
Video + AI: Traducciones en directo con conector de audio
Tiempo de lectura: 5 minutos
Imagínese estar en una videollamada con personas de todo el mundo que hablan su propia lengua materna y todos se entienden. El audio del orador se traduce en texto que los demás participantes pueden leer en su propio idioma. En esta entrada del blog explicaremos cómo hacerlo posible. Uno de los componentes principales es la nueva función Audio Connector que acabamos de lanzar.
En resumen, con Conector de audiolos flujos de audio de sus sesiones de videollamada enrutadas pueden enviarse individualmente (A, B) o combinados (A+B) a un servidor WebSocket para un total de hasta 50 flujos.
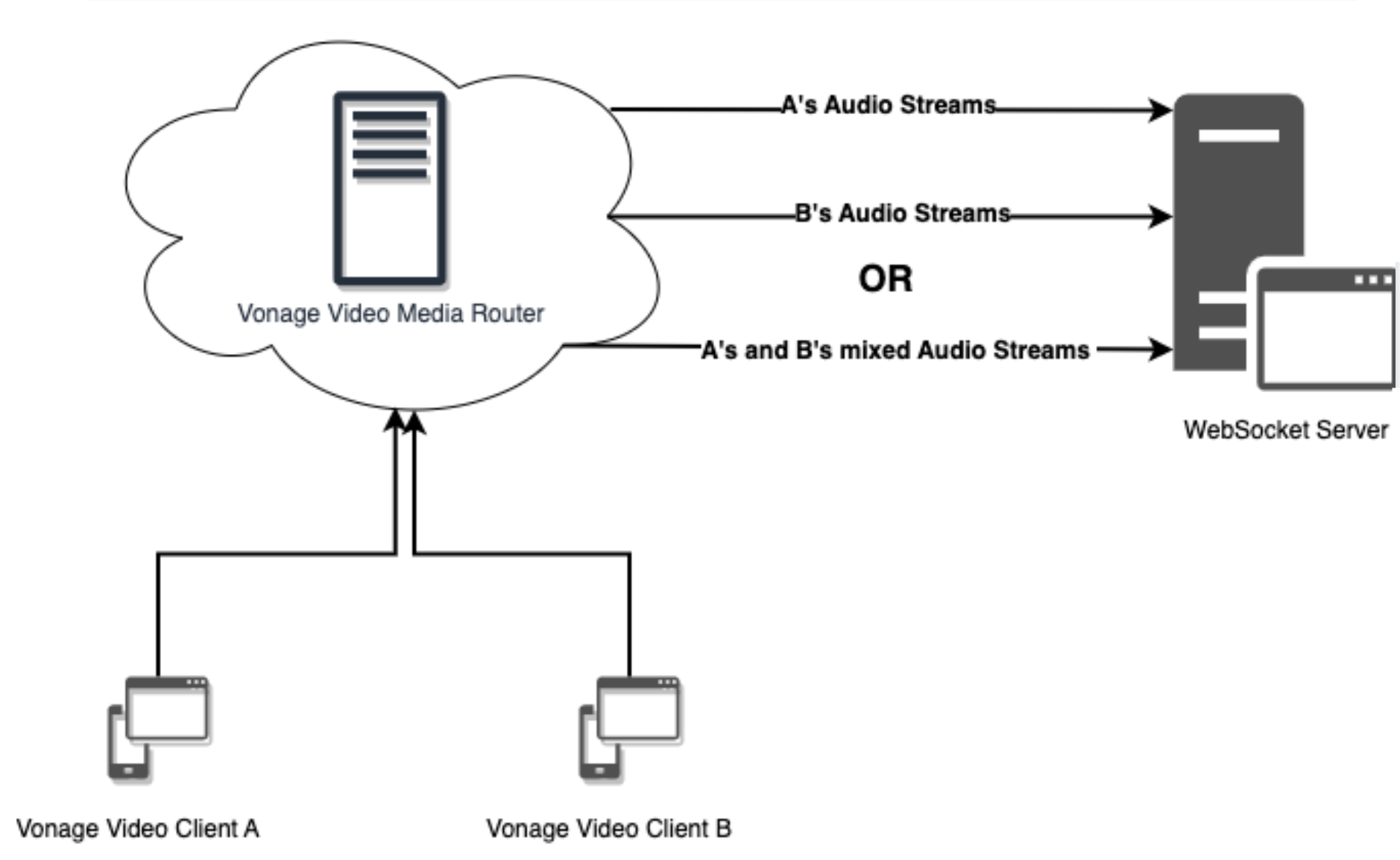 Audio Connector Diagram
Audio Connector Diagram
No hay ningún indicador o interruptor que activar para empezar a utilizar Audio Connector. Está activado por defecto, y su precio se basa en el número de flujos de audio participantes enviados. Todo lo que tenemos que hacer es crear un servidor WebSocket para recibir los flujos de audio.
Ser capaz de aislar y analizar flujos de audio abre un montón de nuevas posibilidades. Una de las que analizaremos en esta entrada del blog será el uso de la Inteligencia Artificial para realizar traducciones en tiempo real con Azure de Microsoft AI Speech Service.
Si desea ver el código y una demostración en acción, puede consultar el repositorio de GitHub para una aplicación basada en NodeJS. Con un clic en el botón de despliegue e introduciendo algunas credenciales, podrás experimentar traducciones en directo en tiempo real en una videollamada.
Como se ha mencionado anteriormente, necesitará algunas credenciales para ejecutar la aplicación de demostración.
Puedes encontrar la clave y el secreto de la API de Video de Vonage en el tableroya sea en un proyecto anterior o en uno recién creado.
 Vonage Project Credentials
Vonage Project Credentials
Por parte de Microsoft, tendrá que crear un recurso Speech Services en el portal Azure. Una vez creado, necesitará una de las Claves (cualquiera de ellas es válida) y el valor en "Ubicación/Región".
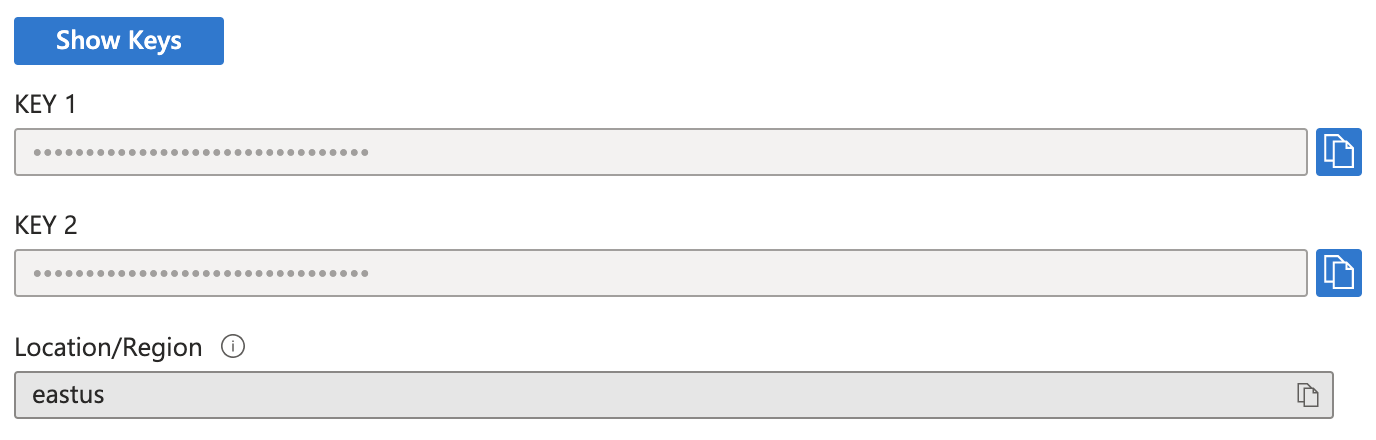 Microsoft Azure Project Credentials
Microsoft Azure Project Credentials
Introduciendo estas credenciales junto con el dominio de la aplicación en ejecución, podrás introducir tu nombre, seleccionar los idiomas en los que hablarás y leer la traducción. Comparte la URL y haz que uno o dos amigos se unan a tu sesión de Video.
En esta sección describiré lo que ocurre entre bastidores en la aplicación de demostración. Para ser lo más agnóstico posible en cuanto al código, hablaré de los métodos en general y señalaré la documentación para que puedas implementar las cosas en el lenguaje de programación que prefieras. Construí mi aplicación de demostración usando NodeJS.
La videollamada es una videollamada básica y normal como la que se encuentra en este proyecto de ejemplo o una creada con nuestros nuevos Componentes Web de Video. La única diferencia es permitir al usuario introducir su nombre y los idiomas que desea utilizar antes de iniciar la sesión.
Una vez que la llamada de Video está ocurriendo, eso significa que hay audio para que el Conector de Audio comience a enviar a un servidor WebSocket. Si no estás seguro de cómo crear un servidor WebSocket, puedes buscar <your programming language> WebSocket server y con suerte, muchos tutoriales y librerías estarán en los resultados de la búsqueda. Si no, siempre hay un chatbot AI al que puedes preguntar. Jaja
Para comenzar a enviar tus flujos de audio a tu recién creado servidor WebSocket, Vonage proporciona un método en los distintos SDK de servidor (Java, NodeJS, PHP, Python, Ruby, .NET) para iniciar una conexión WebSocket. Si no ve su lenguaje del lado del servidor, también puede utilizar un punto final REST.
Ahora que su servidor WebSocket recibe flujos de audio, es el momento de empezar a traducir. Azure de Microsoft AI Speech Service puede traducir audio de más de 30 idiomas. Microsoft tiene SDKs de Speech Service para C++, C#, Go, Java, JavaScript/NodeJS, Objective-Cy Python.
En primer lugar, configure la traducción de voz con su clave y región. En su SDK de idiomas, debería haber algo similar a SpeechTranslationConfig con un fromSubscription en el que puedes pasar tus credenciales. Dónde establecer el reconocimiento de voz y los idiomas de destino puede depender de si envía un flujo combinado o varios flujos individuales.
En tu servidor WebSocket, querrás recoger los datos enviados desde el Conector de Audio para traducirlos con inteligencia artificial. Para ello, será necesario crear un Push Stream para el Audio Input Stream, al menos en NodeJS. Así es como funciona.
Audio Connector envía diferentes tipos de mensajes WebSocket:
Hay mensajes basados en texto que incluyen el mensaje inicial, actualizaciones cuando se silencia/desilencia un flujo de audio y cuando se desconecta la conexión. Estos mensajes contienen información sobre el formato de audio, datos sobre el estado de la conexión y cualquier encabezado personalizado que hayas enviado al crear la conexión.
El otro tipo son los mensajes de audio binarios que representan el flujo de audio. Estos son los que quieres añadir al Push Stream para que la inteligencia artificial los traduzca.
Para diferenciar los mensajes de texto de los de audio, intento analizar el mensaje en JSON. Si no obtengo ningún error, significa que se trata de un mensaje de texto. Si obtengo un error, significa que es un mensaje de audio binario que se añade al Push Stream.
Ahora que tenemos un Flujo de Entrada de Audio suministrado por el Flujo Push, necesitamos configurar el audio de la entrada del flujo para que el SDK de Voz pueda analizar y traducir el audio. Para comenzar a "entender" el flujo, se crea un Reconocedor de Traducción utilizando las configuraciones de Audio y Traducción de Voz. El Reconocedor de Traducción se inicia entonces para intentar reconocer continuamente lo que se está diciendo en el flujo de audio.
Se dispararán traducciones parciales mientras el Reconocedor de Traducción intenta descifrar lo que se está diciendo. Una vez que tenga lo que cree que es una comprensión completa de lo que se ha dicho en la frase, se presentará una traducción finalizada.
A continuación, tomaremos esas traducciones finalizadas a medida que se presenten y las enviaremos a la sesión de vídeo a través de la función Vonage Video de Vonage para que se muestren en las pantallas de los participantes.
He pensado que sería interesante añadir la posibilidad de silenciar a todos los participantes en la videollamada y hacer que el navegador lea el texto traducido con voz sintetizada. Si lo pruebas, cuéntanos cómo va en la Slack de la comunidad de desarrolladores o en X, antes conocido como Twitter. @VonageDev.