
Compartir:
Desarrollador IOS convertido en entusiasta de la Ciencia de Datos / Aprendizaje Automático. Quiero que la gente entienda qué es el aprendizaje automático y cómo podemos utilizarlo en nuestras aplicaciones.
Creación de un clasificador de imágenes en Tensorflow
Tiempo de lectura: 9 minutos
En este post, vas a construir un modelo básico de clasificación de imágenes para procesar las imágenes enviadas por los miembros de una conversación en una aplicación iOS integrada con Nexmo In-App Messaging. Después de que un usuario suba una imagen, se mostrará un pie de foto describiendo la imagen.
Vamos a utilizar Python para construir nuestro modelo de clasificación de imágenes. No te preocupes si no has trabajado con Python o no tienes conocimientos previos en aprendizaje automático.
La clasificación de imágenes en el aprendizaje automático se produce cuando se tiene una foto y el modelo de aprendizaje automático es capaz de decir qué sujeto aparece en la foto. Por ejemplo, si tomas una foto de un perro, el modelo de aprendizaje automático podrá decir "Esto es un perro".
En primer lugar, para construir un modelo de aprendizaje automático, necesitamos datos para entrenarlo.
Un modelo de aprendizaje automático utiliza datos de entrenamiento para que el modelo aprenda. Para empezar, tendremos que elegir los datos de entrenamiento. En este artículo utilizaremos los datos CIFAIR-10 CIFAIR-10.
Este conjunto de datos contiene imágenes en 10 clases, con 6000 imágenes por clase. Es un conjunto de datos muy utilizado para el aprendizaje automático y será un buen punto de partida para nuestro proyecto. Como el conjunto de datos es bastante pequeño, podemos entrenar el modelo rápidamente.
Este cuaderno está alojado en Google Colab. Colaboratory es un entorno de cuaderno Jupyter gratuito que no requiere configuración y se ejecuta completamente en la nube.
Ten en cuenta que necesitarás una Account de Google para ejecutar el bloc de notas.
Ejecutar el cuaderno es superfácil. En cada celda que contiene código, hay un botón de ejecución a la izquierda de la celda. Toca el botón para ejecutar el código. También puede utilizar el comando de teclado Shift y luego Enter.
Lo primero que tenemos que hacer es importar nuestros paquetes. Estos paquetes están preinstalados en Google Colab por lo que no necesitamos instalarlos.
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as npFíjate, estamos usando Tensorflow y Keras como frontend de Tensorflow. Keras es un gran framework que te permite construir modelos más fácilmente, sin tener que usar los métodos más verbosos de Tensorflow.
A continuación, cargaremos el conjunto de datos CIFAR. Usando Keras, somos capaces de descargar el conjunto de datos muy fácilmente.
Dividimos el conjunto de datos en 2 grupos, uno para entrenamiento (x_train, y_train)y el otro para las pruebas (x_test, y_test).
Dividir el conjunto de datos permite al modelo aprender del conjunto de entrenamiento. Después, cuando probemos el modelo, queremos ver lo bien que ha aprendido utilizando el conjunto de prueba. Esto nos dará nuestra precisión, es decir, lo bien que lo ha hecho el modelo.
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print('y_train shape', y_train.shape)
print(x_test.shape[0], 'test samples')
print('x_test shape', x_test.shape)
print(y_test.shape[0], 'test samples')Using TensorFlow backend.
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170500096/170498071 [==============================] - 75s 0us/step
x_train shape: (50000, 32, 32, 3)
50000 train samples
y_train shape (50000, 1)
10000 test samples
x_test shape (10000, 32, 32, 3)
10000 test samplesA continuación, declararemos algunas constantes.
batch_sizees el número de muestras que se van a propagar por la red.epochsson las veces que entrenamos con el conjunto de datos completo.class_nameses una lista de todas las etiquetas posibles en el conjunto de datos CIFAR-10.
batch_size = 32
epochs = 100
class_names = ["airplane","automobile","bird","cat","deer","dog","frog","horse","ship","truck"]Utilizaremos estas constantes más adelante cuando convirtamos nuestro modelo a CoreML.
def plot_images(x, y, number_of_images=2):
fig, axes1 = plt.subplots(number_of_images,number_of_images,figsize=(10,10))
for j in range(number_of_images):
for k in range(number_of_images):
i = np.random.choice(range(len(x)))
title = class_names[y[i:i+1][0][0]]
axes1[j][k].title.set_text(title)
axes1[j][k].set_axis_off()
axes1[j][k].imshow(x[i:i+1][0])En primer lugar, veamos algunas imágenes. Tenemos una función que traza 4 imágenes aleatorias y su etiqueta correspondiente.
plot_images(x_train, y_train) Image recognition Tensorflow CoreML
Image recognition Tensorflow CoreML
Ahora, vamos a configurar un modelo simple. Estamos creando una red neuronal profunda utilizando convoluciones, abandonoy agrupación máxima.
Al final, aplanaremos la red y utilizaremos Reluseguido de un Softmax.
Esto nos dará un vector (matriz de 1 dimensión), lleno en su mayoría de 0's.
Se verá así.
[0,0,0,0,0,0,1,0,0,0]Este vector corresponde a la etiqueta dada de la imagen Así, en este ejemplo, el 1 en el séptimo lugar sería una rana, ya que 'rana' está en el séptimo lugar de la class_names la lista.
A continuación se muestra toda la red.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10, activation='softmax'))¡Eso es!
En primer lugar, compilamos el modelo para obtener su pérdida. La pérdida es una medida del rendimiento del modelo durante la prueba. Una pérdida elevada significa que el modelo no lo hizo bien.
Aquí se utiliza Optimizador Adam, un algoritmo que se extiende a un descenso de gradiente estocástico ampliamente utilizado para el aprendizaje automático, para calcular la pérdida.
Entonces llamaremos a .fit que entrenará el modelo durante 100 épocas. Esto significa que el conjunto completo de datos de entrenamiento será entrenado 100 veces, El batch_size de 32 es el número de muestras que se propagarán a través de la red.
A continuación, vemos cómo le fue después de cada época utilizando model.evaluate. Nos da una puntuación para el modelo (los números más altos son mejores) y la pérdida (los números más bajos son mejores).
Nota, esto tomó alrededor de 15 minutos corriendo en Colab. Si desea ver los resultados más rápido, establezca el parámetro epochs a 1 o 2. Sin embargo, su precisión no será tan buena.
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])
# Train the model
model.fit(x_train / 255.0, tf.keras.utils.to_categorical(y_train),
batch_size=batch_size,
shuffle=True,
epochs=epochs,
validation_data=(x_test / 255.0, tf.keras.utils.to_categorical(y_test))
)
# Evaluate the model
scores = model.evaluate(x_test / 255.0, tf.keras.utils.to_categorical(y_test))
print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])Train on 50000 samples, validate on 10000 samples
Epoch 1/100
#Omitted for readability
50000/50000 [==============================] - 30s 603us/step - loss: 0.1378 - acc: 0.9518 - val_loss: 0.7136 - val_acc: 0.8116
10000/10000 [==============================] - 2s 151us/step
Loss: 0.714
Accuracy: 0.812Nuestra precisión final fue del 81%, y nuestra pérdida fue de 0,7, lo que está bastante bien.
Una vez más, la precisión es lo bien que el modelo ha podido clasificar cada imagen, mientras que la pérdida indica lo malas que han sido las predicciones del modelo.
Para más información, consulte esta definición de pérdida y precisión en curso acelerado de aprendizaje automático de Google.
Una vez entrenado el modelo, podemos guardarlo y convertirlo al formato Core ML.
Lanzado en la WWDC 2018, Core ML permite a los desarrolladores de iOS integrar una amplia variedad de tipos de modelos de aprendizaje automático en una app de iOS. Aquí utilizas esta tecnología con Nexmo In-App Messaging para facilitar tu propio aprendizaje profundo para procesar imágenes.
En primer lugar, tenemos que guardar el modelo entrenado.
model.save('cifar-model.h5')Utilizaremos coremltools, que convertirá el modelo a un formato que nuestra aplicación Stitch pueda utilizar.
Tenga en cuenta que el paquete Core ML no está preinstalado en Colab, por lo que debemos instalarlo utilizando pip
Desde arriba, se puede ver que el paquete se instaló en nuestro portátil.
A continuación, convertiremos el modelo guardado en Core ML.
Dado que hemos utilizado Keras para entrenar nuestro modelo, es muy fácil convertirlo a Core ML. Sin embargo, esto varía en función de cómo hayas construido tu modelo. Las herramientas de Core ML tienen otras funciones para utilizar con otros paquetes de aprendizaje automático, incluyendo Tensorflow y Scikit Learn. Ver el repositorio coremltools para más información.
from keras.models import load_model
import coremltools
model = load_model('cifar-model.h5')
coreml_model = coremltools.converters.keras.convert(model,
input_names="image",
image_input_names="image",
image_scale=1/255.0,
class_labels=class_names)
coreml_model.save('CIFAR.mlmodel') 0 : conv2d_input, <keras.engine.topology.InputLayer object at 0x7fa7c829fac8>
1 : conv2d, <keras.layers.convolutional.Conv2D object at 0x7fa7c829f358>
2 : conv2d__activation__, <keras.layers.core.Activation object at 0x7fa7c75bf198>
3 : conv2d_1, <keras.layers.convolutional.Conv2D object at 0x7fa7c80e40b8>
4 : conv2d_1__activation__, <keras.layers.core.Activation object at 0x7fa7c75bf438>
5 : max_pooling2d, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c80e4550>
6 : conv2d_2, <keras.layers.convolutional.Conv2D object at 0x7fa7c77434a8>
7 : conv2d_2__activation__, <keras.layers.core.Activation object at 0x7fa7c73f9240>
8 : max_pooling2d_1, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c7743f28>
9 : conv2d_3, <keras.layers.convolutional.Conv2D object at 0x7fa7c87ad1d0>
10 : conv2d_3__activation__, <keras.layers.core.Activation object at 0x7fa7c7262dd8>
11 : max_pooling2d_2, <keras.layers.pooling.MaxPooling2D object at 0x7fa7c7743f60>
12 : flatten, <keras.layers.core.Flatten object at 0x7fa7c76fac50>
13 : dense, <keras.layers.core.Dense object at 0x7fa7c76b42b0>
14 : dense__activation__, <keras.layers.core.Activation object at 0x7fa7c71ff390>
15 : dense_1, <keras.layers.core.Dense object at 0x7fa7c7670358>
16 : dense_1__activation__, <keras.layers.core.Activation object at 0x7fa7c71ff898>La salida de arriba muestra todas las capas dentro del modelo. Éstas se correlacionan directamente con la forma en que creamos el modelo en esta celda.
Eche un vistazo a los parámetros de la función convert función. Aquí, vamos a establecer la entrada para ser un image tanto para input_names y image_input_names parámetros. Esto ayudará al modelo Core ML a saber qué tipo de entrada está esperando, que es una imagen.
A continuación, reducimos la escala de las imágenes en el parámetro image_scale a un número comprendido entre 0 y 1.
A continuación, establecemos el parámetro class_labels a la constante class_names que creamos anteriormente.
Cuando utilicemos este modelo en Xcode, el resultado será a Stringcorrespondiente a la etiqueta predicha de la imagen.
Ahora podemos echar un vistazo al modelo Core ML.
print(coreml_model)input {
name: "image"
type {
imageType {
width: 32
height: 32
colorSpace: RGB
}
}
}
output {
name: "output1"
type {
dictionaryType {
stringKeyType {
}
}
}
}
output {
name: "classLabel"
type {
stringType {
}
}
}
predictedFeatureName: "classLabel"
predictedProbabilitiesName: "output1"Puede ver que nuestro input es una imagen de 32x32 píxeles, y nuestra salida es una cadena, llamada classLabel
A continuación, guardamos el mlmodel localmente utilizando un paquete de Google Colab para descargar el archivo en nuestra máquina.
from google.colab import files
files.download('CIFAR.mlmodel')
Una vez guardado nuestro modelo, podemos importarlo a nuestra aplicación. Para ello, basta con arrastrar el modelo que acabamos de guardar a Xcode.
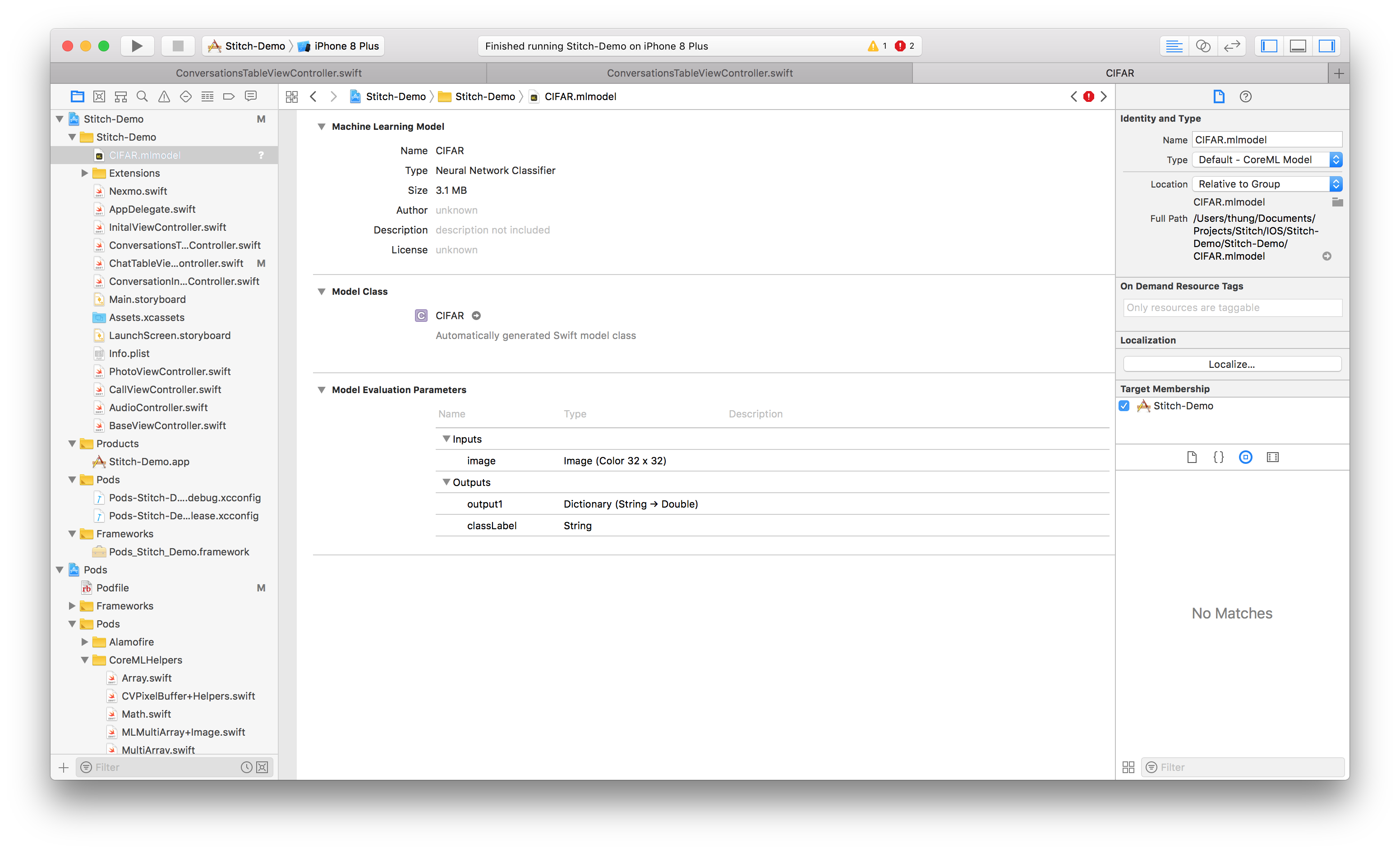 CIFAR xcode
CIFAR xcode
Asegúrese de que el modelo está incluido en el objetivo verificando que está seleccionada la Pertenencia al objetivo.
A continuación, escribiremos el código en nuestra aplicación iOS que utilizará este modelo.
En nuestra Aplicación de demostración de Stitchlos usuarios pueden cargar una foto en una Conversación existente.
In-App Messaging de Nexmo permite a los usuarios, como miembros de una conversación, activar no sólo TextEvents sino ImageEvents subiendo una foto a una conversación existente. Para este ejemplo, intentaremos predecir el contenido de la foto que ha subido un usuario.
Usted integra la funcionalidad para observar ImageEvents para Core ML directamente en su ViewController. Puede encontrar un ejemplo de cómo hacerlo en el código fuente de este ejemplo.
En nuestro ViewController, instanciaremos el modelo.
let model = CIFAR()Ahora, dentro del método cellForRowAtPath comprobaremos si el método event es un ImageEventy si es así, mostraremos la foto del ImageEvent. Luego, tomamos la imagen, la convertimos en un PixelBuffercon un tamaño de 32x32 píxeles y la introducimos en el modelo.
La razón por la que tenemos que remuestrear la imagen es porque el modelo está entrenado en imágenes de 32x32 píxeles, por lo que si no redimensionamos las imágenes, el modelo no será capaz de dar una predicción (Veremos un error en Xcode diciendo que el tamaño de la imagen es incorrecto).
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: "cell", for: indexPath)
let event = conversation?.events[indexPath.row]
switch event {
case is ImageEvent:
//get the image from the ImageEvent
let imageEvent = (event as! ImageEvent)
guard let imagePath = imageEvent.path(of: IPS.ImageType.thumbnail), let image = UIImage(contentsOfFile: imagePath) else {
break
}
cell.imageView?.image = image
//convert the image to a pixelBuffer
//using https://github.com/hollance/CoreMLHelpers.git
if let pixelBuffer = image.pixelBuffer(width: 32, height: 32) {
let input = CIFARInput(image: pixelBuffer)
//perform the prediction
if let output = try? model.prediction(input: input) {
cell.textLabel?.text = (imageEvent.from?.name)! + " uploaded a photo of a \(output.classLabel)"
}
else {
cell.textLabel?.text = (imageEvent.from?.name)! + " uploaded a photo"
}
}
break;
default:
cell.textLabel?.text = ""
}
return cell;
}El modelo devolverá entonces un classLabel. Será el nombre de la imagen que el modelo ha predicho, que puede ser una de las siguientes etiquetas: "avión", "automóvil", "pájaro", "gato", "ciervo", "perro", "rana", "caballo", "barco" o "camión".
Tras observar nuestras predicciones, podemos decir que el modelo sólo será capaz de reconocer 10 etiquetas. El cuaderno completo está disponible en GitHub.
Esto es bueno para una demostración, pero no para una aplicación de producción. En un próximo post, veremos cómo construir un modelo de reconocimiento de imágenes con más datos. Examinaremos la popular base de datos base de datos ImageNetque contiene 14.197.122 imágenes etiquetadas.
Se trata de una descarga de 150 GB, por lo que veremos cómo descargarla, formarla e integrarla en nuestra aplicación de demostración Stitch.