
Compartir:
Yotam es científico principal de datos en Vonage. Aporta su doctorado en Neurociencia Computacional y su pasión por la ciencia de datos ética a todos los proyectos que emprende. Su trabajo anterior incluye la dirección de un proyecto de investigación financiado con una subvención para crear una herramienta de comunicación controlada por gestos faciales para pacientes con ELA, impulsada por una tecnología de electrodos en la frente accesible y de bajo coste.
Man in the Loop vs. LLM in the Loop
Tiempo de lectura: 8 minutos
En la IA, lograr un equilibrio entre la supervisión humana ("man in the loop") y la automatización ("LLM in the loop") es crucial para crear soluciones reales. En Vonage AI, el equipo responsable de desarrollar servicios de IA dentro de Vonage, nos enfrentamos a este reto mientras rediseñábamos nuestros sistemas de voz a texto (STT) para satisfacer la creciente demanda de transcripciones precisas en los centros de llamadas.
Para superar los límites de la evaluación comparativa tradicional, hemos desarrollado un nuevo método que utiliza modelos lingüísticos amplios (LLM) para generar transcripciones de referencia de alta calidad procesando los resultados de múltiples proveedores de STT. En lugar de basarse en referencias generadas por humanos o en una única "verdad de base", el LLM sintetiza una transcripción de consenso, utilizando su comprensión del lenguaje y el contexto a través de las entradas.
Esta referencia derivada del LLM permite un cálculo escalable, imparcial y sensible al contexto de la tasa de error de palabra (WER) para cada proveedor.
En este post, comparamos este método basado en LLM con la evaluación comparativa tradicional, centrándonos en:
Los límites de los actuales métodos de evaluación comparativa
Cómo sintetizan los LLM las transcripciones de referencia
Principales conclusiones de nuestros experimentos
En Vonage AI, somos un equipo de investigadores e ingenieros dedicados a ampliar los límites de lo que es posible con la inteligencia artificial. Como parte del compromiso de Vonage con las comunicaciones inteligentes, nos centramos tanto en la IA conversacional de vanguardia como en la investigación básica del aprendizaje automático, ofreciendo soluciones de IA sólidas, escalables y con visión de futuro. Esta publicación comparte uno de nuestros esfuerzos de investigación: repensar la forma en que evaluamos la precisión de la transcripción en un mundo en constante cambio y con múltiples modelos.
Hace unos años, cuando afinábamos nuestros modelos STT para los distintos dialectos presentes en el centro de llamadas de nuestros de nuestros clientes de los centros de llamadas de nuestros clientes, recurríamos en gran medida a anotadores humanos para transcribir fragmentos de audio. Estas transcripciones servían como "verdad de base" para entrenar y evaluar nuestros modelos internos.
El proceso lleva mucho tiempo y ralentiza los ciclos de desarrollo.
Los elevados costes dificultan una ampliación eficaz.
Los revisores humanos suelen partir de transcripciones existentes, lo que puede introducir un sesgo inherente en sus correcciones.
La tarea es mentalmente exigente, lo que aumenta la probabilidad de error humano con el tiempo.
Sin embargo, los retos merecieron la pena: nuestro modelo propio perfeccionado acabó superando a las principales soluciones de terceros para nuestro caso de uso específico.
A medida que evolucionaban las necesidades de los clientes, nos enfrentábamos a nuevos retos con el etiquetado manual
Para dar soporte a nuevas lenguas y dialectos era necesario contratar a expertos humanos que dominaran cada lengua específica.
Las pruebas en casos de uso específicos del sector, como la transcripción médica, exigían humanos con experiencia en el campo.
El rápido crecimiento de los modelos avanzados de código abierto introdujo más opciones de evaluación, despliegue y ajuste; por tanto, necesitábamos una forma escalable y coherente de evaluar la precisión sin esperar semanas a la transcripción manual.
Como resultado, entramos en una nueva era: LLM en el bucle.
En lugar de confiar en los humanos para transcribir el audio y obtener la verdad sobre el terreno, ahora utilizamos un Gran Modelo Lingüístico (LLM) para generar transcripciones de referencia. El LLM analiza los resultados de varios sistemas de transcripción y razona entre ellos para obtener la reconstrucción más precisa de lo que se dijo, a veces alineándose con los resultados de un modelo para un segmento parcial del audio y con los resultados de otro modelo para una parte diferente del audio.
Es como tener un árbitro inteligente y rápido que:
Lee varias transcripciones del mismo audio
Comprende el contexto y los matices lingüísticos
Se obtiene una "referencia" fiable e imparcial con la que comparar los modelos.
Para validar el concepto, procesamos un corpus bien conocido que previamente habíamos etiquetado manualmente. Lo utilizamos para estimar la precisión del proceso basado en LLM y, al mismo tiempo, evaluar la contribución original del esfuerzo de etiquetado manual.
Esto es lo que hemos diseñado:
Transcribimos los mismos fragmentos de audio de 5-15 segundos utilizando múltiples sistemas STT, incluidos nuestros propios modelos internos, modelos de código abierto y proveedores de terceros.
Para cada clip, recopilamos todas las transcripciones junto con las etiquetas humanas originales. A continuación, pedimos al LLM que nos diera estas alternativas (sin conocer sus fuentes) y le pedimos que generara la transcripción más precisa y probable para ese fragmento.
Utilizando esta "verdad sintética" generada por el LLM en ~300 muestras, calculamos la tasa de error de palabra (WER) para cada sistema STT.
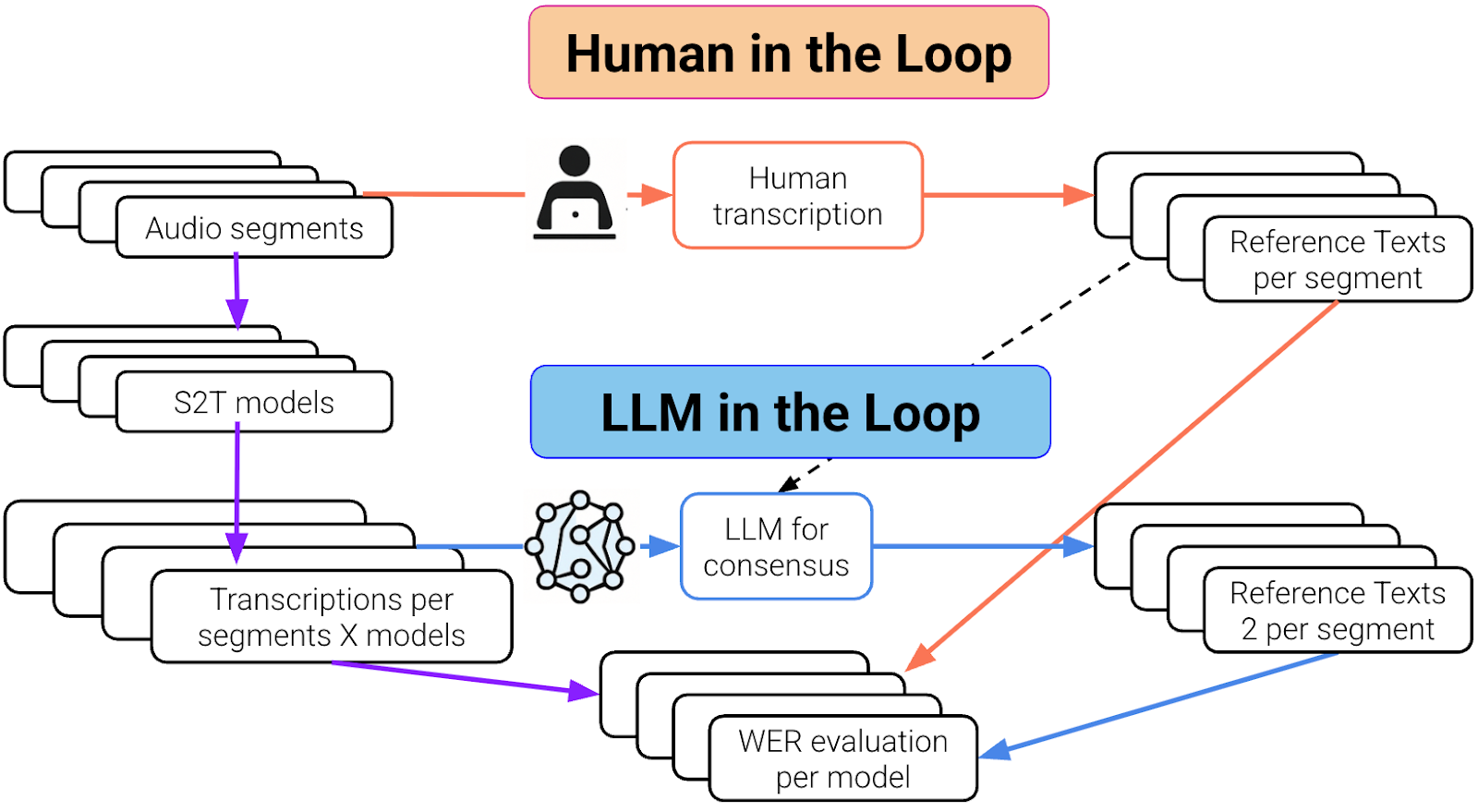 Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Los bucles humano y LLM. La parte morada es común en ambos bucles.
Imaginemos que tenemos las siguientes salidas STT de varios proveedores para un breve fragmento de audio de un agente:
 Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Estas transcripciones varían en cuanto a formato, representación numérica y precisión, lo que refleja los resultados típicos de los distintos modelos.
Se ordena al LLM que genere dos transcripciones de referencia alineadas:
Referencia alfabética:
Si pasa el plazo de veinticuatro horas, se cobrarán cincuenta dólares por cancelar hasta ocho días antes de la llegada.
Referencia alfanumérica:
Si pasa el plazo de 24 horas, se cobrarán 50 $ por cancelar hasta 8 días antes de la llegada.
Este enfoque garantiza una comparación equitativa (e imparcial en cuanto al formato) entre los distintos tipos de resultados de los modelos: los modelos sin formato (como nuestra solución) se miden con referencias sin formato, mientras que los modelos con formato se miden con referencias con formato que conservan un significado equivalente.
Se probaron los siguientes modelos:
IA de Vonage (VAI) - Nuestro modelo interno perfeccionado, entrenado con datos etiquetados manualmente por el mismo equipo.
Vonage AI (VAI): nuestro modelo de versión anterior, no ajustado para este caso de uso.
Las transcripciones originales con etiqueta humana
Tres modelos de código abierto de OpenAI: Whisper-Large(V3), Whisper-Mediano, Whisper-Pequeño
Dos proveedores externos
Para examinar el papel de las referencias humanas, utilizamos el proceso de evaluación basado en LLM en dos configuraciones:
Label-In: La transcripción humana se incluyó entre las salidas alternativas mostradas al LLM para la síntesis de referencia.
Etiquetado: La transcripción humana fue excluida (cegada) de las alternativas mostradas al LLM
Comparamos ambos para evaluar la solidez de la referencia generada por el LLM y los posibles sesgos introducidos por los datos etiquetados por humanos.
Utilizamos la tasa de error de palabra (WER) como principal medida de evaluación. Se trata de una medida estándar de la calidad de la transcripción. El WER cuantifica el número de errores de una transcripción comparándola con una referencia. Estos errores se dividen en tres categorías:
Inserciones: palabras añadidas
Supresiones: palabras omitidas
Sustituciones: palabras incorrectas en lugar de las correctas
La WER se calcula mediante la fórmula
 Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Un WER más bajo indica una transcripción más precisa.
 Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Los WER fueron casi idénticos en ambas configuraciones, lo que demuestra la solidez de las referencias generadas por LLM.
Valores estables de clasificación y WER en las configuraciones de label-in y label-out para la mayoría de los modelos.
"3rd-Party 2" mostró una notable mejora cuando se excluyó la etiqueta humana (WER 10,5 → 9,5), lo que sugiere una mejor alineación con los resultados generados por LLM que con las anotaciones humanas.
En esta evaluación, las transcripciones realizadas por personas obtuvieron una TMA superior a la de casi todos los modelos automatizados. Esto era de esperar, ya que el corpus fue transcrito por hablantes no nativos de inglés y la herramienta de anotación carecía de salvaguardas contra errores tipográficos.
El modelo VAI Fine-tuned entrenado con etiquetas humanas por el mismo equipo siguió superando a su homólogo sin ajustar (WER 13,7 → 12,5), lo que demuestra la utilidad de estos datos a pesar de sus imperfecciones.
Estos resultados demuestran que las transcripciones de referencia generadas por LLM son fiables, coherentes y escalables para la evaluación comparativa de sistemas STT. Los WER y las clasificaciones casi idénticas en todas las evaluaciones, con o sin datos etiquetados por humanos, ponen de manifiesto la solidez del proceso.
Aunque algunos modelos pueden ajustarse mejor al estilo de tokenización o formateo del LLM (como ocurre con "3rd-Party 2"), en general, las referencias derivadas del LLM ofrecen un método de evaluación justo y reproducible.
Es importante destacar que, aunque las referencias etiquetadas por humanos mostraron tasas de error más elevadas, siguen siendo valiosas para el entrenamiento de modelos. El ajuste con estos datos mejoró significativamente el rendimiento del modelo, reafirmando el papel de los datos etiquetados en el desarrollo de modelos, incluso cuando la evaluación puede automatizarse.
Los LLM pueden generar transcripciones de referencia fiables, lo que permite una evaluación comparativa escalable y de alto rendimiento.
Las referencias con etiqueta humana ya no son necesarias para la evaluación, pero siguen ofreciendo ventajas para la formación.
Este método acelera la evaluación comparativa equitativa entre nuevos modelos, idiomas y dominios, eliminando la necesidad de transcripción manual.
¿Quieres crear tu propio agente de IA y comparar distintas soluciones? Puede probar su propio Agente AI Studio y combinarlo con varias soluciones de terceros como Deepgram y ver cuál funciona mejor para ti.
¿Tienes alguna pregunta o algo que compartir? Únete a la conversación en Slack de la comunidad de Vonagey mantente actualizado con el Boletín para desarrolladoressíguenos en X (antes Twitter)suscríbete a nuestro canal de YouTube para ver tutoriales en video, y sigue la página de página para desarrolladores de Vonage en LinkedInun espacio para que los desarrolladores aprendan y se conecten con la comunidad. Mantente conectado, comparte tu progreso y entérate de las últimas noticias, consejos y eventos para desarrolladores.
Compartir:
Yotam es científico principal de datos en Vonage. Aporta su doctorado en Neurociencia Computacional y su pasión por la ciencia de datos ética a todos los proyectos que emprende. Su trabajo anterior incluye la dirección de un proyecto de investigación financiado con una subvención para crear una herramienta de comunicación controlada por gestos faciales para pacientes con ELA, impulsada por una tecnología de electrodos en la frente accesible y de bajo coste.