
Partager:
David is a Software Architect working on Vonage Call Centre, focussing on infrastructure, internal platform and frontend. He has experience across multiple industries including finance, IoT and Cloud Communications.
Datastores en libre-service
Temps de lecture : 5 minutes
Traditionnellement, les datastores sont gérés par des équipes de spécialistes et leur mise en place et leur gestion nécessitent beaucoup de travail. Cette approche peut fonctionner pour les architectures monolithiques. Cependant, pour les microservices avec un taux de changement plus élevé et l'objectif pour chacun d'eux d'avoir son propre magasin de données, ce modèle n'est pas évolutif. Cela peut rendre la création de microservices coûteuse et les équipes deviennent dépendantes d'une équipe centralisée.
Le CCV (Vonage Contact Center) a résolu ce problème en adoptant un système de libre-service en utilisant l'automatisation, permettant aux équipes d'effectuer elles-mêmes un grand nombre de ces tâches. Cependant, le libre-service étant un concept assez abstrait, notre première tâche a été de définir ce qu'un datastore en libre-service signifiait réellement pour nous.
Un datastore est "un référentiel permettant de stocker et de gérer de manière persistante des collections de données." Pour nous, cela signifie
Base de données relationnelle, par exemple MySQL
Base de données NoSQL, par exemple DynamoDB
Caches, par exemple Redis
Autres magasins comme Elasticsearch
Le libre-service signifie qu'une équipe peut
Créer et gérer leur magasin de données
Modifier le schéma
Modifier les données en toute sécurité
Soutenir leur magasin de données, y compris l'accès pour le débogage et le soutien à la production.
En soi, ces choses sont assez faciles à faire. Toutefois, pour éviter de créer plus de problèmes que nous n'en résolvons, nous devons également prendre en compte les éléments suivants :
Des outils qui intègrent les meilleures pratiques à l'aide de tests automatisés et de portes de qualité
Piste d'audit pour tous les accès et toutes les modifications afin de garantir la conformité
Barrières et façades multi-tenant (il n'est pas toujours économique d'avoir un cluster de base de données par microservice)
Complexité de la réplication à chaud, le cas échéant
Facilité d'utilisation, robustesse et dissimulation de la complexité interne
Les deux principales parties prenantes des datastores (les équipes qui exploitent les datastores et les équipes chargées des fonctionnalités qui utilisent les datastores) bénéficient du libre-service, mais de manière différente. Selon votre structure organisationnelle, il peut même s'agir de la même équipe ! Les deux graphiques suivants montrent le scénario de l'adoption du libre-service et de son amélioration continue par rapport à celui de l'inaction, sur une période de 18 mois.
Ces graphiques illustrent notre expérience de la manière dont les tâches habituelles (BAU), telles que les migrations de schémas, les modifications de données, etc. ont affecté les équipes lorsque la demande de datastores a augmenté au fil du temps.
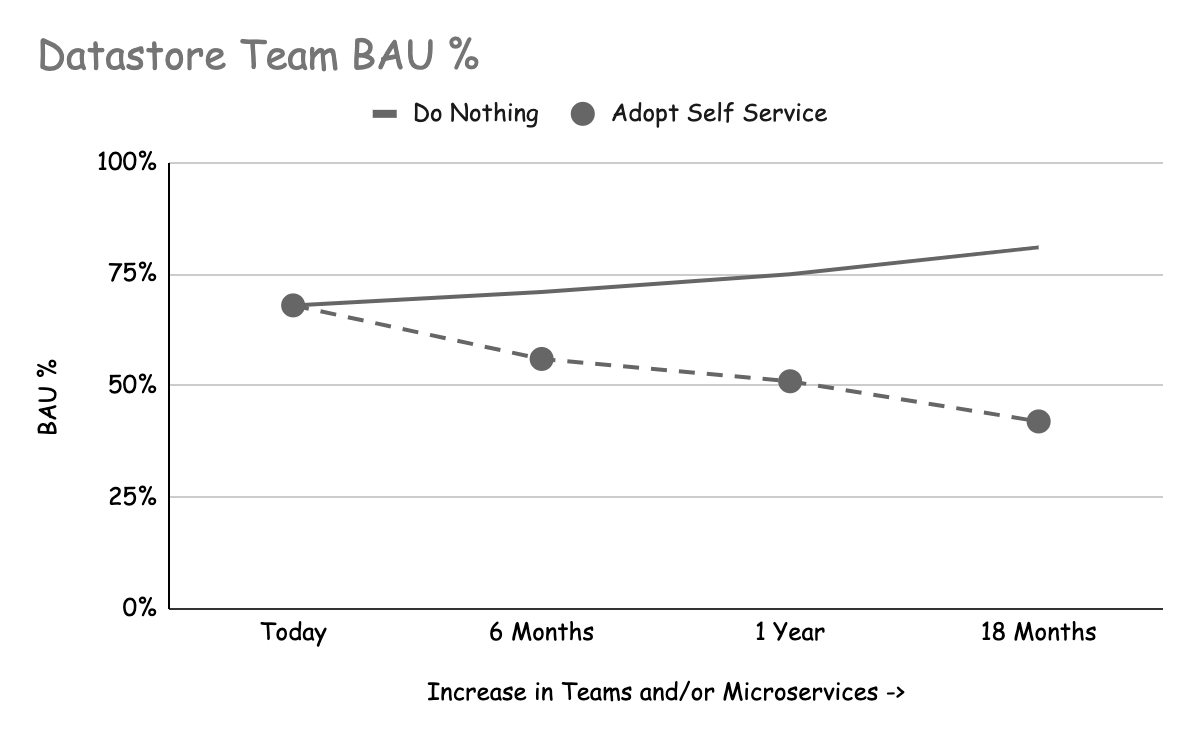 Impact from BAU tasks increases over time
Impact from BAU tasks increases over time
Si votre organisation augmente le nombre de microservices et/ou d'équipes qu'elle possède, il arrivera un moment où la quantité de BAU submergera votre (vos) équipe(s) de datastore. Vous pouvez y remédier en ajoutant du personnel, mais il est probable que cela ne suffira pas à répondre à la demande. Le passage à une stratégie de libre-service réduira le BAU en supprimant des tâches telles que la migration des schémas, tout en permettant à l'équipe du datastore de se concentrer sur des tâches à plus forte valeur ajoutée.
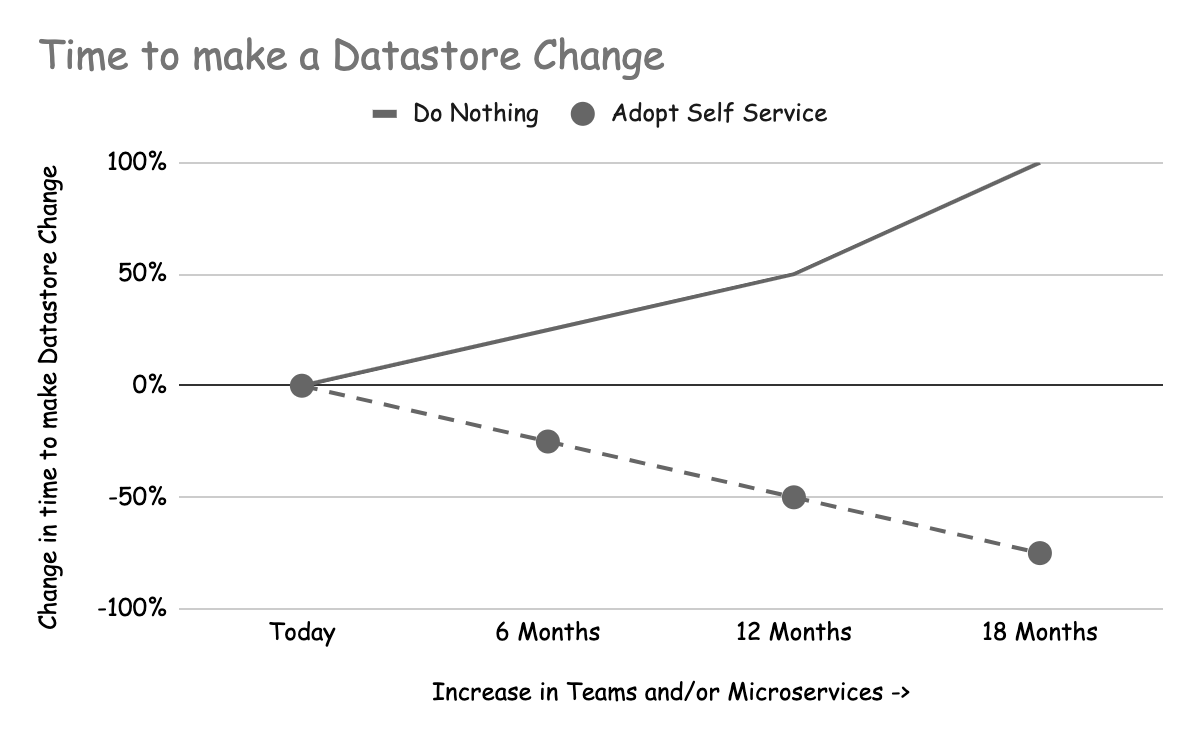 Time to make a datastore change increases over time
Time to make a datastore change increases over time
Les équipes chargées des fonctionnalités bénéficieront également du libre-service, car les changements apportés aux magasins de données seront plus rapides et moins coûteux au fur et à mesure que vous ajouterez des fonctionnalités en libre-service. Si les équipes chargées des fonctionnalités dépendent d'une équipe chargée du datastore pour effectuer ces changements à leur place, cette équipe peut devenir un goulot d'étranglement et augmenter le coût des changements. Ce coût se traduit principalement par le temps écoulé. Si l'équipe chargée du stockage des données commence à être débordée, les équipes chargées des fonctionnalités devront peut-être commencer à suivre les modifications qu'elles ont demandées pour s'assurer qu'elles sont bien apportées.
Maintenant que vous savez ce qu'est un entrepôt de données en libre-service et pourquoi nous en avons besoin, vous êtes probablement curieux de savoir ce que nous faisons pour passer à un modèle en libre-service.
Les équipes travaillant sur le CCV ont adopté le libre-service pour AWS Aurora MySQLce qui nous permet de créer automatiquement de nouveaux schémas pour les services et d'apporter des modifications aux schémas dans le cadre du pipeline CI. Il prend également en charge la fourniture des informations d'identification de la base de données et la configuration de l'accès aux microservices.
Le processus d'exécution des migrations (comme le montre le diagramme ci-dessous) implique une lambda qui orchestre la création de conteneurs Docker pour effectuer les migrations. La messagerie est utilisée pour la communication entre le système CI et le système de migration des schémas. Le processus créera également une base de données si le schéma n'existe pas encore.
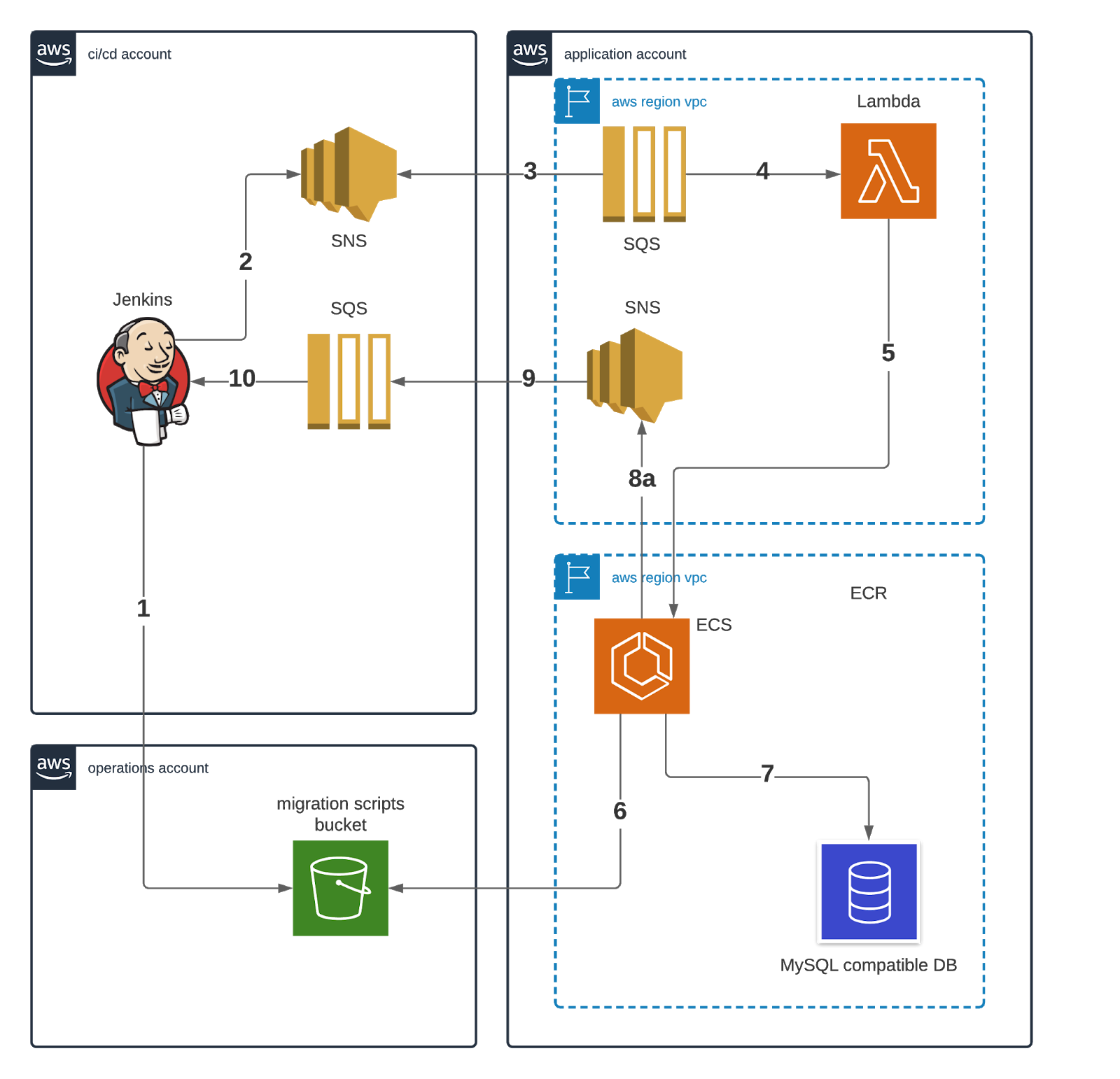
Le flux de travail du processus de migration est le suivant : Jenkins demande le déploiement d'une nouvelle version d'un schéma en (1) téléchargeant la migration dans le seau de scripts de migration, puis (2) en la publiant sur un sujet SNS. Ce dernier est récupéré par (3) un SQS, qui s'abonne au sujet et (4) déclenche la lambda de migration de schéma.
La lambda de migration de schéma (5) démarre une tâche ECS dont le conteneur (6) tire la migration du seau de script de migration et ensuite (7) exécute flyway en utilisant le script de migration sur le cluster aurora ciblé. À la fin de la migration (8), le conteneur publie un message SNS qui est (9) récupéré par une file d'attente SQS CI/CD qui (10) met à jour l'état de la tâche Jenkins pour indiquer qu'elle est terminée.
Pour ce faire, nous avons également élaboré des lignes directrices sur les meilleures pratiques spécifiques à notre architecture (par exemple, des considérations sur la réplication multi-clusters à chaud et les meilleures pratiques pour les migrations, afin que les équipes puissent éviter les pièges les plus courants).
Ensuite, nous envisageons d'ajouter des fonctionnalités en libre-service, telles que la possibilité de modifier les données en libre-service, de fournir davantage de mesures et d'outils pour l'analyse détaillée des requêtes. Nous voulons permettre un accès sécurisé et sans friction aux données, avec une intégration dans notre piste d'audit. Nous devons également vérifier que le travail que nous avons déjà effectué a apporté les avantages que nous attendions.
Enfin, nous cherchons à savoir si d'autres parties de Vonage peuvent tirer parti du travail que nous avons accompli. Cela est d'autant plus important que nous construisons la plateforme de communication de Vonage et l'architecture commune des plateformes internes. plateformes internes pour la soutenir.