
Compartir:
Aaron era un defensor de los desarrolladores en Nexmo. Ingeniero de software experimentado y aspirante a artista digital, Aaron suele crear cosas con código o electrónica; a veces ambas cosas. Cuando está trabajando en algo nuevo, suele percibir el olor a componentes quemados en el aire.
Clasificación automática de grabaciones de llamadas mediante PNL
Tiempo de lectura: 3 minutos
Voice API de Nexmo facilita la grabación de llamadas telefónicas entrantes y salientes. Sin embargo, localizar cada llamada en la que la gente habla de un tema concreto, como "Informática", podría llevar mucho tiempo si hay que escuchar cada archivo de audio cada vez.
En este tutorial, te mostraremos cómo puedes utilizar el Procesamiento del Lenguaje Natural, a través de Google Cloud Services, para clasificar automáticamente el contenido de cada grabación, de forma que puedas identificar rápidamente las llamadas de voz que trataban sobre temas específicos.
Todo el código código de este tutorial está disponible en GitHub. Utiliza pipenv para gestionar las dependencias y requiere Python 3.6.4. Puedes crear un entorno virtual e instalar las dependencias ejecutando:
pipenv installVamos a utilizar la Voice API de Nexmo, concretamente la acción record acción. Antes de continuar con este tutorial, usted debe leer a través de nuestros bloques de construcción de voz, así como algunos de nuestros tutoriales anteriores sobre la creación de Voice Applications.
En el tutorial también utilizamos dos API de Google Cloud Services: Cloud Speech-to-Text y Cloud Natural Language. Debe crear un nuevo proyecto de Google Cloud Platform (GCP) y asegurarse de habilitar Speech-to-Text y Natural Language.
Recuerda descargar las credenciales de tu proyecto GCP y almacenarlas en algún lugar donde tu script pueda acceder a ellas. Yo añadí las mías a la raíz del proyecto y les puse el nombre google_private.json.
Hay un .env.example en la raíz del proyecto. Este archivo de ejemplo describe las diferentes variables de entorno que espera la aplicación. Copia este archivo y renómbralo a .env. Cualquier valor establecido en este archivo se carga automáticamente en su entorno cuando se ejecuta:
pipenv shellGrabación de la llamada
Esperamos que a estas alturas ya conozca las NCCOs. Nuestra primera ruta Flask va a servir a nuestro archivo NCCO, instruyendo a Nexmo Voice API para grabar cualquier llamada a nuestro número virtual:
@app.route("/", methods=["GET"])
def ncco():
logger.info(f"New call received from {request.args['from']}")
return jsonify(
[
{"action": "talk", "text": "Record your message after the beep"},
{
"action": "record",
"eventUrl": [f"{os.environ['BASE_URL']}/recordings"],
"format": "wav",
"endOnKey": "*",
"beepStart": True,
},
]
)Hay dos cosas principales a tener en cuenta en el código anterior:
La dirección
event_urlapunta a nuestro servidor Flask local. El manejador para esta ruta se discute más adelante en el tutorial.El formato de grabación se establece en
wavpor defecto, Nexmo proporciona las grabaciones como archivos MP3. Sin embargo, el servicio Google Speech-to-Text admite WAV, por lo que debemos configurar el formato de nuestra grabación para que coincida.
Cada vez que se completa una llamada, la Voice API de Nexmo envía una POST solicitud a nuestro event_url. He extraído la mayor parte del trabajo pesado del manejador de vistas de Flask y lo he trasladado a una serie de tareas en segundo plano utilizando Huey:
pipeline = download_recording_task.then(transcribe_audio).then(classify_transcription)
huey.enqueue(pipeline)
El método get_recording del cliente Python de Nexmo es nuevo, por lo que si has instalado el cliente Python antes es probable que necesites actualizarlo:
@huey.task()
def download_recording(recording_url, recording_uuid):
logger.info(f"Download recording {recording_uuid}")
recording = nexmo_client.get_recording(recording_url)
recordingfile = f"./recordings/{recording_uuid}.wav"
os.makedirs(os.path.dirname(recordingfile), exist_ok=True)
with open(recordingfile, "wb") as f:
f.write(recording)
return {"recording_uuid": recording_uuid}Después de recuperar el archivo WAV de Nexmo, la aplicación lo guarda en el directorio recordings directorio. La función download_recording devuelve el valor recording_uuid dentro de un diccionario, ya que Huey pasa cualquier valor de retorno a la siguiente función en el pipeline como argumentos de palabra clave.
Antes de poder procesar el lenguaje natural del contenido de nuestro archivo de audio, tenemos que convertirlo en texto:
@huey.task()
def transcribe_audio(*args, recording_uuid):
# Instantiates a client
client = speech.SpeechClient()
# The name of the audio file to transcribe
file_name = f"./recordings/{recording_uuid}.wav"
# Loads the audio into memory
with io.open(file_name, "rb") as audio_file:
content = audio_file.read()
audio = speech_types.RecognitionAudio(content=content)
config = speech_types.RecognitionConfig(
encoding=speech_enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
# Detects speech in the audio file
logger.info(f"Sending file {recording_uuid} for transcribing")
response = client.recognize(config, audio)
return {
"transcription_text": response.results[0].alternatives[0].transcript,
"recording_uuid": recording_uuid,
}Puede obtener más información sobre la Google Cloud Speech-to-Text API en su sitio web. Ahora que el archivo de audio se ha convertido en texto, se activa la siguiente función del proceso.
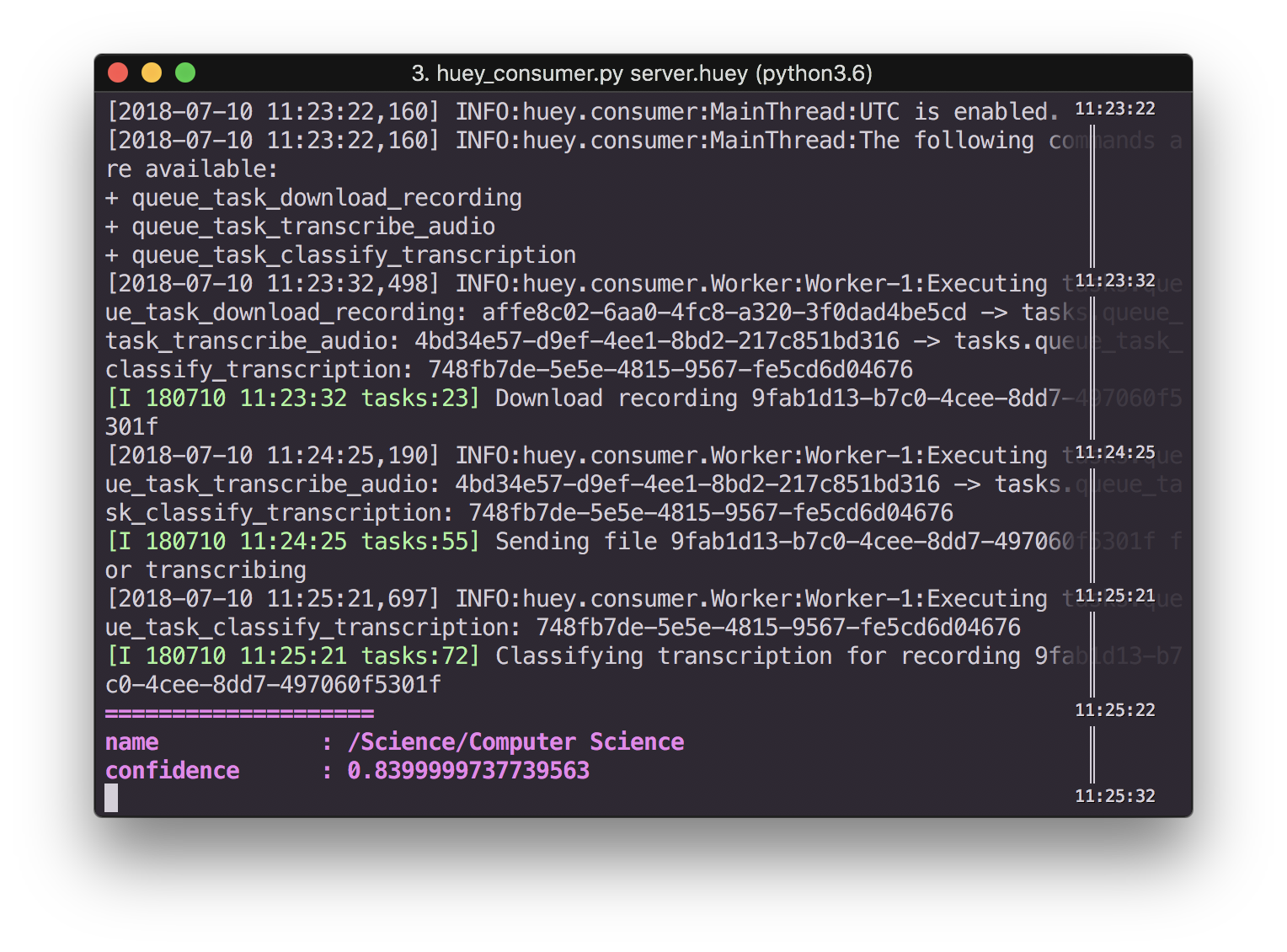 Screenshot of terminal showing audio classification
Screenshot of terminal showing audio classification
La aplicación realiza una última llamada a la API, esta vez al servicio Google Cloud Language:
@huey.task()
def classify_transcription(transcription_text, recording_uuid):
client = language.LanguageServiceClient()
document = language_types.Document(
content=transcription_text, type=language_enums.Document.Type.PLAIN_TEXT
)
logger.info(f"Classifying transcription for recording {recording_uuid}")
categories = client.classify_text(document).categories
for category in categories:
print(colorful.bold_violet("=" * 20))
print(colorful.bold_violet("{:<16}: {}".format("name", category.name)))
print(
colorful.bold_violet("{:<16}: {}".format("confidence", category.confidence))
)
return True
Esta API puede hacer mucho más que simplemente clasificar texto; puede proporcionar información sobre el sentimiento del texto proporcionado, o descomponer el texto en una serie de frases y tokens utilizando el Análisis Sintáctico. Lea su documentación para más detalles.
Esperamos que nuestro tutorial le haya dado una idea de lo que es posible combinando Nexmo Voice API con Google Cloud. Si desea obtener más información sobre otras cosas interesantes que puede lograr con el Nexmo Voice API estos otros tutoriales serán de interés:
Compartir:
Aaron era un defensor de los desarrolladores en Nexmo. Ingeniero de software experimentado y aspirante a artista digital, Aaron suele crear cosas con código o electrónica; a veces ambas cosas. Cuando está trabajando en algo nuevo, suele percibir el olor a componentes quemados en el aire.