
Partager:
Yotam est data scientist principal chez Vonage. Il apporte son doctorat en neurosciences computationnelles et sa passion pour la science des données éthiques à chaque projet qu'il entreprend. Il a notamment dirigé un projet de recherche financé par des subventions visant à créer un outil de communication contrôlé par le geste facial pour les patients atteints de SLA, grâce à une technologie d'électrodes frontales accessible et peu coûteuse.
L'homme dans la boucle vs. le LLM dans la boucle
Temps de lecture : 9 minutes
Dans le domaine de l'IA, il est essentiel de trouver un équilibre entre la supervision humaine ("l'homme dans la boucle") et l'automatisation ("LLM dans la boucle") pour élaborer des solutions concrètes. Chez Vonage AI, l'équipe responsable du développement des services d'IA au sein de Vonage, nous avons été confrontés à ce défi lors de la refonte de nos systèmes de conversion de la parole en texte (STT) afin de répondre à la demande croissante de transcription précise dans les centres d'appels.
Pour surmonter les limites de l'évaluation comparative traditionnelle, nous avons développé une nouvelle approche utilisant de grands modèles de langage (LLM) pour générer des transcriptions de référence de haute qualité en traitant les résultats de plusieurs fournisseurs de STT. Au lieu de s'appuyer sur des références générées par l'homme ou sur une "vérité de terrain" unique, le LLM synthétise une transcription consensuelle, en utilisant sa compréhension du langage et du contexte à travers les entrées.
Cette référence dérivée du LLM permet un calcul évolutif, impartial et contextuel du taux d'erreur de mots (WER) pour chaque fournisseur.
Dans cet article, nous expliquons comment cette méthode basée sur le LLM se compare au benchmarking traditionnel, en mettant l'accent sur les points suivants :
Les limites des méthodes actuelles d'évaluation des performances
Comment les LLM synthétisent les transcriptions de références
Principales conclusions de nos expériences
Chez Vonage AI, nous sommes une équipe de chercheurs et d'ingénieurs qui se consacrent à repousser les limites de ce qui est possible avec l'intelligence artificielle. Dans le cadre de l'engagement de Vonage en faveur des communications intelligentes, nous nous concentrons à la fois sur l'IA conversationnelle de pointe et sur la recherche fondamentale en matière d'apprentissage automatique, afin de fournir des solutions d'IA robustes, évolutives et tournées vers l'avenir. Ce billet présente l'un de nos efforts de recherche : repenser la façon dont nous évaluons la précision de la transcription dans un monde qui évolue rapidement et qui comporte de nombreux modèles.
Il y a quelques années, alors que nous affinions nos modèles STT pour les différents dialectes présents dans le centre d'appel de nos clients, nous avons décidé de les adapter à la réalité. centres d'appels de nos clients, nous nous appuyions fortement sur des annotateurs humains pour transcrire les extraits audio. de nos clients, nous faisions largement appel à des annotateurs humains pour transcrire les extraits audio. Ces transcriptions servaient de "vérité de base" pour l'entraînement et l'évaluation de nos modèles internes.
Ce processus prend du temps et ralentit les cycles de développement.
Les coûts élevés rendent difficile une mise à l'échelle efficace.
Les réviseurs humains commencent souvent par des transcriptions existantes, ce qui peut introduire un biais inhérent dans leurs corrections.
La tâche est exigeante sur le plan mental, ce qui augmente le risque d'erreur humaine au fil du temps.
Cependant, les défis se sont avérés payants ; notre modèle propriétaire finement ajusté a finalement surpassé les principales solutions tierces pour notre cas d'utilisation spécifique.
Au fur et à mesure que les besoins des clients évoluaient, nous avons été confrontés à de nouveaux défis en matière d'étiquetage manuel
La prise en charge de nouvelles langues et de nouveaux dialectes a nécessité le recrutement d'experts humains parlant couramment chaque langue spécifique.
Les tests sur des cas d'utilisation spécifiques à l'industrie, tels que la transcription médicale, ont exigé des humains ayant une expertise dans le domaine.
La croissance rapide des modèles avancés à code source ouvert a multiplié les possibilités d'évaluation, de déploiement et d'ajustement ; nous avions donc besoin d'un moyen évolutif et cohérent d'évaluer la précision sans avoir à attendre des semaines pour la transcription manuelle.
Nous sommes donc entrés dans une nouvelle ère : LLM dans la boucle.
Au lieu de compter sur les humains pour transcrire l'audio pour la vérité de base, nous utilisons maintenant un grand modèle de langage (LLM) pour générer des transcriptions de référence. Le LLM analyse les résultats de différents systèmes de transcription et raisonne entre eux pour produire la reconstruction la plus précise de ce qui a été dit, en s'alignant parfois sur les résultats d'un modèle pour un segment partiel de l'audio et sur les résultats d'un autre modèle pour une partie différente de l'audio.
C'est comme avoir un arbitre intelligent et rapide :
Lire plusieurs transcriptions d'un même fichier audio
Comprendre le contexte et les nuances linguistiques
produit une "référence" fiable et impartiale permettant de comparer les modèles entre eux
Pour valider le concept, nous avons traité un corpus bien connu que nous avions préalablement étiqueté manuellement. Nous l'avons utilisé pour estimer la précision du pipeline piloté par LLM tout en évaluant la contribution originale de l'effort d'étiquetage manuel.
Voici ce que nous avons conçu :
Nous avons transcrit les mêmes extraits audio de 5 à 15 secondes en utilisant plusieurs systèmes STT, y compris nos propres modèles internes, des modèles à source ouverte et des fournisseurs tiers.
Pour chaque clip, nous avons recueilli toutes les transcriptions ainsi que les étiquettes humaines originales. Nous avons ensuite présenté au LLM ces alternatives (sans connaître leurs sources) et lui avons demandé de générer la transcription la plus précise et la plus probable pour cet extrait.
En utilisant cette "vérité de terrain synthétique" générée par le LLM sur ~300 échantillons, nous avons calculé le taux d'erreur de mot (WER) pour chaque système STT.
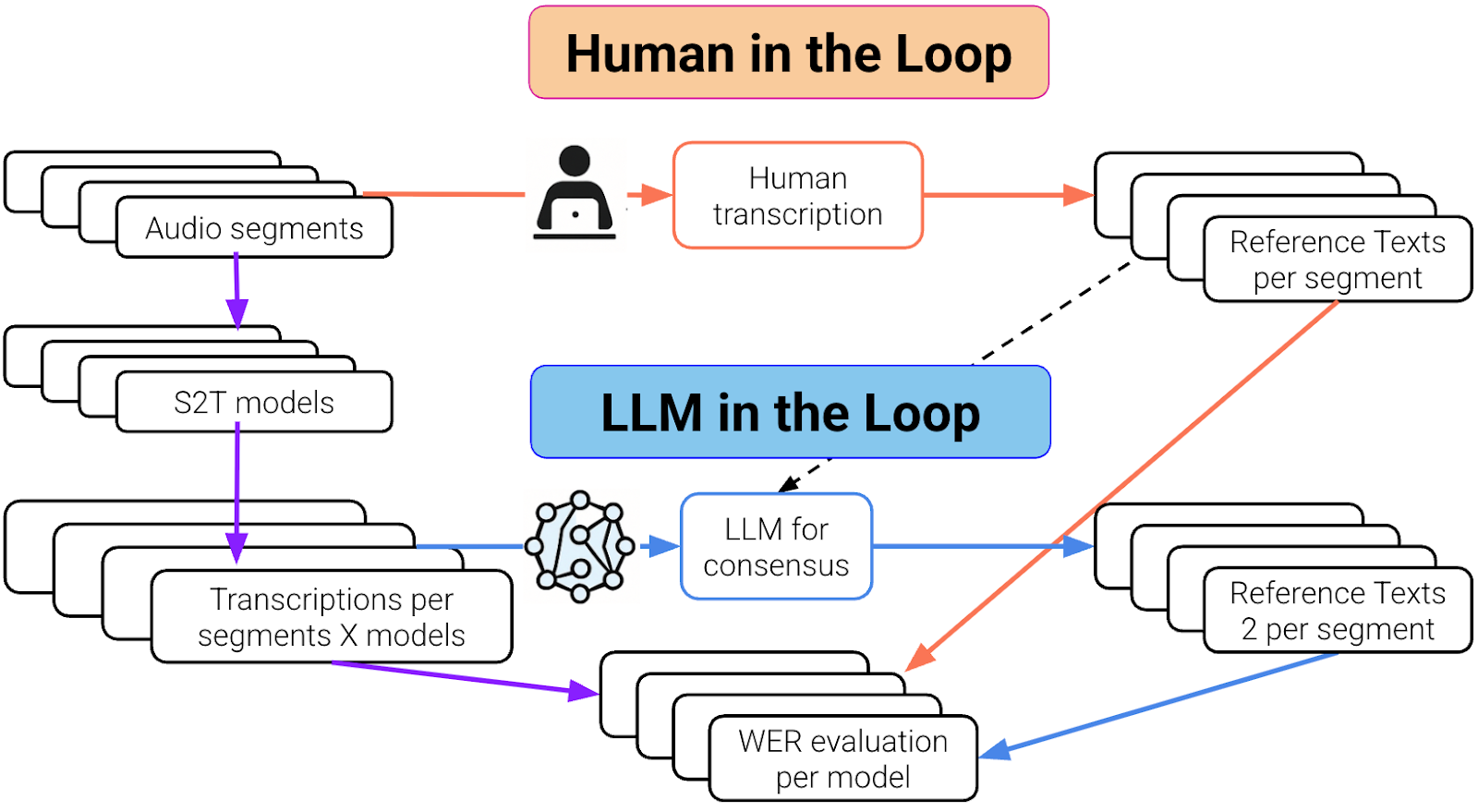 Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
La boucle humaine et la boucle LLM. La partie violette est commune aux deux boucles.
Imaginons que nous ayons les sorties STT suivantes de différents fournisseurs pour un court extrait audio d'agent :
 Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Ces transcriptions varient en termes de formatage, de représentation numérique et de précision, reflétant les résultats typiques de différents modèles.
Le LLM est chargé de générer deux transcriptions de référence alignées :
Référence alphabétique :
Si le délai de vingt-quatre heures est dépassé, l'annulation jusqu'à huit jours avant l'arrivée entraînera des frais de cinquante dollars.
Référence alphanumérique :
Si le délai de 24 heures est dépassé, les frais d'annulation jusqu'à 8 jours avant l'arrivée s'élèvent à 50 dollars.
Cette approche garantit une comparaison équitable (et non biaisée par le formatage) entre différents types de résultats de modèles : les modèles non formatés (tels que notre solution) sont évalués par rapport à des références non formatées, tandis que les modèles compatibles avec le formatage sont évalués par rapport à des références formatées qui préservent une signification équivalente.
Les modèles suivants ont été testés :
Vonage AI (VAI) - Notre modèle interne affiné, formé sur des données étiquetées manuellement par la même équipe.
Vonage AI (VAI) - Notre ancienne version du modèle, non adaptée à ce cas d'utilisation.
Les transcriptions originales marquées par l'homme
Trois modèles open-source d'OpenAI : Whisper-Large(V3), Whisper-Medium, Whisper-Petit
Deux fournisseurs tiers
Pour examiner le rôle des références humaines, nous avons utilisé le pipeline d'évaluation basé sur le LLM dans deux configurations :
Label-In : La transcription humaine a été incluse dans les résultats alternatifs présentés au LLM pour la synthèse de référence.
Label-Out : La transcription humaine a été exclue (en aveugle) des alternatives présentées au LLM.
Nous avons comparé les deux pour évaluer la robustesse de la référence générée par le LLM et les biais potentiels introduits par les données étiquetées par l'homme.
Nous avons utilisé le taux d'erreur de mots (WER) comme principale mesure d'évaluation. Il s'agit d'une mesure standard de la qualité de la transcription. Le WER quantifie le nombre d'erreurs dans une transcription en la comparant à une référence. Ces erreurs se répartissent en trois catégories :
Insertions : mots supplémentaires ajoutés
Suppressions : mots manquants
Substitutions : mots incorrects à la place des mots corrects
Le WER est calculé à l'aide de la formule suivante :
 Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Un WER plus faible indique une transcription plus précise.
 Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Les WERs étaient presque identiques dans les deux configurations, démontrant la robustesse des références générées par le LLM.
Classement et valeurs WER stables pour la plupart des modèles, qu'il s'agisse de l'introduction ou de la suppression d'étiquettes.
"3rd-Party 2" a montré une amélioration notable lorsque l'étiquette humaine a été exclue (WER 10.5 → 9.5), suggérant un meilleur alignement avec les sorties générées par LLM qu'avec les annotations humaines.
Dans le cadre de cette évaluation, les transcriptions marquées par l'homme présentaient un REE plus élevé que presque tous les modèles automatisés. Ce résultat était prévisible, étant donné que le corpus a été transcrit par des personnes dont l'anglais n'est pas la langue maternelle et que l'outil d'annotation ne comportait pas de protection contre les fautes de frappe.
Le modèle VAI Fine-tuned formé sur des étiquettes humaines par la même équipe a encore surpassé son homologue non réglé (WER 13,7 → 12,5), ce qui montre l'utilité de ces données malgré leurs imperfections.
Ces résultats démontrent que les transcriptions de référence générées par LLM sont fiables, cohérentes et évolutives pour l'évaluation des systèmes STT. Les WERs et les classements presque identiques à travers les évaluations, avec ou sans données étiquetées par l'homme, soulignent la robustesse du pipeline.
Bien que certains modèles puissent mieux s'aligner sur la tokenisation ou le style de formatage du LLM (comme on le voit avec "3rd-Party 2"), dans l'ensemble, les références dérivées du LLM offrent une méthode d'évaluation juste et reproductible.
Il est important de noter que, bien que les références étiquetées par l'homme présentent des taux d'erreur plus élevés, elles restent précieuses pour l'entraînement des modèles. La mise au point sur ces données a permis d'améliorer considérablement les performances des modèles, ce qui réaffirme le rôle des données étiquetées dans le développement des modèles, même lorsque l'évaluation peut être automatisée.
Les LLM peuvent générer des transcriptions de référence fiables, ce qui permet de réaliser des analyses comparatives évolutives à haut débit.
Les références étiquetées par l'homme ne sont plus nécessaires pour l'évaluation, mais offrent toujours des avantages pour la formation.
Cette méthode accélère l'analyse comparative équitable entre les nouveaux modèles, les nouvelles langues et les nouveaux domaines, en éliminant le besoin de transcription manuelle.
Vous souhaitez créer votre propre agent d'intelligence artificielle et comparer différentes solutions ? Vous pouvez essayer votre propre AI Studio Agent et le combiner avec diverses solutions tierces comme Deepgram et voir ce qui fonctionne le mieux pour vous.
Vous avez une question ou souhaitez partager ce que vous construisez ?
Rejoignez la conversation sur le Communauté Vonage Slack
S'abonner à la Bulletin d'information du développeur
Suivez-nous sur X (anciennement Twitter) pour les mises à jour
Regardez les tutoriels sur notre chaîne YouTube
Connectez-vous avec nous sur la page Vonage Developer sur LinkedIn
Restez connecté et tenez-vous au courant des dernières nouvelles, astuces et événements concernant les développeurs.
Partager:
Yotam est data scientist principal chez Vonage. Il apporte son doctorat en neurosciences computationnelles et sa passion pour la science des données éthiques à chaque projet qu'il entreprend. Il a notamment dirigé un projet de recherche financé par des subventions visant à créer un outil de communication contrôlé par le geste facial pour les patients atteints de SLA, grâce à une technologie d'électrodes frontales accessible et peu coûteuse.