
Partager:
Développeur IOS devenu passionné de science des données et d'apprentissage automatique. Je veux que les gens comprennent ce qu'est l'apprentissage automatique et comment nous pouvons l'utiliser dans nos Applications.
Construction d'un modèle d'apprentissage automatique pour la détection des machines à répondre
Temps de lecture : 7 minutes
Avez-vous déjà eu besoin d'un moyen de détecter si un répondeur était en communication vocale ? Non ? Ce n'est pas grave. Je l'ai fait !
Ce billet suppose que vous avez une expérience de base de Python, ainsi qu'une compréhension très élémentaire de l'apprentissage automatique. Nous allons passer en revue quelques concepts de base sur l'apprentissage automatique, et nous avons mis des liens vers d'autres ressources tout au long de ce post.
Il y a quelques semaines, l'un de nos ingénieurs commerciaux m'a demandé de mettre en place un service de détection de répondeurs pour un client. Il souhaitait un moyen d'envoyer un message à un répondeur lorsque l'appel tombait sur la messagerie vocale.
J'ai fait quelques recherches à ce sujet et cela semble possible, mais je n'ai rien trouvé sur la manière dont cela a été fait. J'ai donc décidé de me débrouiller...
La première idée a été de construire un modèle d'apprentissage automatique qui détecte le moment où le son d'un répondeur est entendu. beep son d'un répondeur téléphonique. Dans ce billet, nous allons voir comment le modèle a été entraîné et déployé dans une application.
Avant de commencer à construire un modèle d'apprentissage automatique, nous devons disposer de données. Pour ce problème, nous avons besoin d'un ensemble de fichiers audio contenant les sons du répondeur beep comme celui-ci :
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4 ou ceci :
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4
Nous devons également inclure des échantillons qui n'incluent pas le bip sonore :
https://soundcloud.com/user-872225766-984610678/7eaeb600-0202-11e9-bb68-51880c8718e4
Étant donné que ce type de données ne semble pas exister sur l'internet, nous avons dû rassembler autant d'échantillons que possible de bips et d'autres sons provenant d'appels, afin d'entraîner notre modèle. Pour ce faire, j'ai créé une page web qui permet à chacun d'enregistrer le message d'accueil de sa boîte vocale.
Lorsque vous appelez le numéro Vonage, l'application crée un appel sortant vers le même numéro. Lorsque l'appel est reçu, il suffit de l'envoyer directement à la messagerie vocale. Ensuite, nous enregistrons l'appel à l'aide de l'action record action et nous sauvegardons le fichier dans un panier de Google Cloud Storage. Après avoir recueilli un grand nombre d'exemples, nous pouvons commencer à examiner les données.
Dans tout projet d'apprentissage automatique, l'une des premières choses à faire est d'examiner les données et de s'assurer qu'elles sont exploitables.
Comme il s'agit d'un fichier audio, nous ne pouvons pas regarder directement, mais nous pouvons visualiser les fichiers audio à l'aide d'un mel-spectrogramme, qui ressemble à ceci :
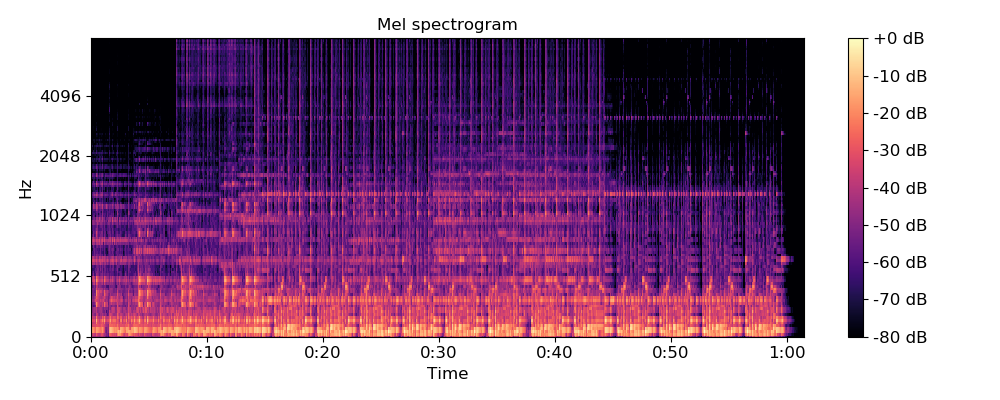
Un mel-spectrogramme montre une gamme de fréquences (les plus basses en bas de l'écran, les plus hautes en haut) et indique l'intensité sonore des événements à différentes fréquences. En général, les événements bruyants apparaissent brillants et les événements silencieux apparaissent sombres.
Nous devrons charger quelques fichiers de ces deux types de sons, les tracer et voir à quoi ils ressemblent. Pour montrer le mel-spectrogramme, nous utiliserons un paquetage Python appelé Librosa pour charger l'enregistrement audio, puis nous tracerons le mel-spectrogramme à l'aide de matplotlibun autre paquetage Python permettant de tracer des diagrammes et des graphiques.
import glob
import librosa
import matplotlib.pyplot as plt
%matplotlib inline
def plot_specgram(file_path):
y, sr = librosa.load(file_path)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128,fmax=8000)
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.power_to_db(S,ref=np.max),y_axis='mel', fmax=8000,x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title(file_path.split("/")[-2])
plt.tight_layout()
sound_file_paths = [
"answering-machine/07a3d677-0fdd-4155-a804-37679c039a8e.wav",
"answering-machine/26b25bb7-6825-43e7-b8bd-03a3884ed694.wav",
"answering-machine/2a685eda-8dd9-4a4d-b00e-4f43715f81a4.wav",
"answering-machine/55b654e5-7d9f-4132-bc98-93e576b2d665.wav",
"speech-recordings/110ac98e-34fa-42e7-bbc5-450c72851db5.wav",
"speech-recordings/3840b850-02e6-11e9-aa3d-ad1a095d8d72.wav",
"speech-recordings/55b654e5-7d9f-4132-bc98-93e576b2d665.wav",
"speech-recordings/81270a2a-088b-4e3c-9f47-fd927a90b0ab.wav"
]
for file in sound_file_paths:
plot_specgram(file)Voyons à quoi ressemble chaque fichier audio.
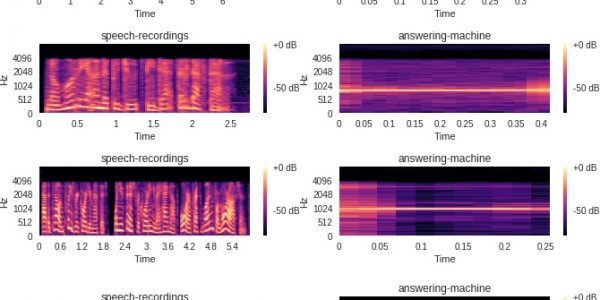
Vous pouvez clairement distinguer le fichier audio qui est un beep et celui qui est juste speech.
Avant d'entraîner notre modèle, nous allons prendre tous les enregistrements dont nous disposons, qu'il s'agisse de bips ou de non-bips, qui sont étiquetés. beeps et les non-bips, qui sont étiquetés comme speechet convertir chaque enregistrement en un vecteur de nombres, puisque notre modèle n'acceptera que des nombres, et non des images.
Pour calculer les données, nous utiliserons les coefficients cepstraux de fréquence mélodique (MFCC) de chaque échantillon. Ensuite, nous enregistrerons cette valeur dans un fichier csv afin de ne pas avoir à recalculer les MFCC.
Pour chaque échantillon audio, le fichier csv contiendra le chemin d'accès à l'échantillon audio, l'étiquette de l'échantillon audio (beepou speech), le MFCC, et la durée de l'échantillon audio (en utilisant la fonction get_duration dans librosa). Nous avons également essayé quelques autres caractéristiques audio, notamment la chrominance, le contraste et tonnetz). Cependant, ces caractéristiques n'ont pas été utilisées dans la dernière version du modèle.
Examinons maintenant les 5 premières lignes du fichier csv, pour voir à quoi ressemblent les données.
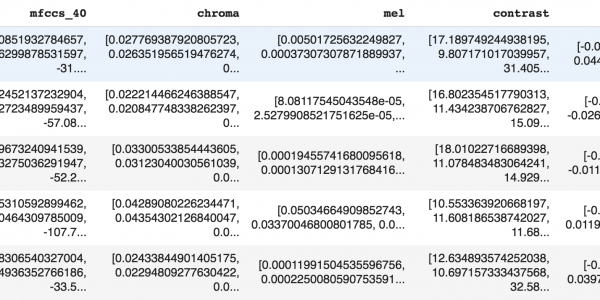
Chaque ligne contient un vecteur à une dimension de chacune des caractéristiques audio. C'est ce que nous utiliserons pour entraîner notre modèle.
Nous allons maintenant utiliser ces données pour former un modèle. Nous utiliserons le paquet Scikit-learn pour effectuer notre apprentissage. Scikit-learn est un excellent paquetage qui vous permet de construire des modèles simples d'apprentissage automatique sans avoir besoin d'être un expert en apprentissage automatique.
Pour chaque modèle, nous avons pris notre base de données, qui contenait l'étiquette de chaque fichier audio (beep, speech), avec le MFCC pour chaque échantillon, nous l'avons divisé en un ensemble de données de formation et un ensemble de données de test, et nous avons exécuté chaque modèle sur les données.
def train(features, model):
X, y = generateFeaturesLabels(features)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
model.fit(X_train, y_train)
print("Score:",model.score(X_test, y_test))
cross_val_scores = cross_val_score(model, X, y, cv=5, scoring='f1_macro')
print("cross_val_scores:", cross_val_scores)
print("Accuracy: %0.2f (+/- %0.2f)" % (cross_val_scores.mean(), cross_val_scores.std() * 2))
predictions = model.predict(X_test)
cm = metrics.confusion_matrix(y_test, predictions)
plot_confusion_matrix(cm, class_names)
return modelLa fonction train prend une liste de caractéristiques que nous voulons utiliser, qui est juste le MFCC de l'échantillon audio, ainsi que le modèle sur lequel nous voulons nous entraîner. Nous imprimons ensuite notre score, qui indique la performance du modèle. Nous imprimons également le score de validation croisée. Cela permet de s'assurer que notre modèle a été entraîné correctement. La fonction plot_confusion_matrix trace une matrice de confusion qui montre exactement ce que le modèle a obtenu de correct et d'incorrect.
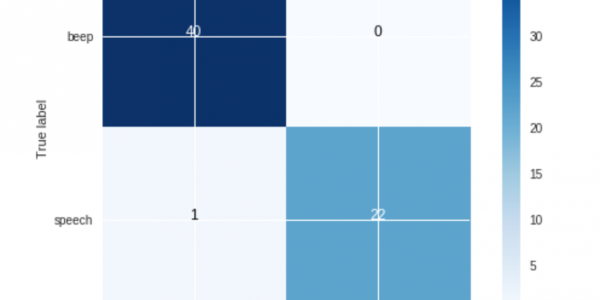
Nous avons ensuite essayé les modèles suivants et indiqué leur précision (score de 0 à 100 % sur la performance du modèle).
RandomForestClassifier 97% de précision
Régression logistique Précision de 96
Machines à vecteurs de support 84% de précision
Tous ces modèles ont donné de très bons résultats, à l'exception des machines à vecteurs de support. Le meilleur modèle était Gaussian Naive Bayes, c'est donc celui que nous utiliserons. Dans notre matrice de confusion ci-dessus, sur les 67 exemples, 40 échantillons prédits comme étant un beep étaient en fait beepset 22 échantillons prédits comme étant speech étaient en fait speech exemples. Cependant, 1 exemple prédit comme étant a beep était en fait speech.
Après avoir obtenu notre modèle, nous devons le sauvegarder dans un fichier, puis l'importer dans notre application VAPI.
import pickle
filename = "model.pkl"
pickle.dump(model, open(filename, 'wb'))
La dernière partie consiste à intégrer notre modèle dans une application VAPI.
Nous allons créer une application qui permet à un utilisateur de composer un numéro Vonage. Nous demanderons ensuite à l'utilisateur d'entrer un numéro de téléphone à appeler. Une fois le numéro saisi, nous connecterons cet appel à la conversation en cours et à notre websocket. Utilisation des websockets de Vonagede Vonage, nous sommes en mesure de diffuser l'appel audio dans notre application.
Tout d'abord, nous devons charger notre modèle dans notre application.
loaded_model = pickle.load(open("models/model.pkl", "rb"))Lorsque l'utilisateur compose pour la première fois le numéro de Vonage, nous renvoyons un NCCO avec le texte suivant :
class EnterPhoneNumberHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
ncco = [
{
"action": "talk",
"text": "Please enter a phone number to dial"
},
{
"action": "input",
"eventUrl": ["https://3c66cdfa.ngrok.io/ivr"],
"timeOut":10,
"maxDigits":12,
"submitOnHash":True
}
]
self.write(json.dumps(ncco))
self.set_header("Content-Type", 'application/json; charset="utf-8"')
self.finish()Nous envoyons d'abord une action action de synthèse vocale dans l'appel demandant à l'utilisateur de saisir un numéro de téléphone. Lorsque le numéro de téléphone est saisi, nous récupérons les chiffres de l'url https://3c66cdfa.ngrok.io/ivr url.
class AcceptNumberHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def post(self):
data = json.loads(self.request.body)
ncco = [
{
"action": "connect",
"eventUrl": ["https://3c66cdfa.ngrok.io"/event"],
"from": NEXMO_NUMBER,
"endpoint": [
{
"type": "phone",
"number": data["dtmf"]
}
]
},
{
"action": "connect",
"eventUrl": ["https://3c66cdfa.ngrok.io/event"],
"from": NEXMO_NUMBER,
"endpoint": [
{
"type": "websocket",
"uri" : "ws://3c66cdfa.ngrok.io/socket",
"content-type": "audio/l16;rate=16000"
}
]
}
]
self.write(json.dumps(ncco))
self.set_header("Content-Type", 'application/json; charset="utf-8"')
self.finish()Après la saisie du numéro de téléphone, nous recevrons un rappel de l https://3c66cdfa.ngrok.io/ivr url. Ici, nous prenons le numéro de téléphone que l'utilisateur a saisi à partir de data["dtmf"] et effectuons une action de connexion à ce numéro de téléphone, puis effectuons une autre action de connexion à notre websocket. Maintenant, notre socket est capable d'écouter l'appel.
Au fur et à mesure que l'appel est transmis à la prise web, nous devons capturer des morceaux de voix à l'aide de la détection de l'activité vocale, les enregistrer dans un fichier wave et effectuer nos prédictions sur ce fichier wav à l'aide de notre modèle entraîné.
class AudioProcessor(object):
def __init__(self, path, rate, clip_min, uuid):
self.rate = rate
self.bytes_per_frame = rate/25
self._path = path
self.clip_min_frames = clip_min // MS_PER_FRAME
self.uuid = uuid
def process(self, count, payload, id):
if count > self.clip_min_frames: # If the buffer is less than CLIP_MIN_MS, ignore it
fn = "{}rec-{}-{}.wav".format('', id, datetime.datetime.now().strftime("%Y%m%dT%H%M%S"))
output = wave.open(fn, 'wb')
output.setparams((1, 2, self.rate, 0, 'NONE', 'not compressed'))
output.writeframes(payload)
output.close()
self.process_file(fn)
self.removeFile(fn)
else:
info('Discarding {} frames'.format(str(count)))
def process_file(self, wav_file):
if loaded_model != None:
X, sample_rate = librosa.load(wav_file, res_type='kaiser_fast')
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
X = [mfccs]
prediction = loaded_model.predict(X)
if prediction[0] == 0:
beep_captured = True
print("beep detected")
else:
beep_captured = False
for client in clients:
client.write_message({"uuids":uuids, "beep_detected":beep_captured})
else:
print("model not loaded")
def removeFile(self, wav_file):
os.remove(wav_file)
Une fois que nous avons un fichier wav, nous utilisons librosa.load pour charger le fichier, puis nous utilisons la fonction librosa.feature.mfcc pour générer le MFCC de l'échantillon. Nous appelons ensuite loaded_model.predict([mfccs]) pour effectuer notre prédiction. Si la sortie de cette fonction est 0, a beep a été détecté. Si la sortie de cette fonction est 1, alors c'est speech. Nous générons ensuite une charge utile JSON indiquant si a beep a été détecté, ainsi que les uuids de la conversation. De cette façon, notre application cliente peut envoyer un TTS dans l'appel, en utilisant les uuids.
L'étape finale consiste à créer un client qui se connecte au websocket, observe lorsqu'un bip est détecté et envoie un TTS dans l'appel, lorsque la boîte vocale est détectée.
Tout d'abord, nous devons nous connecter au websocket.
ws = websocket.WebSocketApp("ws://3c66cdfa.ngrok.io/socket",
on_message = on_message,
on_error = on_error,
on_close = on_close)
ws.on_open = on_open
ws.run_forever()Ensuite, nous nous contentons d'écouter tout message entrant en provenance de notre websocket.
def on_message(ws, message):
data = json.loads(message)
if data["beep_detected"] == True:
for id in data["uuids"]:
response = client.send_speech(id, text='Answering Machine Detected')
time.sleep(4)
for id in data["uuids"]:
try:
client.update_call(id, action='hangup')
except:
pass<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-confusion-matrix.png"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-confusion-matrix-600x300.png" alt="" width="300" height="150" class="alignnone size-medium wp-image-28012" /></a>
<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-df.png"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-df-600x300.png" alt="" width="300" height="150" class="alignnone size-medium wp-image-28015" /></a>
<a href="https://www.nexmo.com/wp-content/uploads/2019/02/amd-eda.jpg"><img src="https://www.nexmo.com/wp-content/uploads/2019/02/amd-eda-600x300.jpg" alt="" width="300" height="150" class="alignnone size-medium wp-image-28018" /></a>
Nous analyserons le message entrant sous forme de JSON, puis nous vérifierons que la propriété beep_detected est True. Si c'est le cas, un beep a été détecté. Nous enverrons alors un TTS dans l'appel disant 'Answering Machine Detected', puis nous exécuterons une hangup action dans l'appel.
Nous avons montré comment nous avons construit un modèle de détection de répondeurs automatiques avec une précision de 96%, en utilisant quelques échantillons audio de beeps et speech afin d'entraîner notre modèle. Nous espérons avoir montré comment vous pouvez utiliser l'apprentissage automatique dans vos projets. Nous vous souhaitons beaucoup de plaisir !