
Compartir:
Max es un antiguo miembro del equipo de Vonage. Era promotor de Python e ingeniero de software, y le interesaban las API de comunicaciones, el aprendizaje automático, la experiencia de los desarrolladores y ¡el baile! Se formó en Física, pero ahora trabaja en proyectos de código abierto y crea herramientas para facilitar la vida de los desarrolladores.
Mejore su proyecto de software - Tercera parte: Mejoras de siguiente nivel
Tiempo de lectura: 14 minutos
¿Alguna vez te has hecho cargo de una base de código y te has dado cuenta de que no estás contento con cómo está escrito u organizado? Es una historia común, pero que puede causar muchos dolores de cabeza. La deuda técnica puede convertirse en una bola de nieve que dificulte exponencialmente la comprensión del código y la incorporación de nuevas funciones.
En esta serie de tres partes, voy a recorrer algunas de las cosas clave que usted querrá hacer para ser más feliz con su brillante (viejo) proyecto. Para dar algunos ejemplos concretos, voy a atar todo junto explicando cómo he refactorizado y mejorado el código abierto Vonage Python SDKuna biblioteca que realiza llamadas HTTP a las API de Vonage, pero los principios se aplican a cualquier tipo de proyecto de software.
Los ejemplos de este post estarán escritos en Python, pero estos principios se aplican a proyectos en cualquier lenguaje. También hay una práctica lista de comprobación si estás intentando arreglar específicamente un proyecto en Python.
Tercera parte: Mejoras de siguiente nivel (este artículo)
Si has seguido Primera parte y Parte Dos de esta serie, tendrás un buen conocimiento de tu proyecto y puede que ya hayas hecho algunas refactorizaciones, añadido funcionalidades y publicado nuevas versiones.
En la tercera parte hablaremos de:
Mejorar su proyecto
Herramientas que puede utilizar
Automatización
Buenas prácticas para traspasar un proyecto a otra persona
Las mejoras que pueden introducirse en un código se dividen en dos grupos:
Mejoras que benefician directamente al usuario, y
Mejoras que benefician al mantenedor.
Empecemos hablando de algunas mejoras para el usuario.
Cuando un usuario se encuentra con un error, la utilidad de ese error para ayudarle a descubrir lo que está mal puede variar enormemente. Veamos dos ejemplos distintos.
El ejemplo A muestra una forma de escribir una función que comprueba si un parámetro de entrada a un método es válido. El método en cuestión permite a un usuario enviar mensajes a través de canales como SMS, MMS, WhatsApp, Messenger y Viber con la Mensajes API de Vonage. Esta comprobación asegura que han especificado un canal válido.
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise ExceptionEn este caso, si el usuario no especifica un canal de mensajes válido, simplemente verá que se ha producido una excepción. No dispondrá de ninguna información específica y tendrá que rebuscar en su pila de llamadas para ver qué ha provocado el error.

El Anexo B muestra otra forma de escribir este código.
from .errors import MessagesError
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise MessagesError(f"""
'{params['channel']}' is an invalid message channel.
Must be one of the following types: {self.valid_message_channels}'
""")En este caso, creé un error personalizado relacionado con la API de Messages API de Vonage. Especifico un mensaje de error que describe el problema exacto con el código del usuario y lo que puede hacer para solucionarlo. Esto es mucho más claro para el usuario y puede ahorrarle mucho tiempo de depuración.

Podemos ver arriba que el usuario intentó enviar un mensaje de "paloma mensajera" a través de la Messages API, que es un canal no soportado. Este ejemplo muestra lo mucho que puedes ayudar a tus usuarios si creas excepciones personalizadas para ayudar con la depuración.
Si tus usuarios tienen que pasar datos a las funciones de tu código, es posible que quieras considerar qué comprobaciones estás haciendo en esos datos de entrada. Si está utilizando un enfoque basado en clases fuertemente tipadas, como Java Orientado a Objetos, su código intentará reunir los datos de entrada en una estructura apropiada. Si estás utilizando un enfoque menos estricto, es posible que desees validar la entrada del usuario para devolver un error tan pronto como sea posible si las cosas no están bien.
Veamos un par de ejemplos reales. Este es un código del SDK que envía un SMS:
def send_message(self, params):
...
return self._client.post(
self._client.host(),
"/sms/json",
params, # This is the user's input!
supports_signature_auth=True,
**Sms.defaults,
)Si llamas a este método, sucederán estas cosas:
paramsse pasan a la funciónsms.send_messagefunción por el usuarioEstos valores se pasan inmediatamente a otra función, el método
postde la claseclientclaseEl método
postrealiza una petición post y devuelve la respuesta al usuario.
Durante este proceso, la entrada del usuario se asigna inmediatamente al objeto params sin validación alguna. Esto está bien para casos sencillos, pero si la API con la que nos comunicamos acepta muchas combinaciones de opciones, es posible que queramos considerar la validación de la entrada del usuario.
Buena pregunta. Si todo lo que vamos a hacer es lanzar un error de todos modos, ¿por qué molestarse? Bueno, este es un ejemplo perfecto de la "enfoque "a prueba de fallosCapturar los errores en la raíz del problema facilita la depuración y significa que se utilizan menos recursos para realizar peticiones que serán rechazadas.
He aquí otro ejemplo, esta vez de la Mensajes API de Vonage:
def send_message(self, params: dict):
self.validate_send_message_input(params) # This calls the function below
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params, # This is still the user's input, but if we get here, we know it's valid!
auth_type=self._auth_type,
)
def validate_send_message_input(self, params):
# Each of these lines calls a different check on the user's input
# An error is thrown if any of the checks fail
self._check_input_is_dict(params)
self._check_valid_message_channel(params)
self._check_valid_message_type(params)
self._check_valid_recipient(params)
self._check_valid_sender(params)
self._channel_specific_checks(params)
self._check_valid_client_ref(params)Podemos ver que esta vez la entrada de un usuario se comprueba cuidadosamente para que no enviemos una solicitud errónea.
Aunque escribir comprobaciones manuales es eficaz, también merece la pena considerar un enfoque basado en clases o modelos si tienes que validar muchas entradas de usuario. Algunos lenguajes tienen esta función implementada a través de clases fuertemente tipadas, donde el constructor de una clase espera una entrada específica para crear una instancia de esa clase. En este caso, hacer que el usuario cree clases válidas y pasarlas a tus otras funciones puede asegurar que el usuario pasa los datos correctos. En Python, no tenemos un sistema de tipado que funcione de esta forma, pero hay librerías como bibliotecas como Pydantic que pueden crear modelos para hacer esto por ti.
He reescrito el código anterior utilizando un enfoque basado en modelos con Pydantic para utilizar modelos para la validación de entrada:
# I created models (that look like classes) that inherit from Pydantic's BaseModel class.
# I'm able to specify specific constraints, including the type and length of parameters, and specify defaults.
class Message(BaseModel):
to: constr(min_length=7, max_length=15)
sender: constr(min_length=1)
client_ref: Optional[str]
class SmsMessage(Message): # Inherits the properties of the "Message" model
channel = Field(default='sms', const=True)
message_type = Field(default='text', const=True)
text: constr(max_length=1000)
... # More classes for each type of message that the Messages API can send
class Messages: # Class that contains the code to call the Messages API
... # Skipping showing the constructor etc. here
def send_message_from_model(self, message: Message):
params = message.dict()
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params,
auth_type=self._auth_type,
)Esta versión puede parecer más complicada que la anterior, pero nos ahorra escribir manualmente todas las comprobaciones. Ahora, si un usuario quiere enviar un mensaje y se equivoca en parte de la entrada, obtendrá un error sensible que indica lo que puede haber hecho mal.

Ahora, la validación está estrechamente vinculada a la instanciación de la clase. En la implementación anterior, la validación tenía que escribirse manualmente y no era obligatoria. Usando este enfoque basado en modelos con Pydantic, podemos garantizar que no hay ninguna posibilidad de pasar entradas no válidas.
En resumen, cuando trabajes con entradas de usuario, considera la posibilidad de validarlas. La forma de hacer esa validación depende de tu lenguaje y del enfoque que le hayas dado, pero tener alguna forma de validación puede ahorrar mucho tiempo a tus usuarios.
La última mejora potencial de cara al usuario que quiero identificar tiene que ver con el código asíncrono. A menos que tu proyecto tenga que ver con operaciones io-bound, puede que no necesites considerar esto en absoluto - en cuyo caso, simplemente pasa a la siguiente sección.
El código asíncrono es aquel en el que las operaciones pueden ceder el control de un hilo para permitir que sucedan otras cosas. Compárelo con el código síncrono, que espera a que se complete cada operación antes de iniciar la siguiente. Algunos lenguajes (por ejemplo, Node.js) son asíncronos por defecto, pero otros lenguajes tienen características asíncronas que se pueden utilizar cuando sea necesario. Si eres un desarrollador de JavaScript, probablemente puedas saltarte esta sección.
Si tu código hace una solicitud y tiene que esperar mucho tiempo por una respuesta, podría valer la pena escribir tu código de manera asincrónica y permitir que otras cosas sucedan hasta que recibas una respuesta. En el caso del SDK Python de Vonage, estamos realizando solicitudes HTTP a un servidor remoto. Estamos haciendo esto en forma sincrónica, por lo que vale la pena considerar si hacer una versión asincrónica de parte del SDK beneficiaría a mis usuarios. Podemos suponer que hacer un método asíncrono haría posible enviar más peticiones a la vez con el SDK... pero ¿por qué suponer? Hagamos un experimento.
Para investigar si hacer algunos métodos asíncronos disminuiría el tiempo necesario para hacer peticiones, escribí 2 trozos de código. Uno utilizó una función del SDK de Python de Vonage de manera normal para realizar 100 solicitudes HTTP a la API de Number Insight API de Vonage y el otro utilizó una versión asincrónica de la función que creé. Perfilé ambas versiones del código (utilizando el método de creación de perfiles que describí en la primera parte de esta serie, aquí) y podemos ver que la mayor parte del tiempo del programa se dedica a realizar solicitudes HTTP.
La primera imagen a continuación es un gráfico de carámbano que muestra la parte superior de la pila de llamadas de nuestro SDK a medida que realiza 100 solicitudes a una API de Vonage.
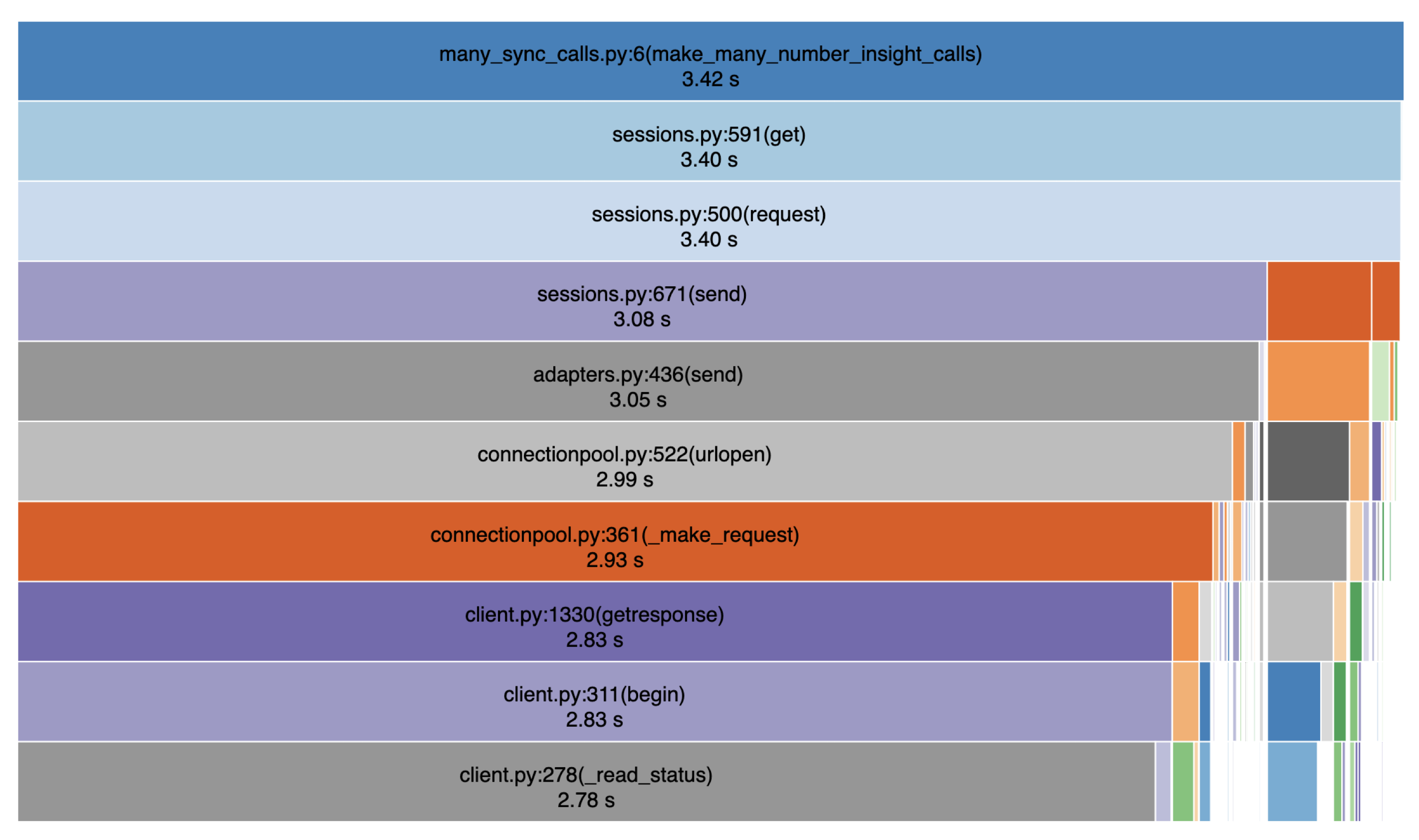
La siguiente imagen muestra la parte inferior de la pila de llamadas. Como puedes ver aquí, la mayor parte del tiempo que tarda en ejecutarse todo el programa (2,78/3,42 segundos, ¡o el 81%!) se gasta sólo en esperar las conexiones SSL entre nuestro código y el servidor remoto. Y eso es sólo una parte del proceso en la que tenemos que esperar al hacer llamadas de sincronización.

Esto sugiere que si el código pudiera ceder el control del hilo hasta que se establezcan las conexiones, ¡el tiempo de ejecución podría ser mucho menor! A continuación se muestran los datos de una versión asíncrona del código, que realiza las mismas 100 peticiones a la misma API.

Podemos ver en el gráfico anterior que toda la tarea se completó en 0,33s, ¡unas 10 veces más rápido que la versión síncrona! En este caso, tiene sentido para mí explorar si debo hacer mi código asíncrono.
El último párrafo parece bastante poco comprometido, dado que acabo de hacer el código 10 veces más rápido. ¿Por qué no querría empezar inmediatamente a asincronizar mi código? Bueno, puede hacer las cosas mucho más complicadas.
Aunque el código asíncrono funciona bien en muchos casos, tiene inconvenientes importantes. Para hacer mi código asíncrono, tendría que reescribir gran parte de él. En Python, las coroutines asíncronas se comportan de forma muy diferente a los métodos normales; tienen que ser llamadas y tratadas de forma muy diferente.
Peor que eso es la cuestión del soporte. Si tuviera que reescribir completamente toda la librería para hacerla asíncrona y lanzar una nueva versión principal del proyecto (como discutimos en la Parte 2), ¡obligaría a mis usuarios a reescribir todo su código que utiliza mi SDK! Si no quisiera hacer pasar a mis usuarios por este calvario, tendría que mantener versiones síncronas y asíncronas del mismo código, duplicando efectivamente el tamaño del código base. Eso es el doble de código para probar, y si quisiera añadir nuevas características tendría que añadirlas dos veces.
Hay formas de aligerar la carga, pero añadir soporte async seguiría siendo una inversión de tiempo significativa. En general, async es muy potente, pero considere cuidadosamente cuáles son los casos de uso para su código base. Si crees que habrá un beneficio muy significativo, considera hacer las cosas async, pero considéralo muy cuidadosamente antes de comprometerte a entregarlo. Y si eres un programador JavaScript que lee esta sección a pesar de que así es como funciona tu código de todos modos, espero que esto haya sido perspicaz, o al menos entretenido. 🤷
Si quieres invertir en la salud a largo plazo de tu proyecto, probablemente querrás configurar herramientas que te ayuden a escribir tu código, o que te den información sobre aspectos del mismo. He mencionado algunas herramientas en Primera parte de esta serie pero hablemos ahora de forma más práctica sobre la aplicación de herramientas automatizadas a tu código.
Suponiendo que su código utiliza el control de versiones, es posible configurar herramientas para ejecutar cuando el código es empujado / PR se hacen, etc. Hay muchas herramientas para hacer esto. En mi caso, Vonage Python SDK utiliza Acciones de GitHubque es gratuito para proyectos de código abierto alojados en GitHub, e incluso para repos privados de GitHub por debajo de cierta cuota de uso.
En mi repo, he configurado una acción GitHub que ejecuta pruebas cuando se hace un push o PR y calcula la cobertura del código. La ventaja de utilizar la automatización para hacer esto es que puedo probar en múltiples plataformas y versiones de Python sin tener que configurar manualmente una máquina virtual para cada plataforma y un nuevo entorno virtual para cada versión de Python. Yo recomendaría la configuración de sus pruebas para ejecutar de esta manera, ya que puede detectar errores antes de de que lleguen a tu entorno de producción.

En Primera parte de esta serie hablamos brevemente de las ventajas que pueden aportar las pruebas de mutación. Puede ser fácil caer en la trampa de la cobertura de código de aumentar la cobertura, sin importar el coste. La ley de Goodhart afirma que "cuando una medida se convierte en un objetivo, deja de ser una buena medida". Los desarrolladores que invierten demasiado en métricas de cobertura de código tienden a sacrificar la calidad de las pruebas por la cantidad de cobertura. La puntuación de mutación es una forma de evitar que esto ocurra.
La puntuación de mutación está relacionada con la capacidad de tus pruebas para ser resistentes a los cambios. Como comentamos en la primera parte, las pruebas de mutación funcionan cambiando el código de forma sutil y aplicando las pruebas unitarias a estas nuevas versiones "mutantes" del código.
Las pruebas de mutación pueden tardar algún tiempo en ejecutarse en una base de código más grande. Afortunadamente, sin embargo, debido a que este es un método de prueba automatizado, es posible añadir pruebas de mutación en un proceso de construcción/liberación. Decidí hacer esto para el Vonage Python SDK, utilizando una biblioteca de mutación Python llamada mutmut.
Configuré una acción de GitHub "Prueba de mutación" que ejecuta una prueba de mutación en el código base, como se muestra a continuación:
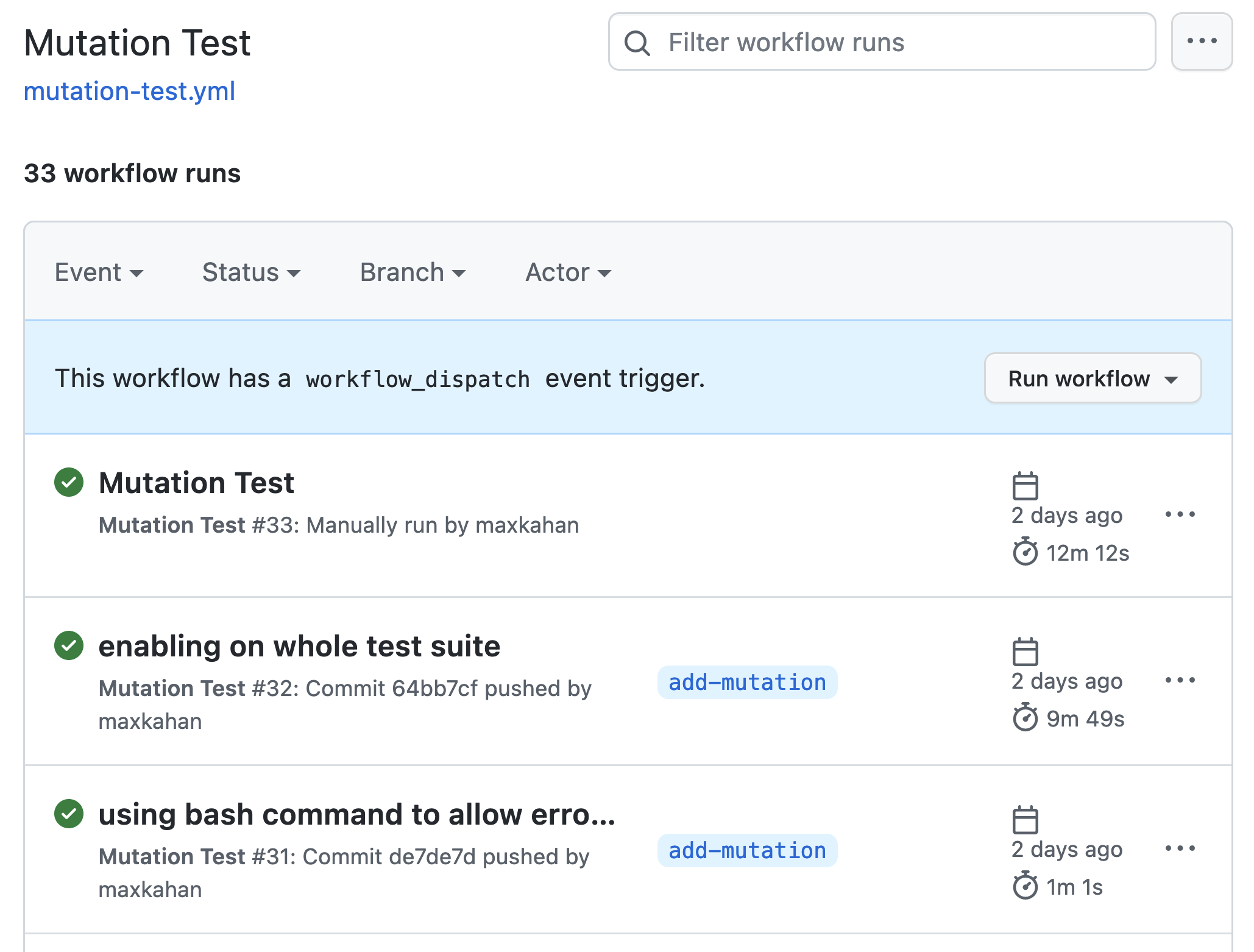
Este flujo de trabajo tiene un disparador de ejecución manual. Esto se debe a que una ejecución automatizada en push o PR tomaría más tiempo del que quiero completar. Tener el flujo de trabajo activado manualmente significa que siempre que quiero obtener información sobre el estado de mi código base, puedo ejecutarlo.

El flujo de trabajo de la prueba de mutaciones genera un resultado HTML que se puede descargar dentro de la ejecución de la prueba específica. Contiene un archivo de índice que muestra una visión general y, a continuación, una lista de las mutaciones que eludieron la detección para cada módulo.
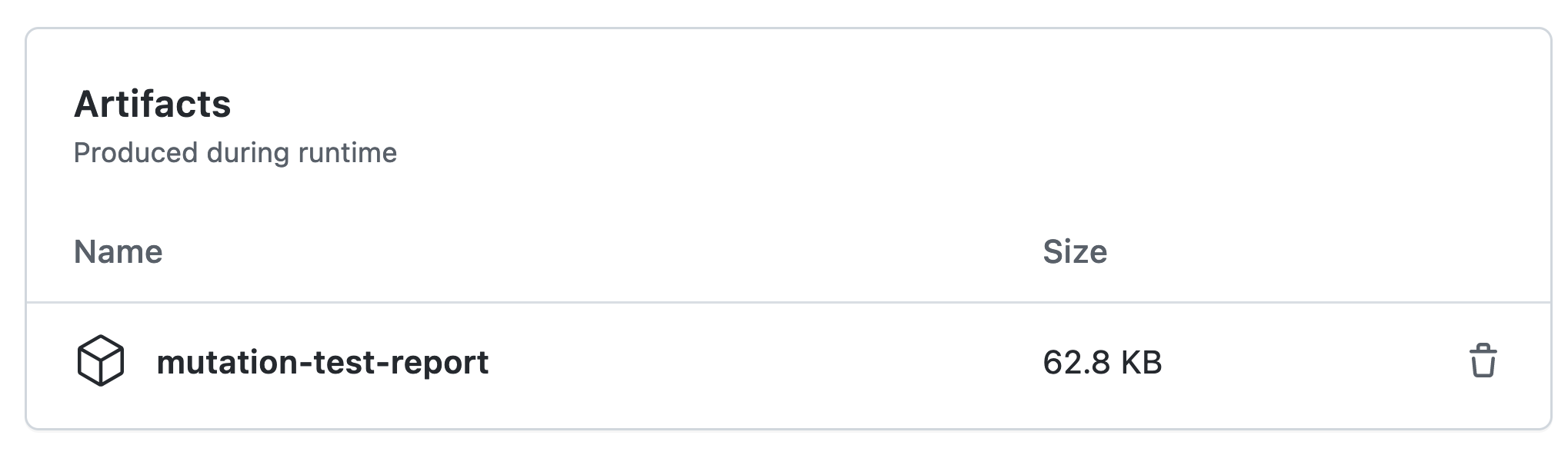
Podemos ver aquí que capturamos 383/522 versiones mutantes del código o alrededor del 74%. Es una buena cantidad, pero podemos ver algunas discrepancias entre módulos y quizá queramos investigar la causa de las mismas. No siempre es productivo intentar conseguir la puntuación más alta (¡recuerda la ley de Goodhart!), pero podemos utilizar estas métricas para comprender mejor lo que hacen nuestras pruebas. Tener una puntuación de mutación que mejore constantemente (aunque sea muy lentamente) es más importante que tener una puntuación alta.
Si tu proyecto utiliza dependencias, deberías estar seguro de que estás utilizando versiones de las mismas que no comprometen la seguridad de tus usuarios. Muchas herramientas automatizadas pueden comprobar esto por ti, por ejemplo Mend para GitHub.comque escanea periódicamente tu código en busca de vulnerabilidades y plantea problemas y PR para intentar solucionarlos.
Es importante utilizar una herramienta que rastree las bases de datos de vulnerabilidades y los avisos de seguridad, ya que continuamente se descubren nuevas amenazas.
Esta serie se ha centrado principalmente en la situación en la que has empezado a trabajar en un proyecto heredado, pero probablemente no serás el responsable de ese proyecto para siempre. En algún momento, es probable que traspases el código a otra persona, y es una buena práctica aprovechar tus últimas semanas en un proyecto para asegurarte de que el traspaso se realiza de la forma más fluida posible. Es posible que hayas oído la regla adaptada de los exploradores por Bob MartinDeja el código en mejor estado del que lo encontraste.
A dos semanas del traspaso, es hora de dejar de aceptar nuevos trabajos. Tu trabajo en este punto debe ser crear un traspaso sin fisuras. Termine o interrumpa cualquier característica y fusione o cierre cualquier PR abierto. Lo ideal es que te pongas a escribir lo antes posible.
Documenta el estado del código. Esto incluye asegurarse de que los README y la documentación están actualizados, por si el código no se toca durante un tiempo, pero también: ¡escribir un documento de traspaso! No querrás que tu sucesor tenga que rebuscar entre muchas ramas abiertas de código no comprometido para averiguar qué estabas planeando. El documento de traspaso debería incluir:
Visión general del código base
Cómo empezar a desarrollar el proyecto
Resumen de las pruebas
El trabajo que empezaste pero no terminaste
Trabajo que tenía previsto realizar y por qué
Cualquier otra cosa que no esté documentada o no sea evidente.
Por último, es posible que tu sucesor se ponga en contacto contigo para hablar del código. Considera la posibilidad de hablar con ellos, si tienes tiempo. Es bueno ser amable.
Si estás leyendo esto, ¡enhorabuena! Estás en una posición inmejorable para hacer que un proyecto tuyo sea lo mejor posible.
Si tiene alguna pregunta o sugerencia, puede ponerse en contacto con nosotros en nuestro Slack de la comunidad de Vonage o envíanos un mensaje en Twitter.
Gracias por acompañarme en este viaje y mucha suerte en todos sus proyectos futuros.
Compartir:
Max es un antiguo miembro del equipo de Vonage. Era promotor de Python e ingeniero de software, y le interesaban las API de comunicaciones, el aprendizaje automático, la experiencia de los desarrolladores y ¡el baile! Se formó en Física, pero ahora trabaja en proyectos de código abierto y crea herramientas para facilitar la vida de los desarrolladores.