
Compartir:
Mark ha desarrollado demos, implementado POCs e infligido su humor a colegas desprevenidos en Vonage durante más de 4 años. Lleva programando profesionalmente desde 1979, y su experiencia técnica abarca desde FORTRAN en tarjetas perforadas hasta React Native en la nube. Su creatividad y entusiasmo por desarrollar y compartir soluciones tecnológicas solo es comparable a su afición por los chistes de papá.
Demostración de diarización de altavoces con Vonage Video y Deepgram
Tiempo de lectura: 6 minutos
Muchos trabajadores de todo el mundo han vuelto a la oficina, pero el uso de sistemas de videoconferencia no ha disminuido. La mayoría de los sistemas del mercado actual están diseñados para un orador por flujo de vídeo, lo que convierte en un caos los sistemas de salas de oficina compartidos por varios oradores. Imagínate leer la transcripción de un intercambio entre tres personas pero sin identificar a los distintos oradores. Puede resultar bastante confuso.
Cada vez más, los sistemas de conferencias recurren a capacidades de inteligencia artificial para gestionar esta complejidad. La última generación de tecnologías va más allá de los simples subtítulos y traducciones y emplea el poder de la IA para gestionar la complejidad de los sistemas de salas, así como los escenarios de vídeo híbrido.
Saber quién dijo qué a quién es importante para dar sentido a una conversación y aportar valor a las notas y transcripciones de las reuniones. La identificación del hablante va más allá de la comprensión de la conversación, ya que permite obtener un valor añadido como las notas y transcripciones de las reuniones. Separar quién habla a partir de una única fuente de audio es una tarea para la que los humanos se han adaptado especialmente, pero supone un complejo reto para las máquinas. Este proceso se denomina diarización del hablante.
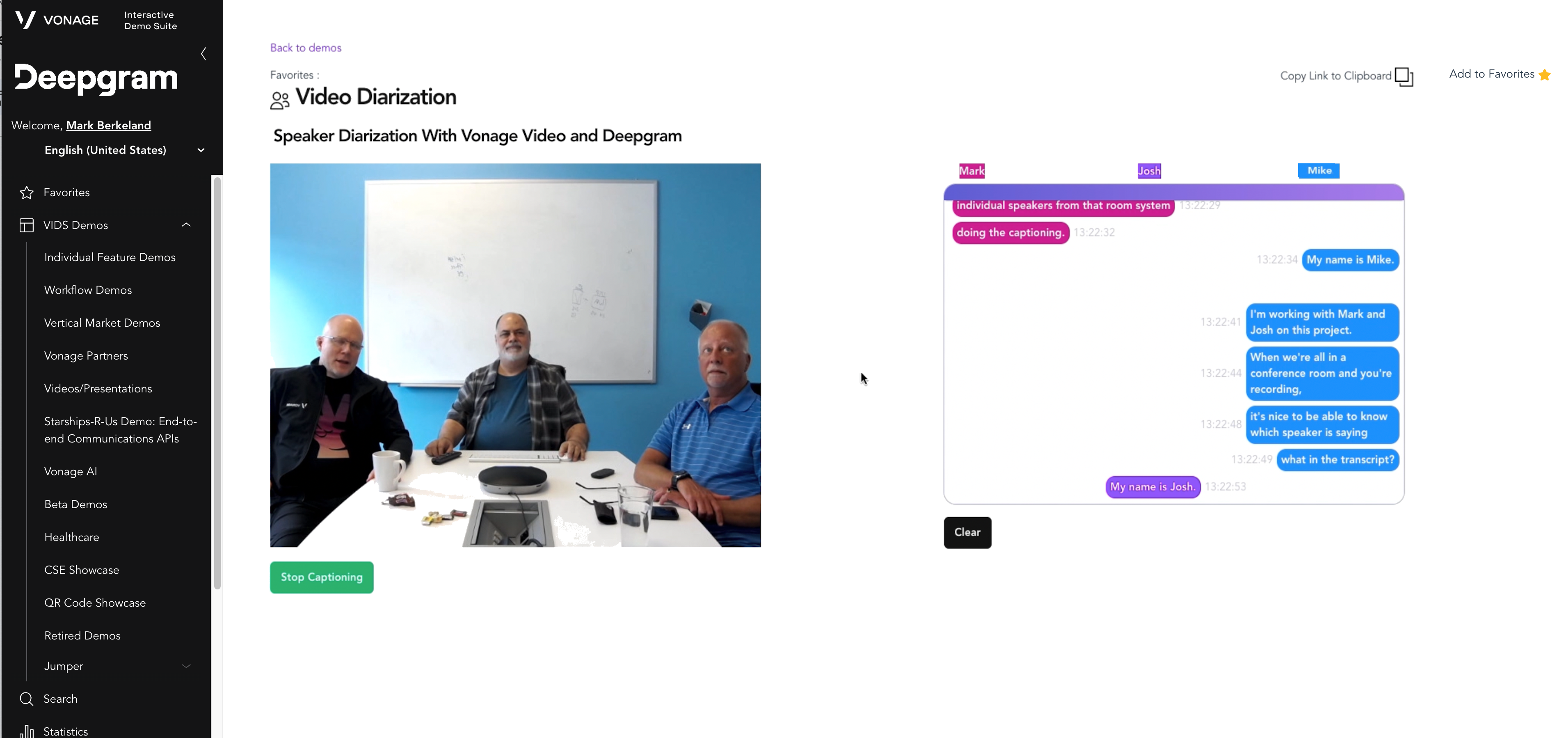
En este blog, demostraremos cómo construimos un sistema de videoconferencia para salas con varios altavoces y diarización.
¡A continuación puede ver un Video de esta demostración en acción!
Para aplicar esta solución, teníamos que asegurarnos:
El sistema de videoconferencia tenía acceso seguro al audio sin procesar en el servidor para garantizar los tiempos de procesamiento más rápidos, así como captura desde dispositivos SIP para cualquier participante que marque.
El servicio de reconocimiento automático del habla (ASR) podría separar a los hablantes individuales en un flujo de audio, de modo que las expresiones de cada hablante se identifiquen de forma única.
La obtención de estas capacidades fue crucial para liberar todo el potencial de los sistemas de conferencias para sistemas de salas y casos de uso híbridos y construir una aplicación de vídeo útil y amigable, como se ve a continuación:
 vonage_video_api_diarization_demo.png
vonage_video_api_diarization_demo.png
¿Qué es la diarización de oradores?
La diarización de locutores es el proceso de separar un flujo de audio en segmentos según la identidad del locutor, independientemente del canal. La diarización de locutores suele dividirse en cuatro subtareas principales:
Detección - Busca regiones de audio que contengan habla en contraposición al silencio o al ruido.
Segmentación - Divide y separa las regiones detectadas en secciones de audio más pequeñas.
Representación - Utilizar un vector discriminante para representar esos segmentos.
Atribución - Añade una etiqueta de locutor a cada segmento en función de su representación discriminativa.
Las funciones de diarización que ofrecen los distintos proveedores de ASR varían. Nuestro socio Deepgram ha implementado uno de los conjuntos de funciones más robustos que hemos visto en el mercado, con más de una docena de idiomas y sin límites en el número de hablantes activos. Puede obtener más información sobre esta solución aquí.
Más información sobre la diarización de oradores en este Deepgram (https://blog.deepgram.com/what-is-speaker-diarization/)
Para que el reconocimiento de voz funcione con eficacia, es necesario acceder a los flujos de audio sin procesar directamente desde el router multimedia. Esto proporciona las ventajas de la compatibilidad nativa con todos los dispositivos, utiliza una fracción del ancho de banda de una solución del lado del cliente y puede funcionar con sistemas con cortafuegos. Usando Vonage Video API Audio Connector, podemos extraer flujos de audio sin procesar de nuestras sesiones de video en vivo y enviarlos a Deepgram para el procesamiento en tiempo real (así como fuera de línea) de flujos de audio. Puedes encontrar más información sobre el Audio Connector aquí.
Cuando construimos nuestra demo, nos interesaba mostrar la diarización en tiempo real de un sistema de habitaciones utilizando la Video API de Vonage para crear la sesión de vídeo y Deepgram para transcribir el discurso.
Para mayor claridad, no incluimos a otros individuos que se unan a la conferencia, aunque esta solución puede manejar absolutamente ese caso (así como múltiples sistemas de sala simultáneos). El conector de audio se pone en marcha cuando añadimos un nuevo editor (que, en este caso, sabemos que es un sistema de sala). En realidad es bastante sencillo configurar el Audio Connector, puesto que ya conocemos el StreamID del editor (nos lo envía la aplicación front-end). Aunque el AudioConnector puede manejar "todos", o "una lista de streams", en nuestro caso sólo estamos usando un stream, asociado con el sistema de salas. Tenga en cuenta que esto PODRÍA ser incluso un sistema de conferencia de sala SIP tradicional.
Necesitábamos una Video API de Vonage y una cuenta de Deepgram para crear esta demo. Puedes crear tus cuentas gratuitas aquí para Vonage Video API y aquí para Deepgram.
Tras crear nuestra instancia de Opentok ("opentok"), y crear una Sesión para la videoconferencia ("sessionId") junto con un token de autorización asociado ("token"), la aplicación nos informa del flujo del sistema de la sala ("streamId"). A continuación, basta con asociar ese flujo a la URL de un websocket en espera ("url"):
opentok.websocketConnect(sessionId, token, url, {
streams: [streamId],
headers: {
sessionid: sessionId,
streamId: streamId
},
audioRate: 16000,
}, function(error, socket) {
if (error) {
console.log('Error:', error.message);
} else {
console.log('OpenTok Socket websocket connected');
}
});El websocket está a la escucha de conexiones entrantes, y como estamos pasando el sessionId y el streamId en las cabeceras, podemos saber exactamente qué stream vamos a transcribir y registrar:
app.ws('/socket', async (ws, req) => {
…
ws.on('message', (msg) => {
try {
if (typeof msg === 'string') {
let config = JSON.parse(msg);
console.log("Socket string message: ", config);
// Do whatever we need here…
// the sessionId and streamId are contained in the msg!
} else {
Donde el "msg" llega como:
Socket string message: {
'content-type': 'audio/l16;rate=16000',
event: 'websocket:connected',
sessionid: '1_MX40NjQyMzI5Mn5-MTY4NjA5MDM1MTkwNX5yUVlkZmp0bE9jMk5rQTAyVxxxxxxxxx-xx',
streamId: '553236ce-xxxx-xxxx-8cb4-9dd17b3119dc'
}Ahora podemos enganchar nuestro flujo de audio entrante directamente en el modelo de streaming de Deepgram. Cuando vemos el websocket del Conector de Audio conectándose, le decimos a Deepgram que abra un websocket. Para nuestra demostración, encontramos que usando el modelo "phonecall" en el nivel "enhanced" nos dio muy buenos resultados, y usamos el formato por defecto de Audio Connector de "16000" para la frecuencia de muestreo y "linear16" para el formato de audio. Haz clic aquí para obtener información sobre las funciones y opciones de Deepgram. También (y esto es más o menos el punto aquí), le decimos a Deepgram que use diarización ("diarize: true"):
const deepgramLive = deepgram.transcription.live({
punctuate: true,
model: 'phonecall',
tier: 'enhanced',
language: “en - US”,
,
diarize: true,
encoding: 'linear16',
sample_rate: 16000,
endpointing: 10,
});A continuación, podemos utilizar esa conexión Deepgram para escuchar los resultados de la transcripción (más adelante veremos qué hacemos con ella), configurando un "oyente":
deepgramLive.addListener('transcriptReceived', async (transcription) => {
Bien, ya tenemos la fontanería lista... ¡es hora de abrir la espita!
En el websocket del Conector de Audio, cada vez que recibimos un paquete de audio procedente de nuestro sistema de sala (en otras palabras, cuando el tipo de mensaje es "binario"), primero nos aseguramos de que Deepgram está preparado para recibir datos:
if ((deepgramLive.getReadyState() === 1)) {
Y si es así, simplemente pasamos los datos tal cual.
deepgramLive.send(msg);
Una vez que Deepgram obtenga suficientes datos para crear el subtítulo, nos llamará al "oyente" antes mencionado. Deepgram nos proporciona un montón de información sobre el audio transcrito (recomiendo encarecidamente echar un vistazo a su excelente documentación para tener una buena idea de la riqueza de la información proporcionada), pero la parte que más nos interesa para la diarización de nuestro sistema de salas es la matriz de "palabras" (más específicamente, las "punctuated_word", ya que le pedimos a Deepgram que puntuara cada frase por nosotros). Ahora, Deepgram diarización funciona sobre una base por palabra, capaz de diferenciar incluso cuando hay altavoces superpuestas, por lo que queremos mirar a cada PALABRA y dividirlos por los individuos. Creamos una matriz en la que cada entrada será "lo que dijo ese hablante en particular", y luego iteramos a través de las palabras, separándolas y recomponiéndolas por hablante:
let words = transcription.channel.alternatives[0].words
let message = [];
words.forEach(function each(word) {
if (word.speaker in message) {
message[word.speaker] += " " + word.punctuated_word
} else {
message[word.speaker] = word.punctuated_word
}
});Ahora tenemos message[0] con lo que dijo el primer orador, message[1] con lo que dijo el segundo orador, etc.
Y ya está. Podemos enviar estos mensajes de vuelta a la GUI, para que los muestre según convenga.
Ahora tenemos un sistema de sala que toma notas de las reuniones y gestiona varios oradores, ¡incluso si están en la misma sala!
Haga clic aquí ¡para ver un Video de esta demostración en acción!
También puede solicitar una demostración personal de uno de nuestros expertos. Si tienes preguntas o comentarios, únete a nosotros en el Slack para desarrolladores de Vonage o envíanos un Tweet en Twitter.
Compartir:
Mark ha desarrollado demos, implementado POCs e infligido su humor a colegas desprevenidos en Vonage durante más de 4 años. Lleva programando profesionalmente desde 1979, y su experiencia técnica abarca desde FORTRAN en tarjetas perforadas hasta React Native en la nube. Su creatividad y entusiasmo por desarrollar y compartir soluciones tecnológicas solo es comparable a su afición por los chistes de papá.