
Compartir:
Hamza es ingeniero de software y vive en Chicago. Trabaja con Webrtc.ventures, una empresa líder en soluciones WebRTC. También trabaja como Full Stack Developer en Vonage ayudando con la Plataforma de Video para servir mejor a las necesidades de sus clientes. Como orgulloso introvertido, le gusta pasar su tiempo libre jugando con sus gatos.
Transcripción de voz con Symbl.ai y la API de Video de Vonage
Tiempo de lectura: 3 minutos
Voice transcription, speech-to-text, and live closed captioning are in popular demand in today's world where video/audio meetings are a primary form of communication. Symbl.ai destaca en inteligencia conversacional. Hoy vamos a incorporar subtítulos en directo a nuestra solución SimplyDoc Telehealth Starter Kit utilizando la API de streaming e información de Symbl.ai. Nuestro Video y audio serán alimentados por Video API de Vonage. Comencemos.
Obtenemos la pista de audio llamando al método OT.initPublisher() método Esto devuelve un Editor objeto. Podemos llamar a .getAudioSource() sobre este objeto para recibir un objeto MediaStreamTrack.
Ahora este objeto MediaStream tiene la pista de audio del editor que necesitamos enviar a Symbl.ai. Vamos a utilizar la Web Audio API para manipular la pista de audio en una forma que podamos enviar a Symbl.ai a través de WebSockets. Para que la Web Audio API funcione, necesitamos un objeto MediaStream. Existe una API que nos permite utilizar el objeto MediaStreamTrack directamente, pero en el momento de escribir esto, sólo está disponible en Firefox.
const audioTrack = publisher.getAudioSource()
const stream = new MediaStream();
stream.addTrack(audioTrack);Ahora tenemos el objeto stream que podemos usar con el Web Audio API para crear un Audio Buffer para enviar a Symb.ai.
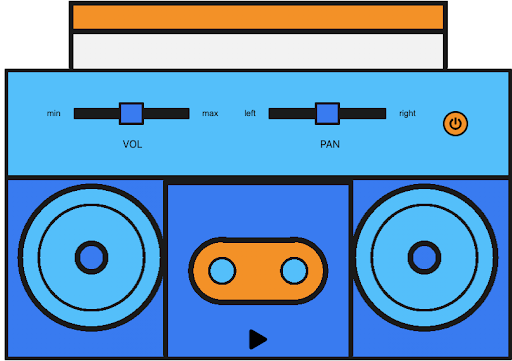
En primer lugar, es importante entender un poco la Web Audio API ya que la utilizaremos para procesar nuestro audio en el frontend. Piensa en la Web Audio API como un boombox donde declaramos cada componente. En primer lugar, declaramos el objeto AudioContext, que es como el chasis exterior del boombox.
const AudioContext = window.AudioContext;
const context = new AudioContext();Ahora que hemos declarado nuestro contexto de audio, estamos listos para darle una fuente. Piensa en la fuente como el casete o el CD que va en el radiocasete.
const source = context.createMediaStreamSource(stream);
const processor = context.createScriptProcessor(1024, 1, 1);
const gainNode = context.createGain();En estas tres líneas de código, primero declaramos nuestro nodo fuente, luego declaramos nuestro ScriptProcessorNodey finalmente nuestro `gainNode`. Ninguno de estos tres nodos hace nada en este momento porque no los hemos conectado entre sí. El `gainNode` es como la perilla del volumen en el boombox y el nodo procesador es como el lector magnético o la aguja que lee los datos del casete o CD.
Ahora vamos a conectarlos.
source.connect(gainNode);
gainNode.connect(processor);
processor.connect(context.destination);Aquí, conectamos la fuente al `gainNode.` Podemos utilizar el `gainNode` para aumentar o disminuir el volumen de la fuente. Así que si digamos, el micrófono de una persona es demasiado bajo podemos aumentar el valor de la ganancia para mitigar.
gainNode.gain.value = 2;Esto no es necesario para este tutorial, ya que suponemos que todo el mundo tiene un micrófono lo suficientemente decente.
A continuación, conectamos la salida del `gainNode` al nodo procesador. El nodo procesador recibe tres argumentos: el tamaño del búfer, el número de canales de entrada y el número de canales de salida, respectivamente. Elegimos 1024 como tamaño de búfer porque se encuentra en el extremo inferior del espectro de fotogramas de muestra (256, 512, 1024, 2048, 4096, 8192, 16384). Esto significa que obtendremos mejor latencia/rendimiento a costa de un audio extremadamente preciso. Si sientes que a Symbl.ai le faltan palabras en tu audio, entonces aumentar esto podría ayudar. Tenga en cuenta que dará lugar a la onaudioprocess más a menudo, lo que podría ralentizar su máquina.
Hablando de onaudioprocesseste es el evento que se disparará cada vez que el nodo procesador tenga un buffer de audio listo para el tamaño especificado. A Symbl.ai le gusta preparar el búfer para enviarlo así:
processor.onaudioprocess = (e) => {
// convert to 16-bit payload
const inputData = e.inputBuffer.getChannelData(0) || new Float32Array(this.bufferSize);
const targetBuffer = new Int16Array(inputData.length);
for (let index = inputData.length; index > 0; index--) {
targetBuffer[index] = 32767 * Math.min(1, inputData[index]);
}
// Send audio stream to websocket.
if (ws.readyState === WebSocket.OPEN) {
ws.send(targetBuffer.buffer);
}
};
};
Hablaremos de cómo enviamos el buffer usando WebSockets más adelante en este artículo.
Por último, enviamos el nodo procesador al destino. El destino es como los altavoces del radiocasete.
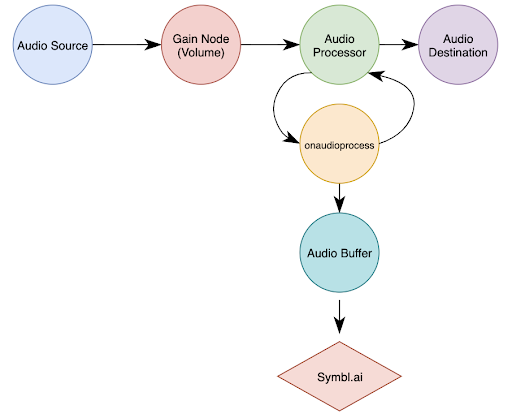
Aquí tienes un diagrama de lo que hemos construido hasta ahora utilizando la Web Audio API.
Y con eso, ¡nuestro boombox está listo para funcionar!
Ahora, vamos a crear una conexión WebSocket con Symbl.ai para poder enviar el buffer de audio que hemos preparado en los pasos anteriores y recibir los insights de Symbl.ai.
const accessToken = accessToken;
const uniqueMeetingId = btoa("user@example.com");
const symblEndpoint = `wss://api.symbl.ai/v1/realtime/insights/${uniqueMeetingId}?access_token=${accessToken}`;Para generar el código de acceso, siga esta guía.
El ID único de la reunión puede ser cualquier hash o cadena única. Esto es sólo un ejemplo de la creación de una cadena cifrada única de un correo electrónico. Ahora, vamos a declarar nuestros oyentes.
// Fired when a message is received from the WebSocket server
ws.onmessage = (event) => {
// You can find the conversationId in event.message.data.conversationId;
const data = JSON.parse(event.data);
if (data.type === 'message' && data.message.hasOwnProperty('data')) {
console.log('conversationId', data.message.data.conversationId);
}
if (data.type === 'message_response') {
for (let message of data.messages) {
console.log('Transcript (more accurate): ', message.payload.content);
}
}
if (data.type === 'topic_response') {
for (let topic of data.topics) {
console.log('Topic detected: ', topic.phrases)
}
}
if (data.type === 'insight_response') {
for (let insight of data.insights) {
console.log('Insight detected: ', insight.payload.content);
}
}
if (data.type === 'message' && data.message.hasOwnProperty('punctuated')) {
console.log('Live transcript (less accurate): ', data.message.punctuated.transcript)
}
console.log(`Response type: ${data.type}. Object: `, data);
};
// Fired when the WebSocket closes unexpectedly due to an error or lost connection
ws.onerror = (err) => {
console.error(err);
};
// Fired when the WebSocket connection has been closed
ws.onclose = (event) => {
console.info('Connection to websocket closed');
};
Hemos optado por utilizar la data.message.punctuated.transcript que ofrece transcripción en directo. Esto conlleva el coste de cierta precisión, pero puedes decidir cómo utilizar los datos. Cuando se abre la conexión WebSocket, tenemos que enviar un mensaje a Symbl.ai describiendo nuestra reunión y los oradores que intervienen. Esto nos ayuda a crear una transcripción posterior a la llamada, así como otras cosas como diarización de oradores.
// Fired when the connection succeeds.
ws.onopen = (event) => {
ws.send(JSON.stringify({
type: 'start_request',
meetingTitle: 'Websockets How-to', // Conversation name
insightTypes: ['question', 'action_item'], // Will enable insight generation
config: {
confidenceThreshold: 0.5,
languageCode: 'en-US',
speechRecognition: {
encoding: 'LINEAR16',
sampleRateHertz: 44100,
}
},
speaker: {
userId: 'example@symbl.ai',
name: 'Example Sample',
}
}));
};
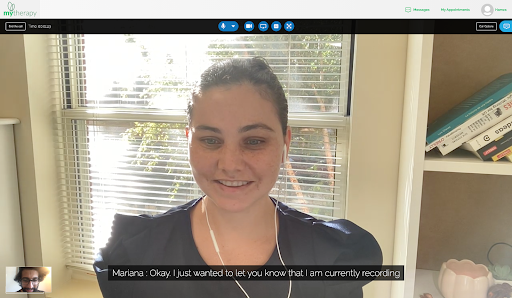
Y con esto, ¡el núcleo de nuestra demostración de voz a texto está completo! Con un poco de trabajo en la interfaz de usuario, este es el aspecto de una llamada con transcripción de voz:
Compartir:
Hamza es ingeniero de software y vive en Chicago. Trabaja con Webrtc.ventures, una empresa líder en soluciones WebRTC. También trabaja como Full Stack Developer en Vonage ayudando con la Plataforma de Video para servir mejor a las necesidades de sus clientes. Como orgulloso introvertido, le gusta pasar su tiempo libre jugando con sus gatos.