
Compartir:
Ori es jefe de tecnología en Vonage Israel. Le encanta el software, la música, el fútbol, el ajedrez y los animales.
Minimizar los problemas de producción con el seguimiento de registros
Pongámonos en situación:
Se ha producido un incidente crítico en la producción. Depende de usted encontrarlo y resolverlo. Investigas los registros de los cien servicios diferentes y te pierdes totalmente. ¿Qué acción causó qué reacción? ¿El error está relacionado con esta llamada a la API o con esta otra? A todos nos ha pasado. Y todos estamos de acuerdo en que no es divertido.
Pero existe una solución. Una solución que no resolverá todos sus problemas de producción, pero que le ayudará enormemente. Y la buena noticia es que puede integrarse fácilmente en tus servicios.
Rastreo de registros.
Parece sencillo, ¿verdad? Pero en realidad, puede ser una poderosa herramienta para casi cualquier tipo de investigación. Porque en las arquitecturas modernas de hoy en día, cuando un usuario pulsa un solo botón en nuestro sitio, dispara una petición API a la pasarela API, a un servicio de negocio, a una base de datos, a otro servicio, a un bus de mensajes centralizado, a otro servicio, etcétera, etcétera.
Es un viaje abrumador que se ve inundado por cientos de registros producidos por cada flujo que sucede cientos de veces por segundo por cientos de miles de usuarios. Uf.
Antes de pasar a la aplicación de estos conceptos, vamos a entender lo que queremos decir cuando decimos que queremos rastrear los registros. Rastrear suele significar añadir algún identificador que pueda utilizarse para agregar datos. El significado de cada ID es entonces una cuestión de gusto. Podemos tener un ID de rastreo que se añada a todos los datos de una única petición. O podemos tener un conjunto de ID de tramo que se utilizarán en el contexto de un servicio. La idea básica es la siguiente
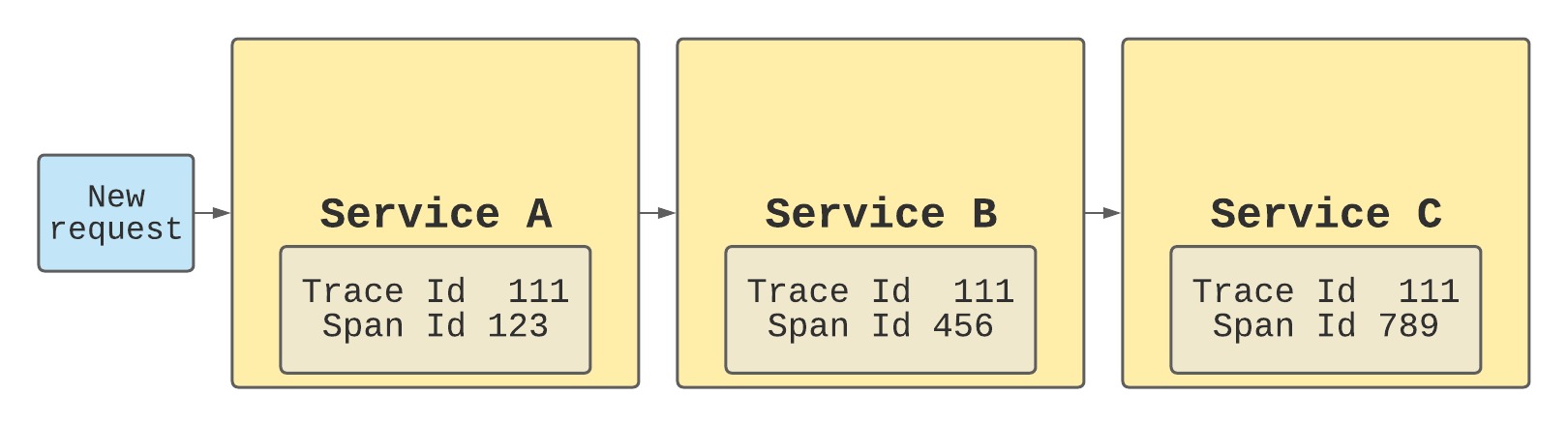 basic log tracing flow
basic log tracing flow
Hay que entender dos conceptos clave:
Agregue todos los registros de todos los servicios para cada solicitud mediante rastreo
Deje que la infraestructura se ocupe del seguimiento para que no interfiera con la lógica empresarial.
¿Cómo lo ponemos en práctica?
Este concepto es bastante sencillo. Tenemos que seguir dos reglas muy sencillas:
Añade el ID de rastreo a cada registro que escribamos para una petición y pasa el ID de rastreo siempre que realicemos cualquier operación IO.
Si dos servicios se comunican en la misma petición a través de un bus de mensajes, añadiremos al mensaje añadido al bus el ID de rastreo. Si dos servicios se comunican a través de peticiones http, añadiremos el ID de rastreo a las cabeceras de la petición. De esta forma, podemos seguir una única petición a través de todo su flujo sin ningún ruido de otras peticiones o registros que se produzcan en paralelo.
Asegurarnos de que podemos hacer un seguimiento de todos los datos enviados o recibidos puede requerir una buena cantidad de codificación. Siempre queremos separar conceptos de infraestructura como este de la lógica de negocio tanto como sea posible. Por suerte, en nuestro caso, es fácil separar la gestión del rastreo casi por completo.
En nuestro código, escribimos registros para varios eventos y errores mientras añadimos datos a estos registros. Queremos mantener estos flujos intactos mientras añadimos nuestro rastreo a todos los registros en paralelo. La mayoría de las herramientas que utilizamos hoy en día nos permiten añadir interceptores a cada solicitud que reciben. Si nos aseguramos de añadir interceptores a nuestra herramienta IO y a nuestra herramienta de registro, estaremos en el camino de asegurar que todos los registros serán rastreados sin tocar nada del código existente.
La forma más fácil de explicarlo es mostrando un ejemplo real de nuestros propios servicios.
Este código de abajo del servicio nodejs que recibe peticiones http, escribe varios logs y luego hace una petición http al siguiente servicio. Es uno de los tres lugares donde hemos colocado interceptores: solicitud de entrada, registro y solicitud de salida.
function tracingMiddleware(req,res,next) {
ns.run(() => {
let traceId = req.headers['x-b3-traceid'];
let spanId = req.headers['x-b3-spanid'];
if (!traceId || !spanId) {
traceId = uuid().replace(/-/g, '');
spanId = uuid().replace(/-/g, '').substring(16);
}
ns.set('traceId', traceId);
ns.set('spanId', spanId);
next();
});
}
Utilizamos Express como nuestra infraestructura de API para implementar express middlewares que interceptan cada solicitud. Extraemos el ID de seguimiento de la solicitud o creamos uno nuevo si somos el primer servicio de la cadena. A continuación, establecemos el ID de rastreo en una herramienta de almacenamiento de sesiones para poder recuperarlo en cada paso del proceso.
Fíjese en el ns.set. Esto es usando cls-hookedun paquete de almacenamiento local de continuación que envuelve los ganchos asíncronos de nodo. Nos permite almacenar localmente el ID de rastreo de cada sesión. Pero si estás usando Node 14, esta funcionalidad ya está integrada con async local storage. Lo bueno de este método, sin embargo, es que puede ser implementado en cualquier lenguaje.
A continuación, añadimos un interceptor a la herramienta de registro que toma el ID de rastreo del almacenamiento de sesión y lo añade a cada línea de registro:
function createBunyanStreamMiddleware(streams) {
return {
type: 'raw',
level: process.env.LOG_LEVEL,
stream: {
write: (entry) => {
if(ns && ns.active) {
entry['traceId'] = ns.get('traceId');
entry['spanId'] = ns.get('spanId');
}
streams.forEach((stream) => {
stream.stream.write(entry)
});
}
}
}
}
Por último, añadimos un interceptor a la herramienta http que añade el ID de rastreo a las cabeceras de la solicitud antes de que ésta se envíe:
function insertTracingHeaders(config = {}){
if(ns && ns.active) {
const traceId = ns.get('traceId');
const spanId = ns.get('spanId');
if (!config.headers) {
config.headers = {};
}
if (traceId && spanId) {
config.headers['x-b3-parentspanid'] = spanId;
config.headers['x-b3-traceid'] = traceId;
}
}
return config;
}
El flujo completo será algo parecido a esto:
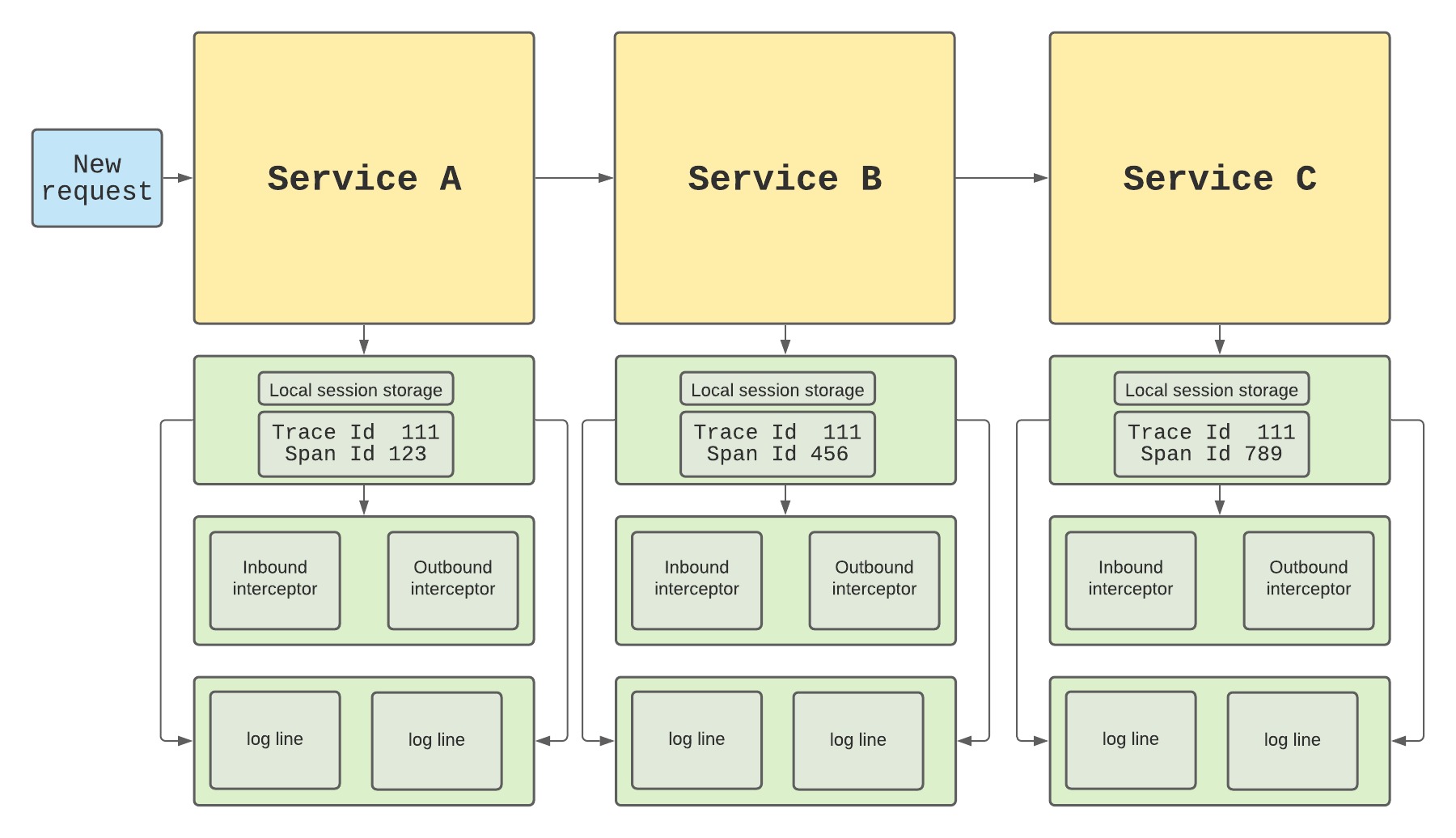 tracing flow with interceptors
tracing flow with interceptors
El rastreo de registros puede utilizarse en todo tipo de contextos, pero este uso en particular evita muchos quebraderos de cabeza a la hora de investigar errores. Garantiza que los registros de peticiones de cada flujo sean fácilmente accesibles, para que no tengas que rebuscar en miles de registros sin relación entre sí.
Podemos decir personalmente que en los servicios en los que hemos aplicado estos Concepts, la eficacia y el valor experimentados durante la investigación de registros se han disparado. Desde entonces, escudriñar los registros de cualquier otra forma no nos parece correcto.
Así, la próxima vez que haya un incidente crítico en producción y te toque a ti resolverlo, al menos esta vez los registros estarán de tu parte.