
Compartir:
Aboze Brain John es analista de negocio de tecnología en Axa Mansard. Tiene experiencia en ciencia y análisis de datos, investigación de productos y redacción técnica. Brain ha participado en proyectos integrales de análisis de datos que van desde la recopilación de datos, la exploración, la transformación, el modelado y la derivación de conocimientos empresariales procesables, y proporciona liderazgo en conocimientos.
Detección de spam por SMS con aprendizaje automático en Python
Este artículo se actualizó en abril de 2025
En este tutorial, vas a construir una aplicación web de detección de spam de SMS. Esta aplicación se construirá con Python utilizando el framework Flask e incluirá un modelo de aprendizaje automático que entrenarás para detectar el spam de SMS. Trabajaremos con la API de SMS de Vonage para que puedas clasificar los mensajes SMS enviados al número de teléfono que tienes registrado en tu cuenta de Vonage.
Para comprar un número de teléfono virtual, vaya a su panel API y siga los pasos que se indican a continuación.
 Purchase a phone number
Purchase a phone number
Vaya a su Panel API
Vaya a CONSTRUIR Y GESTIONAR > Numbers > Comprar Numbers.
Elija los atributos necesarios y haga clic en Buscar
Pulse el botón Comprar junto al número que desee y valide su compra
Para confirmar que ha adquirido el número virtual, vaya al menú de navegación de la izquierda, en CONSTRUIR Y GESTIONAR, haga clic en Numbers y, a continuación, en Sus Numbers.
Python instalado. El sitio Anaconda incluye una serie de bibliotecas útiles para la ciencia de datos.
Conocimientos básicos de FlaskHTML y CSS.
A continuación se muestra un resumen del directorio de archivos de este proyecto:
├── README.md
├── dataset
│ └── spam.csv
├── env
│ ├── bin
│ ├── etc
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
├── model
│ ├── spam_model.pkl
│ └── tfidf_model.pkl
├── notebook
│ └── project_notebook.ipynb
├── requirements.txt
├── script
└── web_app
├── app.py
├── static
└── templatesCrearemos todos los archivos en el árbol de directorios anterior a través de los pasos de este tutorial.
Necesitamos crear un entorno aislado para varias dependencias de Python exclusivas de este proyecto.
En primer lugar, cree una nueva carpeta de desarrollo. En su terminal, ejecute:
A continuación, cree un nuevo entorno virtual Python. Si utiliza Anacondapuedes ejecutar el siguiente comando:
A continuación, puede activar el entorno utilizando:
Si está utilizando una distribución estándar de Python, cree un nuevo entorno virtual ejecutando el siguiente comando:
Para activar el nuevo entorno en un ordenador Mac o Linux, ejecute:
Si utiliza un ordenador con Windows, active el entorno del siguiente modo:
Independientemente del método que hayas utilizado para crear y activar el entorno virtual, tu prompt debería haberse modificado para parecerse a lo siguiente:
A continuación, instalarás todos los paquetes necesarios para este tutorial. En tu nuevo entorno, instala los siguientes paquetes (que incluyen librerías y dependencias):
Nota: Para crear un proyecto de ciencia de datos reproducible, limítate a las versiones que he incluido aquí. Estas eran las versiones más actualizadas en el momento de escribir este artículo.
He aquí algunos detalles sobre estos paquetes:
jupyterlab es para la construcción de modelos y la exploración de datos.
matraz sirve para crear el servidor de aplicaciones y las páginas.
lightgbm es el algoritmo de aprendizaje automático para construir nuestro modelo
nexmo es una biblioteca de Python para interactuar con tu cuenta de Vonage
matplotlib, plotly, plotly-express son para visualización de datos
python-dotenv es un paquete para gestionar variables de entorno como claves API y otros valores de configuración.
nltk es para operaciones en lenguaje natural
numpy es para el cálculo de matrices
pandas sirve para manipular y manejar datos estructurados.
regex es para operaciones con expresiones regulares
scikit-learn es un conjunto de herramientas de aprendizaje automático
nube de palabras se utiliza para crear imágenes de nubes de palabras a partir de texto
Tras la instalación, inicia tu laboratorio Jupyter ejecutando:
Esto abre la popular interfaz de laboratorio Jupyter en su navegador web, donde va a llevar a cabo alguna exploración interactiva de datos y construcción de modelos.
La interfaz del laboratorio Jupyter se muestra aquí Jupyterlab.
Ahora que tu entorno está listo, vas a descargar los datos de entrenamiento de SMS y construir un modelo sencillo de aprendizaje automático para clasificar los mensajes SMS. El conjunto de datos de spam para este proyecto puede descargarse aquí. El conjunto de datos contiene 5574 mensajes con las respectivas etiquetas de spam y ham (legítimo). Más información sobre el conjunto de datos aquí. Con estos datos, entrenaremos un modelo de aprendizaje automático que pueda clasificar correctamente los SMS como jamón o spam. Estos procedimientos se llevarán a cabo en un cuaderno Jupyter, que desde nuestro directorio de archivos se llama 'project_notebok'
Aquí aplicaremos diversas técnicas para analizar los datos y comprenderlos mejor.
Las bibliotecas necesarias para este proyecto pueden importarse a project_notebook.ipynb de la siguiente manera:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly_express as px
import wordcloud
import nltk
import warnings
warnings.filterwarnings('ignore')El conjunto de datos de spam ubicado en el directorio de conjuntos de datos denominado spam.csv puede importarse del siguiente modo
df = pd.read_csv("../dataset/spam.csv", encoding='latin-1')Nota: La codificación de caracteres de este conjunto de datos es latin-1(ISO/IEC 8859-1).
A continuación, obtenemos una visión general del conjunto de datos:
df.head()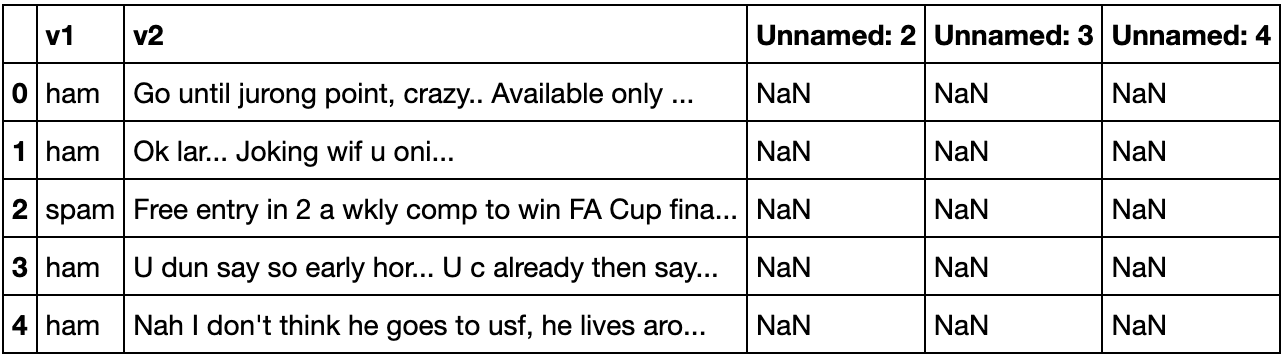 Dataset overview
Dataset overview
El conjunto de datos contiene 5 columnas. La columna v1 es la etiqueta del conjunto de datos ("jamón" o "spam") y la columna v2 contiene el texto del mensaje SMS. Las columnas "Sin nombre: 2", "Sin nombre: 3" y "Sin nombre: 4" contienen "NaN" (no es un número), lo que significa que faltan valores. No son necesarias, por lo que pueden eliminarse, ya que no van a ser útiles para construir el modelo. El siguiente fragmento de código eliminará y renombrará las columnas para mejorar la comprensibilidad del conjunto de datos:
df.drop(columns=['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], inplace=True)
df.rename(columns = {'v1':'class_label','v2':'message'},inplace=True)
df.head() Rename columns
Rename columns
Veamos la distribución de las etiquetas:
fig = px.histogram(df, x="class_label", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"])
fig.show()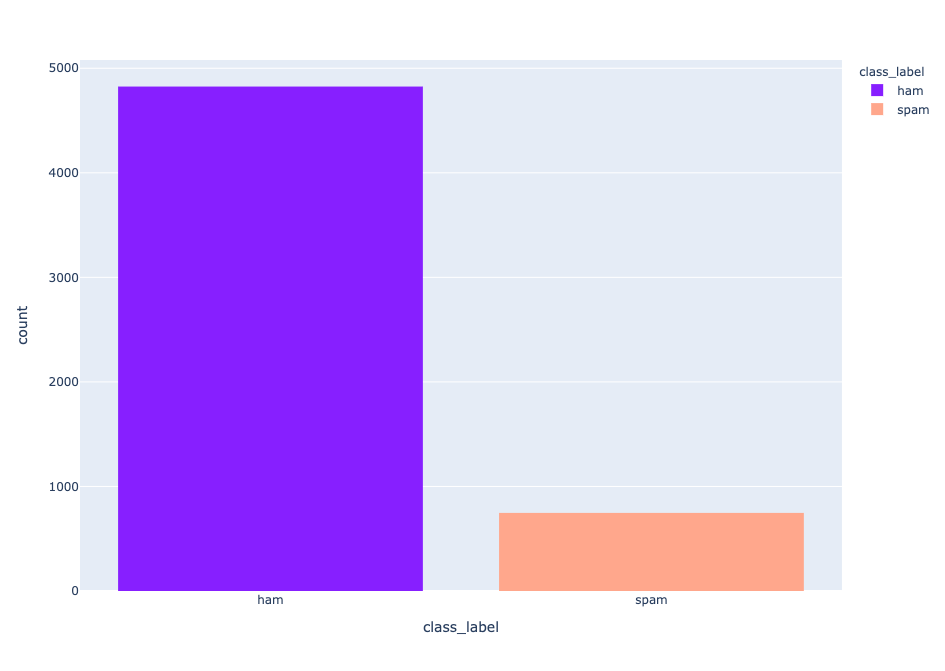 Distributions of labels
Distributions of labels
Tenemos un conjunto de datos desequilibrado, con 747 mensajes de spam y 4825 de jamón.
fig = px.pie(df.class_label.value_counts(),labels='index', values='class_label', color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()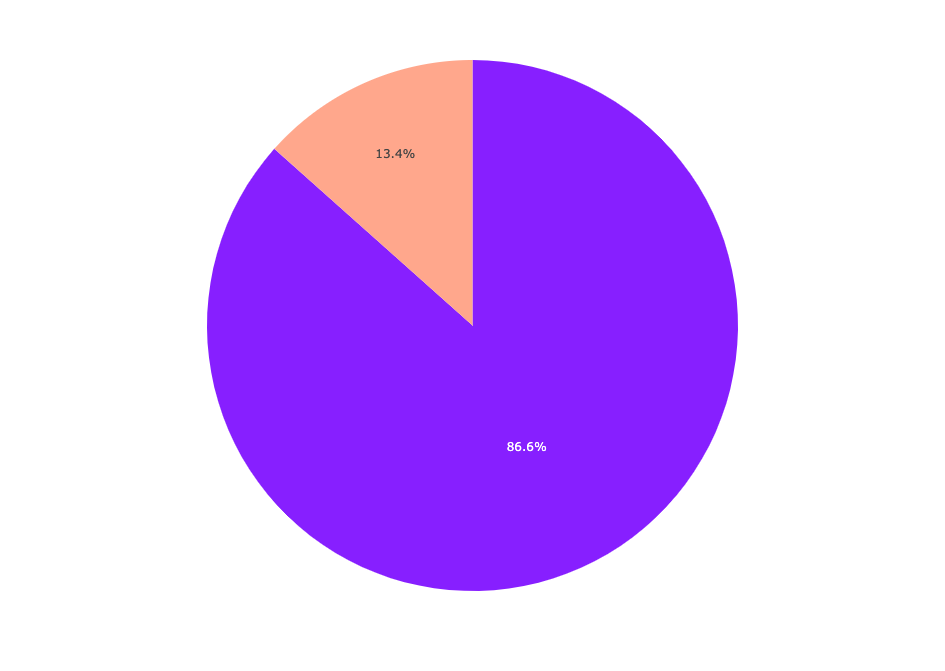 Labels pie chart
Labels pie chart
El spam constituye el 13,4% del conjunto de datos, mientras que el jamón compone el 86,6%.
A continuación, nos adentraremos en un poco de ingeniería de funciones. La longitud de los mensajes puede proporcionarnos algunas pistas. Echemos un vistazo:
df['length'] = df['message'].apply(len)
df.head() Message length
Message length
fig = px.histogram(df, x="length", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()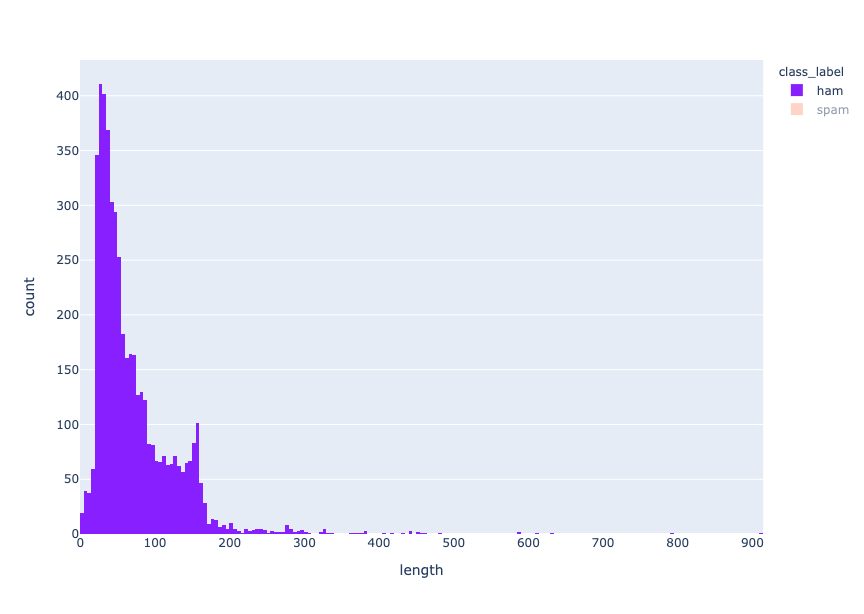 length distribution - ham
length distribution - ham
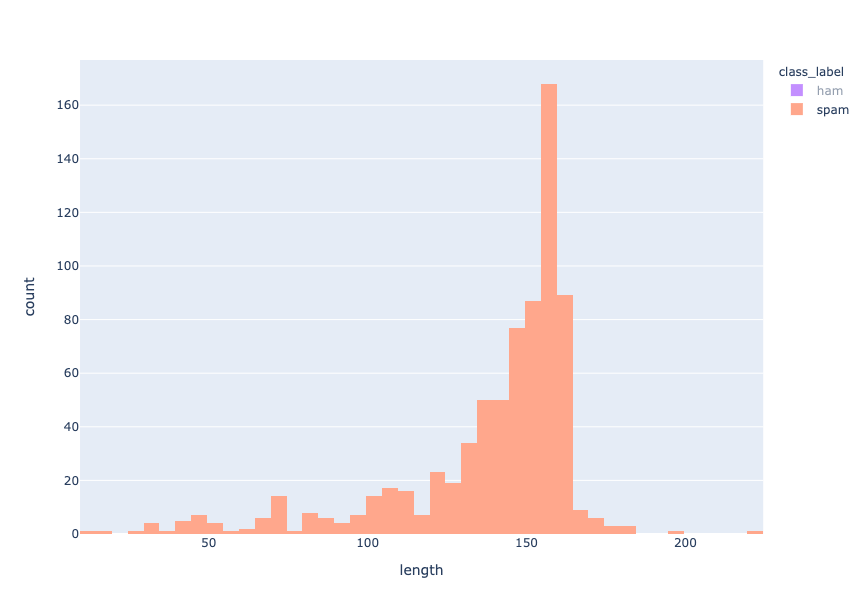 Length distribution - spam
Length distribution - spam
Se puede observar que los mensajes de spam son más cortos que los de spam, ya que la distribución de las longitudes de los mensajes de spam y de spam se centra en torno a 30-40 y 155-160 caracteres, respectivamente.
Tener una visión de las palabras más comunes utilizadas en spams y hams nos ayudará a comprender mejor el conjunto de datos. Una nube de palabras puede darnos una idea de qué tipo de palabras predominan en cada clase.
Para hacer una nube de palabras, primero separe las clases en dos marcos de datos pandas y añada una función simple de nube de palabras, como se muestra a continuación:
data_ham = df[df['class_label'] == "ham"].copy()
data_spam = df[df['class_label'] == "spam"].copy()
def show_wordcloud(df, title):
text = ' '.join(df['message'].astype(str).tolist())
stopwords = set(wordcloud.STOPWORDS)
fig_wordcloud = wordcloud.WordCloud(stopwords=stopwords, background_color="#ffa78c",
width = 3000, height = 2000).generate(text)
plt.figure(figsize=(15,15), frameon=True)
plt.imshow(fig_wordcloud)
plt.axis('off')
plt.title(title, fontsize=20)
plt.show()A continuación se muestra el código que muestra una nube de palabras para los SMS de spam:
show_wordcloud(data_spam, "Spam messages") word cloud spam
word cloud spam
También puedes visualizar la nube de palabras de los SMS de jamón:
show_wordcloud(data_ham, "ham messages")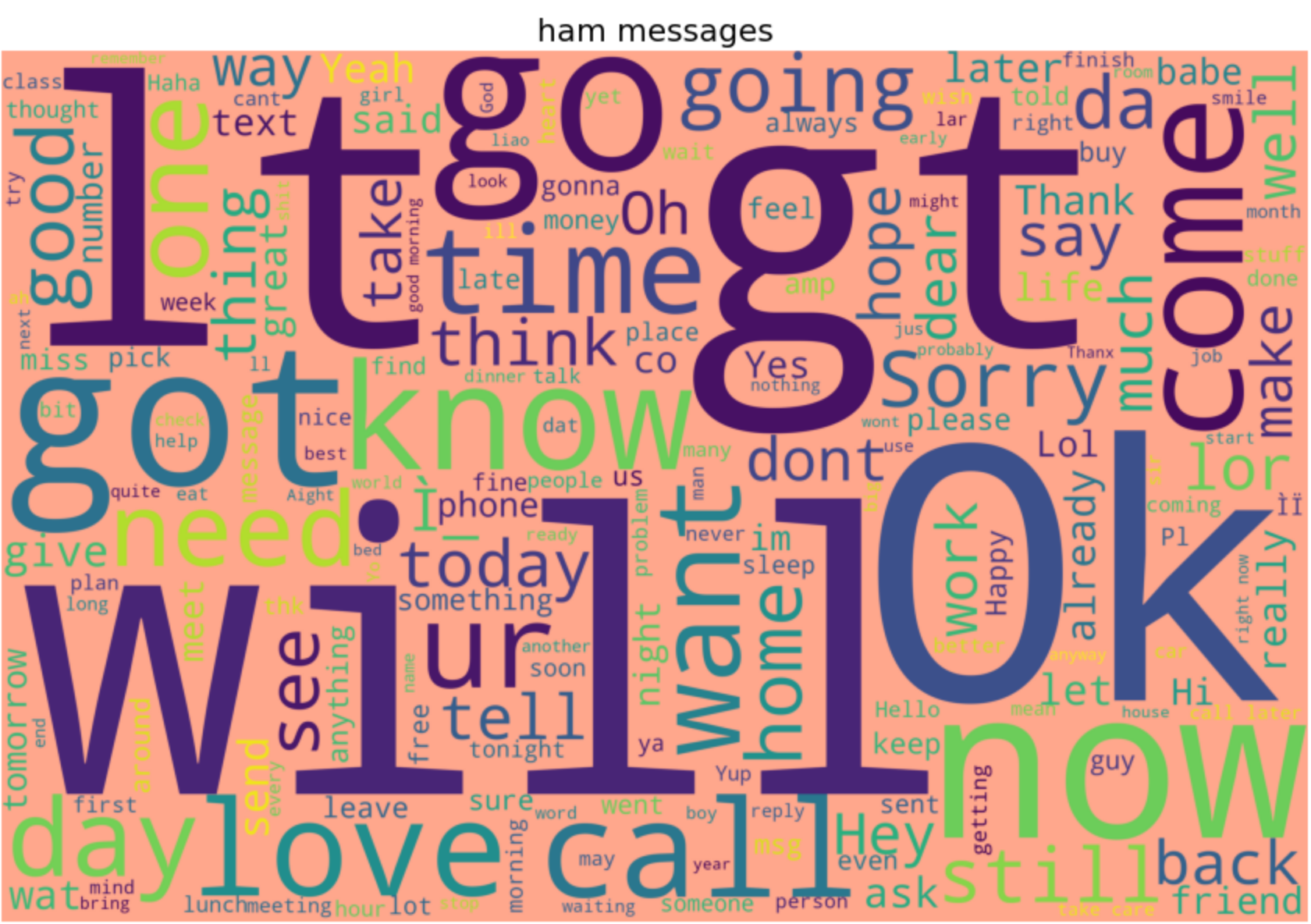 word cloud ham
word cloud ham
El proceso de convertir los datos en algo que un ordenador pueda entender se denomina preprocesamiento. En el contexto de este artículo, se trata de procesos y técnicas para preparar nuestros datos de texto para nuestro algoritmo de aprendizaje automático.
En primer lugar, convertiremos la etiqueta a formato numérico. Esto es esencial antes del entrenamiento del modelo, ya que los modelos de aprendizaje profundo necesitan datos en forma numérica.
df['class_label'] = df['class_label'].map( {'spam': 1, 'ham': 0})A continuación, procesaremos el contenido del mensaje con expresiones regulares (Regex) para mantener uniformes las direcciones de correo electrónico y web, los números de teléfono y los números, codificar los símbolos, eliminar los signos de puntuación y los espacios en blanco y, por último, convertir todo el texto a minúsculas:
# Replace email address with 'emailaddress'
df['message'] = df['message'].str.replace(r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
# Replace urls with 'webaddress'
df['message'] = df['message'].str.replace(r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
# Replace money symbol with 'money-symbol'
df['message'] = df['message'].str.replace(r'£|\$', 'money-symbol')
# Replace 10 digit phone number with 'phone-number'
df['message'] = df['message'].str.replace(r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
# Replace normal number with 'number'
df['message'] = df['message'].str.replace(r'\d+(\.\d+)?', 'number')
# remove punctuation
df['message'] = df['message'].str.replace(r'[^\w\d\s]', ' ')
# remove whitespace between terms with single space
df['message'] = df['message'].str.replace(r'\s+', ' ')
# remove leading and trailing whitespace
df['message'] = df['message'].str.replace(r'^\s+|\s*?$', ' ')
# change words to lower case
df['message'] = df['message'].str.lower()A partir de ahora, eliminaremos las stopwords del contenido del mensaje. Las stop words son palabras que los motores de búsqueda han sido programados para ignorar, tanto al indexar las entradas para su búsqueda como al recuperarlas como resultado de una consulta de búsqueda, como "el", "un", "una", "en", "pero", "porque", etc.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
df['message'] = df['message'].apply(lambda x: ' '.join(term for term in x.split() if term not in stop_words))A continuación, extraeremos la forma base de las palabras eliminando los afijos. Es lo que se denomina "stemming", que es como reducir las ramas de un árbol a sus tallos. Existen numerosos algoritmos de stemming, como:
Algoritmo Stemmer de Porter
Lovins Stemmer
Dawson Stemmer
Krovetz Stemmer
Xerox Stemmer
N-Grama Stemmer
Bola de nieve Stemmer
Lancaster Stemmer
Algunos de estos algoritmos son agresivos y dinámicos. Algunos se aplican a lenguas distintas del inglés y el tamaño de los datos del texto afecta a varias eficiencias. En este artículo se ha utilizado el algoritmo Snowball Stemmer por su velocidad de cálculo.
Nota: Al utilizar estos algoritmos de derivación, tenga cuidado de no excederse ni quedarse corto.
ss = nltk.SnowballStemmer("english")
df['message'] = df['message'].apply(lambda x: ' '.join(ss.stem(term) for term in x.split()))Los algoritmos de aprendizaje automático no pueden trabajar directamente con texto en bruto. El texto debe convertirse en números, más concretamente, en vectores de números. Vamos a dividir los mensajes (datos de texto en frases) en palabras. Se trata de un requisito en las tareas de procesamiento del lenguaje natural, en las que es necesario capturar cada palabra y someterla a un análisis posterior. En primer lugar, creamos un modelo Bag of Words (BOW) para extraer características del texto:
sms_df = df['message']
from nltk.tokenize import word_tokenize
# creating a bag-of-words model
all_words = []
for sms in sms_df:
words = word_tokenize(sms)
for w in words:
all_words.append(w)
all_words = nltk.FreqDist(all_words)Veamos el número total de palabras:
print('Number of words: {}'.format(len(all_words))) Number of words 6526
Number of words 6526
Trace ahora las 10 palabras más comunes en los datos de texto:
all_words.plot(10, title='Top 10 Most Common Words in Corpus');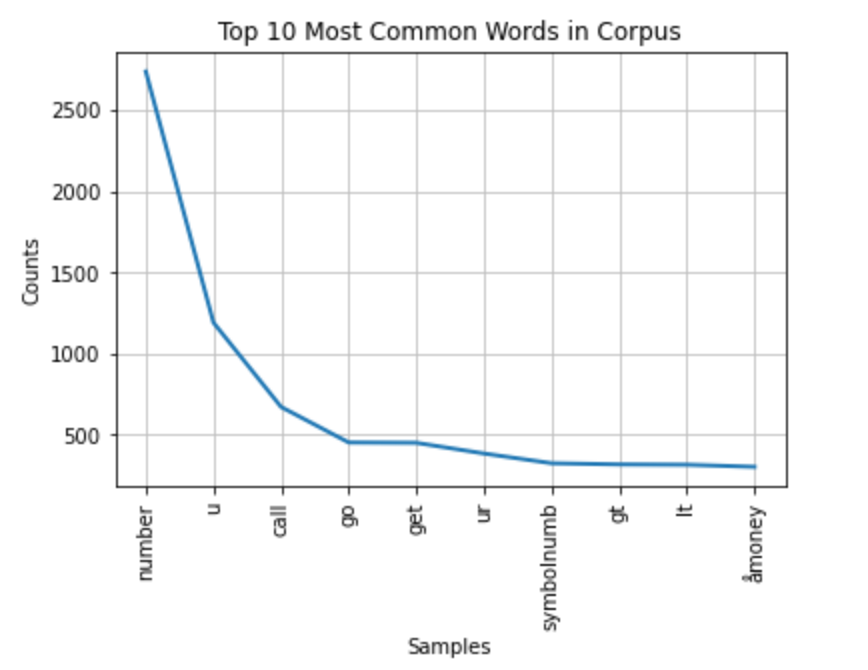 Most common words
Most common words
A continuación, aplicaremos una técnica de PNL -frecuencia de términos-frecuencia inversa de documentos- para evaluar la importancia de las palabras en los datos textuales. En resumen, esta técnica simplemente define lo que es una "palabra relevante". El modelo tfidf_model creado a partir de esta técnica NLP se guardará (serializará) en el disco local para transformar posteriormente los datos de prueba de nuestra aplicación web:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
tfidf_vec=tfidf_model.fit_transform(sms_df)
import pickle
#serializing our model to a file called model.pkl
pickle.dump(tfidf_model, open("../model/tfidf_model.pkl","wb"))
tfidf_data=pd.DataFrame(tfidf_vec.toarray())
tfidf_data.head() tfidf
tfidf
La forma del marco de datos resultante es de 5572 por 6506. Para entrenar y validar el rendimiento de nuestro modelo de aprendizaje automático, tenemos que dividir los datos en un conjunto de datos de entrenamiento y otro de prueba, respectivamente. El conjunto de entrenamiento debe dividirse posteriormente en un conjunto de entrenamiento y otro de validación.
### Separating Columns
df_train = tfidf_data.iloc[:4457]
df_test = tfidf_data.iloc[4457:]
target = df['class_label']
df_train['class_label'] = target
Y = df_train['class_label']
X = df_train.drop('class_label',axis=1)
# splitting training data into train and validation using sklearn
from sklearn import model_selection
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,Y,test_size=.2, random_state=42)La proporción de división para el conjunto de validación es del 20% de los datos de entrenamiento.
Utilizaremos un algoritmo de aprendizaje automático conocido como LightGBM. Se trata de un marco de refuerzo de gradiente que utiliza algoritmos de aprendizaje basados en árboles. Tiene las siguientes ventajas:
Mayor velocidad de entrenamiento y mayor eficacia
Menor uso de memoria
Mayor precisión
Soporte de aprendizaje paralelo y GPU
Capaz de manejar datos a gran escala
La métrica de rendimiento para este proyecto es la puntuación F1. Esta métrica tiene en cuenta tanto la precisión como la recuperación para calcular la puntuación. La puntuación F1 alcanza su mejor valor en 1 y el peor en 0.
import lightgbm as lgb
from sklearn.metrics import f1_score
def train_and_test(model, model_name):
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f'F1 score is: {f1_score(pred, y_test)}')
for depth in [1,2,3,4,5,6,7,8,9,10]:
lgbmodel = lgb.LGBMClassifier(max_depth=depth, n_estimators=200, num_leaves=40)
print(f"Max Depth {depth}")
print(" ")
print(" ")
train_and_test(lgbmodel, "Light GBM") F1 score
F1 score
A partir de esta iteración, puede verse que la profundidad máxima de seis (6) tiene la puntuación F1 más alta de 0,9285714285714285. A continuación, realizaremos una búsqueda aleatoria de los mejores parámetros para el modelo:
from sklearn.model_selection import RandomizedSearchCV
lgbmodel_bst = lgb.LGBMClassifier(max_depth=6, n_estimators=200, num_leaves=40)
param_grid = {
'num_leaves': list(range(8, 92, 4)),
'min_data_in_leaf': [10, 20, 40, 60, 100],
'max_depth': [3, 4, 5, 6, 8, 12, 16, -1],
'learning_rate': [0.1, 0.05, 0.01, 0.005],
'bagging_freq': [3, 4, 5, 6, 7],
'bagging_fraction': np.linspace(0.6, 0.95, 10),
'reg_alpha': np.linspace(0.1, 0.95, 10),
'reg_lambda': np.linspace(0.1, 0.95, 10),
"min_split_gain": [0.0, 0.1, 0.01],
"min_child_weight": [0.001, 0.01, 0.1, 0.001],
"min_child_samples": [20, 30, 25],
"subsample": [1.0, 0.5, 0.8],
}
model = RandomizedSearchCV(lgbmodel_bst, param_grid, random_state=1)
search = model.fit(X_train, y_train)
search.best_params_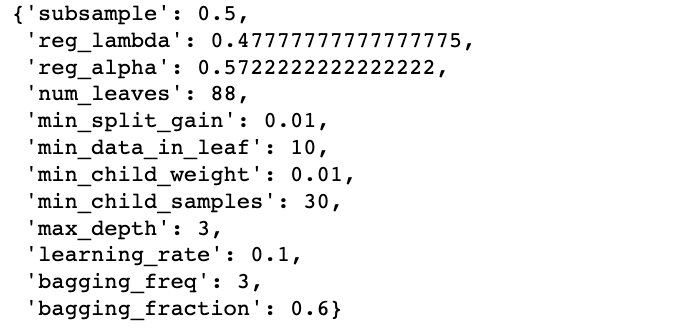 best parameters search
best parameters search
Utilizaremos los mejores parámetros para entrenar el modelo:
best_model = lgb.LGBMClassifier(subsample=0.5,
reg_lambda= 0.47777777777777775,
reg_alpha= 0.5722222222222222,
num_leaves= 88,
min_split_gain= 0.01,
min_data_in_leaf= 10,
min_child_weight= 0.01,
min_child_samples= 30,
max_depth= 3,
learning_rate= 0.1,
bagging_freq= 3,
bagging_fraction= 0.6,
random_state=1)
best_model.fit(X_train,y_train) Trained model
Trained model
Comprobemos el rendimiento del modelo mediante su predicción:
prediction = best_model.predict(X_test)
print(f'F1 score is: {f1_score(prediction, y_test)}') Model prediction
Model prediction
Como último paso, realizaremos un entrenamiento completo en el conjunto de datos para que nuestra aplicación web pueda hacer predicciones para datos que no ha visto. Guardaremos el modelo en nuestra máquina local:
best_model.fit(tfidf_data, target)
pickle.dump(best_model, open("../model/spam_model.pkl","wb"))
Ahora que tienes el modelo entrenado, vamos a crear una aplicación Flask que leerá los mensajes enviados y recibidos a través de la API de SMS de Vonage y los clasificará en spam o jamón. El resultado final se mostrará en un panel de SMS que también vas a definir en esta sección.
El directorio web_app directorio se compone de:
├── app.py
├── static
│ ├── Author.png
│ ├── style.css
│ ├── style2.css
│ └── vonage_logo.svg
└── templates
├── inbox.html
├── index.html
└── predict.htmlEn su editor de código, abra un nuevo archivo llamado .env (observe el punto inicial) y añada las siguientes credenciales:
API_KEY=<Your API key>
API_SECRET=<Your API secret>
Esto es importante por motivos de seguridad, ya que nunca debe codificar sus secretos en su aplicación.
A continuación, creamos un archivo llamado app.py en el directorio web_app directorio. Importaremos las bibliotecas para crear correctamente la aplicación web. Luego, cargaremos nuestras credenciales de la API de Vonage desde el archivo .env e iniciaremos la aplicación Flask. También importaremos los modelos guardados de nuestro bloc de notas.
import os
import warnings
import nexmo
from flask import Flask, render_template, url_for, request, session
import pickle
import pandas as pd
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("API_KEY")
API_SECRET = os.getenv("API_SECRET")
client = nexmo.Client(key=API_KEY, secret=API_SECRET)
warnings.filterwarnings("ignore")
app = Flask(__name__)
# secret key is needed for session
app.secret_key = os.getenv('SECRET_KEY')Después de la instancia de aplicación Flask, utilizamos sesiones Flask para ayudar a la retención de datos en varios intervalos de registro del servidor. Estas sesiones requieren que tengas una clave secreta-puedes guardar el valor de la clave secreta en el archivo .env y cargarlo como hicimos con las credenciales de la API.
A continuación, definimos tres funciones relacionadas con las rutas: home(), inbox()y predict(). Las plantillas respectivas de estas rutas son index.html, inbox.htmly predict.htmlcon dos hojas de estilo, stlye.css y stlye2.css.
La ruta home/index proporciona la interfaz para enviar el mensaje:
@app.route('/', methods=['GET', 'POST'])
def home():
return render_template('index.html')La interfaz se muestra a continuación:
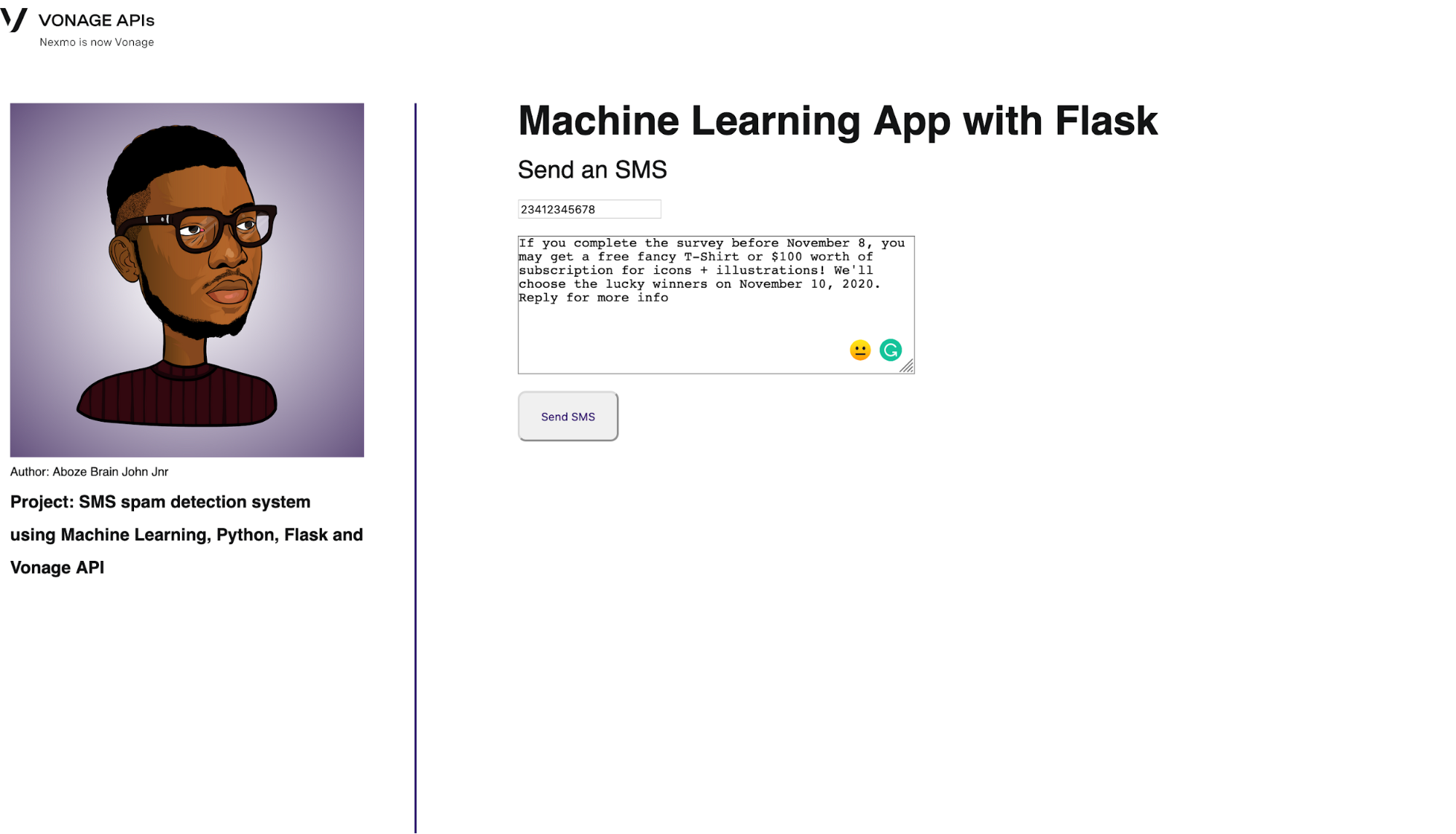 Home interface
Home interface
El archivo index.html en el directorio templates debe tener el siguiente aspecto:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Spam detection Project</title>
<link rel="stylesheet" href="../static/style.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Machine Learning App with Flask</h1>
<p>Send an SMS</p>
<form action="/inbox" method="POST">
<input id="to_number" class="form-control" name="to_number" type="tel" placeholder="Phone Number"/>
<br>
<br>
<textarea id="message" class="form-control" name="message" placeholder="Your text message goes here" rows="10" cols="50"></textarea>
<br>
<br>
<input type="submit" class="btn-info" value="Send SMS">
</form>
</div>
</section>
</body>
</html>
La siguiente ruta es la ruta de la bandeja de entrada, donde se almacenan los mensajes enviados y el número de teléfono del remitente del índice. La SMS API de Vonage se utiliza aquí para iniciar el objeto cliente y enviar el mensaje:
@app.route('/inbox', methods=['GET', 'POST'])
def inbox():
""" A POST endpoint that sends an SMS. """
# Extract the form values:
to_number = request.form['to_number']
message = request.form['message']
session['to_number'] = to_number
session['message'] = message
# Send the SMS message:
result = client.send_message({
'from': 'Vonage APIs',
'to': to_number,
'text': message,
})
return render_template('inbox.html', number=to_number, msg=message)La interfaz se muestra a continuación:
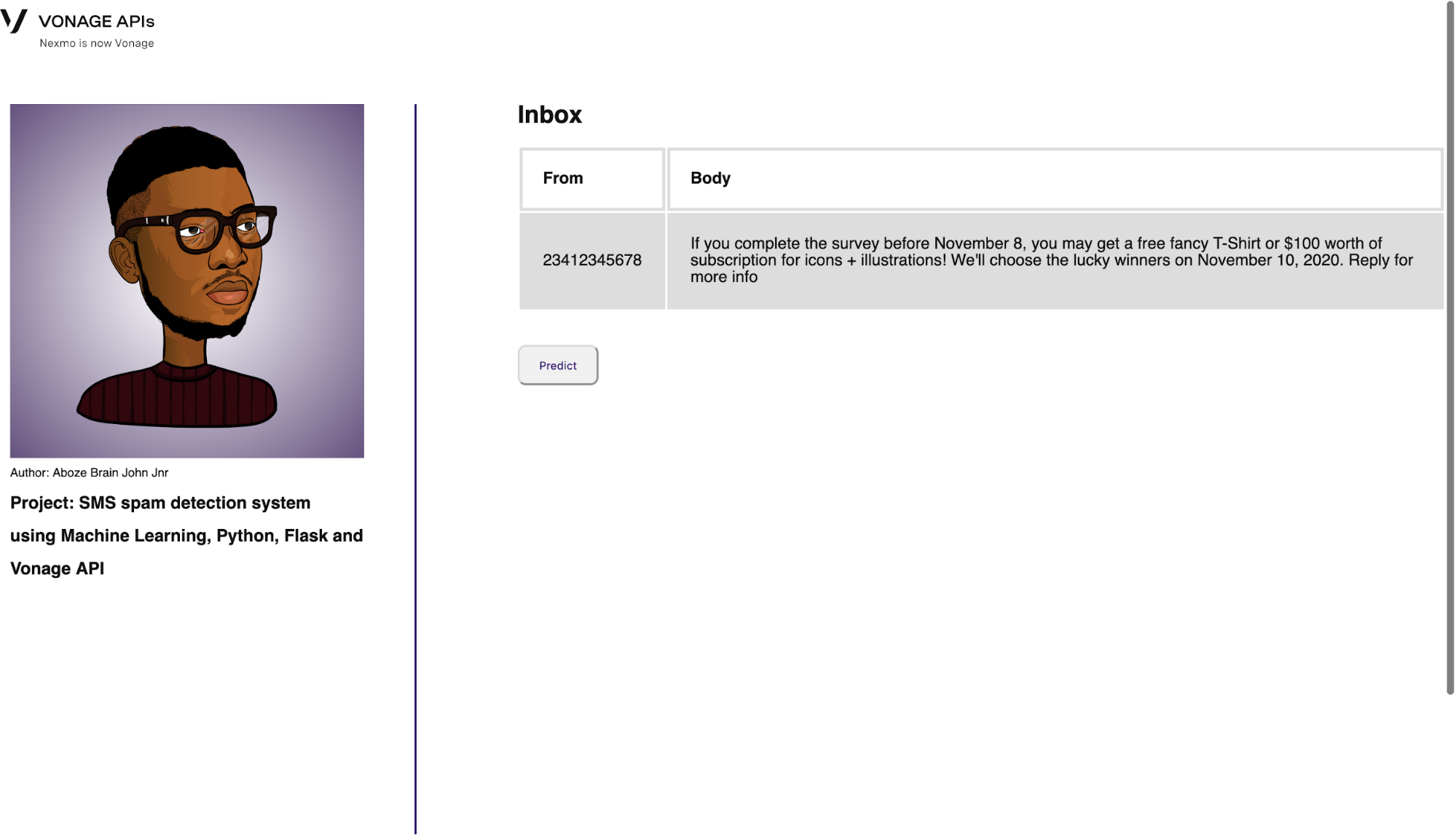 Inbox interface
Inbox interface
El archivo inbox.html en el directorio templates tiene el siguiente aspecto:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Inbox</h1>
<br>
<table class="table" >
<tr>
<th scope="col">From</th>
<th scope="col">Body</th>
</tr>
<tr scope='row'>
<td>{{number}}</td>
<td>{{msg}}</td>
</tr>
</table>
<br>
<br>
<form action="/predict" method="POST">
<input type="submit" class="btn-info" value="Predict">
</form>
<!-- <input type="submit" class="btn-info" value="Predict" formaction="/predict" method="POST"> -->
</div>
</section>
</body>
</html>
La última ruta es para nuestra predicción. Aplica todas las técnicas de preprocesamiento anteriores utilizadas para entrenar el modelo de aprendizaje automático a los nuevos datos en forma de mensajes de la bandeja de entrada:
@app.route('/predict', methods=['POST'])
def predict():
model = pickle.load(open("../model/spam_model.pkl", "rb"))
tfidf_model = pickle.load(open("../model/tfidf_model.pkl", "rb"))
if request.method == "POST":
message = session.get('message')
message = [message]
dataset = {'message': message}
data = pd.DataFrame(dataset)
data["message"] = data["message"].str.replace(
r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
data["message"] = data["message"].str.replace(
r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
data["message"] = data["message"].str.replace(r'£|\$', 'money-symbol')
data["message"] = data["message"].str.replace(
r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
data["message"] = data["message"].str.replace(r'\d+(\.\d+)?', 'number')
data["message"] = data["message"].str.replace(r'[^\w\d\s]', ' ')
data["message"] = data["message"].str.replace(r'\s+', ' ')
data["message"] = data["message"].str.replace(r'^\s+|\s*?$', ' ')
data["message"] = data["message"].str.lower()
stop_words = set(stopwords.words('english'))
data["message"] = data["message"].apply(lambda x: ' '.join(
term for term in x.split() if term not in stop_words))
ss = nltk.SnowballStemmer("english")
data["message"] = data["message"].apply(lambda x: ' '.join(ss.stem(term)
for term in x.split()))
# tfidf_model = TfidfVectorizer()
tfidf_vec = tfidf_model.transform(data["message"])
tfidf_data = pd.DataFrame(tfidf_vec.toarray())
my_prediction = model.predict(tfidf_data)
return render_template('predict.html', prediction=my_prediction)La interfaz se muestra a continuación:
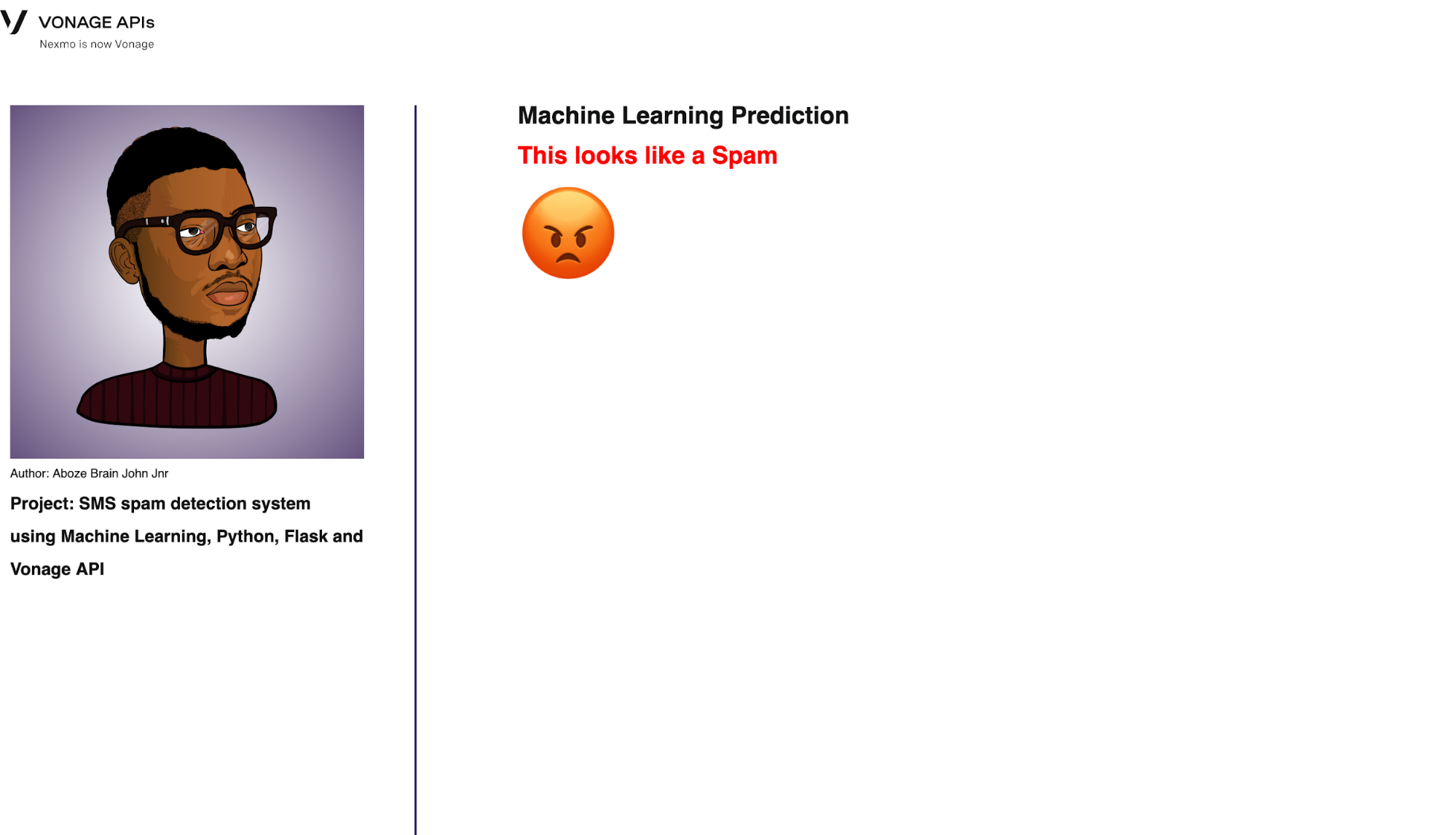 Prediction interface
Prediction interface
El archivo predict.html en el directorio templates tiene el siguiente aspecto:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main results">
<h1>Machine Learning Prediction</h1>
{% if prediction == 1%}
<h2 style="color:red; font-size: x-large;">This looks like a Spam</h2>
<span style='font-size:100px;'>😡</span>
{% elif prediction == 0%}
<h2 style="color:green; font-size: x-large;">This looks like a Ham</h2>
<span style='font-size:100px;'>😀</span>
{% endif %}
</div>
</section>
</body>
</html>
Al final del archivo Python, añade este código para iniciar un servidor local:
if __name__ == '__main__':
app.run(debug=True)A continuación se proporciona el css minificado de las dos hojas de estilo de apoyo utilizadas en este proyecto.
Para style.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}.main h1{font-size:40px;padding-bottom:15px}.main p{font-size:24px;padding-bottom:15px}.btn-info{color:#310069;height:50px;width:100px;border-radius:8px}Para style2.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}td,th{border:3px solid #ddd;text-align:left;padding:20px}tr:nth-child(even){background-color:#ddd}input{width:80px;height:40px;border-radius:8px;color:#310069}button{width:80px;height:40px;border-radius:8px;color:#310069}Ya puedes probar tu aplicación. Para iniciar el servidor, abra la carpeta raíz en un terminal y ejecute lo siguiente en el directorio web_app directorio:
Si has seguido todos los pasos anteriores, entonces deberías ver tu servidor funcionando como se muestra a continuación:
 Server output
Server output
Introduzca http://localhost:5000/ en la barra de direcciones para conectarse a la aplicación.
Con esto, llegamos al final de este tutorial. Puedes probar otros ejemplos de SMS para ver el resultado. Estoy seguro de que ya puedes pensar en todas las increíbles posibilidades y casos de uso de este nuevo conocimiento. Puedes integrar este filtrado de spam en software de RRHH, chatbots, atención al cliente y cualquier otra aplicación basada en mensajes.
¿Tienes alguna pregunta o algo que compartir? Únete a la conversación en Slack de la comunidad de Vonagey mantente actualizado con el Boletín para desarrolladoressíguenos en X (antes Twitter)suscríbete a nuestro canal de YouTube para ver tutoriales en video, y sigue la página de página para desarrolladores de Vonage en LinkedInun espacio para que los desarrolladores aprendan y se conecten con la comunidad. Mantente conectado, comparte tu progreso y entérate de las últimas noticias, consejos y eventos para desarrolladores.
Compartir:
Aboze Brain John es analista de negocio de tecnología en Axa Mansard. Tiene experiencia en ciencia y análisis de datos, investigación de productos y redacción técnica. Brain ha participado en proyectos integrales de análisis de datos que van desde la recopilación de datos, la exploración, la transformación, el modelado y la derivación de conocimientos empresariales procesables, y proporciona liderazgo en conocimientos.