
Partager:
Développeur IOS devenu passionné de science des données et d'apprentissage automatique. Je veux que les gens comprennent ce qu'est l'apprentissage automatique et comment nous pouvons l'utiliser dans nos Applications.
Construire un classificateur d'images avec Tensorflow
Temps de lecture : 9 minutes
Dans ce billet, vous allez construire un modèle de classification d'images de base pour traiter les images envoyées par les membres d'une conversation dans une app iOS intégrée à Nexmo In-App Messaging. Après qu'un utilisateur ait téléchargé une image, une légende décrivant l'image sera affichée.
Nous allons utiliser Python pour construire notre modèle de classification d'images. Ne vous inquiétez pas si vous n'avez jamais travaillé avec Python ou si vous n'avez pas de connaissances préalables en matière d'apprentissage automatique.
La classification d'images dans le cadre de l'apprentissage automatique consiste à prendre une photo, et le modèle d'apprentissage automatique est capable de déterminer le sujet de la photo. Par exemple, si vous prenez la photo d'un chien, le modèle d'apprentissage automatique sera capable de dire "C'est un chien".
Tout d'abord, pour construire un modèle d'apprentissage automatique, nous avons besoin de données pour l'entraîner.
Un modèle d'apprentissage automatique utilise des données d'entraînement pour apprendre. Pour commencer, nous devons choisir les données d'entraînement. Pour cet article, nous utiliserons les données de CIFAIR-10 .
Cet ensemble de données contient des images réparties en 10 classes, avec 6000 images par classe. Il s'agit d'un ensemble de données bien utilisé pour l'apprentissage automatique, et il constituera un bon point de départ pour notre projet. Comme l'ensemble de données est relativement petit, nous pouvons entraîner le modèle rapidement.
Ce carnet est hébergé sur Google Colab. Colaboratory est un environnement de bloc-notes Jupyter gratuit qui ne nécessite aucune installation et fonctionne entièrement dans le nuage.
Account, vous devez disposer d'un compte Google pour exécuter le bloc-notes.
L'exécution du carnet est très simple. Dans chaque cellule contenant du code, un bouton d'exécution se trouve à gauche de la cellule. Appuyez sur ce bouton pour exécuter le code. Vous pouvez également utiliser la commande clavier Shift puis Enter.
La première chose à faire est d'importer nos paquets. Ces paquets sont pré-installés sur Google Colab, nous n'avons donc pas besoin de les installer.
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as npNous utilisons Tensorflow et Keras comme interface avec Tensorflow. Keras est un excellent framework qui vous permet de construire des modèles plus facilement, sans avoir à utiliser les méthodes plus verbeuses de Tensorflow.
Ensuite, nous allons charger le jeu de données CIFAR. Grâce à Keras, nous pouvons télécharger l'ensemble de données très facilement.
Nous avons divisé l'ensemble de données en deux groupes, l'un pour l'entraînement, l'autre pour le test. (x_train, y_train)et l'autre pour le test (x_test, y_test).
La division de l'ensemble de données permet au modèle d'apprendre à partir de l'ensemble d'apprentissage. Ensuite, lorsque nous testons le modèle, nous voulons voir s'il a bien appris en utilisant l'ensemble de données de test. Nous obtenons ainsi notre précision, c'est-à-dire l'efficacité du modèle.
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print('y_train shape', y_train.shape)
print(x_test.shape[0], 'test samples')
print('x_test shape', x_test.shape)
print(y_test.shape[0], 'test samples')Using TensorFlow backend.
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 75s 0us/step
x_train shape: (50000, 32, 32, 3)
50000 train samples
y_train shape (50000, 1)
10000 test samples
x_test shape (10000, 32, 32, 3)
10000 test samplesEnsuite, nous allons déclarer quelques constantes.
batch_sizeest le nombre d'échantillons qui vont être propagés dans le réseau.epochsreprésentent le nombre de fois où nous nous entraînons sur l'ensemble des données.class_namesest une liste de toutes les étiquettes possibles dans l'ensemble de données CIFAR-10.
batch_size = 32
epochs = 100
class_names = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]Nous utiliserons ces constantes plus tard lors de la conversion de notre modèle en CoreML.
def plot_images(x, y, number_of_images=2):
fig, axes1 = plt.subplots(number_of_images,number_of_images,figsize=(10,10))
for j in range(number_of_images):
for k in range(number_of_images):
i = np.random.choice(range(len(x)))
title = class_names[y[i:i+1][0][0]]
axes1[j][k].title.set_text(title)
axes1[j][k].set_axis_off()
axes1[j][k].imshow(x[i:i+1][0])Tout d'abord, jetons un coup d'œil à quelques images. Nous avons une fonction qui trace 4 images aléatoires et leur étiquette correspondante.
plot_images(x_train, y_train) Image recognition Tensorflow CoreML
Image recognition Tensorflow CoreML
Nous allons maintenant mettre en place un modèle simple. Nous créons un réseau neuronal profond à l'aide de convolutions, dropoutet mise en commun maximale.
Au final, nous allons aplatir le réseau et utiliser Relusuivi d'un Softmax.
Cela nous donnera un vecteur (matrice à une dimension), rempli de 0 pour la plupart.
Il se présentera comme suit.
[0,0,0,0,0,0,1,0,0,0]Ce vecteur correspond à l'étiquette donnée dans l'image. 1 à la septième place serait une grenouille, puisque "grenouille" se trouve à la septième place de la liste. class_names liste.
L'illustration suivante montre l'ensemble du réseau.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10, activation='softmax'))C'est tout !
Tout d'abord, nous compilons le modèle pour obtenir sa perte. La perte est une mesure de l'efficacité du modèle lors des tests. Une perte élevée signifie que le modèle s'est mal comporté.
Ici, vous utilisez Adam Optimizerun algorithme qui s'étend à une descente de gradient stochastique largement utilisée pour l'apprentissage automatique, pour calculer la perte.
Ensuite, nous appellerons .fit qui entraînera le modèle pendant 100 époques. Cela signifie que l'ensemble des données d'entraînement sera entraîné 100 fois. batch_size de 32 est le nombre d'échantillons qui vont être propagés à travers le réseau.
Nous voyons ensuite comment il s'est comporté après chaque époque en utilisant model.evaluate. Cela nous donne un score pour le modèle (les nombres les plus élevés sont les meilleurs) et la perte (les nombres les plus bas sont les meilleurs).
Remarque : cette opération a duré environ 15 minutes sur Colab. Si vous voulez voir les résultats plus rapidement, réglez le paramètre epochs à 1 ou 2. La précision ne sera toutefois pas aussi bonne.
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])
# Train the model
model.fit(x_train / 255.0, tf.keras.utils.to_categorical(y_train),
batch_size=batch_size,
shuffle=True,
epochs=epochs,
validation_data=(x_test / 255.0, tf.keras.utils.to_categorical(y_test))
)
# Evaluate the model
scores = model.evaluate(x_test / 255.0, tf.keras.utils.to_categorical(y_test))
print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])Train on 50000 samples, validate on 10000 samples
Epoch 1/100
#Omitted for readability
50000/50000 [==============================] - 30s 603us/step - loss: 0.1378 - acc: 0.9518 - val_loss: 0.7136 - val_acc: 0.8116
10000/10000 [==============================] - 2s 151us/step
Loss: 0.714
Accuracy: 0.812Notre précision finale était de 81 %, et notre perte de 0,7, ce qui est plutôt bon.
Pour rappel, la précision correspond à la capacité du modèle à classer chaque image, tandis que la perte indique à quel point les prédictions du modèle sont mauvaises.
Pour plus d'informations, consultez la définition de la perte et de la précision dans le cours accéléré sur l'apprentissage automatique de Google. cours accéléré de Google sur l'apprentissage automatique.
Après avoir entraîné le modèle, nous pouvons l'enregistrer, puis le convertir au format Core ML.
Présenté lors de la WWDC 2018, Core ML permet aux développeurs iOS d'intégrer une grande variété de types de modèles d'apprentissage automatique dans une app iOS. Ici, vous utilisez cette technologie avec Nexmo In-App Messaging pour faciliter votre propre apprentissage profond pour le traitement des images.
Tout d'abord, nous devons enregistrer le modèle formé.
model.save('cifar-model.h5')Nous utiliserons coremltools, qui convertira le modèle dans un format utilisable par notre application Stitch.
Remarque : le paquetage Core ML n'est pas préinstallé sur Colab, nous devons donc l'installer à l'aide de la commande pip
Ci-dessus, vous pouvez voir que le paquet a été installé dans notre ordinateur portable.
Ensuite, nous allons convertir le modèle enregistré en Core ML.
Comme nous avons utilisé Keras pour entraîner notre modèle, il est très facile de le convertir à Core ML. Cependant, cela varie en fonction de la façon dont vous avez construit votre modèle. Les outils Core ML ont d'autres fonctions à utiliser pour d'autres packages d'apprentissage automatique, y compris Tensorflow et Scikit Learn. Voir le coremltools repo pour plus d'informations.
from keras.models import load_model
import coremltools
model = load_model('cifar-model.h5')
coreml_model = coremltools.converters.keras.convert(model,
input_names="image",
image_input_names="image",
image_scale=1/255.0,
class_labels=class_names)
coreml_model.save('CIFAR.mlmodel') 0 : conv2d_input, <keras.engine.topology.InputLayer object at 0x7fa7c829fac8>
1 : conv2d, <keras.layers.convolutional.Conv2D object at 0x7fa7c829f358>
2 : conv2d__activation__, <keras.layers.core.Activation object at 0x7fa7c75bf198>
3 : conv2d_1, <keras.layers.convolutional.Conv2D object at 0x7fa7c80e40b8>
4 : conv2d_1__activation__, <keras.layers.core.Activation object at 0x7fa7c75bf438>
5 : max_pooling2d, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c80e4550>
6 : conv2d_2, <keras.layers.convolutional.Conv2D object at 0x7fa7c77434a8>
7 : conv2d_2__activation__, <keras.layers.core.Activation object at 0x7fa7c73f9240>
8 : max_pooling2d_1, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c7743f28>
9 : conv2d_3, <keras.layers.convolutional.Conv2D object at 0x7fa7c87ad1d0>
10 : conv2d_3__activation__, <keras.layers.core.Activation object at 0x7fa7c7262dd8>
11 : max_pooling2d_2, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c7743f60>
12 : flatten, <keras.layers.core.Flatten object at 0x7fa7c76fac50>
13 : dense, <keras.layers.core.Dense object at 0x7fa7c76b42b0>
14 : dense__activation__, <keras.layers.core.Activation object at 0x7fa7c71ff390>
15 : dense_1, <keras.layers.core.Dense object at 0x7fa7c7670358>
16 : dense_1__activation__, <keras.layers.core.Activation object at 0x7fa7c71ff898>La sortie ci-dessus montre toutes les couches à l'intérieur du modèle. Celles-ci sont directement liées à la façon dont nous avons créé le modèle dans cette cellule.
Jetez un coup d'œil aux paramètres de la fonction convert . Ici, nous allons définir l'entrée comme étant un image pour les paramètres input_names et image_input_names et pour les paramètres. Cela permettra au modèle Core ML de savoir quel type d'entrée il attend, à savoir une image.
Ensuite, nous réduisons l'échelle des images dans le paramètre image_scale à un nombre compris entre 0 et 1.
Ensuite, nous fixons le paramètre class_labels à la constante class_names que nous avons créée précédemment.
Lorsque nous utilisons ce modèle dans Xcode, le résultat sera a Stringcorrespondant à l'étiquette prédite de l'image.
Nous pouvons maintenant examiner le modèle Core ML.
print(coreml_model)input {
name: "image"
type {
imageType {
width: 32
height: 32
colorSpace: RGB
}
}
}
output {
name: "output1"
type {
dictionaryType {
stringKeyType {
}
}
}
}
output {
name: "classLabel"
type {
stringType {
}
}
}
predictedFeatureName: "classLabel"
predictedProbabilitiesName: "output1"Vous pouvez voir que notre input est une image de 32x32 pixels, et que notre sortie est une chaîne de caractères, appelée classLabel
Ensuite, nous enregistrons localement le modèle mlmodel en utilisant un paquet Google Colab pour télécharger le fichier sur notre machine.
from google.colab import files
files.download('CIFAR.mlmodel')
Une fois notre modèle sauvegardé, nous pouvons maintenant l'importer dans notre application. Pour ce faire, il suffit de faire glisser le modèle qui vient d'être sauvegardé dans Xcode.
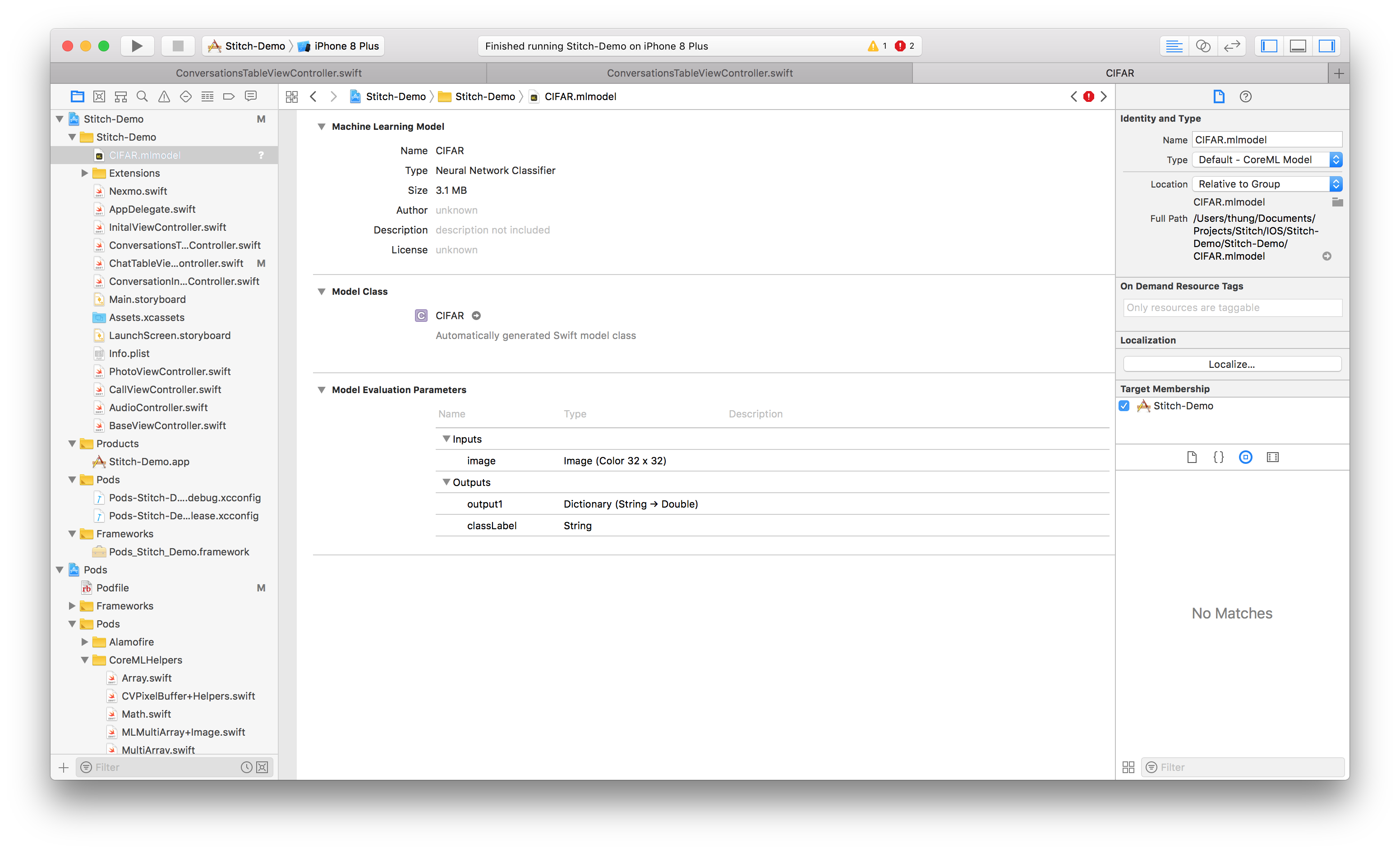 CIFAR xcode
CIFAR xcode
Assurez-vous que le modèle est inclus dans la cible en vérifiant que l'option Adhésion à la cible est sélectionnée.
Ensuite, nous allons écrire le code dans notre application iOS qui utilisera ce modèle.
Dans notre Stitch Demo Applicationles utilisateurs peuvent télécharger une photo dans une conversation existante.
In-App Messaging de Nexmo permet aux utilisateurs, en tant que membres d'une conversation, de déclencher non seulement des TextEvents mais ImageEvents en téléchargeant une photo dans une conversation existante. Pour cet exemple, nous allons essayer de prédire le contenu de la photo qu'un utilisateur a téléchargée.
Vous intégrez la fonctionnalité d'observation ImageEvents pour Core ML directement dans votre ViewController. Un exemple de la manière dont cela peut être fait peut être trouvé sur le code source de cet exemple.
Dans notre ViewController, nous allons instancier le modèle.
let model = CIFAR()Maintenant, à l'intérieur de la méthode cellForRowAtPath nous allons vérifier si le event est un ImageEventet si c'est le cas, nous affichons la photo de l'événement ImageEvent. Ensuite, nous prenons l'image, la convertissons en une image PixelBufferà une taille de 32x32 pixels, puis nous l'introduisons dans le modèle.
La raison pour laquelle nous devons rééchantillonner l'image est que le modèle est entraîné sur des images de 32x32 pixels, donc si nous ne redimensionnons pas les images, le modèle ne sera pas en mesure de donner une prédiction (nous verrons une erreur dans Xcode disant que la taille de l'image est incorrecte).
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: "cell", for: indexPath)
let event = conversation?.events[indexPath.row]
switch event {
case is ImageEvent:
//get the image from the ImageEvent
let imageEvent = (event as! ImageEvent)
guard let imagePath = imageEvent.path(of: IPS.ImageType.thumbnail), let image = UIImage(contentsOfFile: imagePath) else {
break
}
cell.imageView?.image = image
//convert the image to a pixelBuffer
//using https://github.com/hollance/CoreMLHelpers.git
if let pixelBuffer = image.pixelBuffer(width: 32, height: 32) {
let input = CIFARInput(image: pixelBuffer)
//perform the prediction
if let output = try? model.prediction(input: input) {
cell.textLabel?.text = (imageEvent.from?.name)! + " uploaded a photo of a \(output.classLabel)"
}
else {
cell.textLabel?.text = (imageEvent.from?.name)! + " uploaded a photo"
}
}
break;
default:
cell.textLabel?.text = ""
}
return cell;
}Le modèle renvoie alors un classLabel. Il s'agit du nom de l'image prédite par le modèle, qui peut être l'une des étiquettes suivantes : "avion", "automobile", "oiseau", "chat", "cerf", "chien", "grenouille", "cheval", "bateau" ou "camion"
Après avoir examiné nos prédictions, nous pouvons dire que le modèle ne pourra reconnaître que 10 étiquettes. Le cahier complet est disponible sur GitHub.
C'est bien pour une démo, mais pas pour une application de production. Dans un prochain article, nous nous pencherons sur la construction d'un modèle de reconnaissance d'images avec plus de données. Nous nous pencherons sur la populaire base de données ImageNetqui contient 14 197 122 images étiquetées.
Il s'agit d'un téléchargement de 150 Go, nous verrons donc comment le télécharger, le former et l'intégrer dans notre application de démonstration Stitch.