
Partager:
Max est un ancien membre de l'équipe Vonage. Il était « Developer Advocate » Python et ingénieur logiciel, passionné par les API de communication, l'apprentissage automatique, l'expérience développeur et la danse ! Il a suivi une formation en physique, mais il travaille désormais sur des projets open source et crée des outils destinés à faciliter la vie des développeurs.
Améliorez votre projet logiciel - Troisième partie : Améliorations de niveau supérieur
Temps de lecture : 14 minutes
Avez-vous déjà pris en charge une base de code et réalisé que vous n'étiez pas satisfait de la façon dont le code était écrit ou organisé ? C'est une histoire courante, mais qui peut causer bien des maux de tête. La dette technique peut faire boule de neige, rendant la compréhension du code et l'ajout de nouvelles fonctionnalités exponentiellement plus difficiles.
Dans cette série en trois parties, je vais passer en revue certaines des choses clés que vous voudrez faire pour devenir plus heureux avec votre (ancien) projet brillant. Pour donner des exemples concrets, j'expliquerai comment j'ai remanié et amélioré le logiciel libre Vonage Python SDKune bibliothèque qui fait des appels HTTP aux API de Vonage, mais les principes s'appliquent à n'importe quel type de projet logiciel.
Les exemples de ce billet seront écrits en Python, mais ces principes s'appliquent à des projets dans n'importe quel langage. Il y a également une liste de contrôle pratique à suivre si vous essayez spécifiquement de corriger un projet Python.
Troisième partie : Améliorations du niveau suivant (cet article)
Si vous avez suivi première partie et deuxième partie de cette série, vous avez une bonne compréhension de votre projet et vous avez peut-être déjà procédé à des remaniements, ajouté des fonctionnalités et publié de nouvelles versions.
Dans la troisième partie, nous aborderons les sujets suivants :
Améliorer votre projet
L'outillage que vous pouvez utiliser
Automatisation
Bonnes pratiques pour transmettre un projet à quelqu'un d'autre
Les améliorations qui peuvent être apportées à une base de code se répartissent en deux groupes :
Améliorations qui profitent directement à l'utilisateur, et
Améliorations qui profitent au responsable de la maintenance.
Commençons par discuter des améliorations apportées aux utilisateurs.
Lorsqu'un utilisateur rencontre une erreur, l'utilité de cette erreur pour l'aider à découvrir ce qui ne va pas peut varier considérablement. Prenons deux exemples distincts.
L'illustration A montre une façon d'écrire une fonction qui vérifie la validité d'un paramètre d'entrée d'une méthode. La méthode en question permet à un utilisateur d'envoyer des messages via des canaux tels que SMS, MMS, WhatsApp, Messenger et Viber avec l Vonage Messages API. Cette vérification permet de s'assurer que l'utilisateur a spécifié un canal valide.
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise ExceptionDans ce cas, si l'utilisateur ne spécifie pas de canal de message valide, il verra simplement qu'une exception a été levée. Il ne disposera d'aucune information spécifique et devra fouiller dans sa pile d'appels pour trouver la cause de l'erreur.

L'illustration B montre une autre façon d'écrire ce code.
from .errors import MessagesError
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise MessagesError(f"""
'{params['channel']}' is an invalid message channel.
Must be one of the following types: {self.valid_message_channels}'
""")Dans ce cas, j'ai créé une erreur personnalisée liée à l'API Messages de Vonage. Je spécifie un message d'erreur qui décrit le problème exact du code de l'utilisateur et ce qu'il peut faire pour le résoudre. C'est beaucoup plus clair pour l'utilisateur et cela peut lui faire gagner beaucoup de temps en matière de débogage !

Nous pouvons voir ci-dessus que l'utilisateur a essayé d'envoyer un message "pigeon voyageur" via l'API Messages, qui est un canal non pris en charge. Cet exemple montre à quel point vous pouvez aider vos utilisateurs en créant des exceptions personnalisées pour faciliter le débogage.
Si vos utilisateurs doivent transmettre des données aux fonctions de votre code, vous pouvez vous interroger sur les contrôles que vous effectuez sur ces données d'entrée. Si vous utilisez une approche basée sur des classes fortement typées, comme le Java orienté objet, votre code essaiera de rassembler les données d'entrée dans une structure appropriée. Si vous utilisez une approche moins stricte, vous voudrez peut-être valider les données saisies par l'utilisateur afin de renvoyer une erreur dès que possible si les choses ne sont pas correctes.
Examinons quelques exemples réels. Voici du code provenant du SDK qui envoie un SMS :
def send_message(self, params):
...
return self._client.post(
self._client.host(),
"/sms/json",
params, # This is the user's input!
supports_signature_auth=True,
**Sms.defaults,
)Si vous appelez cette méthode, les choses suivantes se produisent :
paramssont transmises à la fonctionsms.send_messagepar l'utilisateurCes valeurs sont immédiatement transmises à une autre fonction, la méthode
postde laclientclasseLa méthode
posteffectue une requête post et renvoie la réponse à l'utilisateur.
Au cours de ce processus, l'entrée de l'utilisateur est immédiatement affectée à l'objet sans aucune validation. params sans aucune validation. Cela convient aux cas simples, mais si l'API avec laquelle nous communiquons accepte de nombreuses combinaisons d'options, nous pouvons envisager de valider l'entrée de l'utilisateur.
Excellente question. Si tout ce que nous allons faire est de lancer une erreur de toute façon, pourquoi se donner la peine ? Il s'agit là d'un exemple parfait de l'approche "approche "fail-fastL'approche "fail-fast" : le fait d'attraper les erreurs à la racine du problème rend le débogage beaucoup plus facile et signifie que moins de ressources sont utilisées pour faire des requêtes qui seront rejetées.
Voici un autre exemple, cette fois-ci à partir de l'API Vonage Messages API:
def send_message(self, params: dict):
self.validate_send_message_input(params) # This calls the function below
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params, # This is still the user's input, but if we get here, we know it's valid!
auth_type=self._auth_type,
)
def validate_send_message_input(self, params):
# Each of these lines calls a different check on the user's input
# An error is thrown if any of the checks fail
self._check_input_is_dict(params)
self._check_valid_message_channel(params)
self._check_valid_message_type(params)
self._check_valid_recipient(params)
self._check_valid_sender(params)
self._channel_specific_checks(params)
self._check_valid_client_ref(params)Nous pouvons constater que, cette fois, l'entrée de l'utilisateur est soigneusement vérifiée afin de ne pas envoyer une requête erronée.
Si l'écriture de contrôles manuels est efficace, il convient également d'envisager une approche basée sur les classes ou les modèles si vous devez valider un grand nombre d'entrées utilisateur. Dans certains langages, cette fonction est mise en œuvre par le biais de classes fortement typées, où le constructeur d'une classe attend une entrée spécifique pour créer une instance de cette classe. Dans ce cas, le fait de demander à l'utilisateur de créer des classes valides et de les passer à vos autres fonctions permet de s'assurer que l'utilisateur transmet les bonnes données. En Python, nous n'avons pas de système de typage prêt à l'emploi qui fonctionne de cette manière, mais il existe des bibliothèques telles que Pydantic qui peuvent créer des modèles pour faire cela pour vous.
J'ai réécrit le code ci-dessus en utilisant une approche basée sur les modèles avec Pydantic pour utiliser les modèles pour la validation des entrées :
# I created models (that look like classes) that inherit from Pydantic's BaseModel class.
# I'm able to specify specific constraints, including the type and length of parameters, and specify defaults.
class Message(BaseModel):
to: constr(min_length=7, max_length=15)
sender: constr(min_length=1)
client_ref: Optional[str]
class SmsMessage(Message): # Inherits the properties of the "Message" model
channel = Field(default='sms', const=True)
message_type = Field(default='text', const=True)
text: constr(max_length=1000)
... # More classes for each type of message that the Messages API can send
class Messages: # Class that contains the code to call the Messages API
... # Skipping showing the constructor etc. here
def send_message_from_model(self, message: Message):
params = message.dict()
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params,
auth_type=self._auth_type,
)Cette version peut sembler plus compliquée que la précédente, mais elle nous évite d'écrire manuellement toutes les vérifications. Désormais, si un utilisateur veut envoyer un message et qu'il se trompe dans une partie de la saisie, il obtiendra une erreur judicieuse indiquant ce qu'il a pu faire de travers.

Désormais, la validation est étroitement liée à l'instanciation de la classe. Dans l'implémentation précédente, la validation devait être écrite manuellement et n'était pas obligatoire. En utilisant cette approche basée sur le modèle avec Pydantic, nous pouvons garantir qu'il n'y a plus aucune chance de passer des entrées invalides.
En résumé, lorsque vous traitez des entrées utilisateur, pensez à les valider. La manière dont vous procédez à cette validation dépend de votre langue et de l'approche que vous avez adoptée, mais le fait de disposer d'une certaine forme de validation peut faire gagner beaucoup de temps à vos utilisateurs.
La dernière amélioration potentielle pour l'utilisateur que je souhaite identifier concerne le code asynchrone. À moins que votre projet ne traite d'opérations liées à l'interface utilisateur, vous n'aurez peut-être pas besoin d'y réfléchir - dans ce cas, passez directement à la section suivante.
Le code asynchrone est un code dans lequel les opérations peuvent abandonner le contrôle d'un thread pour permettre à d'autres choses de se produire. Il est à comparer au code synchrone, qui attend la fin de chaque opération avant de commencer la suivante. Certains langages (par exemple Node.js) sont asynchrones par défaut, mais d'autres langages disposent de fonctionnalités asynchrones qui peuvent être utilisées en cas de besoin. Si vous êtes un développeur JavaScript, vous pouvez probablement sauter cette section.
Si votre code effectue une requête et doit attendre longtemps une réponse, il peut être intéressant d'écrire votre code de manière asynchrone et de permettre à d'autres choses de se produire jusqu'à ce que vous receviez une réponse. Dans le cas du SDK Python de Vonage, nous effectuons des requêtes HTTP vers un serveur distant. Nous le faisons de manière synchrone, il est donc intéressant de se demander si une version asynchrone d'une partie du SDK serait bénéfique pour mes utilisateurs. Nous pouvons supposer que la création d'une méthode asynchrone permettrait d'envoyer plus de requêtes à la fois avec le SDK... mais pourquoi supposer ? Faisons une expérience.
Pour déterminer si la création de méthodes asynchrones permettrait de réduire le temps nécessaire pour effectuer des requêtes, j'ai écrit deux morceaux de code. Le premier utilisait une fonction du SDK Python de Vonage comme d'habitude pour effectuer 100 requêtes HTTP à l'API Number Insight API de Vonage et l'autre utilisait une version asynchrone de la fonction que j'avais créée. J'ai profilé les deux versions du code (en utilisant la méthode de profilage que j'ai décrite dans la première partie de cette série, ici) et nous pouvons voir que la majorité du temps passé dans le programme est consacré aux requêtes HTTP.
La première image ci-dessous est un graphique en forme de glaçon qui montre le sommet de la pile d'appels de notre SDK lorsqu'il effectue 100 demandes auprès d'une API de Vonage.
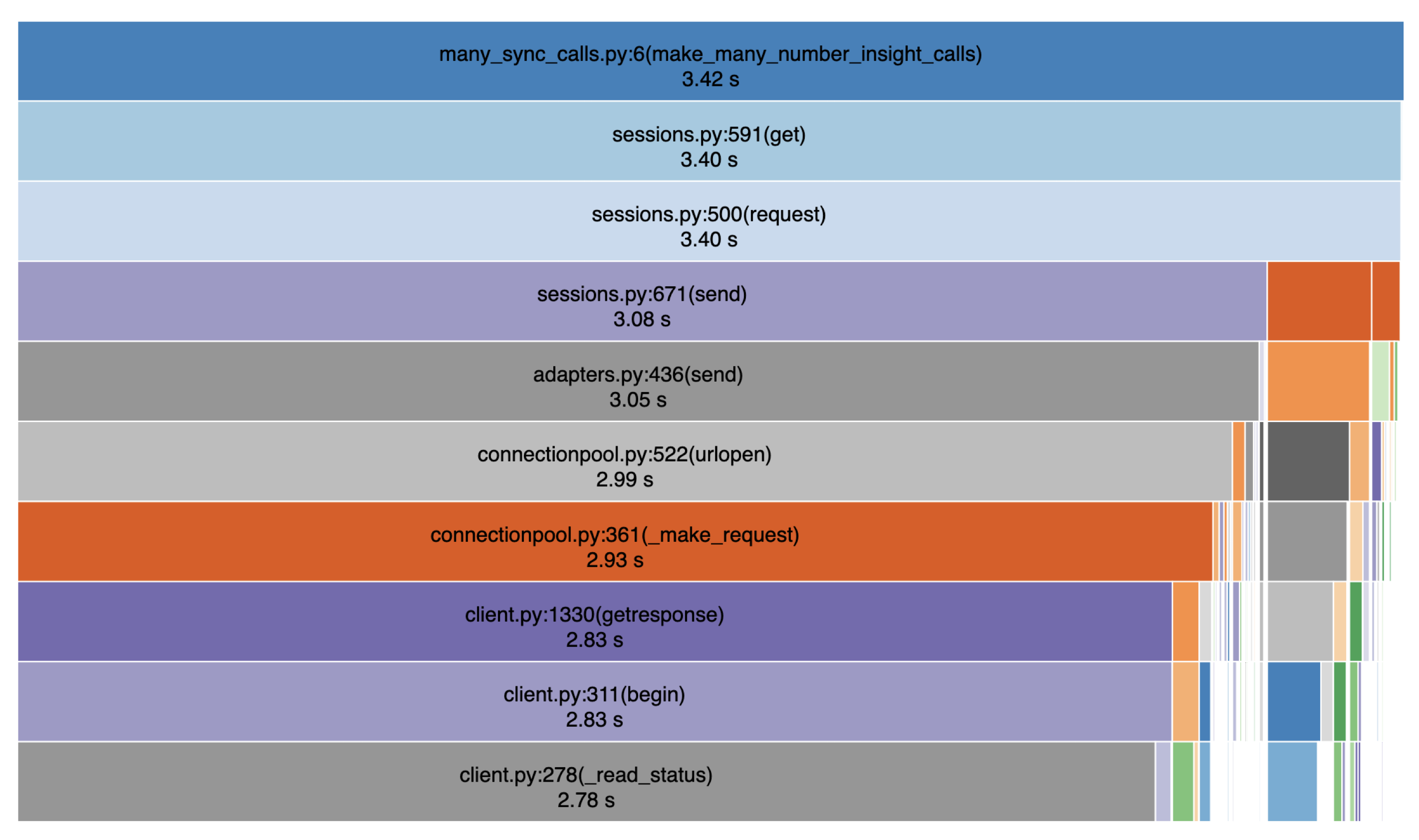
L'image suivante montre le bas de la pile d'appels. Comme vous pouvez le voir ici, la majeure partie du temps d'exécution du programme (2,78/3,42 secondes, soit 81 % !) est consacrée à l'attente des connexions SSL entre notre code et le serveur distant. Et ce n'est qu'une partie du processus où nous devons attendre lorsque nous faisons des appels de synchronisation.

Cela suggère que si le code pouvait abandonner le contrôle du thread jusqu'à ce que les connexions soient établies, la durée d'exécution pourrait être beaucoup plus courte ! Voici les données d'une version asynchrone du code, qui effectue les mêmes 100 requêtes à la même API.

Nous pouvons voir sur le graphique ci-dessus que la tâche entière a été accomplie en 0,33 seconde, soit environ 10 fois plus vite que la version synchrone ! Dans ce cas, il est logique que j'étudie la possibilité de rendre mon code asynchrone.
Le dernier paragraphe semble assez peu engageant, étant donné que je viens de rendre le code 10x plus rapide. Pourquoi ne voudrais-je pas commencer immédiatement à asynchroniser mon code ? Eh bien, cela peut rendre les choses beaucoup plus compliquées.
Bien que le code asynchrone fonctionne bien dans de nombreux cas, il présente des inconvénients importants. Pour rendre mon code asynchrone, je devrais en réécrire une grande partie. En Python, les coroutines asynchrones se comportent très différemment des méthodes normales ; elles doivent être appelées et traitées très différemment.
Pire encore, il y a la question du support. Si je devais réécrire entièrement la bibliothèque pour la rendre asynchrone et publier une nouvelle version majeure du projet (comme nous l'avons vu dans la partie 2), j'obligerais mes utilisateurs à réécrire tout leur code qui utilise mon SDK ! Si je ne voulais pas imposer cette épreuve à mes utilisateurs, je devrais maintenir des versions synchrones et asynchrones du même code, ce qui reviendrait à doubler la taille de la base de code. Cela représente deux fois plus de code à tester, et si je voulais ajouter de nouvelles fonctionnalités, je devrais le faire deux fois.
Il existe des moyens d'alléger la charge, mais l'ajout d'un support asynchrone représenterait toujours un investissement en temps important. Dans l'ensemble, l'asynchronisme est très puissant, mais réfléchissez bien aux cas d'utilisation de votre base de code. Si vous pensez qu'il y a un avantage très important, envisagez de rendre les choses asynchrones, mais réfléchissez bien avant de vous engager à le faire. Et si vous êtes un programmeur JavaScript qui a lu cette section même si c'est ainsi que votre code fonctionne de toute façon, j'espère que cela a été instructif, ou au moins divertissant. 🤷
Si vous souhaitez investir dans la santé à long terme de votre projet, vous voudrez probablement mettre en place des outils qui vous aideront à écrire votre code ou vous donneront un aperçu de certains aspects de celui-ci. J'ai mentionné quelques outils dans la première partie de cette série mais parlons maintenant plus concrètement de l'application d'outils automatisés à votre code.
En supposant que votre code utilise le contrôle de version, il est possible de mettre en place des outils qui s'exécutent lorsque le code est poussé ou que des rapports de presse sont rédigés, etc. Il existe de nombreux outils pour ce faire. Dans mon cas, le SDK Python de Vonage utilise les outils suivants GitHub Actionsqui est gratuit pour les projets open-source hébergés sur GitHub, et même pour les dépôts GitHub privés en dessous d'un certain quota d'utilisation.
Dans mon repo, j'ai mis en place une action GitHub qui exécute des tests lorsqu'un push ou un PR est effectué et calcule la couverture du code. L'avantage d'utiliser l'automatisation est que je peux tester sur plusieurs plateformes et versions de Python sans avoir à configurer manuellement une VM pour chaque plateforme et un nouvel environnement virtuel pour chaque version de Python. Je vous recommande de configurer vos tests de cette manière, car vous pouvez détecter les erreurs avant qu'elles n'atteignent votre environnement de production. avant qu'elles n'atteignent votre environnement de production.

En première partie de cette série nous avons brièvement discuté des avantages que les tests de mutation peuvent apporter. Il peut être facile de tomber dans le piège de l'augmentation de la couverture du code, quel qu'en soit le coût. La loi de Goodhart stipule que "lorsqu'une mesure devient une cible, elle cesse d'être une bonne mesure". Les développeurs qui s'investissent trop dans les mesures de couverture du code ont tendance à sacrifier la qualité des tests au profit de la quantité de couverture. Le score de mutation est un moyen d'éviter cela.
Le score de mutation est lié à la capacité de vos tests à résister aux changements. Comme nous l'avons vu dans la première partie, les tests de mutation fonctionnent en modifiant votre code de manière subtile, puis en appliquant vos tests unitaires à ces nouvelles versions "mutantes" de votre code.
Les tests de mutation peuvent prendre un certain temps pour être exécutés sur une base de code importante. Heureusement, comme il s'agit d'une méthode de test automatisée, il est possible d'ajouter les tests de mutation dans un pipeline de construction/révélation. J'ai décidé de le faire pour le SDK Python de Vonage, en utilisant une bibliothèque de mutations Python appelée bibliothèque de mutation Python appelée mutmut.
J'ai mis en place une action GitHub "Mutation Test" qui exécute un test de mutation sur la base de code, comme indiqué ci-dessous :
Ce flux de travail a un déclencheur d'exécution manuelle. En effet, une exécution automatisée sur push ou PR prendrait plus de temps que je ne le souhaite. Le déclenchement manuel du flux de travail signifie que je peux l'exécuter chaque fois que je souhaite obtenir un aperçu de l'état de ma base de code.

Le flux de travail du test de mutation génère une sortie HTML qu'il met à disposition pour le téléchargement à l'intérieur de l'exécution du test spécifique. Cette sortie contient un fichier d'index présentant une vue d'ensemble, puis une liste des mutations qui ont échappé à la détection pour chaque module.
Nous pouvons voir ici que nous avons capturé 383/522 versions mutantes du code, soit environ 74%. C'est un bon résultat, mais nous pouvons voir des divergences entre les modules et nous pourrions vouloir en rechercher la cause. Il n'est pas toujours productif d'essayer d'obtenir le score le plus élevé (rappelez-vous la loi de Goodhart !), mais nous pouvons utiliser ces métriques pour mieux comprendre ce que font nos tests. Il est plus important d'avoir un score de mutation qui s'améliore constamment (même si c'est très lentement) que d'avoir un score élevé.
Si votre projet utilise des dépendances, vous devez être certain d'utiliser des versions de celles-ci qui ne compromettent pas la sécurité de vos utilisateurs. De nombreux outils automatisés peuvent vérifier cela pour vous, par exemple Mend pour GitHub.comMend pour GitHub.com, qui analyse périodiquement votre code à la recherche de vulnérabilités et soulève des problèmes et des PR pour tenter de corriger les vulnérabilités.
Il est important d'utiliser un outil qui suit les bases de données de vulnérabilités et les avis de sécurité, car de nouvelles menaces sont découvertes en permanence.
Cette série s'est principalement concentrée sur la situation où vous avez commencé à travailler sur un projet existant, mais vous ne serez probablement pas responsable de ce projet pour toujours. À un moment donné, vous transmettrez probablement le code à quelqu'un d'autre, et c'est une bonne pratique que d'utiliser vos dernières semaines de travail sur un projet pour vous assurer que le transfert se passe aussi bien que possible. Vous avez peut-être entendu la règle adaptée des scouts par Bob Martin: laissez le code dans un meilleur état que celui dans lequel vous l'avez trouvé.
À deux semaines de la remise des clés, il est temps de cesser d'accepter tout nouveau travail. À ce stade, votre travail doit consister à créer un transfert transparent. Terminez ou abandonnez toutes les fonctionnalités et fusionnez ou fermez tous les PR ouverts. Dans l'idéal, vous devriez passer à l'étape importante de la rédaction dès que possible.
Documenter l'état du code. Il s'agit notamment de s'assurer que les README et la documentation sont à jour, au cas où le code ne serait pas touché pendant un certain temps, mais aussi de rédiger un document de passation de pouvoir ! Vous ne voulez pas que votre successeur ait à passer au crible de nombreuses branches ouvertes de code non validé pour découvrir ce que vous aviez prévu. Votre document de passation doit comprendre les éléments suivants
Un aperçu de la base de code
Comment commencer à développer le projet
Vue d'ensemble des tests
Le travail que vous avez commencé mais que vous n'avez pas terminé
Travail que vous avez prévu de faire, et pourquoi
Tout autre élément non documenté ou non évident
Enfin, votre successeur pourrait vous contacter pour discuter du code. Envisagez de les contacter si vous en avez le temps. C'est bien d'être gentil !
Si vous lisez ceci, félicitations ! Vous êtes dans une position idéale pour rendre un projet que vous possédez aussi génial que possible.
Si vous avez des questions ou des idées à partager, vous pouvez nous contacter sur notre Communauté Vonage Slack ou nous envoyer un message sur sur Twitter.
Merci de m'avoir accompagné dans ce voyage et bonne chance pour tous vos projets futurs.
Partager:
Max est un ancien membre de l'équipe Vonage. Il était « Developer Advocate » Python et ingénieur logiciel, passionné par les API de communication, l'apprentissage automatique, l'expérience développeur et la danse ! Il a suivi une formation en physique, mais il travaille désormais sur des projets open source et crée des outils destinés à faciliter la vie des développeurs.