) {
Et si c'est le cas, nous transmettons simplement les données telles quelles !
deepgramLive.send(msg);
Une fois que Deepgram aura obtenu suffisamment de données pour créer la légende, il nous rappellera l'"auditeur" mentionné ci-dessus. Deepgram nous fournit un grand nombre d'informations concernant l'audio transcrit (je vous conseille vivement de consulter leur excellente documentation pour avoir une bonne idée de la richesse des informations fournies), mais la partie qui nous intéresse le plus pour la diarisation de notre système de salle est le tableau des "mots" (plus précisément, les "punctuated_word "s, car nous avons demandé à Deepgram de ponctuer chaque phrase pour nous). La diarisation de Deepgram fonctionne sur la base d'un mot, capable de faire la différence même lorsque les locuteurs se chevauchent, nous voulons donc examiner chaque MOT et les répartir par individu. Nous créons un tableau dont chaque entrée sera "ce que ce locuteur particulier a dit", puis nous itérons à travers les mots, en les décomposant et en les recomposant par locuteur :
let words = transcription.channel.alternatives[0].words
let message = [];
words.forEach(function each(word) {
if (word.speaker in message) {
message[word.speaker] += " " + word.punctuated_word
} else {
message[word.speaker] = word.punctuated_word
}
});Nous avons maintenant message[0] avec ce qu'a dit le premier orateur, message[1] avec ce qu'a dit le deuxième orateur, etc.
Et le tour est joué ! Nous pouvons renvoyer ces messages à l'interface graphique pour qu'elle les affiche comme il convient.
Nous disposons désormais d'un système de salle qui prend des notes de réunion et gère plusieurs intervenants, même s'ils se trouvent dans la même pièce !
Cliquez ici pour voir une vidéo de cette démonstration en action !
Vous pouvez également demander une démonstration personnelle à l'un de nos experts. Si vous avez des questions ou des commentaires, rejoignez-nous sur le Slack des développeurs de Vonage ou envoyez-nous un Tweet sur Twitter.
Partager:
Mark a développé des démos, mis en œuvre des POC et infligé son humour à des collègues peu méfiants chez Vonage pendant plus de 4 ans. Il programme professionnellement depuis 1979, et son expérience technique s'étend de FORTRAN sur des cartes perforées à React Native sur le cloud. Sa créativité et son enthousiasme pour le développement et le partage de solutions technologiques n'ont d'égal que son penchant pour les blagues de papa.