Présentation de l'Audio Connector SDK et du Pipecat Serializer pour les applications audio de l'IA
Temps de lecture : 6 minutes
Les applications d'IA en temps réel transforment la façon dont les développeurs créent des expériences vocales et vidéo. Qu'elles alimentent des services de transcription, des agents conversationnels, des traductions en temps réel ou des analyses de sentiments, les applications modernes nécessitent de plus en plus d'accéder à l'audio brut en mouvement, et pas seulement à la fin d'un enregistrement ou après le téléchargement d'un fichier.
Pipecat, un framework open-source, améliore l'intégration des API Video et Voice de Vonage avec des connecteurs audio en fournissant une plateforme modulaire et indépendante des fournisseurs pour l'orchestration des flux de travail d'IA. Avec des fonctionnalités telles que la latence ultra-faible, la détection avancée de l'activité vocale et la prise en charge multimodale, Pipecat permet aux développeurs de créer des expériences d'IA conversationnelle très réactives et naturelles. Sa flexibilité permet une intégration transparente avec une gamme de modèles et de services d'IA, ce qui en fait un choix idéal pour construire des applications audio et vidéo riches et en temps réel.
Pour soutenir cette nouvelle génération d'applications intelligentes, Vonage a introduit deux outils complémentaires conçus spécifiquement pour les développeurs : le Vonage Audio Connector Python Server SDK et le Vonage Serializer pour Pipecat. Ensemble, ils facilitent considérablement le streaming audio entre les sessions Video et Voice de Vonage, les serveurs WebSocket et les frameworks d'IA tels qu'OpenAI, Deepgram ou AWS Nova Sonic.
Ce blog donne un aperçu de ces outils, explique comment ils s'articulent entre eux et fournit des références pour le déploiement de votre premier agent doté d'IA.
De nombreux flux de travail d'IA - la conversion de la parole en texte, l'analyse pilotée par LLM, la synthèse vocale et la perception multimodale - dépendent de l'audio en temps réel. Les développeurs qui travaillent avec les API Voice et Video de Vonage demandent depuis longtemps un moyen simple et fiable de recevoir de l'audio d'une session active, de le traiter et de renvoyer des réponses.
Le connecteur audio de Vonage pour l'API Video et le Voice API WebSocket permet aux développeurs de créer des serveurs WebSocket qui relient les sessions Vonage aux flux de travail de l'IA.
Cependant, la création de serveurs WebSocket à faible latence, la gestion de trames audio binaires, la coordination des taux d'échantillonnage et le maintien de connexions avec état peuvent s'avérer complexes et sujets aux erreurs. Cette complexité ralentit souvent l'expérimentation, le développement de la validation du concept et les déploiements en production.
Le SDK du connecteur audio de Vonage élimine ce problème.
La chaîne d'outils prend en charge un large éventail d'expériences d'IA en temps réel, notamment :
Transcription de la parole au texte
Assistants de réunion basés sur le LLM
Analyse du sentiment ou de l'intention dans les appels en direct
Bots vocaux interactifs
Traduction linguistique en temps réel
Prise de notes ou résumé automatisé
Modération audio et détection de la conformité
Le schéma suivant présente l'architecture d'une session vidéo ou d'une conversation vocale intégrée au SDK Audio Connector via une WebSocket. Le SDK est un paquetage Python (disponible sur PyPI) qui fait abstraction de la complexité de la gestion des flux audio WebSocket des sessions Vonage.
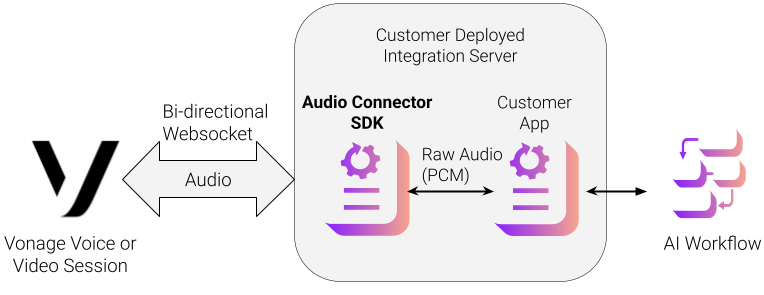
Serveur WebSocket événementiel pour la réception et l'envoi d'audio PCM
Prise en charge d'échantillons de 8 kHz, 16 kHz et 24 kHz avec traitement automatique des trames
Rappels asynchrones propres pour les événements de connexion, de déconnexion, de message et d'erreur
Contrôle intégré de la mémoire tampon et de la synchronisation pour une lecture fluide
Plusieurs connexions simultanées pour les flux de travail multi-agents ou multi-participants
Prise en charge de TLS pour des déploiements de production sécurisés
Cela permet aux développeurs de se concentrer entièrement sur ce qu'ils veulent construire - pipelines de transcription, outils d'analyse, assistants vocaux - sans avoir besoin d'écrire une quelconque infrastructure WebSocket.
Le SDK peut être installé à partir de l'index des paquets Python à l'aide d'un gestionnaire de paquets Python.
pip install vonage-audio-connector-server
Le guide du développeur Guide du développeur SDK fournit une référence de base pour la configuration et le démarrage du serveur WebSocket, la mise en place de gestionnaires asynchrones pour la gestion des sessions et de l'audio, et l'injection de l'audio dans la session Video via le WebSocket.
Des informations sur l'ouverture d'une connexion WebSocket entre une session Video et un serveur à l'aide du SDK sont disponibles sur la Page du développeur du connecteur audio. Des informations sur l'ouverture d'une connexion WebSocket à partir d'une conversation Voice vers un serveur à l'aide du SDK sont disponibles sur la page du développeur de Voice WebSockets page du développeur.
Vous pouvez cloner le code d'exemple pour l'utilisation de l'Audio Connector SDK à partir du dépôt dépôt GitHub
Pipecat est un framework open-source permettant d'orchestrer des workflows d'IA complexes dans les domaines de l'audio, de la vidéo, des images et du texte. Pour les applications axées sur l'audio, le nouveau Vonage Serializer pour Pipecat sert de pont entre les sessions Voice et Video de Vonage et un pipeline de traitement Pipecat.
Convertit les trames audio Vonage entrantes dans le format de trame interne de Pipecat.
Alignement des fréquences d'échantillonnage et des encodages audio
Prise en charge des DTMF et autres métadonnées
Convertit les trames audio Pipecat sortantes en trames Vonage WebSocket
Cela signifie que les développeurs peuvent utiliser la liste croissante de nœuds d'IA de Pipecat - OpenAI Realtime, Deepgram, Whisper, ElevenLabs, etc. - sans avoir à écrire de code de traduction des médias.
Le sérialiseur fournit une ligne directe entre l'audio d'un participant en direct et un flux de travail d'IA entièrement programmable.
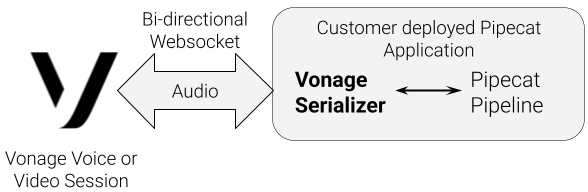
Guide du sérialiseur Guide du sérialiseur fournit une référence de base pour configurer le Serializer de Vonage avec Pipecat.
Utilisation du Connecteur audio Vonage SDK ou Pipecat Serializer offre aux développeurs un moyen propre, moderne et adapté à Python de créer des agents audio en temps réel, sans avoir à réinventer les serveurs WebSocket ou les pipelines multimédias.
Que vous souhaitiez créer un bot vocal, intégrer la synthèse vocale à un LLM, générer des réponses synthétisées en temps réel ou analyser le comportement des appels, ces outils fournissent les bases dont vous avez besoin.
Si vous êtes prêt à commencer, explorez :
Le paquet Paquet PyPI pour le SDK Audio Connector
Exemples d'applications pour le SDK
Le sérialiseur sérialiseur Vonage Pipecat
Exemples de Vonage dans le repo de Pipecat
Grâce à ces outils, vous pouvez déployer votre premier agent d'IA en quelques minutes - et construire en toute confiance vers des applications entièrement intelligentes et sensibles aux médias sur la plateforme Vonage.
Vous avez une question ou souhaitez partager ce que vous construisez ?
Rejoignez la conversation sur le Communauté Vonage Slack
S'abonner à la Bulletin d'information du développeur
Suivez-nous sur X (anciennement Twitter) pour les mises à jour
Regardez les tutoriels sur notre chaîne YouTube
Connectez-vous avec nous sur la page Vonage Developer sur LinkedIn
Restez connecté et tenez-vous au courant des dernières nouvelles, astuces et événements concernant les développeurs.